Comparing Kafka, RabbitMQ, NATS and ActiveMQ for Enterprise Systems
Comparison of Kafka, RabbitMQ, NATS and ActiveMQ for enterprise systems: delivery guarantees, transactional behavior, monitoring and real maintenance costs.
Why a message broker for an enterprise system
In enterprise integration a message broker is needed where systems must exchange events and tasks without tight coupling. Instead of every service calling every other directly, producers publish messages to a broker and consumers pick them up when ready.
Synchronous APIs are good for "give me an answer now" requests, but they don't handle load peaks well and depend on the partner's availability. If accounting or the warehouse is down for 10 minutes, direct calls start failing, users see errors and data can be lost. An asynchronous queue lets you accept a request, put it in a buffer and process it later.
In practice the pain is usually not in sending a message, but in what happens during failures: messages get lost, retries create duplicates, latency increases, and diagnosis becomes guesswork. So when comparing Kafka, RabbitMQ, NATS and ActiveMQ it's important to first understand which scenarios you need to cover and what cost you pay for reliability.
Most often a broker helps to:
- survive temporary outages of dependent systems without losing data
- smooth load peaks via buffering
- decouple producer speed from consumer speed
- simplify routing of events between many systems
- make processing repeatable and controllable
Multiple teams are usually involved: development designs message contracts and idempotency, operations owns stability and monitoring, security sets access, encryption and audit rules. If any party joins late, the "technical" broker choice quickly becomes an organizational issue.
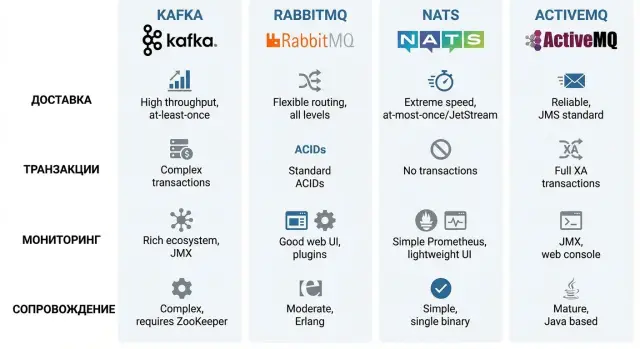
Kafka, RabbitMQ, NATS, ActiveMQ — the quick overview
Kafka is often chosen not as a "task queue" but as an event log. Messages are stored on disk, can be reread, multiple independent consumers can be attached, and service state can be rebuilt from history. This is convenient for analytics, event-driven integrations and stream processing, but it requires discipline in data schemas and careful retention and partition management.
RabbitMQ is a classic queue broker with strong routing features: queues, exchanges, different delivery types and well-known patterns (work queue, pub/sub, request/reply). It's usually convenient for "send a task to a worker and get acknowledgement" scenarios, especially when flexible routing and a quick start matter.
NATS is a lightweight broker for low latency and simple pub/sub. In its basic mode it focuses on speed and minimalism. If you need persistence, acknowledgments and redelivery you typically enable JetStream, which changes the operational model and trade-offs.
ActiveMQ is a mature enterprise integration option, often used with JMS and conventional corporate patterns for queues and topics. It's suitable when compatibility and predictable behavior matter, but exact capabilities depend heavily on version and configuration.
Before comparing, be explicit about what you're comparing: the product or a specific build, the operating mode (e.g. NATS vs NATS JetStream), storage requirements (how much and how long), load type (event stream or task queue), and consumption model (single consumer, consumer group, multiple independent readers).
How to compare: criteria and requirement questions
To make a comparison useful, start not with product names but with what you actually pass through the broker: events, commands, documents, logs. That determines requirements for reliability, retention and speed.
Collect inputs in one place, brief and concrete: message peaks, average size, how critical loss is, whether you need to keep a stream for weeks or minutes.
Questions that clarify choice quickly
Answer these before a pilot:
- What SLOs do you need: acceptable latency, availability, and how many minutes or hours to recover from a failure?
- How many consumers will there be and who are they: microservices, ERP/CRM integrations, analytics, external partners?
- Which languages do teams use and which clients are convenient for them: this affects onboarding time and support.
- What matters most: strict ordering, re-reading history, complex routing, or developer simplicity?
Then check constraints that often break plans late. For example, isolated infrastructure and internal certification or access rules may eliminate some options regardless of functionality.
Mini-scenario to validate requirements
Imagine this chain: POS sends a sale, the warehouse deducts stock, accounting posts entries, analytics computes reports. If analytics needs to replay a month of history, requirements differ. If the warehouse must react within seconds and order matters, priorities shift.
Delivery guarantees and living with duplicates
Usually three delivery levels are discussed: at-most-once (may lose messages, no duplicates), at-least-once (no losses, duplicates possible) and exactly-once (appealing but almost always with caveats). In practice most corporate integrations run in at-least-once mode and learn to tolerate duplicates.
Simply put: Kafka by default provides solid at-least-once and tolerates temporary consumer problems well; RabbitMQ and ActiveMQ often rely on consumer acknowledgments (acks); NATS in basic mode is closer to "deliver-and-forget", while reliable delivery is tied to JetStream and its ack/retention configuration.
Reliability mechanics come down to basics: the producer must know a message was accepted (ack), the consumer must confirm processing, and the system must retry on failures. Retries appear not because someone "messed up" but because during a failure it's unclear whether processing completed.
To prevent duplicates from breaking business logic, build protections: handler idempotency, unique keys (e.g. order_id + version), deduplication in storage (unique index or processed IDs table), cautious retries with limits to avoid retry storms.
A DLQ (dead-letter queue) is needed when some events are "poisoned" or require manual inspection. Keep it simple at first: agree on retry counts and who inspects the DLQ.
A practical test is simple: run a consumer, process 100 messages, then kill it mid-run (or cut network) and observe behavior after restart. A good outcome: no losses, and duplicates are either safe or filtered by keys.
Transactions and exactly-once: what’s realistic
A broker transaction is not the same as a database transaction. In a DB you commit data changes; in a broker you commit publication (and sometimes reads). The problem is at the boundary: DB writes and event sends happen in different systems, and you usually can't commit them both atomically.
Exactly-once is rarely a magical switch. It's a set of conditions and discipline. Kafka has transactions and an idempotent producer which helps inside its model. But end-to-end "exactly once" between services still depends on handlers, databases, retries and network failures. Often it's cheaper to accept at-least-once and make processing idempotent.
The most practical way to coordinate DB and events is outbox/inbox patterns. Example: a billing service writes the invoice to its DB and inserts an outbox row with the "InvoiceCreated" event. A separate process reads the outbox and publishes to the broker. On the consumer side, an inbox stores processed message_ids to avoid double-processing.
If distributed transactions are too heavyweight, compensation is normal: "order created" then "order canceled" rather than trying to roll everything back at once.
To make this predictable, document processing rules in a contract: unique message_id and idempotency key, which retries are acceptable and how to detect them, what counts as successful processing (and what to do on partial success), retention and ordering requirements, and allowed compensating actions.
Ordering, retention and replay
Differences between brokers are not only about speed but about how they store messages and how consumers read them.
Queue vs topic models differ. A queue usually means one of the consumers takes the message and it's gone (or goes to DLQ on error). A topic is more like a log: multiple consumer groups can read the same data and messages live according to retention rules.
Ordering has a cost. Strict ordering is usually guaranteed only within a single stream (e.g. a queue or partition). The stricter the ordering requirement, the less parallelism you can use: careful partitioning keys, cautious scaling, more failure handling. If ordering matters only "per customer" or "per request", you usually solve it by a key so all events for an entity go to the same stream.
Retention and replay matter when you need to reprocess. In integrations between accounting, warehouse, helpdesk and others, systems often fall out of sync, and being able to restore state from an event stream is practical insurance.
Decide up front where replay is needed: rebuilding an analytic view, recovering after a consumer crash, onboarding a new service to past events, or incident investigation along a time line.
Another topic is data schemas. Without versioning rules (at least: "add fields, don’t break old ones") replay quickly becomes painful: old messages must remain understandable to new consumers.
Monitoring and diagnostics in production
A message broker is valuable in production until the first midnight incident. Monitoring must answer "where is the cause" (client, network, broker, disk), not just "something is wrong."
Basic metrics you can’t do without
Metrics are similar across Kafka, RabbitMQ, NATS and ActiveMQ even if names differ:
- consumer lag and its growth dynamics
- input and output throughput (messages/sec, bytes/sec)
- publish and consume errors, failure rates
- retries and size of retry queues (or DLQ) growth
- disk usage and growth rate (for persistent systems)
Link metrics to context: which service, which topic or queue, what message type. Then you see not "broker down" but "billing service can't keep up."
Logs, tracing and alerts that get acted on
Broker logs are useful but often show symptoms. The fastest way to a root cause is correlation id in messages, structured client logs and distributed tracing (if present).
Alerts should be rare and actionable. Examples:
- lag grows continuously for 10–15 minutes and doesn't shrink while input rate is normal
- disk usage > 80% or projected fill time < 24 hours
- publish error rate > 1% over 5 minutes
- retries or DLQ grow faster than they are processed
Also monitor cluster health (node availability, replication, leader election) and clients (reconnects, timeouts, protocol versions).
Operations need a "what’s on fire now" dashboard. Business teams benefit from a simple screen: how many messages passed, how many delayed, how many moved to retries. That way integration value is visible beyond engineers.
Security and access control without extra bureaucracy
In enterprises security is less about "which product is better" and more about how you issue access and live with it for years. For Kafka, RabbitMQ, NATS and ActiveMQ both protocols and processes matter.
Start with a simple rule: grant access to applications, not people. Create a separate identity (or certificate) per service and restrict publish/read rights to required topics/queues. That way compromising one service doesn’t expose the whole exchange.
TLS encryption is almost always a must-have, but the pain is in certificates: expiration, rotation, trusted CAs. Agree with InfoSec who issues certs, how they rotate and how quickly keys can be replaced without downtime.
Strictly separate environments. If test services read production messages for debugging, you are courting an incident. Keeping distinct clusters is the easiest approach, though strict namespaces and separate identities may be acceptable if InfoSec agrees.
Audit logs should record: granting and changing rights, topic/queue creation and deletion, failed authentications, TLS/certificate changes, and admin operations via console or API.
To avoid manual work, agree on standard roles and request templates: "reader", "publisher", "project admin". Automate via a central catalog and approved policies to give InfoSec control and teams speed.
Operations and total cost of ownership
Broker cost is rarely just a license fee. Major expenses appear after launch: upgrades, incidents, tuning, backups, team training and on-call.
Kafka is usually more expensive to operate because of disk and network demands. It writes a lot to disk, requires planning retention and careful monitoring of lag, partition sizes and balance. This is justified when high throughput and replay are important, but administration is notably harder.
RabbitMQ is often simpler for teams when solving queueing and routing problems. But clusters, mirroring policies, very large queues and "stuck" consumers still require experience. NATS is chosen for ease and quick start, but costs can grow if you need persistence, replay and strict guarantees. ActiveMQ is familiar to long-time Java shops, but large deployments require pre-checks on scaling and observability.
Operational time is mostly spent on: capacity planning (CPU, RAM, disk, network and 6–12 month growth), upgrades and client compatibility, managing schemas and event versions, backups and restores, and incidents (delivery delays, duplicates, overloaded queues, crashed consumers).
Personnel matters: finding an experienced Kafka engineer is usually harder and costlier than a RabbitMQ admin, and training takes time.
When estimating TCO count everything together: hardware (often decisive for Kafka), licenses (if any), support and, worst of all, downtime. In enterprise environments this becomes: how many people are needed to run the system predictably 24/7, and do you have the infrastructure and support for that?
Resilience and scaling: a practical view
Resilience starts with deployment, not product name: is there a cluster, how does replication work, who decides on node loss (quorum), and what happens to messages during failure.
RPO and RTO in plain terms
RPO = how much data (messages) you are willing to lose in a failure. RTO = how quickly the service must be back. For integration between accounting and warehouse RPO is often near zero and RTO measured in minutes, otherwise manual work piles up and errors increase.
Make a recovery plan: where state is stored, how to bring up a new node, and who decides to failover.
Geo-distribution and chaos testing
Geo-distribution is needed when one data center outage is unacceptable. It adds risks: latency, split-brain, more complex updates and more expensive monitoring. Often it's better to start with a reliable cluster in one DC and clear recovery procedures.
Validate resilience with regular tests:
- shut down one cluster node during load
- simulate network partitions between nodes
- fill a disk or cause sudden disk latency
- restart a broker during active publishing
- crash a consumer and recover
Scale where the bottleneck is measured: disk and network for storage/replication, partition/queue counts, connection limits, heavy consumers. Otherwise you may overpay for nodes while the real problem is a slow disk, wrong ack settings or a single slow consumer.
Step-by-step broker selection
Start not with tech, but with describing your events. The same broker can be great for logs but unsuitable for payments. First fix requirements, then compare features.
A practical sequence:
- Map flows: who publishes, who reads, and what happens if an event is lost or duplicated.
- Choose consumption model: queue for commands, pub/sub for notifications, streams and replay for analytics and recovery.
- Agree on delivery and retries: acceptable duplicates, idempotency approach, retry limits and what goes to dead-letter.
- Plan observability: required metrics (lag, throughput, errors), alerts and incident handling rules.
- Run a pilot on 1–2 real integrations and measure latency, load, operation complexity and recovery time.
After the pilot lock down standards: event format and versioning, key and partitioning rules, retention and access policies.
Simple example: for accounting-to-warehouse integration losing events is unacceptable but duplicates are possible. Plan deduplication at the consumer and test it under failure in a test cluster.
Example scenario: integrating multiple systems without losses
Imagine a company where an ERP creates an order, CRM keeps customer data, and an internal portal accepts employee and partner requests. Each change becomes an event: "TicketCreated", "OrderPaid", "ContactUpdated". Events go to a broker and other systems subscribe to update their data.
Requirements are strict: tickets cannot be lost, duplicates are acceptable, and audit is needed to answer "who processed the event and when?" afterward.
To avoid loss and live safely with duplicates follow a few rules: acknowledge processing only after writing to your DB (ack after commit), do retries with backoff and limits, move hopeless messages to DLQ, include an idempotency key (e.g. request_id) and store a processed flag, write minimal audit (event id, time, result, error).
Integration health is visible not by "all green" but by metrics: lag, consumer error counts and processing time. If processing time doubles users will feel it before a crash.
Decide who is on-call and what to do at night without developers. Keep short runbooks: how to stop a consumer, safely replay DLQ, increase limits, or find a "poison" message. Automate alerts and common actions so you don't summon a chat of 10 people for every slowdown.
Common implementation mistakes and how to avoid them
A broker rarely breaks an integration by itself. Problems usually stem from expectations: teams expect "proper settings" to replace careful data handling and processes.
Costly mistakes
Typical production problems:
- Trying to "fix" business logic with broker parameters. The solution is idempotent handlers, unique message keys, deduplication and clear retry rules.
- Shoving different event types into one topic/queue for "simplicity." Better to separate channels by purpose, have explicit contracts, versioned schemas and compatibility rules.
- Not planning retention. Retention, disk growth, headroom for peaks and backups must be calculated before launch, otherwise disk will run out and the pipeline stops.
- Not testing failures and networks while expecting high reliability. Run fault tests: node failures, latency, partitions, queue overload and recovery.
- Having monitoring but no response. Define thresholds, owners, response times and clear action plans.
Practical mini-case
If accounting sends payments and warehouse confirms shipments, a repeated message might double an operation. The fix is simple: give each payment/shipment a unique identifier and have the consumer store processing state and ignore repeats. Then a network failure becomes a delay, not a financial incident.
Short checklist and next steps
Before choosing between Kafka, RabbitMQ, NATS and ActiveMQ verify requirements, not names. The same broker can be ideal or painful depending on whether replay, strict ordering, easy operations or minimal latency matter more.
Checklist for message behavior (record answers):
- Which delivery is needed: at-least-once, at-most-once, any real exactly-once requirements?
- Is ordering needed: globally or only by key (order, customer, device)?
- How do you do retries: number of attempts, delays, where do "stuck" messages live?
- Is there a DLQ and who processes it: team, runbook, SLAs?
- Do you need retention and replay: how many days and who will re-read?
Also verify operations, which often matter more than theoretical guarantees:
- Update plan: who runs rolling updates and are there maintenance windows?
- Capacity: traffic forecast for 6–12 months, peaks, disk and network headroom
- Monitoring and alerts: processing latency, queue sizes, consumer errors, disk space
- Backups and recovery: what is actually backed up, RPO/RTO, test restores
- On-call and escalation: who answers at night and what counts as an incident
Before launch prepare message contracts (schema, versions, compatibility), naming rules for topics/queues and incident runbooks: what to do on duplicates, consumer lag and DLQ growth.
If you have many systems, strict InfoSec requirements and 24/7 needs, sometimes hiring an integrator is easier. For projects like this GSE.kz often helps not only with software but with practical surrounding work: infrastructure sizing (including local servers), monitoring setup and organizing support.
Next steps: pick 1–2 critical flows, run a pilot under real load, size resources and maintenance costs, then fix an SLA and a staged rollout plan.
FAQ
Why use a message broker if we already have APIs?
A broker is useful when services need to exchange events and tasks without direct calls. It helps survive temporary unavailability of dependent systems, smooth traffic spikes and decouple producers' speed from consumers'.
How do I know I need Kafka instead of RabbitMQ?
When you need flexible routing and acknowledgment-based task delivery, RabbitMQ or ActiveMQ is often more convenient. If you need a stream of events with storage, the ability to replay history and add consumers later, Kafka is usually a better fit.
When does it make sense to choose NATS and what changes with JetStream?
NATS is chosen when low latency and simple pub/sub are key. If you need acknowledgments, redelivery and persistent storage, look at JetStream — but note that operating JetStream adds a different class of complexity.
In which cases is ActiveMQ a reasonable choice today?
ActiveMQ is a reasonable choice if you already follow traditional enterprise integration patterns, use a Java stack and need JMS compatibility. Before finalizing, check the specific version, clustering modes and how you will monitor and scale it.
Which delivery guarantees should I choose: at-most-once, at-least-once or exactly-once?
In most corporate integrations a practical default is **at-least-once**: no data loss, but duplicates are possible. The key question then becomes not how to eliminate duplicates, but how to make processing safe in their presence (idempotency, deduplication).
How to handle duplicate messages so business logic doesn’t break?
Duplicates occur because it's unclear at a failure point whether processing finished. The usual minimum is a unique message_id or business key, idempotent handler logic and recording the processing result in your database so repeats are detected and ignored.
What is a DLQ and when is it really needed?
A DLQ is for messages that can't be processed after a defined number of retries and pause intervals. At the start, agree on retry limits, the error format and who is responsible; otherwise DLQ becomes a "problem warehouse" that nobody inspects.
Why "exactly once" rarely solves everything and what to do instead?
Broker transactions and database transactions are different, and you usually cannot atomically commit a DB write and publish an event together. The most practical approach is outbox/inbox: persist the event next to business data, and publish it reliably later while protecting consumers from duplicates.
What metrics and alerts are mandatory for a broker in production?
Minimum metrics — lag (consumer lag), input/output throughput, share of publish/consume errors, retries and DLQ growth, disk usage and its growth for systems that persist messages. Tie metrics to the specific service and topic/queue to see which consumer is falling behind, not just that "something is red."
How to manage access and encryption in a broker without constant manual work?
Start with a separate account or certificate per service and grant rights only to required topics or queues. TLS is almost always a must; the usual pain point is cert rotation and revocation. Agree with InfoSec who issues certs, how they are rotated and how quickly you can replace a key without downtime.