Internal ACME for TLS Certificates: Offline Renewal
How to build an internal ACME for TLS certificates without internet: architecture, trust model, issuance and auto-renewal, lifetime monitoring and audit.
The problem: certificates expire and services stop
TLS certificates are almost always noticed at the last minute: users see a browser warning, an API starts returning errors, or VPN clients fail to connect. The reason is simple — manual renewal relies on calendars, attention, and access to the right systems. One missed expiration, one person on vacation, one forgotten intermediate link in the chain — and a service "breaks" not because of code, but because of trust.
The problem is sharper in isolated environments. "No internet access" usually means nodes cannot:
- contact public certificate authorities and their validation services;
- publish or update records in external DNS;
- accept incoming checks from outside;
- quickly apply updates and cloud-like tooling.
At the same time certificates are needed everywhere, and most visible and critical points suffer first: web portals and admin panels, APIs for integrations, mail servers, VPN gateways, authentication services and equipment admin UIs.
When there are dozens of such services, a manual scheme becomes a lottery: somewhere the certificate was renewed but the load balancer restart was forgotten; somewhere it was updated on only one cluster node; somewhere a certificate was issued with the wrong name. An internal ACME for TLS certificates doesn’t just make the process prettier — it achieves four practical goals: continuity of service, unified issuance control, predictable scheduled renewal, and audit (who requested what, when, and under what justification).
ACME in brief: roles and ownership validation logic
ACME is a protocol that enables automatic issuance and renewal of TLS certificates according to clear rules. Simply put, there are three roles: the client (an agent on your server), the ACME server (the endpoint that accepts requests), and the certificate authority (CA) that ultimately signs the certificate. The client requests a certificate, the ACME server issues a challenge to prove ownership, the client proves control over the name, and then the CA issues the certificate.
The key difference between ACME and a "script that copies certificates" is that ACME ties issuance to domain-ownership validation and to the client account. The protocol also defines the full lifecycle: request, validation, issuance, renewal, revocation. This reduces the risk of silent misissuance and helps keep the process under control.
Common challenge types are:
- HTTP-01: place a token over HTTP on the domain (convenient if there is a reachable web endpoint).
- DNS-01: create a TXT record in DNS (often the most practical option within segmented networks).
- TLS-ALPN-01: present a token over TLS on port 443 (useful when a temporary TLS response is easy to provide).
In closed contours DNS-01 usually wins: you don't need to open HTTP access to each service, only manage internal DNS records.
Where keys are stored depends on policy. Often the key is generated and kept on the application server (where rotation also happens). For stricter requirements the key can be generated and stored in an HSM or secrets store to reduce leakage risk and limit admin access.
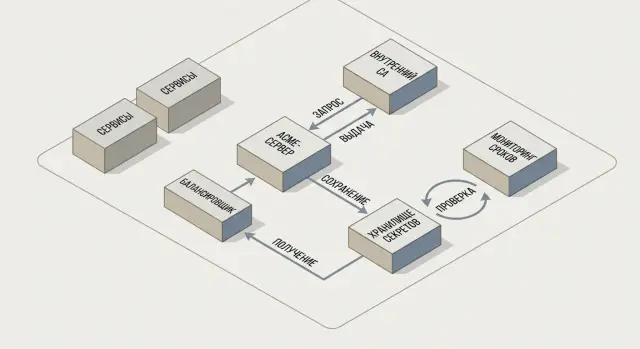
Architecture: components of an internal ACME contour
An internal ACME for TLS certificates is typically built as a small contour inside the network: a dedicated service issues and renews certificates while applications only request and install them on their endpoints. This removes manual issuance while keeping centralized control.
Basic components include:
- ACME server on the local network: accepts issuance requests, runs ownership validation, and returns the issued certificate.
- Private certificate authority (CA): the root certificate is kept highly isolated and issuance is done by an intermediate CA.
- DNS and DHCP: help maintain name-to-IP order, and DNS is often used for domain validation.
- Secrets store: securely holds ACME account keys, automation tokens, and, if needed, DNS access keys.
- Integration points: where certificates are actually needed.
Splitting the CA into a root and intermediate is important: if an intermediate key is leaked, you can revoke and reissue just that intermediate without rebuilding trust across the entire organization. The root is best kept offline or in a tightly restricted segment.
DNS and DHCP become part of the trust model: anyone who can create records could pass validation and obtain certificates. Therefore, zone permissions, update privileges, and change logs must be clear and restricted.
Integrations are usually done through standard ACME clients and automated configuration reloads, for example for:
- web servers and APIs
- load balancers
- Kubernetes ingress
- reverse proxies
- mail and internal portals
In closed contours (for instance in government or bank data centers) this approach helps keep certificate lifetimes short without internet dependence.
Trust and control: how not to turn an internal CA into a 'printing press'
An internal ACME removes manual work but introduces a risk: if issuance rules are weak, any service could get a certificate for someone else's name. So the focus should be on trust and control rather than speed.
Start with a simple principle: the root CA must be as inaccessible as possible. Keep it offline, power it on only to issue or rotate intermediates, and restrict access to a small group of administrators with an established procedure. A locked safe, an isolated machine without network access, audit logs and two-person control for critical operations often provide more security than elaborate solutions.
The workhorse is the intermediate CA. It signs certificates for ACME, has a shorter lifetime (for example 1–3 years) and is easier to revoke in an incident. Plan rotation in advance: issue a replacement intermediate, update trust on clients, then decommission the old one.
Distribute trust in a controlled way: deploy the internal root to PCs and servers via domain policies, to mobile devices via MDM, and to thin clients via a base image or centralized configuration. Pay special attention to medical and industrial devices that may receive updates rarely.
Policies that keep the system under control
A good issuance policy usually answers five questions:
- Who is allowed to request issuance (groups, service accounts, network segments).
- Which names are permitted: your internal DNS zone list only, forbidding external domains.
- Whether wildcards are allowed and under what conditions (usually restrictive).
- Which SANs are permitted (for example, only within a particular project or department).
- Maximum lifetimes and reissue frequency to avoid creating "eternal" certificates.
Audit: what must remain in the trail
Logs should show the chain of events: who requested a certificate, which validation method was used, what was issued (CN/SAN, validity period, fingerprint), and who approved it if manual approval exists. In closed networks (e.g., government or bank customers) this helps answer "why did this service get a certificate?" and stop incorrect requests quickly.
How to validate domains internally: DNS, HTTP and segmentation specifics
An internal ACME depends on one thing: how to prove that a service actually controls a name when the network is isolated and access rules are strict. DNS-01 typically wins inside the contour because it doesn't require direct HTTP access to the service and works well across segments.
DNS-01 is the standard option: the ACME client places a temporary TXT record in your internal DNS zone, and the ACME server verifies it via corporate DNS. This works well when you have many services, load balancers, NAT and closed ports.
HTTP-01 is possible in an isolated contour but more finicky. It's suitable when the ACME server can reach the specific host and validation path over HTTP and routing/proxies don't alter the request. It becomes problematic if there are many services behind a single reverse proxy, floating addresses, or if ACME-to-DMZ access is blocked.
A useful decision tree looks like:
- DNS-01: best choice for closed networks, DMZs, load balancers and wildcards
- HTTP-01: simpler for single services with a direct route and stable URL
- Wildcard: convenient for microservices but requires strict issuance controls
Wildcard certificates (for example, for *.corp.local) reduce the number of issues but reduce control precision: one key can cover many names. Therefore wildcards are generally granted only to platform teams and only for specific zones.
Segmentation matters: set different policies for DMZ and internal zones (who may request, which domains, and allowed lifetimes). Good practice is to use separate ACME accounts and issuance profiles for networks with different risk levels.
To avoid a renewal "storm," introduce limits:
- rate limits per domain and per team
- jitter (random shift) in renewal schedules
- mass-issuance locks triggered by DNS failures
- mandatory approval for wildcards in sensitive zones
For example, in a hospital network, DMZ services validate names via DNS-01, while internal admin panels get a separate zone and stricter limits so a single automation failure won't stop the entire infrastructure.
Deployment options without internet: fully offline and semi-offline
For internal ACME deployments you typically choose one of two modes: fully offline, where the entire contour lives inside the closed network, or semi-offline, where a tightly controlled "bridge" brings updates and policies in.
Fully offline
In this mode the perimeter contains: the private root (and usually an intermediate), the ACME server, the ACME database, DNS (for DNS-01), and clients on services (e.g., Certbot or built-in ACME clients in proxies). No external checks, no public DNS queries, and no reliance on external repositories.
Main advantage — predictability and security. Main downside — you must manage updates and fixes yourself on a schedule.
Semi-offline with a "bridge"
Here the issuance contour stays isolated but a dedicated node or process periodically brings inside: OS and package updates, new ACME versions, revocation lists, configuration templates and policy changes. This "bridge" should be effectively one-way: it imports into the contour but does not publish outward.
Apply updates in maintenance windows and first on a staging environment. Don't change CA, ACME and clients at once: that makes root-cause analysis harder.
For backups decide in advance what is restored quickly and what is reissued:
- CA and ACME configs, policies, certificate profiles
- ACME database (accounts, orders, statuses)
- audit logs and issuance/revocation events
- DNS and HTTP challenge configurations (if managed internally)
- key stores only in protected form (HSM, encrypted backups)
The recovery plan should include at least three scenarios: intermediate key leakage, ACME node compromise, accidental mass issuance. For each case define who orders revocation, how CRL/OCSP is propagated internally, and how forced reissuance for critical services is organized (for instance in a corporate closed network or a data center serviced by integrators like GSE.kz under SLA).
Step-by-step: how to roll out internal ACME and enable auto-renewal
Start with a simple decision: which names you will issue and how long certificates should live. Fix domain zones (for example, *.corp.local, *.svc.intra), the list of critical services, and rules: lifetime, minimum time-before-renewal, key requirements (RSA or ECDSA), and where keys will be stored.
Next, build the trust chain. Create a root CA (preferably kept offline) and an intermediate CA for day-to-day issuance. In policies define allowed names, required fields, who can request certificates, and how you will revoke them if compromised.
When your CA is ready, deploy the internal ACME: an ACME server on the local network that accepts client requests, validates control of names and issues certificates via your intermediate CA. Also plan logging and audit: who requested, for which name, and from which host.
A practical rollout plan usually looks like:
- Document domain zones, naming standards and lifetime requirements.
- Deploy root and intermediate CAs and approve issuance policies.
- Deploy ACME server and connect it to the intermediate CA.
- Configure DNS automation for DNS-01: which service updates records and under which account.
- Configure ACME clients on application servers and safe service reloads after updates.
Finish with a test: issue a certificate for a non-public service, verify the trust chain on clients, then wait for a scheduled renewal (or shorten the test certificate lifetime) and ensure the update proceeds without downtime. After that enable regular renewal for other services in groups, starting with less critical ones.
Lifetime control: monitoring, alerts and reporting
Auto-renewal does not remove the need for oversight. Internal ACME reduces manual work but adds a new task: spotting failures in the chain (ACME server, challenge, issuance, delivery, service reload) before a certificate expires.
Key metrics to display on a single screen:
- Days until expiration per name (and separately for critical services)
- Percentage of successful renewals in the last 24 hours and 7 days
- Common failure reasons: DNS/HTTP challenge, ACME unavailability, permission errors
- Certificate ages and share of those renewed off-schedule
- Time from request to installation on the node
Monitor in two places. Centrally — to see the overall picture across segments. And locally on nodes — to catch cases where a certificate was issued but not applied (file not updated, service not reloaded, wrong path to store).
Set alerts with simple thresholds: 30/14/7/1 day before expiration. At 30 days notify the service owner; at 7 and 1 days notify the on-call team and DNS/proxy owners to avoid time lost on approvals.
For post-incident analysis keep logs: issuance and revocation events, challenge attempts, DNS record changes, web server and load balancer restarts. Monthly audits should list active certificates, where they’re installed, owners, and names that are no longer needed. This reduces the risk of the internal CA becoming an uncontrolled "issue-everything" factory.
Common mistakes and pitfalls with internal ACME
People often implement an internal ACME "as on the internet" and are then surprised it becomes even more dangerous. Below are frequent mistakes and why they hurt security and stability.
Mistakes that break manageability
The most common trap is issuing overly long-lived certificates "just in case." It seems to reduce outages, but it actually reduces control: a compromised key becomes a multi-year problem instead of weeks.
Another extreme is using one wildcard for everything. It’s convenient until a private key leaks: then the whole contour is at risk and you can’t limit damage by segments or teams.
Problems also stem from trust distribution: giving the root CA to "whoever needs it" without considering laptops, isolated workstations, and temporary contractors. The result is inconsistent trust (some services fail) and overly broad trust (increased risk of spoofing).
Mistakes in storage and operation
Technically the ACME server may run fine, but surrounding processes lag:
- private keys end up in shared folders, build artifacts or CI logs
- there is no revocation and rapid replacement plan for compromises
- auto-renewal is enabled but it wasn't verified that services reload certificates (a reload or restart is required)
A simple example: a certificate was updated at night but in the morning some clients still see the old, expired chain because the proxy didn’t reload files. Therefore auto-renewal should always be followed by a reload test and a verification that the service actually presents the new certificate.
Short checklist before going live
Before turning on auto-renewal in production, check not only the ACME server but also organizational aspects. Failures are usually not cryptographic but that nobody knows where certificates live and who is responsible.
5 checks that save weeks
- Inventory all TLS endpoints: web and API, reverse proxies, ingress, message brokers, databases, mail, internal panels. Anything missed will be the first to fail.
- Define domain owners and issuance rules: which names are allowed, who may request wildcards, and which teams or service accounts can issue certificates.
- Separate CA roles: keep the root CA isolated (use it rarely), make intermediate CAs rotatable with short lifetimes and minimal privileges. Ensure keys are protected and the replacement process is clear.
- Pick one primary challenge and automate it until it’s routine. In closed networks DNS challenge usually wins, but verify zone-change privileges, propagation delays and segmentation between ACME, DNS and clients.
- Configure lifetime control: metrics, alerts, reports, plus a test of emergency renewal (e.g., shorten a test certificate lifetime to confirm the renewal chain works).
Documentation and emergency actions
Document the revocation and emergency replacement process: who decides, how quickly trust stores update, and how to roll back if a new certificate isn’t accepted by clients. This must be clear to the on-call team, not just the implementer.
Example scenario: a closed network with dozens of internal services
Imagine a bank or hospital with a closed contour: internet access from application servers is forbidden, access exists only inside internal segments, and downtime is unacceptable. Dozens of services run inside: registration, personal accounts, document workflow, integration APIs, admin panels.
Names usually live in internal DNS. Often there are separate zones for apps and infrastructure to avoid mixing server and user names: for example, apps.corp for web services and infra.corp for infrastructure. This helps set access policies and control who may change records.
An internal ACME is then deployed. The contour runs a private CA and an ACME server on the local network, and each service runs an ACME client. For validation they choose DNS-01: the client creates a temporary TXT record in internal DNS, the ACME server verifies it and issues a certificate.
A typical process looks like:
- The ACME client checks expiry once a day and triggers renewal early.
- On success it places the new certificate in the designated directory.
- The service (for example, a web server) performs a soft reload to pick up keys without downtime.
Lifetime control is done via a monitoring dashboard showing certificates expiring in 30, 14 and 7 days. Alerts go to on-call staff, and a short report is generated monthly for InfoSec and system owners.
For the team this reduces night-time certificate incidents, fewer manual requests, and more predictability. In such setups CA and ACME servers are often hosted on dedicated local machines (for example in a rack at the data center) so everything runs reliably without external channels. GSE.kz may be engaged as an integrator under SLA to help design and host such infrastructure.
Next steps: pilot, scaling and support
Start not by installing ACME but by taking inventory. List services already using TLS and those planning to enable HTTPS in the near term. Assign owners: who controls domains, DNS, load balancers and who will receive alerts.
Then choose the target model: fully offline (everything inside) or semi-offline (controlled synchronization of policies and updates). This decision affects migration planning: where to store the root key, how to update trust on workstations and servers, and how to issue certificates for legacy apps.
Before a pilot ensure the infrastructure is ready for daily operations:
- Role separation: CA, ACME and monitoring should not be colocated without reason
- Backups: keys, configs, logs, issued certificate database
- Observability: issuance metrics, validation errors, request growth
- Access control: least privilege for service accounts, auditable actions
- Emergency plan: steps for key compromise or ACME failure
Run the pilot on 2–3 services with different characteristics: one web service behind a load balancer, one internal API, and one service in a separate segment. This reveals DNS, routing and policy issues faster. Record how long issuance, renewal and rollout take and who actually participates.
Scale in waves: by domain zones or by owning teams. For each wave prepare policy templates (lifetime, SANs, allowed keys, naming rules) and acceptance criteria: auto-renewal works, monitoring sees lifetimes, and incidents are traceable by logs.
If you need help designing and implementing, consider engaging a systems integrator. GSE.kz can assist in building a tailored contour, selecting server hardware for CA and ACME (including locally sourced servers), configuring monitoring and organizing 24/7 support with clear responsibilities.