Windows Event Forwarding: сбор событий Windows без агентов пошагово
Windows Event Forwarding помогает собрать события безопасности и системы на одном сервере: подписки, фильтры, расчет объемов, хранение и разбор инцидентов.
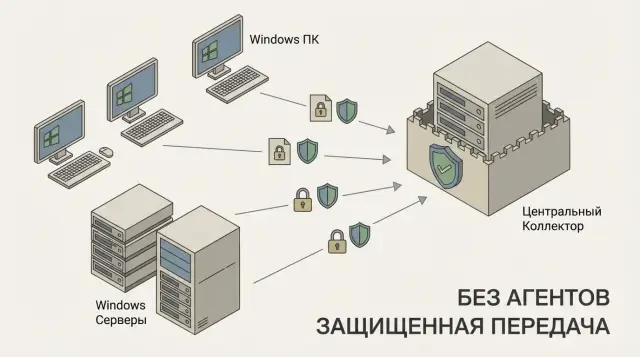
Зачем собирать события в одном месте
На отдельных рабочих станциях и серверах события часто "пропадают" не потому, что их не было, а потому что их неудобно искать. Журналы переполняются, их чистят "чтобы освободить место", часть устройств бывает вне сети, а во время инцидента нужный компьютер уже переустановили или поменяли диск.
Обычно теряются самые полезные следы: удачные и неудачные входы, изменения прав, запуск служб и планировщика, запуск PowerShell и скриптов, установка ПО, события Defender, ошибки драйверов, перезагрузки и внезапные выключения. На серверах добавляются ошибки аутентификации, сбои служб, попытки доступа к общим ресурсам и подозрительные изменения в конфигурации.
Локальные журналы неудобны для расследований по простой причине: нужно собрать картину из десятков машин. Даже если на каждой машине все включено, вручную сопоставлять время, пользователей, хосты и последовательность действий трудно и медленно. К тому же локальные логи легко "испортить" случайно или намеренно.
"Без агентов" в контексте Windows Event Forwarding означает, что на конечные устройства не ставится отдельный сборщик. Используются встроенные компоненты Windows и групповые политики. Это важно, когда нельзя добавлять стороннее ПО, когда нужно меньше точек обновления и меньше рисков от несовместимости, а также когда есть строгие требования к контролю изменений.
Централизованный сбор решает сразу несколько задач:
- Аудит: видеть, кто и что делал, с какой машины и когда.
- Реагирование: быстро находить первопричину и масштаб, а не первый найденный симптом.
- Отчетность: подтверждать соблюдение правил (например, по доступам и изменениям).
- Аналитика: замечать повторяющиеся сбои и подозрительные цепочки событий.
Что такое WEF и как он устроен
Windows Event Forwarding (WEF) - это встроенный в Windows способ пересылать события журналов с множества компьютеров на один сервер, без установки агентов. События рождаются на источниках (рабочие станции и серверы), а собираются и хранятся централизованно на коллекторе.
В схеме три части: источник событий (Source) читает нужные журналы, подписка (Subscription) описывает, что отправлять и откуда, а коллектор (Collector) принимает события и складывает их в свои журналы. Подписка - это набор правил: какие компьютеры участвуют, какие события подходят по фильтру и как часто их забирать.
Чаще всего пересылают события из журналов Security, System и Application. На практике Security нужен для входов, изменений учетных записей и политики, System - для проблем с драйверами, службами и перезагрузками, Application - для сбоев приложений и ошибок .NET. Часто добавляют специализированные журналы (например, PowerShell или Defender), но это зависит от задач.
Технически WEF опирается на штатные компоненты Windows: службу Windows Event Log, Windows Event Collector на сервере и транспорт поверх WinRM (WS-Management). Поэтому WEF хорошо подходит для доменной среды: клиенты подключаются политиками, а доступ контролируется привычными правами и группами.
Важно понимать ограничения. WEF - это не SIEM и не "волшебная аналитика", а в первую очередь транспорт и базовая унификация формата событий. Он не заменяет корреляцию, правила детекта и удобные отчеты. Зато дает надежный фундамент: собрать нужные события в одном месте, а дальше решать, где хранить их дольше и чем разбирать инциденты.
Подготовка: требования, сеть и права
Чтобы Windows Event Forwarding работал стабильно, сначала проверьте версии Windows, доменную среду, сеть и права. Большинство проблем с WEF появляются не в подписках, а в инфраструктуре вокруг них.
По версиям все просто: сервер-коллектор удобнее поднимать на Windows Server (2016/2019/2022), а источниками могут быть как серверы, так и рабочие станции Windows 10/11. На старых системах WEF тоже встречается, но там чаще упираются в устаревшие политики, шифры и ограничения журналов, поэтому лучше ориентироваться на современный пул ОС.
Сеть: что должно быть "зеленым"
WEF чувствителен к базовой сетевой гигиене. Перед пилотом проверьте:
- DNS: источники должны уверенно резолвить имя коллектора и наоборот.
- Время: синхронизация через AD/NTP, иначе Kerberos и подписи будут сбоить.
- Доступность WinRM: источники должны подключаться к коллектору по HTTP/HTTPS (типично 5985/5986, зависит от настроек).
- Межсетевые экраны: правила должны быть одинаковыми для нужных подсетей.
- Пропускная способность: узкие каналы между филиалами и коллектором быстро покажут себя очередями.
Учетные записи и права
В домене чаще всего используют компьютерный аккаунт источника для отправки событий, а коллектору нужно право принимать их и писать в журнал.
Практичный минимум:
- Коллектор: включенный Windows Event Collector и настроенный WinRM.
- Источники: разрешение отправки (через GPO) и доступ к нужным журналам для чтения.
- Оператор/SOC: права только на просмотр и экспорт, без админских полномочий на сами хосты.
Где размещать коллектор, зависит от приоритетов. Если важна скорость разбора и интеграция с SOC/SIEM, ставят ближе к ним, чтобы не гонять объемы по сети. Если важна изоляция, выделяют отдельную зону с ограниченным доступом администраторов. Если важна надежность аутентификации, держат ближе к контроллерам домена, но тогда особенно важно ограничить доступ к самому коллектору.
Шаг за шагом: настраиваем сервер-коллектор
Сервер-коллектор - точка, куда будут стекаться события со всех машин. В WEF сначала поднимают прием и канал связи, а уже потом подписки и фильтры.
Начните с базовой инициализации роли на Windows Server:
wecutil qc
winrm quickconfig
Первая команда включает службу Windows Event Collector и открывает нужные правила брандмауэра. Вторая настраивает WinRM, который используется для доставки событий.
Дальше проверьте безопасность канала. В домене обычно достаточно Kerberos (без паролей в сети), но небезопасные варианты стоит отключить:
- Убедитесь, что WinRM не принимает нешифрованные соединения и не использует Basic.
- Ограничьте доступ к WinRM только с нужных подсетей или групп компьютеров.
- Если коллектор стоит в отдельном сегменте или есть недоверенные сети, используйте WinRM по HTTPS с сертификатом.
Теперь подготовьте журнал, куда будут писаться пересланные события. По умолчанию используется Forwarded Events, и для пилота этого достаточно. Если хотите разнести потоки (например, безопасность отдельно от системы), заранее создайте отдельный журнал и задайте понятный размер, чтобы он не рос бесконтрольно.
Перед массовым раскатом проверьте прием на 1-2 тестовых машинах: например, на рабочей станции пользователя и одном сервере.
Короткая проверка:
- На коллекторе служба Windows Event Collector запущена и стоит в автозапуске.
- С тестовой машины выполняется
Test-WSMan <имя_коллектора>. - В Просмотре событий на коллекторе в Forwarded Events появляются новые записи после настройки клиента.
Если на этом этапе все стабильно, можно подключать клиентов через GPO и создавать подписки.
Шаг за шагом: подключаем клиенты через GPO
Подключать клиентов к Windows Event Forwarding удобнее всего через Group Policy: вы один раз задаете правила, а дальше машины начинают отправлять события сами. Начните с пилотной группы (например, 20-50 ПК из одного подразделения) и только после стабильной работы расширяйте охват.
Сначала включите удаленное управление, на котором держится WEF. В GPO обычно настраивают WinRM (служба и автозапуск) и правила брандмауэра для WinRM. Без этого клиенты не смогут общаться с коллектором, даже если подписка настроена правильно.
Дальше включается механизм пересылки событий. В политике задается адрес коллектора через параметр Client Subscription Manager. Туда указывают URL коллектора (обычно HTTP/HTTPS на WinRM) и, при необходимости, несколько коллекторов для отказоустойчивости. Сразу продумайте режим доставки: для критичных событий выбирают вариант ближе к минимальной задержке, для шумных журналов - более экономный режим, чтобы не создавать лишнюю нагрузку на сеть и диск.
Чтобы раскатывать постепенно, сделайте отдельный OU или security group для пилота и привяжите GPO только к ней. Так проще откатиться, не затрагивая всех.
Проверить, что клиент действительно начал отправлять события, можно быстро:
- На клиенте: выполните gpupdate /force и убедитесь, что служба WinRM запущена.
- На клиенте: проверьте, что применились параметры подписки (через gpresult или в соответствующих разделах политики).
- На коллекторе: откройте журнал Forwarded Events и убедитесь, что появились новые записи от пилотных машин.
- В Event Viewer на коллекторе: посмотрите статус подписки и счетчики принятых событий.
Если события не приходят, чаще всего причина в брандмауэре, DNS (клиент не находит коллектор) или правах: компьютеру или учетной записи не разрешено публиковать события на коллектор.
Подписки WEF: типы и базовая схема
Подписка в WEF - это правило: какие события забирать, с каких компьютеров, как часто и в какой журнал на коллекторе складывать. Чем аккуратнее вы разложите подписки с самого начала, тем проще будет хранение и разбор инцидентов.
Collector-initiated и Source-initiated: что выбрать
Collector-initiated означает, что коллектор сам опрашивает источники. Это удобно в небольших средах, где компьютеры всегда в сети и список источников редко меняется. Минус в том, что список машин нужно вести вручную, а на больших сетях это быстро становится проблемой.
Source-initiated означает, что источники сами подписываются на коллектор (обычно через GPO). Для домена это чаще всего лучший вариант: ноутбуки, новые ПК, сервера после переустановки - все подхватится автоматически, если попадает в нужную OU или группу.
Как разнести подписки по задачам
Одна большая подписка "все события со всех" почти всегда заканчивается шумом и заполненным диском. Практичнее сделать несколько подписок по смыслу и источникам. Например: рабочие станции, серверы, доменные контроллеры, отдельные роли (RDS, файловые серверы, серверы приложений). Так проще назначать разные фильтры, ретенцию и приоритет разбора.
Какие журналы и уровни брать вначале
Стартовый безопасный минимум: Security и System. Дальше добавляйте журналы по роли сервера (например, для AD или DNS).
По уровням ориентируйтесь на цель: для надежного мониторинга обычно достаточно Critical, Error, Warning. Information добавляйте точечно, когда нужно поймать конкретный сценарий. Иначе объемы вырастут в разы.
Имена и документация, чтобы не запутаться
Через полгода важнее всего будет понятное имя и короткое описание. Удобный шаблон: WEF-<роль>-<журналы>-<уровни>-v<версия>. Пример: WEF-Workstations-SecuritySystem-CritErrWarn-v1.
Рядом заведите простую таблицу (хоть в wiki): цель подписки, кто источники, какие каналы, уровни, ключевые Event ID, ожидаемый объем, владелец и дата изменения. Это экономит часы при инциденте, когда нужно быстро ответить на вопрос: почему именно эти события здесь есть, а других нет.
Фильтры и отбор: собираем нужное, а не все подряд
Сначала решите, какие вопросы вы хотите закрыть, и только потом включайте сбор. Иначе получится тонна шума, а важные события потеряются на фоне остальных.
Фильтровать можно по журналу (Security, System и т.д.), Event ID, источнику (Provider), уровню (Level), ключевым словам, а иногда и по данным внутри события (например, имя пользователя или процесс). На практике чаще всего хватает Event ID и Provider, а более тонкую логику добавляют точечно.
XPath-фильтры: простая логика на примерах
В подписках WEF фильтр задается XPath.
<QueryList>
<Query Id="0" Path="Security">
<Select Path="Security">*[System[(EventID=4624 or EventID=4625)]]</Select>
</Query>
</QueryList>
Пример выше соберет успешные и неуспешные входы (4624/4625). Если нужно сузить до конкретного источника:
<Select Path="Security">*[System[Provider[@Name='Microsoft-Windows-Security-Auditing'] and (EventID=4625)]]</Select>
Как не собрать лишнее
Есть события, которые "льются рекой" и редко помогают без контекста. Их лучше либо не собирать, либо вынести в отдельную подписку и включать только по необходимости. Часто шумят массовые успешные логины (4624) на терминальных серверах, служебные события при частых перезапусках, сетевые события на шлюзах и прокси, а также повторяющиеся ошибки приложений, которые уже известны.
Хорошая схема: отдельные подписки для высокошумных источников (например, RDP-серверы и критичные службы) и отдельные - для "тихих, но важных" сигналов. Тогда вы сможете менять фильтры точнее и не ломать весь сбор.
Объемы и производительность: как рассчитать и не перегрузить
Главная ошибка в WEF - включить "все подряд" и удивиться, что коллектор, сеть и диск стали узким местом. Лучше заранее прикинуть объем и проверить его на реальных данных.
Для грубой оценки достаточно простой модели:
- Оцените средние EPS (events per second) на одном ПК и на одном сервере в рабочее время и в пике.
- Возьмите средний размер записи (часто 0,5-2 КБ, но события безопасности бывают больше).
- Умножьте: EPS x размер x число хостов, затем переведите в МБ/час и ГБ/сутки.
- Добавьте запас 30-50% на пики (обновления, массовые логины, сбои).
На нагрузку сильнее всего влияют четыре вещи: тип доставки (чем чаще отправка и меньше пакетирование, тем больше запросов), качество фильтров (чем шире, тем больше шума), наличие "болтливых" источников (например, аудиты файлов и процессов) и редкие, но тяжелые пики. Один неправильно включенный аудит на группе серверов иногда дает больше событий, чем вся остальная сеть.
Проверяйте на фактах: соберите 1 день, посмотрите пики по часам, затем включите 1 неделю, чтобы увидеть понедельник, ночь, окна обновлений и неожиданные всплески.
Признаки перегруза и что менять сначала:
- События приходят с задержкой минутами или часами.
- Растут очереди и буферы, появляются пропуски событий на клиентах.
- Коллектор упирается в диск (постоянно высокий I/O) или CPU.
- Журнал быстро достигает лимита и начинается перезапись.
Сначала сужайте фильтры (убирайте шумные Event ID), затем переключайте доставку на более экономный режим, и только потом масштабируйте коллектор или разделяйте подписки на несколько коллекторов.
Хранение и ретенция: чтобы журналы не "съели" диск
План хранения лучше продумать до запуска WEF: первые дни обычно тихие, а потом объемы растут из-за обновлений, массовых входов и ошибок приложений.
Где держать логи: самый простой вариант - локально на сервере-коллекторе. Так быстрее и легче в поддержке, но есть риск, что диск забьется в неудобный момент. Второй вариант - выделенный сервер хранения или отдельный том, чтобы вынести дисковую нагрузку и резервное копирование.
Политика ретенции
Ретенция - это сочетание срока и лимитов по размеру. Задача простая: вы должны успевать обнаружить инцидент и поднять нужные события, но не хранить "все всегда".
Чаще всего проблему с диском решают четыре настройки:
- максимальный размер журналов на коллекторе и режим перезаписи
- отдельные журналы под разные подписки (без одной общей свалки)
- срок "горячего" хранения (например, 7-30 дней) и срок архива (например, 90-180 дней)
- регулярный контроль свободного места и оповещение
Архив и контроль целостности
Архивируйте события по расписанию: экспортируйте закрытые участки журнала в файл, фиксируйте хеш и храните вместе с метаданными (дата, источник, подписка). Это помогает доказать, что журнал не меняли, и ускоряет разбор инцидента: вы открываете нужный диапазон, а не весь массив.
Отдельно продумайте доступ. Чтение журналов безопасности не должно быть "у всех админов". Дайте право читать только тем, кто расследует, а право на настройку подписок и очистку журналов держите в узком круге. Полезно разделять роли: одни администрируют WEF, другие анализируют события, а действия по очистке или изменению политики всегда фиксируются.
Пример расследования: от тревоги до вывода
Сценарий
Допустим, SOC получает тревогу: ночью был успешный вход на файловый сервер от имени бухгалтера, хотя обычно он работает днем. Дальше появляются признаки разведки и попытка закрепиться. При WEF нужные журналы уже в одном месте, и не надо подключаться к каждому хосту по очереди.
Начните с простой связки: кто вошел, откуда, куда, и что делал сразу после входа. Отметьте точное время (с учетом часового пояса), имя учетной записи, workstation name и IP.
События, которые чаще всего дают быстрый ответ:
- Security 4624 (успешный вход) и 4625 (неуспешный вход) для проверки подбора пароля и типа входа
- Security 4648 (вход с явным указанием учетных данных), если использовали другие креды
- Security 4672 (спецпривилегии) для понимания уровня доступа
- Security 4688 (создание процесса), чтобы увидеть, запускали ли PowerShell, cmd, wmic и похожие утилиты
- System 7045 (установка службы) как частый способ закрепления
Дальше свяжите цепочку по времени: возьмите окно +/- 10 минут вокруг 4624 и посмотрите соседние события на том же хосте. Если WEF собирает 4688, вы быстро увидите, что было запущено сразу после входа (например, powershell.exe с параметрами) и какие команды выполнялись. Если видно обращение к другим серверам, переходите к ним и ищите там новые 4624 от той же учетной записи и с того же источника.
Что сохранить в карточке инцидента
Чтобы выводы можно было проверить и повторить, фиксируйте не только "что случилось", но и доказательства:
- временная линия: ключевые события с timestamp и EventRecordID
- привязка субъектов: пользователь, хост, IP, тип входа (Logon Type)
- команды и артефакты: строка запуска процесса, имена служб, задачи, пути к файлам
- масштаб: какие еще хосты затронуты по тем же признакам
- итог и действия: что подтвердили, что заблокировали, что усилили в фильтрах подписок
Такой формат помогает быстро передать расследование другой смене и использовать находки для улучшения отбора событий в подписках WEF.
Частые ошибки и ловушки при внедрении
Самая частая проблема с Windows Event Forwarding - начинают собирать все подряд. В итоге полезные события тонут в шуме, а место на диске и ресурсы сервера уходят на то, что никто не смотрит.
Обычно это происходит по двум причинам: подписка настроена слишком широко (например, весь Security или System без фильтров), и никто заранее не прикинул объемы. Лучше начинать с небольшого набора событий под конкретные сценарии (входы, изменения групп, запуск служб, ошибки аудита), а потом расширять.
Вторая ловушка - права и WinRM. Подписка может выглядеть живой, клиенты есть в списке, но событий нет или они приходят с задержками. Частые причины: WinRM не включен или не настроен на клиентах, трафик блокируется межсетевым экраном, не хватает прав у учетной записи компьютера на чтение нужных журналов, или клиент не попадает под нужную GPO.
Еще одна ошибка - сложить все в одну подписку. Первое время это кажется удобным, но потом разбор инцидентов превращается в поиск иголки в стоге. Практичнее разделять по смыслу: отдельная подписка под безопасность, отдельная под стабильность системы, отдельная под критичные роли (DC, серверы приложений).
Наконец, ретенция и мониторинг. Если не задать размеры журналов и сроки хранения, вы узнаете о проблеме, когда диск на коллекторе заполнится и начнутся потери. Особенно неприятно, когда расследование нужно за прошлую неделю, а логи уже перезаписаны.
Короткий безопасный подход к изменениям:
- Начните с пилота на 10-20 хостах и измерьте объем в сутки.
- Вносите изменения маленькими шагами: один фильтр или одна подписка за раз.
- Держите эталон настроек (описание фильтров, список источников, ожидаемые события).
- Проверяйте доставку по факту: события пришли и их можно найти.
- Планируйте откат: заранее решите, что отключаете первым при перегрузке.
Быстрые проверки и следующие шаги
Когда WEF уже настроен, проблемы чаще всего оказываются не в подписке, а в базовых вещах: сеть, время, права и то, как клиент применил GPO. Перед тем как расширять охват, сделайте короткую проверку.
Мини-чеклист запуска
Проверьте, что клиенты видят коллектор по имени (DNS) и могут достучаться до него по WinRM. Убедитесь, что время на клиентах и коллекторе синхронизировано: заметный рассинхрон дает провалы и "прыгающую" хронологию.
Дальше проверьте, что нужные GPO применились на конкретной машине, а на коллекторе действительно появляется поток событий в ожидаемых журналах. Если события не приходят, начинайте от простого: правильная ли OU, нет ли конфликтующего GPO, открыты ли нужные правила брандмауэра.
Чеклист качества данных и эксплуатации
Когда события пошли, проверьте качество, иначе централизованный сбор событий Windows быстро превратится в шум:
- Фильтры: собираете только нужные каналы и уровни.
- Пропуски: нет ли дыр по важным источникам (DC, файловые серверы, RDS).
- Дубли: одно и то же событие не попадает дважды из-за пересечения подписок.
- Шум: исключены события, которые не несут пользы, но создают объем.
- Ретенция: журналы на коллекторе не переполняются и не затирают важное.
Заранее задайте правила эксплуатации: сколько дней держите онлайн, что архивируете, кто имеет доступ к журналам и кто меняет фильтры. Параллельно настройте наблюдение за диском и ростом логов, чтобы переполнение не стало сюрпризом.
Следующие шаги обычно такие: подключить больше источников (начиная с самых критичных), разделить подписки по ролям серверов, формализовать процесс разбора инцидентов (кто смотрит, по каким событиям, в какие сроки).
Если вы планируете внедрение под ключ или обновление серверной части под хранение и обработку логов, это часто удобно делать вместе с системной интеграцией и поддержкой. Например, GSE.kz (gse.kz) работает как производитель серверов и системный интегратор, что помогает собрать инфраструктуру и сопровождение в одном контуре.
FAQ
Зачем вообще собирать события Windows в одном месте, если на каждом ПК есть свои журналы?
Потому что локальные журналы легко теряются: их чистят из‑за места, часть машин бывает вне сети, а во время инцидента устройство уже переустановили или заменили диск. Централизация дает единый таймлайн по пользователям и хостам, ускоряет расследования и снижает риск намеренной или случайной порчи логов на конечной машине.
Что такое WEF и почему его называют «без агентов»?
WEF (Windows Event Forwarding) — встроенная в Windows пересылка событий на сервер‑коллектор без установки отдельного агента на рабочие станции и серверы. Клиенты отправляют отобранные события по WinRM, а коллектор складывает их в свои журналы, обычно в Forwarded Events.
Какие журналы лучше пересылать в первую очередь: Security, System или Application?
Для старта чаще всего хватает журналов **Security** и **System**. Security закрывает входы, изменения учетных записей и прав, а System — ошибки драйверов, служб, перезагрузки и выключения; Application добавляйте, когда реально нужно ловить сбои приложений и .NET.
Что выбрать: Source-initiated или Collector-initiated подписки?
Почти всегда выбирают **Source-initiated**: источники сами подписываются на коллектор через GPO и автоматически подключаются после переустановки или появления нового ПК в OU. **Collector-initiated** удобен только в маленьких сетях со стабильным списком машин, где вы готовы вручную поддерживать перечень источников.
Почему события не приходят на коллектор и с чего начинать поиск причины?
Начните с проверки DNS и синхронизации времени, затем проверьте доступность WinRM до коллектора и правила брандмауэра. Дальше убедитесь, что GPO реально применилось на клиенте и что у компьютера есть права публиковать события на коллектор; чаще всего проблема именно в сети, времени или правах, а не в фильтре.
Как не утонуть в шуме и не собрать «всё подряд»?
Используйте фильтрацию по **Event ID**, **Provider** и уровню (Critical, Error, Warning), а информационные события включайте точечно под конкретный сценарий. Если включить «весь Security» без отбора, вы быстро получите шум, задержки доставки и заполненный диск, а важные сигналы станут хуже заметны.
Как прикинуть объем логов и понять, выдержит ли коллектор нагрузку?
Самый практичный подход — пилот на небольшой группе и измерение фактического потока: сколько событий в сутки и какие пики по часам. Затем оцените место на диске и пропускную способность между площадками, и добавьте запас на обновления, массовые логины и аварии; один «болтливый» аудит способен дать больше объема, чем весь остальной парк.
Как настроить хранение и ретенцию, чтобы логи не «съели» диск?
Задайте понятные лимиты размеров журналов и режим перезаписи, а при необходимости разделите потоки по разным журналам или подпискам, чтобы не было одной «свалки». Дальше определите сроки «горячего» хранения и архива, и регулярно контролируйте свободное место, иначе вы узнаете о проблеме в момент, когда логи уже перезаписаны.
Кому какие права выдавать на коллекторе, чтобы не рисковать безопасностью?
Дайте SOC/аналитикам права на просмотр и экспорт, но не на настройку подписок и не на очистку журналов. Администрирование WEF, изменение фильтров и любые действия, которые могут повлиять на полноту логов, держите в узком круге и фиксируйте изменения, чтобы в расследовании не было вопросов «почему данных нет».
Какие события помогают быстрее всего в типовом расследовании (логин, PowerShell, закрепление)?
Чаще всего начинают с 4624/4625, чтобы понять кто и откуда вошел, затем добавляют 4648 и 4672 для контекста учетных данных и привилегий, а дальше смотрят 4688, 7045 и соседние события в окне по времени. Смысл WEF в том, что вы быстро строите цепочку действий по нескольким хостам без ручного обхода машин.