Zabbix мониторинг без подписок: шаблоны, триггеры, карты
Zabbix мониторинг без подписок: как настроить шаблоны, триггеры и карты, чтобы видеть риски сервисов и бизнеса, а не только аптайм.
Что не так с мониторингом «жив/мертв»
«Пинг есть» означает только одно: устройство отвечает на сеть. Но сам сервис может быть уже недоступен. Веб-портал не открывается из-за ошибки в приложении, база данных зависла, диск переполнен, сертификат истек, очередь сообщений встала, а пользователи все равно видят «не работает».
Такой мониторинг опасен тем, что он успокаивает. На дежурстве тишина, зеленые статусы, а бизнес теряет время и деньги. Еще хуже, когда уведомления приходят только в момент полного падения. Тогда команда узнает о проблеме слишком поздно: простой уже начался, сроки сорваны, клиенты жалуются.
Мониторинг должен отвечать не на вопрос «сервер жив?», а на вопрос «насколько мы близки к сбою и чем это грозит». В организациях с критичными сервисами (госуслуги, клиника, банк, учебный портал) важнее видеть риск для записи пациента, обработки платежа или выдачи справки, чем просто доступность хоста.
Хорошая проверка всегда привязана к действию пользователя. Если сайт открывается, но авторизация не проходит, для бизнеса это уже инцидент. Если резервное копирование перестало выполняться, это не авария прямо сейчас, но это высокий риск на завтра.
Мониторинг должен закрывать вопросы бизнеса:
- Работает ли ключевой сценарий пользователя (вход, поиск, оплата, запись)?
- Где именно порвалась цепочка (DNS, сеть, БД, приложение, внешний провайдер)?
- Сколько времени есть до отказа (место на диске, рост ошибок, нагрузка)?
- Какой сервис под риском и какой приоритет у инцидента?
- Кто должен реагировать и что проверить в первую минуту?
Все это можно собрать в Zabbix без подписок: шаблоны для типовых узлов, метрики по ОС и приложениям, триггеры, которые ловят деградацию, а не только «упал», плюс карты и сервисы, чтобы было видно, где риск и кого он затрагивает.
С чего начать: сервисы, зависимости и критичность
Если начать с хостов, быстро появятся сотни сигналов и мало понимания, что реально страдает у людей. Практичнее начинать с сервисов: что пользователь делает и где бизнес теряет деньги или доверие. Тогда мониторинг начинает работать как раннее предупреждение, а не как «пищалка».
Соберите короткую инвентаризацию не по оргструктуре, а по пользовательским сценариям. Часто хватает 30-60 минут разговора с владельцем процесса и ИТ: какие 3-5 действий человек должен выполнять каждый день, в какие окна времени это критично, что считается сбоем («медленно», «ошибка», «данные не обновились»), есть ли обходной путь и как долго он терпим, кто решает «это инцидент», а кто говорит «потерпите».
Дальше разложите сервис на зависимости. Это помогает не путать причину и следствие: «сайт недоступен» может оказаться проблемой DNS, канала, балансировщика, базы или внешнего провайдера.
Удобно рисовать цепочку сверху вниз: сервис -> приложение -> БД -> ОС/сервер -> сеть/питание, плюс внешние точки (SMS-шлюз, гос-сервисы, платежный провайдер). Позже это превращается в карты и бизнес-сервисы.
Затем задайте порог «больно» для бизнеса. Не «CPU 90%», а то, что заметит пользователь: время ответа, доля ошибок, число неуспешных транзакций, отставание очереди, потери пакетов. Например: «если вход в систему дольше 8 секунд больше 5 минут подряд, операторская смена начинает срываться».
И в конце договоритесь о критичности. Простая шкала P1-P3 и правило эскалации обычно хватает: P1 - деньги/безопасность/остановка процесса, P2 - деградация без остановки, P3 - неудобство. Эти договоренности станут основой для приоритетов и маршрутизации уведомлений.
Как устроены шаблоны Zabbix и как их планировать
Шаблон в Zabbix - это набор правил мониторинга, который можно «прикрепить» к десяткам и сотням хостов. Он задает стандарт: какие метрики снимаем, как понимаем сбой, что показываем на графиках и как отделяем важное от второстепенного. Без шаблонов настройка быстро превращается в ручную работу для каждого сервера и вечную путаницу.
Из чего состоит хороший шаблон
Обычно шаблон держится на нескольких элементах:
- Items снимают значения (нагрузка CPU, задержка ответа API, место на диске).
- Triggers переводят цифры в состояния (норма, предупреждение, проблема).
- Graphs показывают динамику.
- Discovery (LLD) автоматически находит повторяющиеся объекты: файловые системы, интерфейсы, базы, сервисы.
Планировать шаблон лучше не «по железу», а по роли. Отдельные шаблоны для веб-сервера, базы данных и балансировщика проще поддерживать, чем один огромный «на все случаи». Так легче менять пороги и не ломать мониторинг там, где он не нужен.
Макросы, окружения и порядок в названиях
Одна и та же логика должна работать в проде, тесте и в филиалах, но с разными порогами. Для этого используйте макросы. Например, один триггер «мало места на диске» берет значение из {$DISK.MIN.FREE} и получает разные цифры для prod и test.
Чтобы быстрее разбирать инциденты, договоритесь о простых правилах: единое именование метрик (что меряем, где, в каких единицах), тэги у триггеров (service=payments, layer=db, env=prod), понятные имена событий («Рост ошибок 5xx, риск недоступности сайта»), и разделение по важности (не все предупреждения должны будить ночью).
Если в компании много типовых площадок (офисы, больницы, школы, ЦОД), эти стандарты особенно полезны: одна модель мониторинга, а различия задаются макросами и тэгами, а не ручными правками.
Какие метрики собирать, чтобы видеть качество сервиса
Если собирать только «пинг» и загрузку CPU, вы увидите факт сбоя, но не поймете, как страдает сервис. Метрики должны отвечать на простой вопрос: пользователь сейчас может выполнить задачу или уже нет?
Начните с базового набора по ОС. Он нужен не ради графиков, а чтобы быстро отличить «серверу плохо» от «приложению плохо»: CPU (включая iowait), RAM (включая рост swap), диск (свободное место и задержки/очереди I/O), сеть (потери, ошибки интерфейса, утилизация канала), синхронизация времени (дрейф часов часто ломает аутентификацию и логи).
Дальше добавляйте метрики по роли сервера. Для гипервизора важны «шумные» VM и нехватка ресурсов на узле. Для файлового сервера - задержки диска и ошибки SMB/NFS. Для терминальных серверов - число активных сессий и время логина. Для AD - репликация, очереди и время ответа на LDAP/Kerberos.
Качество сервиса чаще ломается на уровне приложения и базы. Поэтому собирайте не только «процесс запущен», а то, что чувствует клиент: время ответа ключевого запроса, долю ошибок (5xx, timeouts), длину очередей, число подключений и блокировки в БД. Даже если базовые ресурсы в норме (например, на производительных стойках с серверами уровня GSE S200 Series), рост блокировок в БД уже означает риск для платежей, записи пациентов или выдачи справок.
Чтобы не утонуть в однотипных элементах, используйте LLD: автопоиск дисков, интерфейсов, файловых систем и сервисов. Шаблон сам подхватит новый диск или интерфейс и добавит контроль.
И держите 1-2 проверки «глазами пользователя»: открыть страницу логина, выполнить простой запрос, получить успешный ответ API. Это один из лучших индикаторов реального качества.
Пошагово: собрать первый «правильный» мониторинг в Zabbix
Чтобы Zabbix показывал не только «жив/мертв», начните с одного сервиса и доведите его до понятной картины рисков. Это почти всегда быстрее, чем пытаться сразу покрыть всю инфраструктуру.
Выберите сервис, который важен людям, а не железу: «корпоративная почта», «портал заявок», «электронная регистратура». Нарисуйте цепочку зависимостей: DNS -> балансировщик -> веб/приложение -> база данных -> хранилище -> сеть. В реальности часть звеньев будет на физических серверах, часть - на виртуализации, и именно связи между ними определяют, что считать инцидентом.
Соберите первый шаблон и примените его сразу к группе, а не к одному хосту. Это дисциплинирует: метрики, имена, тэги и пороги должны быть одинаковыми.
Рабочий порядок обычно такой:
- Описать сервис и его зависимости, отметить что критично, а что терпит деградацию.
- Сделать базовый шаблон: доступность, задержки, ключевые метрики ресурса и приложения, плюс тэги для фильтрации.
- Добавить LLD там, где объектов много (диски, интерфейсы, файловые системы), а пороги вынести в макросы.
- Проверить «чистоту» данных: единицы (ms, %, B/s), одинаковые интервалы, понятные имена.
- Собрать небольшой дашборд и включить уведомления только на то, что требует действий.
Перед тем как включать алерты на всю команду, проверьте качество сообщений. При реальной проблеме уведомление должно отвечать на три вопроса: что сломалось, как это влияет на сервис, что проверить первым. Например, падение одного интерфейса не всегда инцидент, а рост задержки до базы в часы нагрузки - уже риск для сервиса, даже если хост «жив».
Триггеры: как превратить метрики в понятные риски
Метрики сами по себе редко помогают в момент инцидента. «CPU 92%» или «ping вырос» не объясняют, есть ли риск для сервиса и что делать прямо сейчас. Триггеры в Zabbix переводят цифры в понятные события, а значит - в управляемые риски.
Главная боль - шум. Если алерт приходит каждые 5 минут и часто «сам проходит», команда быстро перестает реагировать.
Чтобы не было флаппинга, задавайте пороги с запасом и используйте гистерезис: разные условия для «плохо» и для «норма». Например: «диск заполнен > 90% в течение 10 минут» и «восстановление, когда стало < 85%». Так вы ловите тенденцию, а не разовый пик.
События полезно строить слоями: отдельно симптомы, отдельно причины. Тогда в ленте меньше каши, и источник находится быстрее.
Несколько правил, которые обычно работают:
- Делайте триггер только под действие (что вы будете делать, если он сработал).
- Добавляйте подтверждение по времени (5-15 минут) для «плавающих» метрик.
- Разделяйте «деградацию» и «отказ» (медленно vs недоступно).
- Для одной проблемы оставляйте один главный алерт, остальные - как диагностические.
- Пишите понятное имя события: что сломалось и какой риск для сервиса.
Сильный инструмент - зависимости триггеров. Если упала сеть или верхний коммутатор, не нужно получать сотни «хост недоступен». Настройте так, чтобы «проблема на узле связи» подавляла «недоступны серверы за ним». Это особенно важно при нескольких стойках или площадках.
Серьезность и тэги решают маршрутизацию: критичные события уходят дежурному, деградации - в очередь на разбор, а предупреждения остаются для плановых работ.
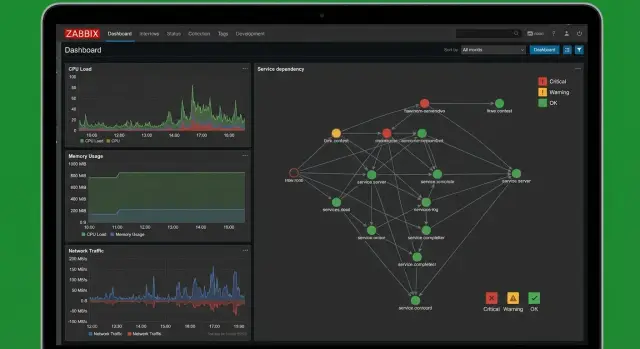
Карты, сервисы и дашборды: чтобы было видно бизнес-картину
Когда мониторинг показывает только «хост жив», он не отвечает на главный вопрос: что будет с услугой для пользователей. В Zabbix это решается связкой из карт, бизнес-сервисов и простых дашбордов. Тогда система говорит на языке риска: «сервис деградирует», а не «у сервера проблемы».
Карты: связи и узкие места
Инфраструктурная карта нужна не ради красоты. Она помогает быстро увидеть, где именно рвется цепочка: коммутатор, канал, кластер, конкретная стойка или сервисный контур.
Хорошая карта показывает связи по потоку: пользователь -> балансировщик -> веб -> база -> хранилище. Отдельно полезно отмечать общие точки отказа (например, один коммутатор на несколько сегментов). Тогда при инциденте видно, почему «упали сразу все».
Business service: статус сервиса из статусов компонентов
Бизнес-сервис в Zabbix собирается как дерево: наверху сервис (например, «Электронная приемная»), ниже компоненты (DNS, канал, веб, БД, очередь, сертификаты). Важно настроить не только down, но и деградацию: сервис может быть доступен, но медленный или частично сломан.
Помогает взвешивание: не все компоненты равны. Потеря одного из двух веб-узлов - это деградация, а не остановка. А истекающий TLS-сертификат через 3 дня - риск, который сегодня еще не «красный», но должен быть заметен.
Дашборды делайте под роль, иначе на них перестают смотреть:
- Дежурному - топ проблемных сервисов, текущие алерты, «что делать сейчас».
- Админу - утилизация, очереди, задержки, емкость, тренды.
- Руководителю - статус ключевых сервисов и время восстановления без технических деталей.
- Сервис-менеджеру - доступность по сервисам и причины простоев.
Отчеты по доступности полезны, но в них легко ошибиться. Не смешивайте «хост доступен» и «сервис работает для пользователя», плановые окна и реальные инциденты, отказы и деградацию, доступность и производительность.
Частые ошибки при настройке Zabbix
Чаще всего проблема не в нехватке функций, а в перегрузке: сотни проверок, десятки алертов в час, и в итоге никто не понимает, что реально сломалось и насколько это опасно.
Шум вместо сигнала
Одна крайность - включить слишком много проверок и поставить частоту опроса «на всякий случай» в 10-30 секунд. Это нагружает агент, сеть и сам Zabbix, но не дает пользы, если метрика не влияет на решения.
Другая крайность - опрашивать слишком редко. Если веб-сервис проверяется раз в 10 минут, пользователи заметят проблему раньше вас.
Еще один источник шума - одинаковые пороги для разных условий. Один и тот же уровень CPU, диска или задержки сети может быть нормой для сервера БД, но тревогой для офисного файлового сервера. То же самое с филиалами: для удаленной площадки «пинг 50 мс» бывает нормой, а для дата-центра это уже признак деградации.
Алерт есть, действий нет
Триггер без контекста выглядит как «Disk space low», и на этом все. Дежурный тратит время на поиск: какой раздел, что на нем, куда смотреть, кого звать.
Полезная привычка - делать алерты с понятной подсказкой: что это значит для сервиса, вероятные причины, первый шаг проверки. Например: какой сервис зависит от узла, где логи, кто контакт дежурной группы.
Часто забывают про зависимости, подавление и окна техработ. Тогда при падении канала приходит десятки алертов «умерло все», хотя причина одна. А во время плановых работ команда выгорает от ложных тревог.
Бывает и наоборот: метрики собирают «потому что можно», но пропускают ключевые для качества сервиса (время ответа, ошибки, заполнение очередей, доступность критичных портов). Простое правило: каждая метрика либо предупреждает о риске, либо помогает быстро найти причину.
Быстрый чеклист: готов ли мониторинг к реальным инцидентам
Мониторинг полезен только тогда, когда помогает принять решение за минуты: что сломалось, насколько это критично, кто реагирует и что будет, если ничего не делать.
Сначала убедитесь, что есть бизнес-картина, а не набор разрозненных хостов. Если упал один сервер, но сервис продолжает работать через резерв, дежурному не нужен «пожар».
Минимум, без которого инциденты будут повторяться
- У сервиса есть схема зависимостей и владелец (техлид, админ, подрядчик). Без владельца алерт становится «ничейным».
- Триггеры разделены по смыслу: причины (заполнен диск, очередь растет, I/O уперся) и симптомы (недоступен сайт, timeouts).
- Пороги деградации заданы заранее: не только «упало», но и «стало хуже» (ошибки, задержки, очередь, место на диске, время ответа). Желательно хотя бы два уровня: предупреждение и критично.
- Уведомления маршрутизируются по тегам: сервис, среда (prod/test), критичность, тип (security, storage, network).
- Есть два вида дашбордов: для дежурного (что делать сейчас) и для руководителя (какие сервисы под риском и почему).
Быстрые проверки «на живом»
Перед реальным ЧП сделайте небольшой тест:
- Запланируйте техработы и проверьте, что алерты подавляются, а после окна возвращаются.
- Проверьте защиту от флаппинга: краткие скачки не должны будить ночью.
- Сымитируйте деградацию (например, заполните тестовый диск или увеличьте latency) и посмотрите, поднимается ли «риск сервиса», а не просто краснеет хост.
Пример: как Zabbix показывает риск для сервиса, а не для хоста
Представьте госорган или банк: есть сервис приема заявок для граждан и отдельный кабинет сотрудника. Оба сервиса живут на одной инфраструктуре, но для бизнеса они разные. Если «все хосты пингуются», это еще не значит, что люди могут подать заявку.
Деградация обычно начинается тихо. Сайт открывается, но формы отправляются дольше обычного. Потом часть запросов начинает получать HTTP 500. В базе растет очередь, а пользователи звонят в поддержку. Здесь мониторинг полезен именно как инструмент управления риском, а не как лампочка.
Чтобы показать риск раньше падения, часто хватает связки метрик и триггеров, которые ловят ухудшение в правильном порядке: растет время ответа API (например, p95) 5-10 минут подряд, затем превышается порог по 5xx, параллельно растет очередь в БД или задержка репликации, а внизу проявляется техническая причина (I/O wait, CPU steal, заполнение диска).
Дальше важна подача. На карте вы видите не «сервер 1 красный», а «Прием заявок: высокий риск», и ниже зависимые узлы: API, БД, очередь, балансировщик. Проваливаетесь в события и видите, что сработало первым, что вторично, и где вероятная причина. Это экономит время: не нужно гадать, какой из десятка хостов «виноват».
С бизнесом в такие моменты лучше говорить просто: какой функционал недоступен (например, отправка заявок), сколько пользователей затронуто, что будет дальше (рост очереди и повторные ошибки), когда ждать восстановление. Даже грубый прогноз по тренду очереди и скорости обработки полезнее, чем «мы проверяем серверы».
Следующие шаги: как масштабировать и поддерживать мониторинг
Когда базовая схема уже показывает риски по сервису, следующий вопрос простой: как сделать так, чтобы через полгода все работало так же понятно, а не превратилось в набор случайных проверок.
Начните с пилота на одном сервисе, где есть владелец и понятная цена простоя: «электронная регистратура» в клинике или «платежный шлюз» в банке. Доведите там шаблоны, триггеры, зависимости и карту до состояния, когда дежурный за 30 секунд понимает: что сломалось, на кого влияет, что делать первым.
Потом тиражируйте подход, а не конфиги «как есть». Чтобы шаблоны жили долго, нужен стандарт и контроль изменений: версионирование шаблонов и короткие заметки «что и зачем поменяли», «золотой» набор отдельно от экспериментальных, единые правила именования, раз в месяц ревизия (что шумит, что не используется, где нет владельца).
Отдельно подумайте о масштабе. Если несколько филиалов, много сетевого оборудования, разный парк ОС и требуется реакция 24/7, логично подключать интегратора.
Свяжите мониторинг с емкостным планированием. Не ограничивайтесь алертами «заканчивается диск». Смотрите тренды по CPU, памяти, IOPS, очередям, росту баз данных и пиковым часам. Тогда решение «добавить ресурсы» появляется заранее, а не ночью во время инцидента.
Если инфраструктура тоже на вашей ответственности, проще, когда мониторинг, серверная база и поддержка согласованы между собой. В таких случаях производитель и системный интегратор вроде GSE.kz (gse.kz) может помочь с типовыми аппаратными платформами и интеграцией, а также с поддержкой по регламенту, не вмешиваясь в вашу логику мониторинга сервисов.
FAQ
Почему «пинг есть» не значит, что сервис работает?
«Пинг есть» показывает только, что хост отвечает по сети. Сервис при этом может быть недоступен из‑за ошибок приложения, зависшей базы, переполненного диска, истекшего сертификата или остановившейся очереди. Надежнее проверять то, что делает пользователь: вход, запрос, оплату, запись, получение ответа API.
С чего лучше начать настройку мониторинга в Zabbix, чтобы было меньше хаоса?
Начните с одного самого важного пользовательского сценария и договоритесь, что считается сбоем для бизнеса: медленно, ошибки, данные не обновились. Затем разложите сервис на зависимости (DNS, сеть, балансировщик, приложение, БД, хранилище, внешние провайдеры) и только после этого добавляйте метрики и алерты. Такой порядок сразу показывает, где риск, а не просто «что-то красное».
Зачем нужны шаблоны Zabbix и как их правильно разбить?
Шаблон задает стандарт мониторинга и позволяет быстро применить одинаковые элементы к десяткам хостов. Хороший подход — делать шаблоны по роли (веб, БД, балансировщик), а не один «на всё», чтобы проще менять пороги и не ломать лишнее. В итоге вы получаете одинаковые имена метрик, понятные графики и предсказуемые алерты.
Как настроить разные пороги для prod, test и филиалов, не копируя шаблоны?
Вынесите пороги в макросы и задавайте значения на уровне хоста или группы: для prod одни, для test и филиалов другие. Тогда один и тот же триггер работает везде, но с правильными цифрами. Это резко снижает ручные правки и ошибки при тиражировании мониторинга.
Что такое LLD (автообнаружение) и когда оно реально нужно?
LLD автоматически находит повторяющиеся объекты, которые постоянно меняются: файловые системы, диски, сетевые интерфейсы, сервисы. Это полезно, когда добавляют новый диск или интерфейс, а вы не хотите каждый раз вручную дописывать items и триггеры. Автопоиск экономит время и уменьшает риск «дырок» в контроле.
Какие метрики собирать, чтобы видеть качество сервиса, а не только ресурсы?
Соберите базовый набор по ОС, чтобы отличать проблемы сервера от проблем приложения: CPU с iowait, память со swap, диск по свободному месту и задержкам I/O, сеть по потерям и ошибкам, синхронизацию времени. Затем добавьте метрики по роли и качеству сервиса: время ответа ключевых запросов, долю ошибок, длину очередей, блокировки и подключения в БД. И обязательно оставьте 1–2 проверки «глазами пользователя», которые показывают реальную работоспособность.
Как настроить триггеры так, чтобы не было шума и «флаппинга»?
Делайте триггеры только под действие: если сработало — понятно, что проверять. Используйте подтверждение по времени и гистерезис, чтобы ловить тенденцию, а не разовые пики, и разделяйте «деградацию» и «отказ». Хорошее имя события должно объяснять риск для сервиса, а не просто значение метрики.
Как избежать сотен алертов при падении сети или общего узла?
Настройте зависимости триггеров, чтобы одна причина не порождала сотни симптомов. Например, если упал канал или коммутатор, «хост недоступен» за ним должен подавляться, а вверху оставаться один главный алерт про сетевую проблему. Это ускоряет диагностику и снижает выгорание дежурных.
Как в Zabbix показать бизнес-картину с сервисами, картами и дашбордами?
Соберите бизнес‑сервис как дерево: сверху сценарий пользователя, ниже компоненты и их состояния, включая деградацию, а не только «down». Сделайте отдельные дашборды под роли: дежурному — что горит и что делать сейчас, админам — тренды и узкие места, руководителю — статус сервисов без технических деталей. Тогда мониторинг помогает принимать решения, а не просто показывает инфраструктуру.
Как масштабировать мониторинг, чтобы через полгода он не превратился в «помойку»?
Сначала доведите до ума пилот на одном сервисе: шаблоны, теги, пороги, зависимости, понятные уведомления и владельцы. Затем тиражируйте подход и регулярно делайте ревизию: что шумит, что не используется, где нет ответственного. Если инфраструктура крупная, много площадок и нужна реакция 24/7, имеет смысл подключать интегратора; например, GSE.kz может закрыть часть вопросов по аппаратным платформам и поддержке, а вы сохраняете свою логику мониторинга сервисов.