Cisco ACI or traditional VLAN network: when a fabric is needed
Cisco ACI or a traditional VLAN network: signs that a fabric is justified and operational risks to consider before deployment.
Where the choice actually starts: what problem really hurts
The debate about Cisco ACI versus “classic VLAN” often starts with technologies but comes down to something else: how fast you need to make changes and who is responsible for them.
Usually ACI enters the conversation after repeated incidents. For example, an application "breaks" after a planned change because a rule was updated on one switch and forgotten on another. Or an outage takes hours to resolve: it’s unclear where configurations diverged and the team inspects dozens of devices one by one.
Another common pain is inconsistent rules and exceptions. As the network grew over years, “special” VLANs, manual ACLs, temporary workarounds and different standards across shifts appear. Change velocity drops and the risk of mistakes rises.
Before comparing solutions, it helps to write down what you actually want to improve. Frame the problem in terms of time, risk and accountability, not brands or protocols.
To avoid the debate becoming “whose technology is better,” gather answers to several questions in advance (from both business and IT): which changes happen most often and how long do they take from request to result; how many incidents per year were related to network changes and how long recovery took; who owns access rules between systems (network, security, application owners); what matters more in the 12–18 month horizon — speed of launching new services or minimal changes to the current model; what constraints do audit, segmentation and logging impose.
If answers are vague, the argument will almost certainly become a matter of taste. It’s far more productive to first agree on a target operational model: who approves policies, who implements them, and who bears responsibility for outcomes.
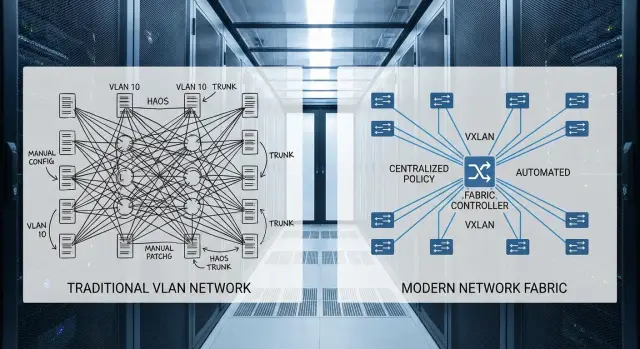
VLAN and ACI in simple terms: how the approaches differ
A traditional VLAN network is usually built on a familiar pattern: access, distribution, core. An admin creates VLANs, configures trunks, sets up SVIs and routing, adds ACLs, enables STP and ensures no loops appear. Adding a new service often requires touching multiple devices and then lengthy checks to ensure neighboring segments weren’t affected.
Cisco ACI is a different approach. The network is built as a fabric and management centers around a unified policy model. Instead of asking “which VLAN on which port,” you describe intent: which groups of systems should communicate and under what rules. The APIC controller stores the model and the fabric switches enforce it.
It’s important not to confuse abstractions with reality: VLANs, VXLAN, L2/L3 don’t disappear. You just work more often at the model and policy level rather than making manual edits on each device.
Where ACI usually helps: when there are many changes, many tenants, a need for isolation and “same everywhere” rules, and when you must spin up new segments and policies quickly and predictably.
Where ACI can add complexity: if the team is used to "CLI on every switch" and isn’t ready for objects and dependencies; if there’s no discipline in naming and lifecycle of objects; if you need ad-hoc logic that in classic setups was a couple of commands but in ACI requires a careful model; if operations aren’t ready for dependence on a controller and stricter change management.
Expectations are often overstated: “ACI will do everything automatically,” “troubleshooting will become simpler,” “you can skip L2/L3 knowledge.” In reality, basic networking fundamentals remain essential, and the fabric’s “magic” works only with careful design and a clear operational model.
When a traditional VLAN network remains a sensible choice
A classic VLAN-based network is often the best solution not because ACI is "worse," but because the tasks are simple and predictable. Start by honestly answering: how many changes do you perform and how much manual work actually hurts?
If there are few segments and new rules and connections appear rarely, the familiar VLAN/VRF/static routing or IGP pattern gives a predictable total cost of ownership. Especially when changes are counted in single digits per month, not dozens per week.
Another strong argument for VLAN is a mature team and orderly operations. When engineers know the network well, documentation isn’t only in one person’s head, and changes follow clear control, the risk of error is lower. In that case, adding a fabric may introduce more new processes and failure points than practical benefit.
Classic design also makes sense when strict micro-segmentation is not required. If a few zones (office, server room, guests, separate DMZ) suffice and audit does not require detailed app-to-app policies, traditional ACLs and firewall zones often cover the needs.
Finally, stability matters. When services rarely change, there are no frequent integrations, container platforms, or regular new app launches, policy automation in a fabric may simply not pay off.
A quick test that VLAN is sufficient: changes are rare and planned in advance; there are few segments and predictable growth; micro-segmentation is not required by compliance; documentation is current and there’s a standard change procedure; most incidents are not caused by manual configuration errors.
Example: a medium office with a small server room where a new department is added once a quarter and occasional new services are connected. In such a situation it’s often better to invest in order (diagrams, config templates, change control) rather than complicate the architecture for infrequent needs.
Signs that a fabric (ACI) will be useful
If you repeatedly ask whether to choose ACI or a classic VLAN network for the data center, it usually means the network has outgrown a “configure once and live” model. Fabric becomes valuable where the main risk is human error and uncoordinated changes rather than hardware.
Signals that it’s time to consider ACI
Common symptoms repeat:
The first — there are too many changes. New VLANs, VRFs, ACLs and rules for load balancers and firewalls appear every week, and manual edits start to drift between racks and sites.
The second — provisioning new environments is a bottleneck. Test, prod and DR should be brought up quickly, but approvals and settings take days because of dependence on specific ports and switches.
The third — segmentation requirements become stricter. Security and audit demands arise: service isolation, micro-segmentation, control of east-west traffic. “A couple of ACLs at the border” no longer cover the risk.
The fourth — identical configuration is needed across locations. Branches, backup sites or a second DC should follow the same rules, while copying “like last time” produces different results.
The fifth — virtualization and data center workloads become central. It becomes more important to describe who can talk to whom than to remember which port a particular server is plugged into.
Imagine an average data center: a virtualization cluster, several application teams and regular releases. In the VLAN approach every new app–DB–queue pair adds ports, VLANs, rules and exceptions. After a year no one is sure what can be removed without downtime. In ACI it’s easier to rely on policies: you declare intent (which groups communicate and how) and the fabric ensures it’s consistent everywhere.
If you identify with 2–3 of these points, it’s worth estimating the operational model in advance: who will own policies, who is responsible for templates, and how you validate changes before deployment.
What changes in operations: people, processes, responsibility
The main difference for operations is not hardware but habits. In a VLAN network the day often begins with “which port on which switch to touch.” In ACI you manage policies more: who can talk to whom, which services are available, and what the security and quality requirements are.
Roles shift accordingly. A single network engineer less often “fixes everything alone”: they must coordinate more with virtualization and security teams and sometimes with application teams. A good sign is having a single owner for changes who can gather stakeholders and make decisions instead of “passing the ball.”
Approval processes also change. A policy change can affect dozens of services at once, raising the cost of mistakes. Yet with the right approach it becomes easier to make repeatable changes and recover faster after failures.
Before launch, describe at least the basics: who owns policies and who approves them; how a request is filed (what counts as a minimally sufficient service description: addresses, ports, dependencies); how emergency response works (where to check status, who triggers a “stop changes” mode, how to rollback); how changes are tracked and basic pre-prod checks (templates, test environment); who owns fabric boundaries (connection to external networks, internet, firewalls).
In practice this means ACI demands a clearer operational model. If infrastructure is supported by an external 24/7 team, it’s useful to document these rules before start so technology does not outrun people and processes. In Kazakhstan this work is often done by system integrators that provide operations, such as GSE.kz, who design not only the topology but also change and incident handling procedures.
Step-by-step: how to assess readiness and make a decision
Choose between ACI and VLAN based on facts, not marketing or engineer preference. The plan below helps determine whether fabric will bring real benefits for you and where staying classic is fine.
Practical assessment plan
-
Inventory applications and traffic. Which systems communicate, which ports and protocols are needed, and where are critical dependencies (DBs, message buses, AD).
-
Quantify current problems. How long does a typical network change take, how many manual steps, how many incidents per month, downtime due to config errors, and how often do you rollback.
-
Record segmentation and logging requirements. Which security zones are needed (prod, test, contractors, medical equipment), who must see logs, retention periods, and which checks apply (internal audit, regulator).
-
Choose an architectural variant and pilot boundaries. For example, one rack row, one virtualization cluster or a set of 5–10 applications with frequent changes. Decide what stays classic (WAN, campus, some DMZs) and where a fabric is justified.
-
Create a migration plan and success criteria. Predefine metrics: reduced change time, fewer incidents, policy transparency, speed of creating new segments, logging quality. Document rollback procedures and responsibilities for each stage.
A small example: in a typical hospital data center the usual pain points are slow approvals and segmentation between departments and contractors. If metrics show changes are slow and fragile, an ACI pilot on one contour will give an honest answer.
If you need a neutral assessment and a pilot tailored to your constraints, an experienced integrator is valuable. GSE.kz, for example, has systems integration and 24/7 support experience, which helps define criteria, migration steps and ongoing operations.
A realistic example: an organization with a medium data center
Imagine an organization in Kazakhstan with two sites: a primary data center at headquarters and a backup site in another city. They run critical services: mail, ERP, several databases, virtualization, and VDI for staff. Infrastructure is split between teams: network, servers, security and application admins, each with their own maintenance windows and priorities.
The network was built on VLANs. While changes were few, it worked. As demands grew, typical symptoms emerged: segments multiplied, inter-segment access rules became long, and any service addition required approvals and manual edits on multiple devices. A single mistake could make an application unavailable on one site or for some users, and tracing the cause took hours.
Against this background the choice between ACI and the classic model becomes practical: will it speed changes and reduce risk?
A fabric pilot is usually not “move everything at once” but a limited slice where approaches can be safely compared. Commonly chosen is a new service contour (test environments or a non-critical business service), a few racks and hypervisor clusters, basic access policies between 3–5 segments, mirrored logs and a clear escalation route among teams.
Before the pilot the team records simple metrics and then compares them afterwards. Typical measurements are time for a standard change (e.g., allow an app to access a DB), share of changes with rollback and reasons, number of post-change incidents per month, total downtime of critical network services, and time to localize the problem to a clear hypothesis (not to full fix).
If after the pilot changes are faster with fewer rollbacks and troubleshooting is shorter and more predictable, that supports fabric. If gains are minimal, the root cause is often process: teams haven’t agreed on policies and responsibilities.
Operational risks of ACI and how to mitigate them
ACI is often chosen after fatigue with manual edits and sprawling VLANs. But remember: you change not only hardware but the whole way you manage the network. This model has its own operational risks.
Where ACI most often "hurts"
The most visible risk is dependence on policy quality. The issue usually isn’t "controller down" but a careless change that affects many segments. In classic setups errors tend to be more localized.
Second risk — skills and diagnostics. On-call staff find it harder to "touch a cable and a VLAN" when network behavior is defined by chains of objects and dependencies. As a result, incidents can take longer to resolve even if the root cause is simple.
Third risk — a poor segmentation model. If EPGs, contracts and filters are shallowly thought-out, you end up with unexpected blocks: an app is "partially alive," monitoring looks green, but some functions don’t work.
Fourth risk — overcomplicating the design from the start. A common mistake is trying to automate everything at once: security, micro-segmentation, integrations and full self-service. That raises the chance of errors and makes support harder.
Practical risk reduction
Discipline helps and solves half the problems.
Train not only project engineers but also the on-call team: basic objects, common symptoms, where to check status. Build a lab or test zone and run changes via templates rather than manual tinkering. Agree naming conventions, a library of standard policies and boundaries of responsibility (network, security, servers). Enforce procedures: change window, mandatory checks, measurable rollback plan. Start with the minimally sufficient segmentation model and add complexity only for real requirements.
If you have external 24/7 support, agree on a runbook: which incidents the on-call covers and which must be escalated. This noticeably shortens time to a clear hypothesis and reduces chaos in the first months. For example, GSE.kz typically helps define responsibility boundaries and escalation rules before production handover.
Typical mistakes during implementation and migration
The most common mistake is buying ACI as a "fashionable upgrade" without answering what exactly should improve and how you will measure it. Without goals like "reduce network provisioning time for a new service from 3 days to 3 hours" or "cut incidents from manual edits," the project becomes a perpetual debate.
The second mistake is migrating the entire data center at once. When design, access policies and tools change together, small issues derail timelines and stability. A limited pilot — one application type, one segment, clear owners and success criteria — is more reliable. The pilot clarifies what works and what needs tuning.
Another problem is mixing responsibilities. ACI touches network, security and virtualization at once; without rules this causes conflicts: who approves policies, who keeps the change log, who investigates incidents. Assign domain owners and agree the change process before migration start.
Emergency mode plan
Emergency procedures and manual workarounds are often forgotten. Operations will see anything: a policy mistake, an unexpected bug, human error. You must document how to quickly isolate and restore connectivity: which "stop buttons" exist, who has rights, and what actions are allowed without lengthy approvals.
Finally, plan time to document applications and flows. To make safe policies that don’t break services you must know which systems talk and on which ports. Without that policies are guessed and exceptions accumulate. A practical approach is to map flows for 2–3 critical apps first, then move them into the fabric.
A short checklist before choosing VLAN or ACI
The choice almost always boils down to readiness to manage the network as a set of rules. Go through these questions and record answers in one document.
Do you understand which applications and services communicate (at least at the level: front, backend, DB, external integrations)? If not, any segmentation will be either too loose or will break traffic.
Is there a clear owner of the segmentation model: who approves policies and who can change them? Without this, ACI quickly becomes "nobody touches anything."
Are logging and observability requirements agreed: what to log, retention, who watches alerts and the expected response time?
Is there a clear change process: request, validation, change window, rollback, and accountability if an app fails after a change?
Have you agreed what matters more: speed of change or maximum predictability, and how you will measure it?
Then decide where it’s safe to try the new model. Do you need a test bench or a low-risk pilot: one or two racks, several typical applications, a documented failure scenario and a rollback plan to "how it was"?
When VLAN is definitely enough
If checklist answers are confident, often fabric isn’t necessary. VLAN fits when changes are few and there’s no queue of segmentation requests; the network is small and problems are solved quickly without complex automation; isolation needs are simple (a few zones, minimal exceptions); and the team isn’t ready to change the operational model and take on policy management.
If you have many microservices, frequent changes and strict segmentation needs, a pilot helps assess cost and benefit before a big migration. If needed, a system integrator like GSE.kz can help formalize policy and observability requirements so operations aren’t a surprise.
Next steps: pilot, migration plan and who to contact
If you’re undecided, don’t resolve the debate by preference. Test 2–3 scenarios where speed and control matter: deliver a new DMZ service in hours, not a week; strict segmentation for medical systems; quick policy rollback during an incident.
A mini-plan that usually brings clarity
Start with a small pilot and agree how you will measure success. This reduces the risk of "we deployed it and nobody can operate it."
Pick 2–3 application cases and describe which network changes must be made, by whom and how quickly. Gather security and audit requirements: who can change what, which logs are needed, which zones are off-limits. Record the current network state and site constraints: links, racks, power, maintenance windows. Prepare training: minimum for on-call engineers and separate training for policy designers and incident handlers. Design the pilot and migration model (phased, with rollback points), then test it in a lab or isolated segment.
After the pilot, decide the operational model without delay. ACI changes responsibilities: who owns policies, who approves templates, who is on duty and what counts as a change.
Who to contact if you need a partner
If you don’t have a team ready to handle design, deployment and 24/7 support, pick an integrator that covers the full cycle: design, migration, operations and training.
For data centers, also check server compatibility with the target architecture. In Kazakhstan this often includes hardware supply and support together with the project. For example, GSE.kz as a manufacturer and systems integrator can help with architecture, server supply (including the S200 Series) and nationwide support.
FAQ
Where is it best to start when choosing between Cisco ACI and a regular VLAN network?
Start with the problem, not the technology: how long does a typical change take, how many incidents are caused by network edits, and who is responsible for access between systems. If changes are rare and the network is predictable, a well-managed VLAN model with proper change control is usually enough. If changes are frequent and often break due to configuration drift, a policy-driven fabric typically brings more value.
When is a traditional VLAN network the most reasonable option?
VLANs are usually the better choice when there are few segments, changes are infrequent, and the team reliably maintains the network: documentation is up to date, standards exist, and there is a clear approval process. In such cases, adding ACI can introduce more processes and dependencies than actual acceleration.
What signs indicate that ACI will actually be useful?
You will recognize several signs: many weekly edits, constant disputes between teams over access rules, tightening segmentation requirements, and the need to maintain identical settings across multiple sites. ACI is especially useful where the main risk is human error and uncoordinated changes rather than hardware failure.
What is the simple difference between VLAN and ACI approaches?
With VLANs you think in devices and ports: which VLAN is on which port, which trunk, where an SVI is configured and which ACLs apply. With ACI you think in policies: which groups of systems can talk and under what rules, while the fabric switches enforce that model. L2/L3 and encapsulations like VXLAN remain—they just get managed more often at the model/policy level rather than via manual per-device edits.
Which expectations about ACI are usually exaggerated?
Expecting ACI to "do everything automatically" or believing troubleshooting will always be simpler are common misconceptions. Basic networking knowledge remains essential, and a policy mistake can affect many services at once. A realistic expectation: with good design and disciplined change management you get repeatability, uniform rules across the fabric, and less configuration drift.
What needs to be decided about people and processes before deploying ACI?
At minimum — an owner of policies and a clear change process: who approves rules, who implements them, how you verify before production and how you rollback. Also agree in advance what constitutes a "sufficient description of a service" for an access request; without that, policies will be created "by eye". Without these agreements, ACI often turns into a situation where everyone is afraid to touch anything.
What are the most common operational risks of ACI and how to reduce them?
The main risk is policy quality and impact: a single edit can affect dozens of segments at once. Another risk is harder diagnostics for on-call teams that don’t know ACI objects and dependencies. Mitigations include operator training, a test bench or staging area to run changes through templates rather than manual edits, common naming conventions, and a pre-defined rollback and emergency plan.
What is the safest way to migrate: the whole data center at once or step by step?
Don't try to "migrate the whole data center at once": when design, access policies, and tools change simultaneously, small issues often break timelines and stability. It's better to run a limited pilot: one application type or segment with clear owners and success criteria. The pilot shows what works and what needs tuning.
How to tell from a pilot whether ACI pays off for us?
Keep the pilot narrow and measurable: pick one cluster or several applications that frequently need changes and define the before/after metrics. Useful metrics are time to perform a typical change, share of changes that required rollback, number of post-change incidents, and time to localize the cause. If metrics don't improve, the issue is usually process and policy agreement rather than the technology itself.
Can ACI and a classic VLAN network be combined in the same infrastructure?
Yes. It's common to use fabric for the data center while keeping WAN, campus, or some DMZs on traditional VLANs if that's simpler and cheaper to operate. The important thing is to define clear boundaries where the fabric ends and external networks and firewalls begin so there is no "gray area" of responsibility. In Kazakhstan such boundaries are often formalized together with an integrator who then provides 24/7 support; GSE.kz, as a systems integrator, typically helps document change and escalation procedures alongside the technical design.