Air-gapped LLM with no internet: reference architecture
How to build an LLM in an air-gapped network with no internet: model repository, offline updates, dependency control, SBOMs, and package scanning.
The task in plain words: an LLM with no internet and no surprises
An LLM in an air-gapped network means the model, the data, and all software required to run it operate entirely inside your network and do not reach out for answers, updates, or “small” things like pulling libraries. Organizations choose this approach when confidentiality, supply-chain control, and clear operational rules matter.
Working with LLMs is more complex than with ordinary applications because, in addition to code, you have a heavy artifact (the model weights), a dependency chain (drivers, CPU/GPU libraries, Python packages, container images), and many tools that habitually “fetch” what they need from the internet during runtime. In a closed network any such attempt becomes a failure or, worse, a policy bypass.
There are three common groups of risks. First—data exfiltration: prompts, documents, logs, or metadata may accidentally be sent to external services. Second—malicious packages and artifact tampering: one compromised component in the supply chain can open the contour. Third—uncontrolled updates: when a model, library, or container changes “by itself” and the result suddenly differs from expectations.
More roles are involved here than people often expect. InfoSec defines isolation, validation, and admission rules for artifacts. IT is responsible for infrastructure, accounts, backups, and support. Procurement and compliance review licenses, provenance, and vendor status. Data owners decide what can be given to the model and how to store content.
Success is measured not only by answer quality. It’s important that the system be predictable (changes scheduled), verifiable (you know exactly what’s running), and reproducible (builds and runs can be repeated exactly). Then the LLM becomes a manageable service rather than a “black box” operating by its own rules.
Requirements and boundaries: what to lock down before design
Before drawing an architecture, agree the rules of the game. In an air-gapped contour, “small” things like logs, updates, and privileges quickly become either risks or operational bottlenecks.
Start with data classes: which documents the model may see, which must never be uploaded to the contour, and which are allowed only in anonymized form. Separately define exfiltration prohibitions: what counts as a leak (text outputs, embeddings, request metadata, document fragments in logs) and where the line between “internal” and “external” lies.
Next—logging and traceability. You need clear answers to: who ran the model, which version, on which dataset, what changes were made, and who approved them. Define upfront what is logged, retention periods, who can access logs, and how logs are protected from tampering.
Define the isolation level. The contour can be fully offline or allow rare, controlled “windows” for updates. This affects everything: from patching processes to choice of replication tools.
Practical constraints matter too: available hardware (CPU, GPU, disks, network), acceptable downtime, and maximum allowable time to deliver a model or package update. If your server fleet is fixed (common in government), design for the real configuration, not for “ideal” capacity.
Acceptance criteria from InfoSec are easiest to keep as a short checklist:
- approved data classes and anonymization rules
- version control of models and dependencies with audit trails
- logging policy and retention periods
- offline update process with pre-deployment checks
- vulnerability scan results and remediation plan
With these boundaries recorded, the reference architecture design stops being a debate about “what’s convenient” and becomes a task of “how to meet requirements without workarounds.”
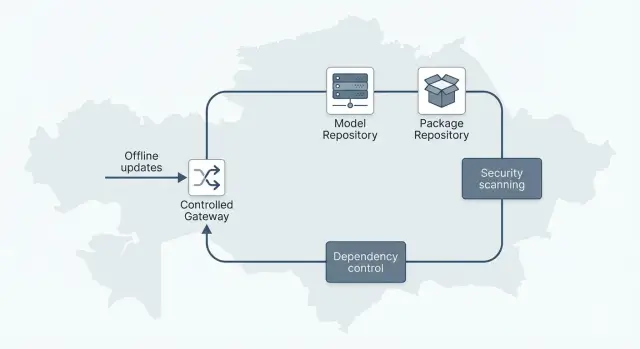
Reference architecture: contour components
To make an LLM predictable in an air-gapped setting, build the contour as a pipeline. Each part has a role, and each version has an owner and a changelog. That way you always know what’s running, where it came from, and who approved it.
Core components of the contour
Usually five supporting components suffice. They can be separate systems or functions of a single platform, but the logic must hold:
- compute layer: GPU/CPU nodes for inference and, if needed, fine-tuning
- artifact storage: models, tokenizers, datasets, container images, weights, prompt templates
- dependency control: pinned library and environment versions, plus an SBOM for each delivery
- scanning: vulnerability and prohibited-component checks for packages and images before runtime
- orchestration and access: service deployment, quotas, audit, secrets, roles and permissions
Flows and control points
A key principle is a single source of truth for versions. One registry (or an agreed set of registries) stores approved artifacts, and only artifacts from it are allowed to run.
A typical delivery flow: an external team produces a package (model + dependencies + SBOM), it enters a quarantine zone, passes scanning and policy checks, then the responsible party approves the release. Only then are artifacts promoted to the offline repository and made available for testing and production.
Environment separation is important even without internet: sandbox for experiments, test for reproducible runs and load checks, production for stable operation. Promote only approved versions between environments—no manual copying.
Explicitly ban implicit fetches. On startup, services must not auto-pull models, plugins, or packages. Any external call must be explicit, toggleable, and recorded in audit logs.
Model repository: storage, versions, and access control
In an air-gapped contour the model repository is the single source of truth. It must store not only weights but everything needed to reproduce and validate the model safely. In an offline environment you cannot “quickly download a missing file,” so release completeness is critical.
A practical rule: one model = one release bundle that can be redeployed to produce the same results.
A release typically includes: model weights (sharded if needed), tokenizer and vocabulary, runtime and inference configs (parameters, limits, context size), license and model card (source and usage restrictions), reference prompts, and a small regression test suite.
Versioning is easiest when strict and readable: tags like model-name:vX.Y.Z, an immutable build identifier (hash), and a signature. That way any production run can be tied to a specific artifact and proven unchanged.
Access controls should follow roles. Many teams may read (e.g., integration teams), only the build pipeline publishes, and product owners with InfoSec approve releases. In tightly regulated environments (common in government, banking, healthcare) this approval flow quickly pays off.
Also plan for quantized and optimized variants. Store them as derived artifacts with clear labels (int8, int4, gguf, etc.) and the same quality tests. This prevents situations where a “speed-optimized” model silently breaks critical queries.
Dependency control: reproducible builds
In an offline contour the main threat is not only data leaks but also that a build done today differs from a build tomorrow. That breaks tests, complicates investigations, and turns updates into a lottery.
First step—maintain local package mirrors and forbid direct external downloads. Mirror only what you actually use: Python packages, system packages (rpm/deb), container images, and large artifacts (models, tokenizers). Forbid all “dynamic” sources: installs from git branches, the “latest” tag, and runtime downloads during builds. If a component cannot be fetched from your mirror, it should not be promoted to prod.
Pinning versions is not a formality. Keep lock files (for Python and containers) and enforce reproducible builds: the same specification should yield identical files. In practice, verify this in CI by building twice and comparing hashes of key artifacts.
Store the SBOM with the release as part of the delivery. Include application dependencies (packages and versions), base images and system libraries, ML artifacts (model, tokenizer, their hashes), and build tools that affect the result.
Vendor-in some components when justified: prebuild local wheels or freeze dependencies into a bundle if packages frequently disappear or require complex offline compilation. This increases your responsibility for updates, so apply it selectively.
One more practical rule: separate dev and prod dependencies (separate repositories or at least separate lock files). That way testing utilities and “convenience” libraries don’t end up in the production contour.
Scanning packages and artifacts: gatekeeping before runtime
In a closed contour the main risk is not an external breach but that a suspicious component slips in and you find out too late. Make scanning a mandatory stage of delivery, not a one-off check.
Scan more than Python packages. Vulnerabilities may hide in a base image, a system library, or a “benign” utility alongside the model. Minimum scanning should cover:
- packages and dependencies (pip/conda/apt), including transitive ones
- container images and base layers
- OS images and system libraries (OpenSSL, glibc, etc.)
- model artifacts: weights, tokenizer, configs, inference scripts
- build files and metadata: lock files, manifests, SBOM
Timing matters. A good practice is multiple quality gates: on import to the isolated repository (initial filtering), before marking an artifact as “trusted,” and before deploying to prod (final check that nothing changed).
Blocking policies should be simple and enforceable: ban critical vulnerabilities with no exceptions, do not allow unsigned artifacts, reject components with unknown provenance or missing hashes. Store scan results as part of the “release passport”: report, date, tool and rules used, plus hash/signature and link to the model or image tag.
Exceptions are inevitable but must be neutralized by process: who approves them (InfoSec + service owner), for how long (short), and what compensations apply (isolation, disabled features, monitoring). In system integration practice, including projects by GSE.kz (gse.kz), this is often formalized as a controlled window until the next offline update so the risk does not become permanent.
Offline updates: safely bringing new artifacts inside
In an air-gapped contour updates are a controlled delivery, not “download and install.” The most common mistake is moving files informally: someone brings a model on a USB drive or an archive of packages, and a month later no one remembers exactly what was installed.
Start with one official transfer channel: either a physical medium tracked and sealed, or a dedicated exchange point (for example, a gateway in a demilitarized zone). In all cases the update must have an owner and a log: what was changed, when, from where, and who approved it.
On entry to the contour validate more than “viruses”—check the full set of properties that make the system predictable:
- vendor signature and signature of your internal build
- checksums (hashes) of each artifact: model, tokenizer, configs
- compliance with version and environment policies (what is allowed in this environment)
- SBOM and dependency list for the inference environment
- vulnerability scan results for packages and containers
Then set a rhythm. Regular update windows (e.g., monthly) prevent backlog. For emergency patches create a separate fast path with pre-agreed criteria.
Before production rollout validate the update on staging with the same hardware and drivers used in production. Run a short regression on your representative queries and compatibility tests (drivers, libraries, model format).
Keep a simple rollback plan: store the previous model and environment, switch via versioning and atomic tag changes, and measure rollback time in minutes, not days.
Minimizing outbound calls: keeping the contour closed
Air-gapped contours fail not from large integrations but from small things: a library sends telemetry, a container tries to update, a runtime checks a license. The rule is simple: deny outbound traffic by default, and every exception must be justified, auditable, and easy to disable.
Eliminate implicit network calls
Inventory everything that likes to “phone home”: auto-updaters, metrics collectors, crash reporters, subscription checks, font and tokenizer downloads. These calls often hide in SDK settings and are enabled by default.
Practical measures:
- deny outbound connections at the network layer (egress deny) for pods/VMs running the LLM
- enforce offline flags and environment variables for libraries (telemetry, updates, cache)
- local mirrors for everything needed at startup: models, packages, containers, documentation
- a central proxy as the only allowed exit point if external access is absolutely required
- mandatory request for each external access: purpose, domain, duration, owner
Check behavior and detect anomalies quickly
At some point a team will add a dependency that tries to connect out. This must be caught before production. Add a “network silence” test: bring up the service in a test segment and verify there are no DNS queries or outbound connections except those explicitly allowed.
Example: a chatbot for an internal knowledge base suddenly makes external calls due to an analytics library. The test detects the attempts, the build is blocked, and the library is replaced with an internal tracking solution.
For investigations keep access logs. Log at minimum: time, source (service/node), destination (domain/IP/port), decision (allowed/blocked), and volume. Maintain quick searches for “new domains” and DNS spikes so you can identify changes and component owners within 10 minutes.
Step-by-step rollout plan: from pilot to production
Start with one or two measurable scenarios: internal document search, support answers, or draft generation for internal communications. Define which data is accessible to the model and which is forbidden, and segment users by access levels (e.g., staff, managers, admins).
Choose a base runtime platform and packaging approach. Containers simplify portability and version control, but in some air-gapped environments a minimal non-container install is more convenient. The key is deploying the same way in test and production.
Collect internal artifact sources: the model repository and the package repository. This removes dependence on external downloads and helps pin exact versions. In an isolated datacenter all models and Python packages must be obtained only from internal stores so servers receive identical artifacts.
Before scaling, document build rules: reproducibility, SBOMs, and artifact signing. This lets you prove what an image contains and avoids debates about “what exactly was installed.”
A typical production progression:
- Pilot on anonymized or non-public data with baseline quality metrics.
- Internal repositories for models and packages, strict access controls.
- Build from templates, SBOM, and signatures before publishing artifacts.
- Package and image scanning, blocking policies at ingress.
- Offline update procedure: delivery, signature checks, regression tests, then release.
A final touch: a regression test suite that detects “silent” breakages (answer quality, data leaks, latency) after each model or dependency update.
Example scenario: an LLM for an internal knowledge base
Imagine the methodology and compliance unit in a large organization. People search regulations, email templates, orders, and instructions, and draft notes: explanations, responses to requests, and internal notices. Internet access is forbidden because documents contain personal and confidential information. The goal is simple: find the right passage faster and produce a tidy draft without exposing data outside.
A typical flow:
- the model and all dependencies are delivered as a single package with versions and checksums
- the package is validated: vulnerability scanning, SBOM verification, license checks
- the model is run through short tests: answer quality on reference queries, checks for forbidden personal-data outputs, and latency
- after approval the release is recorded, deployed to prod, and monitoring is enabled
- in operation keep a log of queries and incidents to investigate disputed answers and improve prompts and the knowledge base
Updates are best scheduled, e.g., monthly: this simplifies planning for windows, tests, and rollback. Unscheduled updates are allowed only for critical vulnerabilities and must follow the same delivery pipeline.
Measure results not only by “likes” but by useful metrics: stability of answers on the same query set, average response latency, number of InfoSec incidents and false positives, and rollback time to the previous release if needed.
Common mistakes and costly traps
The most frequent cause of incidents in these projects is not the model but discipline around it. The contour may appear isolated, but build and update exceptions quickly create risks.
First trap—deploying to prod without pinned library versions and an SBOM. A month later you can’t reproduce the build, so you can’t prove that production matches what was tested.
Second—mixing dev and prod in the same environment. A developer installs a convenient debug package that pulls new dependencies; the “clean” contour starts changing. You’ll see differing hashes and discrepancies in latency and output quality.
Third—updating a model without regression tests or a rollback plan. Even a “minor” version can change response style, worsen performance on your documents, or start hallucinating on critical topics. In an air-gapped setting this is painful: plan rollback in advance rather than hunt for an old copy at the last minute.
Fourth—trusting artifacts without signatures and source verification. Accepting a container, Python package, or model “as is” effectively outsources trust. Require signature checks, hash verification, and a clear supply chain.
Fifth—undetected telemetry and hidden network calls. Many libraries try to send metrics, check licenses, or fetch updates. In an isolated segment this causes hangs, timeouts, and “invisible” outbound attempts.
Sixth—no owner for the update process. If it’s unclear who decides “can we update?”, updates either don’t happen for a long time or happen chaotically.
A useful pre-prod checklist:
- pinned versions, SBOM, and reproducible build
- dev and prod separated, minimal access rights
- tests, update windows, and rollback plan
- artifacts signed and provenance documented
- all external calls blocked and monitored
Quick checklist and next steps
If the architecture is drafted, validate it with a short readiness list. This quickly shows where an “air-gapped contour” can start to drift.
Short readiness checklist:
- a single offline model repository: versions, hashes (integrity checks), clear access controls, and audit
- a mirror for code and libraries, lock files, and an SBOM for each release (for reproducible builds)
- all artifacts (models, containers, packages) scanned before promotion to production and given an “allowed” status
- updates follow a regimen: staging test, deployment window, clear rollback to the previous version
- no implicit external calls during build or runtime (telemetry, auto-updates, runtime downloads of tokenizers, fonts, models)
After that, process matters more than technology. Start with one pilot case (e.g., internal document search) and define what constitutes a “release”: model + config + prompts/templates + dependencies + test data. Assign roles and a changelog: who adds models to the repository, who approves scan results, who signs off deployment.
Next steps for 2–4 weeks:
- build a minimal delivery contour: repositories, scanning, signatures/hashes, update regulations
- perform a reference release and one safe rollback to validate the process
- run a dry incident drill: what to do if a vulnerability is found or a model misbehaves
If you build this contour for government or large enterprises, align InfoSec, infrastructure, and the product owner on delivery rules early. In system integration this often resolves half the issues before production. And if you also need reliable infrastructure and support for offline scenarios (servers, workstations, datacenter integration), local vendors and integrators such as GSE.kz (gse.kz) typically cover the full delivery and support cycle inside the country.