Minimal CMDB for companies with 100–500 employees: entities and relationships
A minimal CMDB for a company of 100–500 employees: which entities and relationships to create so incidents and changes can be linked to assets quickly, without bureaucracy.
Why a minimal CMDB for a company of 100–500 employees
In companies with 100–500 employees there is usually already a service desk, hardware inventory and some procedures. Still, during incidents the same pain appears: a ticket lives separately, and answers to simple questions must be searched manually. What exactly broke, which users were affected, where it is hosted, what was changed yesterday and who is responsible.
A minimal CMDB is needed not for a “nice database”, but to link incident - asset - change. When an incident is tied to a specific IT service and its key components, the root cause is found faster, repeatability becomes clearer, and reliability improvements can be proven. When changes are recorded on the same objects, it becomes clear which work actually increases stability and which creates new failures.
Excessive detail almost always breaks adoption. If you try to describe every cable, every setting and all software on every PC, the CMDB becomes a never‑ending project. Data goes stale and the team stops using it. For a start it’s more important to cover only what affects downtime and mass tickets.
Success at the first stage is visible by simple signs:
- most incidents are tied to a service or asset, not an abstract “internet is down”
- for each major outage it’s clear which changes preceded it
- time to initial diagnosis noticeably drops
- reports show top problematic components, not just a list of tickets
Example: “1C is not working” stops being a single complaint type and becomes a concrete incident on a service related to a server or VM, a network node and the last change (e.g., an update). Even in mixed infrastructure with workstations and servers (including on‑premises), such a minimum gives control without bureaucracy.
Where asset inventory ends and CMDB begins
Asset inventory answers “what we have and where it is”. CMDB answers a different question: “what affects service operation and how it’s related to incidents and changes”. If an object doesn’t help restore faster, make safer changes, or clearly assess impact, it doesn’t belong in the CMDB.
The practical boundary is simple. Inventory, warehouses and contracts usually contain prices, depreciation, serial numbers, warranty, invoices, packaging and “how many mice were issued”. CMDB keeps what support and change management need: who is the owner, where it’s located, what manages it, which service it belongs to and what depends on it.
The 80/20 principle works great for a minimal CMDB: it’s better to have a little data that’s always up to date. The most useful 20% are the items that let you answer three questions in 2 minutes: what broke, who was affected, what was changed nearby.
To prevent the CMDB becoming a “register of everything”, introduce an inclusion rule: each entity must answer a support or change management question. Useful short checklist:
- will this help find the cause of an incident faster?
- will this help assess impact (who and what will be affected)?
- will this help perform and roll back a change more safely?
- does this object have an owner responsible for accuracy?
- can you maintain this data without manual routine work?
Example. Access to accounting drops. If the CMDB has the relation “Accounting IT service -> application -> server/VM -> site”, the on‑call quickly sees the problem is on a specific VM in a branch and that network rules were changed there yesterday. And “what model is the accountant’s monitor” is almost never needed for that incident—leave it in asset inventory.
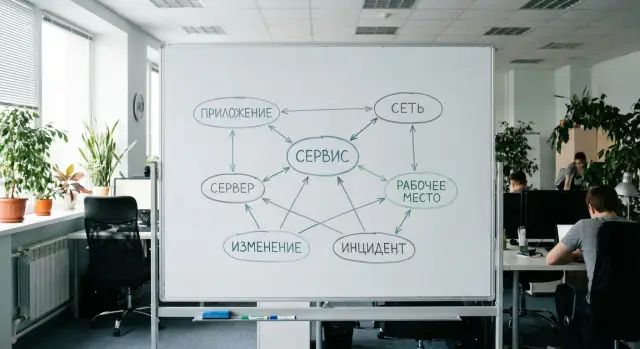
Entity 1: IT service as the main object
If you build a minimal CMDB, start with IT services, not hardware. A service is what a user understands as “working or not working”: mail, 1C/ERP, VPN, corporate Wi‑Fi, printing, file access.
This way you link incidents and changes to an understandable object. It’s easier for users to pick “Mail” than “SRV-EXCH-03”. It’s easier for you to see which components and which support teams stand behind the service.
To avoid drowning in approvals, a service needs only a minimal set of fields:
- name and a short description “for whom and why”
- service owner (one person) and support group (one team)
- criticality (e.g., high, medium, low)
- support window (e.g., 09:00–18:00, 24/7)
- who it’s provided to (departments or user groups)
An owner is needed not for complex procedures but to quickly resolve disputes: what to restore first, whether changes are allowed in business hours, who to notify.
Keep the “service - users/departments” link at a list level, without detailed role modeling. For example: “VPN - all employees + contractors”, “1C/ERP - accounting and procurement”, “Wi‑Fi - office and meeting rooms”. That’s enough to quickly assess scope during an incident and risk during a change.
Example: if “Mail” is down, the incident is opened on the service, the support group and criticality are pulled in. During a planned update of the mail server the change is also linked to the service, immediately showing which users are affected and which support window fits.
Entity 2: Applications and service components
If a service answers “what the business gets”, an application answers “what makes it work”. In a minimal CMDB it’s convenient to treat applications as part of the service rather than a separate zoo of systems. That way, during an incident it’s clearer what could be broken and where to look.
Describe applications not to the maximum, but just enough for incidents and changes to be linked without manual digging. Usually it’s enough to split into client side (workstations or browser) and server side (API, web server, background jobs). Even for a monolithic app this helps: you separate “user can’t log in” from “backend not responding”.
Minimal fields for an application card:
- name and which service it belongs to
- environment: production or test (often prod and non‑prod are enough)
- responsible person: tech lead/admin/support owner (who to call at 2 a.m.)
- vendor or contractor (if any), to understand responsibility boundaries
Relationships matter more than fields. An application must be linked to nodes (servers and VMs) where it actually runs. Then an incident shows the affected CI immediately: e.g., “request portal unavailable” links to the application, which is linked to two VMs and a load balancer.
Databases don’t need full descriptions. But if a database is critical for downtime, create it as a separate element and link it to the application. Then a DB patch, migration or backup configuration change clearly shows risk to production.
Entity 3: Nodes (servers and virtual machines)
For a company of 100–500 employees it’s convenient to create a single CI type called “node”. Physical servers, virtual machines and cloud instances all fall into it. This keeps the minimal CMDB from becoming a set of many entity types and makes incidents easier to link to one clear object.
Keep the node card short. Fields should answer “what is it, where is it and who is responsible”. Usually enough are:
- name (hostname) and unique ID
- role (e.g., web, DB, file, terminal)
- environment (prod, test, dev)
- location (site, server room, rack if necessary)
- OS and owner (team or responsible person)
Avoid overcomplicating clusters. Instead of detailed topology, create a logical group “cluster” and link the nodes that deliver a single result (e.g., “accounting DB cluster”). In an incident you mark the group and then see the node list. Usually that’s enough to assess risk and scope.
Node relationships should be practical. Minimum: "node -> application/component" so you understand which service will be impacted. Often useful to add "node -> network/segment" (e.g., DMZ or office network) and "node -> site/rack" if that affects downtime.
Example: access to the portal disappears at night. The incident is linked to the application “Portal” and the node WEB-PROD-01. Links show the node is in the DMZ at site A and belongs to the logical group “web cluster”. It’s then easier to check whether a recent change affected this node or the network segment, avoiding time wasted finding “where this actually runs”.
Entity 4: Workstations and users
Registering a workstation as a CI is not always necessary. In a minimal CMDB it makes sense when problems often affect many users at once (mass incidents after an OS update, AV failure, faulty batch of laptops) or when security matters (who used the device, where it is, which policies apply).
To make workstation CIs useful for support, keep the card short but unambiguous. Usually you can fill it from procurement, OS images and user records:
- current user (or owner)
- department
- model
- serial number
- OS version
Again, relationships matter more than details. The most useful chain is: workstation -> user -> support group. Then a ticket from a person quickly “understands” which device is affected and where to route it (Service Desk, endpoint support, information security).
Example: after a Windows update the accounting client-bank printing stopped. If workstations are linked to users and departments, you see it’s one laptop model and one OS version. That looks like a mass incident and a single change, not 30 separate tickets.
Boundaries are important. Peripherals (mice, headsets, monitors) should be CIs only if they frequently generate tickets or actually cause downtime. Otherwise you’ll get many cards and little value: support will spend time on inventory instead of solving problems.
Entity 5: Network and sites (only what affects downtime)
Network documentation can easily become an endless diagram. In a minimal CMDB add only what helps restore faster and run safer changes when something fails.
Usually it’s enough to record backbone elements: the main router at a site, critical switches, Wi‑Fi controller (if the office depends on it), inter‑site and internet links, and connection points used by critical services. The rest (ports, minor switches, detailed L2/L3 topology) should live in network documentation, not in the CMDB, unless used daily.
To make a network card usable, fields must be clear to any on‑call person:
- site (office, branch, data node)
- role (core, edge, Wi‑Fi, link)
- owner (internal owner/team)
- provider and escalation contacts (for links)
- criticality (what happens if this element is unavailable)
The most important thing is the "network -> services" link. For each channel or network node note the few services that depend on it (mail, telephony, ERP, POS). Then a “no internet at a branch” incident quickly shows which services are affected, who to notify and what workarounds to check.
Example: a provider swaps equipment on a link. If the link is linked to services “POS” and “VPN to HQ”, the change immediately has a clear risk and test checklist. Not a full network diagram, but the right relationships.
Links with incidents and changes: what must always work
If the CMDB is small but relationships are reliable, you already win. In a minimal CMDB for a 100–500 person company it’s more important that an incident and a change always lead to a clear answer: what was impacted, what was changed and who is responsible.
Minimal change record
A change record should be short so people actually fill it. But it must include basic data without which later outage analysis is impossible:
- what we change (brief and specific)
- when we change (maintenance window)
- responsible person (one owner)
- affected CIs (service, application, node)
- rollback plan (what to do if things get worse)
Key rule: a change is not closed until the “change -> CI” link is filled. You don’t need to describe all dependencies. It’s enough to name 1–3 CIs that can realistically cause an incident.
How to link incidents so you can find a cause in minutes
An incident must include the link “incident -> CI”. If users complain “mail doesn’t work”, select the Mail service CI, not a specific server if that’s unknown at the start.
Second required step: if a change happened before the issue, link the incident to that change as the “last relevant change”. Example: after a driver update on workstations some users lost access to a corporate system. The incident is linked to the CI “workstation” (or a group of workstations) and to the change “driver update”. Then it’s easier to see the scope and roll back quickly.
Approvals can be kept lightweight:
- service owner confirms user impact
- technical owner of the component confirms the technical part
- CAB (or IT manager) is needed only for risky changes during business hours
How to implement a minimal CMDB in 30–60 days
A minimal CMDB works when you describe only what helps link incidents, assets and changes. The 30–60 day goal is simple: so that an on‑call and an engineer can tell in a minute which service was affected, on which node, and what change might have caused it.
5‑step plan
-
Pick 5–10 most business‑critical IT services and create them as configuration items. Start with services that cause the most downtime or complaints: mail, 1–2 key business systems, internet access, telephony.
-
For each service add applications and only key components. Guideline: 1–3 applications per service and 3–10 nodes (servers, VMs, important databases), without trying to document everything.
-
Enforce the rule: every incident must have the CI field filled. If the user doesn’t know what to choose, they pick the service. The dispatcher then refines it to application or node. This quickly builds the habit and produces statistics.
-
Launch change management only for critical CIs. Don’t force the team to document changes for every laptop. It’s enough to record things that can bring a service down: updates, configuration changes, migrations, node replacements.
-
Do a short cleanup monthly: remove duplicates, fix links, close gaps where incidents are regularly attached to “unknown”.
Practical benchmark: if “Accounting” fails at night, the engineer opens the service, sees related applications and nodes, checks recent changes on them and finds the cause faster. This is how a minimal CMDB starts delivering value without extra bureaucracy.
Common mistakes and how to avoid them
The most frequent mistake is trying to describe all assets and dependencies on day one. For a 100–500 employee company this usually ends with a big database that’s empty in practice: half the cards aren’t useful for outage analysis and data becomes stale in a couple of months. Start with what truly helps link incidents, assets and changes.
Mistake 1: “We’ll fill all fields and that will fix everything”
When a card has 20 mandatory fields, people stop creating it or start entering “123” and “unknown”. Better to keep the minimum that can be maintained daily: a clear name, CI type, owner, environment (prod/test), criticality and key links (to a service, node or user).
Working rule: a new mandatory field appears only if it has already helped in at least 3 real incident investigations.
Mistake 2: CMDB without owners and without changes
If a CI has no owner, its accuracy becomes nobody’s responsibility. And if changes leave no trace in the CMDB, it becomes a pretty directory that doesn’t explain why everything failed.
A set of habits that usually works:
- assign an owner to each service and to key nodes (not everything)
- link every planned change to affected CIs at least at the “service - node” level
- agree on a consistent naming template (e.g., APP-ERP, SRV-DB01)
- once a week review 5–10 “suspicious” cards: without owner, without links, unclear name
- when finding a duplicate don’t create a third: merge and fix the “correct” name
Example: after a nighttime VM update with a database, incidents appear in the accounting service. If the change is linked to the VM and the service, finding the cause takes minutes. If links are missing, the team spends hours checking network, users, app, licenses.
Short checklist: is your CMDB sufficient for work?
A minimal CMDB is working not when “everything is recorded”, but when it helps quickly answer two questions: what exactly broke and what was changed before it.
Check these signs:
- a short list of critical IT services exists (usually 10–30), and each has an owner who can state priorities
- every incident has at least one CI selected: service (for mass problems) or workstation (for single cases)
- every change lists affected CIs and has a clear rollback plan
- there is a small set of network and site CIs (about 10–20) that really affect downtime: main internet link, key switch, VPN gateway, hypervisor cluster, site/office as an object
- monthly short review is performed: remove duplicates, merge “double” records, close gaps for critical services
Quick practical test
Open the last 10 highest‑impact incidents. If in 7–8 of them a CI is linked and you can see recent changes for those CIs, the minimal CMDB already does its job. If not, the issue is usually not lack of data but discipline: selecting CI when registering and indicating CI when changing.
When your checklist is “green” but impact is low
This happens if CIs are too detailed. For a 100–500 employee company one “Service: Mail” and one “Node: mail server” are better than 50 components nobody updates.
Real example: linking an incident to an asset and a change
On Monday morning users report ERP loads in 20–30 seconds and invoice printing freezes. The service desk gets a single incident, but quickly finding the bottleneck matters without adding the whole infrastructure to the CMDB.
The dispatcher opens the incident and in “Affected CIs” chooses the service “ERP and document printing” rather than “server #17”. This immediately separates a service problem from a single workstation fault.
Following CMDB links shows how the service is built:
- service: “ERP and document printing”
- application: “ERP backend” and “Print Gateway”
- nodes: VM-ERP-01 and VM-PRINT-01 (or a physical server if printing runs there)
- network/site: VLAN-Office-3 and switch SW-3F-12 (only if they realistically affect downtime)
A few quick checks show ERP is slow for some users and printing only fails on the 3rd floor—pointing to the network. The engineer opens the SW-3F-12 card and checks “last change”. There is an entry: “Friday night firmware update and QoS changes”. Now there’s a concrete hypothesis and a concrete object, not “everything is slow”.
Fixes are processed as a change and linked to the same CIs: SW-3F-12, VLAN-Office-3 and the service “ERP and document printing”. The plan lists simple steps: restore previous QoS profile, check port load, run a smoke test for printing. After execution the incident shows which change resolved it.
What helped: service name, list of key applications, node links and change history on the node or network device. It was unnecessary to store serial numbers of all printers, full floor plans and every port description unless they matter for outage analysis.
Next steps: how to expand the CMDB without extra burden
A minimal CMDB doesn’t have to grow into a huge directory. Expand it only where it reduces downtime and speeds up fixes. Start with three services where an hour of downtime is really costly (e.g., accounting, contact center, e‑registration).
Do not add new entity types until update rules are clear. Every CI must have an owner—not “IT in general” but a specific role or team. The owner ensures that changes in the service are reflected in the CMDB at least at the relationship level.
To avoid debates about fields, agree on minimal templates in advance. They must stay short: what it is, where it is, who owns it and what it’s linked to. Once fixed, expansion becomes a repeatable habit.
A sequence of expansion that usually avoids bureaucracy:
- add new CIs only after 2–3 recurring incidents in the same area
- first capture relationships (service -> application -> node), then fill details as needed
- enforce: every change in a critical service updates the CMDB the same day
- once a month do a short check: 10 random CIs and their links
If you hit infrastructure or process bottlenecks (incidents, changes, monitoring), sometimes it’s easier to involve a system integrator. For example, GSE.kz (gse.kz) as a vendor and integrator helps with infrastructure for critical services, server and workstation selection and support, so the CMDB relies on a real, manageable equipment base.
FAQ
Why do I need a minimal CMDB if we already have a service desk and asset inventory?
A minimal CMDB makes it clear in every incident *what exactly* failed (service/component), *who* was affected and *what* was changed before the issue. This reduces time for initial diagnosis and helps see recurring causes instead of just counting tickets.
Where should I start the CMDB to avoid being overwhelmed by volume?
Start from IT services, not hardware. Pick 5–10 most critical services, assign an owner and a support team, then link 1–3 applications and a few key nodes (servers/VMs/instances) that actually run each service.
Where is the boundary between asset inventory and CMDB?
Asset inventory answers “what do we have and where”. CMDB answers “what affects service operation and how it’s linked to incidents and changes”. If an object doesn’t help to restore service faster, assess impact, or run safer changes, keep it in asset inventory rather than pull it into the CMDB.
What fields should an IT service have in a minimal CMDB?
A short service card is enough: name, brief description (who and why), a single owner, support group, criticality and support window. Add a simple audience link (which departments or user groups) so you can quickly assess scope and priority during an outage.
What should I choose in an incident: a service or a specific server/VM?
If the user doesn’t know the infrastructure, they should pick the service, not the server. Rule of thumb: register the incident on the service, and the dispatcher narrows it to application or node once more details are known. This avoids wasting time guessing the CI during registration.
How to link changes with the CMDB so you can actually find causes of outages?
Record changes briefly, but always link them to 1–3 affected CIs (service, application, node), specify the maintenance window, the responsible person and a rollback plan. Without this link it’s nearly impossible later to prove the outage was caused by specific work, and teams end up ‘trying everything’.
How to describe servers and virtual machines without overcomplicating the model?
Treat all servers, VMs and cloud instances as one CI type: “node”. Keep the node card minimal: hostname/ID, role, environment (prod/test), location and owner. Model clusters as logical groups so you can see composition and risk without complex topology.
Should I include users’ workstations in the CMDB?
Add workstations as CIs when it helps catch mass incidents (after OS updates, antivirus failures, faulty batches of laptops) or when security requires it. Minimum fields: current user/owner, department, model, serial number and OS version; add more only if it helps incident investigation.
How to describe the network in CMDB without turning it into an endless diagram?
Include only key network elements that affect outages: main routers at a site, critical switches, Wi‑Fi controllers (if office connectivity depends on them), inter‑site and internet links, and key connection points used by critical services. Don’t store every port or minor switch in the CMDB—keep detailed network diagrams in network documentation.
How to tell that the minimal CMDB already works and brings value?
Use simple metrics: share of incidents with a filled CI, visibility of the “last relevant change” next to major outages, and reduced time for initial diagnosis. Practical test: open the last 10 high‑impact incidents—if most show which service/node was affected and what was changed before it, the CMDB is delivering value.