API management for government integrations: Kong, Apigee, Azure API Management, Tyk
API management for government integrations: compare Kong, Apigee, Azure API Management and Tyk on limits, keys, auditing, versioning, developer portal and failure handling.
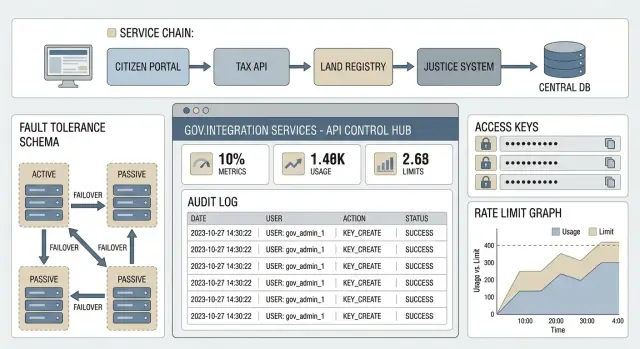
Why government integrations need a separate API management layer
In interagency integrations the API itself rarely breaks — it's the "small things" around it. One consumer starts calling an endpoint ten times more often due to a scheduling bug, another sends nonstandard headers, a third forgets to renew a certificate. As a result everyone suffers: queues grow, the service responds slowly, and the API owner looks guilty.
A dedicated API management layer is needed to catch these problems early and mitigate them before they become incidents. It becomes a single entry point: controlling access, limiting load, recording who called what, and helping roll out changes without chaos.
WAFs or regular proxies don't cover the key tasks. A WAF blocks common attacks but usually doesn't solve API contract issues: quotas per key, different rules for different consumers, publishing documentation, version management, or a unified error policy. A proxy can forward requests, but without centralized rules it quickly turns into a set of manual exceptions.
There are usually three parties: the API owner (an agency or registry operator), consumers (other agencies, front offices, contractors, integrators) and the infrastructure operator (data center, cloud, integration perimeter). Each side needs something different: owners need control and transparency, consumers need clear access and stable rules, operators need manageability and predictable load.
Regulations and audits typically require straightforward but strict controls: identifying every consumer (keys, certificates, roles) without shared accounts; limits and quotas so one client can't take the service down for others; logging of calls and admin actions with storage and search for incidents; version management and planned replacement of old methods without stopping services; a clear access issuance procedure and a single source of documentation.
Example: an agency opens an API to a registry for five systems. Without a management layer you negotiate limits by email and investigate incidents "in app logs." With API management the rules become explicit and verifiable: who called, how often, by which version, and what happened when an external dependency failed.
Brief overview of Kong, Apigee, Azure API Management and Tyk
API management for government integrations is a set of functions around APIs that help publish services securely, grant access to external consumers, control load and collect traces for audits. In practice it's not just a gateway but also access policies, logging, analytics, a developer portal and version management.
Kong and Tyk are often chosen as lighter, more flexible platforms: they can be deployed in your own perimeter, adapted faster to common architectures and integrated with existing auth systems. Apigee and Azure API Management are often seen as a "full stack," with more out-of-the-box policies, API lifecycle management, analytics and tools for teams serving many consumers.
Cloud or your own perimeter
In government environments the hosting decision often dictates everything. Cloud is more convenient operationally, but approvals, data localization requirements and access rules can make on-premise the default.
On-premise is usually easier to explain to auditors: where components are located, who the administrator is, how backups and logs are organized. Cloud wins when rapid API launch and scaling are priorities. In that case agree in advance which data can be exported, how to store logs and who can change settings.
What makes up the "management layer"
A minimally useful set typically includes an API gateway (single entry point, routing, rate limits, basic security policies), a developer portal (documentation, access requests, keys, test environments), analytics and logs (who called, when, with what result, where errors occurred), and a set of policies (validation, transformations, protection against common attacks, version control).
A lightweight solution is enough when you have 1–2 integrations, predictable load and a simple access model (e.g., key + IP). In that case it’s more important to quickly deploy a gateway and limits.
A full stack is needed when there are dozens of consumers (agencies, contractors, regions), strict audit requirements, many API versions, separate sandboxes and a clear access process. In such projects a system integrator usually helps design a target architecture tailored to the customer's requirements and deploy it in a trusted perimeter, including local infrastructure and 24/7 support.
Rate limits and quotas: protect the perimeter without breaking services
In government integrations the API management layer is not only a gateway but a safety valve. Without limits one faulty consumer or a bad release can clog the channel, overload the backend and take others down.
Set limits at multiple levels: by key (token or API key), by IP or subnet, by application (client_id), by method or route (for example, treat /search and /download separately), and by time window (minute, hour, day).
Distinguish between burst and sustained. Burst protects against short spikes (e.g., retries after a timeout), while sustained keeps the average load normal (for example, 200 requests per minute continuously). If you enable only burst, the backend will "boil" under prolonged queueing. If you enable only sustained, you may penalize legitimate short peaks at the start of the day.
Quotas should usually differ by environment: prod, test, pilot. They are often further split by agency and role. Example: for a pilot one consumer might get 50 requests per minute and 10,000 per day, while a critical production service gets higher quotas but stricter rules for expensive operations.
When a limit triggers, the rejection must be clear and auditable. Log and, where appropriate, reflect in the response: who exceeded (key, application, IP), which route and method, which limit fired (burst or sustained and the time window), the counter value and threshold, and a correlation id for the request to help incident analysis. That makes it easier for the consumer to accept the reason ("quota exceeded for /search in the test environment") and for your support to prove the perimeter protected the system rather than "failing."
Keys and access: a practical authentication scheme
In government integrations access is usually checked not only by "who" but also by who exactly is calling the method, from where, and which operations are allowed. Choose a scheme that is easy to operate and strict enough for audits.
What to choose: API key, OAuth2, mTLS, JWT
API key fits basic scenarios with a fixed set of consumer systems when you need to quickly enable access control and limits. The downside is keys tend to live long and can leak if storage discipline is poor.
OAuth2 is convenient when there are many consumers, roles and a need for managed token lifecycles. In practice OAuth2 is often used with JWT so the gateway can validate rights and expirations quickly without constant backend calls.
mTLS (mutual TLS by certificates) works well for inter-system communication in a closed perimeter. It provides a strong signal of trust: a client certificate is required to connect. A common pattern is mTLS to answer "who and where are you?" and OAuth2/JWT to answer "what are you allowed to do?"
If you want to avoid complexity, typical guidance is: for server-to-server in a closed network — mTLS + short-lived JWT; for many consumers and roles — OAuth2/JWT; for temporary integrations or simple read access — API key, but with strict limits and regular rotation.
Rotation and lifetimes: avoid stopping integrations
A frequent cause of sudden outages is expired keys or certificates. Rotate without downtime: issue the new key ahead of time, keep an overlap period when both are valid, then disable the old one. For OAuth2 use short-lived access tokens and longer refresh tokens; for mTLS maintain a renewal calendar for certificates.
Separate privileges by operation, not with a single "one key for everything" approach. A minimal role set: read (GET/reference), write (create/update), admin operations (directory management, bulk actions), and technical access (diagnostics, time-limited).
Secret storage must be regulated: do not keep keys and private certificates in email, chats or documents. Grant access only to those who operate the integration, by request and with logging. Practices that pass audits well: a dedicated secrets vault, role-based issuance and periodic checks of "who has access and why."
Audit and logging: what auditors check and how to prepare
For government integrations logging is not just "look at errors" but provable evidence: who called the API, what was requested, why a call was denied, and who changed gateway settings. In API management projects this is often audited as strictly as database access.
Define a minimum set of events up front. Auditors usually expect logs to contain request events (success and failure), technical errors (4xx/5xx), quota breaches, and any configuration changes: policies, routes, keys, certificates, roles, IP rules.
To avoid manual detective work, enable request correlation across the chain. A simple approach: one request-id flows through the gateway, services and queues and appears in logs of all components. Then you can quickly reconstruct the sequence "consumer -> gateway -> service -> external system" and see where the fault occurred. Agree in advance who creates the id (often the gateway) and how it is passed (e.g., a header).
Log retention typically has two requirements: duration and tamper protection. Retention periods come from regulators and internal rules — usually months rather than days. Protection is implemented via separation of duties (who writes, who reads, who deletes), immutable storage (WORM or equivalent) and sending copies to centralized monitoring/SIEM. If logs contain personal or sensitive data, also record "who viewed the logs."
Prepare report templates auditors request most often: a registry of consumers and rights (which keys/clients have access to which methods), usage and error statistics, a configuration change log with initiator and approval (ticket/request), and incident extracts with full request-id traces and recovery times.
Example: an external consumer reports "missing responses" when calling a registry. With a request-id you can see within minutes that the gateway received the request, a downstream integration service timed out, and that same day someone changed retry policies. Without correlation and change logs this often becomes a week-long dispute about where the problem was.
Versioning APIs without conflicts or downtime
Versioning in government integrations prevents new features from breaking existing services. The same API serves different consumers: legacy agency systems, new mobile apps, contractors. If an update changes field formats or validation rules suddenly, integrations and business processes fail.
Versions in URLs or headers
A version in the URL (for example, /v1/) is easier to support and diagnose. It’s visible in logs, simple to route to different backends, and many teams find it easier to coordinate. The downside is URLs spread into consumer code and documentation, so migration requires releases on each side.
Versioning via headers (Accept or a dedicated X-API-Version) touches routes less and can be more convenient for evolution. But headers are more likely to be lost in incident investigations: not all proxies preserve them and not all logs capture them fully. Account for this.
The main rule: wherever the version is, it must be unambiguous, validated at the gateway and recorded in logs.
Backward compatibility is the best way to avoid widespread failures. When changing a field, it’s often safer to add a new one and support both rather than rename in-place. Define a support window for old versions (for example, 6–12 months) and do not break it without a critical reason.
A deprecation policy should be formal: mark deprecated methods in documentation and in responses (for example, a Deprecation header), notify consumers in advance, set a migration window, monitor usage metrics by key and client, restrict new registrations to the current version and retire the old one according to plan.
To test a new version without affecting production, use parallel deployment: a separate route for v2, isolated quotas and keys, and "shadow" comparisons of responses on a portion of traffic (without impacting end users). In Kong, Apigee, Azure API Management and Tyk this is usually handled by routing rules, limits and gateway-level logging.
Developer portal: fewer emails, more transparency
A developer portal is where API consumers find answers and get access without long email chains. For government integrations this is especially important: many participants, strict control, and constant changes. A well-designed portal reduces errors and speeds up approvals while preserving manageability.
A practical minimum that actually works: clear documentation (methods, parameters, error codes, examples), a specification (for example, OpenAPI) with documentation versioned alongside the API, a sandbox with safe data and clear restrictions, self-service key management (issue, rotate, revoke, view quotas), and a status/incidents page.
Onboarding should be short and measurable. First the consumer chooses the API and access scenario, then confirms organization and contact person, and receives minimal test rights. Full access is granted after verification: who owns the integration, where the key is stored, which IPs/nets are used, required quotas and who is responsible for logging on the consumer side.
To avoid surprise changes, release discipline is needed. The portal should contain compatibility rules (what is a breaking change), a supported versions calendar and release notes in plain language: what changed, who is affected, what needs to be done and by when. A useful format is a one-paragraph summary for managers and a separate technical block for developers.
Example: when integrating with a government registry one consumer uses only search while another does bulk export. On the portal these can be two access profiles with different quotas and method sets, and keys are issued separately. Support receives fewer routine questions because answers are in docs, examples and status updates.
If you implement API management, start with the portal: it’s the most visible layer for consumers. In system integration projects involving companies like GSE.kz (gse.kz), the portal often becomes a quality checkpoint: it quickly reveals outdated documentation, poorly set quotas and overly complex access processes.
Failure scenarios and graceful degradation: don’t fall with your dependencies
In government integrations an external registry, bus or agency system can become a bottleneck. Problems rarely look like "everything crashed" — more often latency grows, partial responses appear, 500s spike and request queues pull the whole system down. Plan failure scenarios in advance: what to do on slow responses, temporary unavailability and degraded data quality.
Timeouts, retries and circuit breakers
The first rule: timeouts must be bounded and understood by all parties. If the gateway timeout is 30 seconds and the client uses 5 seconds, you get extra retries and "zombie" requests.
Helpful baseline settings:
- Timeouts: short for reference reads, slightly longer for operations that allow processing.
- Retries: only for safe operations (GET), with pause and jitter, and with a limit on attempts.
- Circuit breaker: after a series of errors or rising latency the gateway (and client) temporarily short-circuit the dependency to avoid drowning the whole perimeter.
- Parallelism limits: so a failing dependency cannot consume all worker threads.
Roles should be separated: the gateway protects the perimeter and stabilizes traffic, and clients must handle errors correctly and avoid hammering dependencies indefinitely.
Caching and degradation plan
Caching is especially useful for reference data (region codes, statuses, static lists). It is acceptable only if you fix the freshness window and understand the risk. A good practice is to mark responses served from cache and include the last update timestamp.
A degradation plan should state simple rules:
- If the registry is unavailable, return the last valid cached response for reference data (up to N hours).
- For critical checks, return a clear error and a retry scenario instead of "empty."
- For noncritical fields (address, optional attributes) return a partial response and clearly mark the incompleteness.
Also plan geo-redundancy and environment separation: test traffic, reporting and bulk checks must not live in the same corridor as production public services. In system integration projects this is often implemented as independent perimeters with different quotas, keys and failure rules so a local outage doesn't become widespread.
Example scenario: connecting a registry with different consumers
Imagine a single registry (for example, a license registry) used by three agencies. Agency A performs bulk checks. Agency B works from a front office where response time matters. Agency C connects an analytics layer and makes infrequent but heavy requests. Each has different SLAs and you must prevent one consumer from throttling the registry during peaks.
Here the API management layer acts as a dispatcher: it accepts requests, applies access policies and limits, writes audit trails and provides clear reports to each party.
How to separate access, keys and quotas
A practical approach is to create three distinct products (or access plans) and three sets of credentials. Then keys and quotas do not mix and settings remain transparent.
For example:
- Agency A: 200 requests/sec, strict response size limit and mandatory field filtering.
- Agency B: 50 requests/sec, latency-priority, short timeout and clear error codes for operators.
- Agency C: 10 requests/sec, permitted heavy methods only on schedule or with a separate time-based quota.
Issue keys separately (API key or OAuth2 client credentials) and add mTLS or request signing for sensitive methods. Each key should be tied to a specific consumer, environment (test/prod) and method set.
Audit and reports that satisfy everyone
Build audit around "who, what, when, from where and with what result." Logs should include consumer identifier, method, path, response code, time, size and correlation ID to reconstruct the chain. Decide in advance what to mask for personal data and what to store only in protected storage.
Reports should provide slices: per-agency dashboards (successes/errors/peaks) and an overall report for the registry owner (load, availability, quota breaches).
Moving to a new API version without downtime
If you must add fields or change formats, run v1 and v2 in parallel. First publish v2 on the developer portal with examples, schedules and test keys. Route pilot traffic to v2 (for example, only Agency C), include warnings in v1 responses about retirement schedules, set separate limits for v1 and v2, then move v1 to read-only and retire it per plan.
This way, with different consumer maturity you don't stop receiving requests and you keep changes manageable.
Step-by-step rollout plan and next actions
If you need API management for government integrations, start with a plan rather than a product choice. Then Kong, Apigee, Azure API Management or Tyk solve concrete problems instead of standing "for show."
5 steps that usually give predictable results
-
Gather requirements: which environments participate (internal, interagency, internet), SLA expectations for availability and latency, security and audit checks. Agree up front how long logs are kept, who can access them and how fast the incident chain can be reconstructed.
-
Choose a hosting model and identify single points of failure. For government integrations this is often hybrid: some components inside the perimeter, some in a dedicated zone. Check what happens if an external dependency, database, DNS, link or certificate authority is unavailable.
-
Describe policies as "service rules," not vendor-specific settings. Minimum set: limits and quotas per consumer, key issuance and rotation, API version requirements, mandatory log fields, masking of personal data, error and timeout rules.
-
Run a pilot on one real scenario. For example, one registry and two consumer types: an internal service with a high quota and an external contractor with a strict quota. A pilot helps verify that developers understand how to get access and that security knows how to investigate incidents.
-
After the pilot lock down operations: procedures, RACI matrix, update schedule, rollback procedures, templates for publishing new versions and approvals. Add load tests and checks that new policies do not break legacy consumers.
Next actions are usually simple: pick 1–2 critical integrations for a pilot, agree on logging and audit formats, assign an API owner (decision authority), and only then compare platforms by cost and usability.
If you need a partner to deliver infrastructure and integration in a single project, consider system integrators experienced in building trusted perimeters and providing 24/7 operations. For example, GSE.kz (gse.kz) provides system integration, data center solutions and 24/7 support across Kazakhstan.
FAQ
Why do government integrations need a separate API management layer?
Because most failures happen not in the API itself but around it: excessive calls caused by a consumer's scheduling bug, nonstandard headers, expired certificates, endless retries. An API management layer intercepts such issues at the gateway, limits damage and provides transparency about who caused an incident.
How is API management different from a WAF or a plain proxy?
A WAF primarily blocks common attacks, but it usually doesn't handle API contract concerns: quotas per key, different policies for different consumers, versioning, uniform error handling and a developer portal. A simple proxy just forwards traffic and without centralized policies quickly becomes a set of manual exceptions.
What does the "API management layer" include in practice?
A minimally useful set includes a single entry point (gateway) for routing, rate limits and basic security, plus logs and analytics to investigate incidents. Typically you then add a developer portal for documentation and access issuance, and policies for validation, transformations and version control.
What is better for government: cloud or on-premise?
On-premise is often chosen because of data localization, administrative control and the ease of explaining component locations and logs to auditors. Cloud is convenient when you need to launch APIs quickly and scale, but you must agree in advance which data and logs can leave the perimeter and who can access settings.
How to set rate limits and quotas so one consumer won't "take down" everyone?
Set limits across multiple dimensions: by key or client_id, by IP/subnet, by method or route and by time window (minute, hour, day). Separate burst and sustained limits: burst handles short spikes, sustained keeps average load in check. Together they protect the backend and the queue more effectively.
What should happen when a limit is hit?
Rejections should be clear and verifiable: log which consumer exceeded the limit, which method and route, which time window and which counter triggered. If appropriate, include an error code and brief reason in the response and a correlation identifier so support can quickly trace the event chain.
What is best for access: API key, OAuth2/JWT or mTLS?
For closed server-to-server interactions mTLS is a strong way to verify "who" connected, while OAuth2/JWT is convenient for assigning rights and token lifecycles. API key is acceptable for simple or temporary cases but requires strict limits and regular rotation so a key does not become a permanent shared credential.
How to avoid outages from expired keys and certificates?
Rotate without downtime: issue the new key or certificate in advance, keep an overlap period when both old and new work, then retire the old one. Maintain a certificate renewal calendar and separate privileges by operation so compromise of one credential doesn't grant full access.
What do auditors usually expect to see in the logs?
Auditors typically look for provable records: who called the API, what was requested, why a call failed, and who changed gateway settings or policies. Practical minimum — log requests (successes and failures), 4xx/5xx errors, quota breaches and all configuration changes, and carry a request-id through the gateway and services for fast correlation.
How is it better to version APIs: in the URL or in headers?
Version in the URL (e.g., /v1/) is simpler for support and troubleshooting because it’s visible in logs and easy to route to different backends, but migration requires updating each consumer. Versioning via headers touches routes less but headers are more likely to be dropped by intermediaries, so ensure the gateway validates the version and writes it to logs.