Внутренний developer portal: Backstage и аналоги без боли
Внутренний developer portal помогает собрать каталог сервисов, шаблоны и документацию. Разбираем Backstage, аналоги и понятный план внедрения.
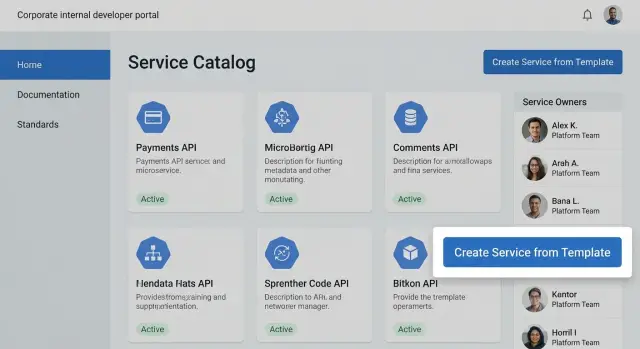
Какие боли решает внутренний портал
Когда в компании появляются десятки сервисов и несколько команд, знания расползаются по разным местам: часть в wiki, часть в репозиториях, что-то в чатах, а важные решения остаются в головах у людей. Внутренний developer portal собирает это в одну точку и делает информацию удобной для ежедневной работы.
Самая частая боль - поиск. Разработчик пытается понять, где репозиторий, какие переменные нужны для запуска, кто владелец сервиса, где дашборды и алерты, как устроен релиз. Поддержка и SRE в момент инцидента ищут контакты и runbook. Время уходит не на работу, а на раскопки.
Вторая боль - размытая ответственность. Если непонятно, кто отвечает за сервис, любое изменение превращается в цепочку ручных согласований: кто апрувит доступ, кто знает, можно ли обновлять библиотеку. Каталог сервисов с понятными owners и зонами ответственности снимает большую часть этих вопросов.
Третья боль - отсутствие общих стандартов. Команды выбирают разную структуру репозиториев, разные подходы к логированию, разные пайплайны и оформление документации. Это усложняет ревью, онбординг и сопровождение. Портал помогает закрепить "золотой путь": шаблоны проектов, чеклисты, принятые практики и минимальные требования, которые легко повторить.
Есть простые сигналы, что внутренний developer portal уже нужен:
- онбординг новых людей растягивается на недели, потому что "надо спросить у N человек"
- одни и те же вопросы про сервисы повторяются в чатах каждую неделю
- на инцидентах теряется время на поиск владельца и инструкции
- каждый сервис выглядит как отдельный мир, и никто не уверен, что "сделано правильно"
- релизы и доступы держатся на ручных договоренностях
Если узнаете хотя бы пару пунктов, портал обычно окупается не интерфейсом, а тем, что снижает трение в ежедневной работе команд.
Что такое developer portal и из чего он состоит
Developer portal - это единое рабочее место, где команда видит свои сервисы, владельцев, инструкции по запуску и поддержке, а также общие правила. Проще говоря, внутренний developer portal собирает в одном месте каталог сервисов, документацию, стандарты и элементы самообслуживания, чтобы меньше прыгать по системам и меньше спрашивать в чатах.
Портал не заменяет ваши инструменты. Он связывает их и дает понятную "точку входа": репозиторий хранит код, трекер - задачи, wiki - заметки. Портал отвечает на практичные вопросы: что это за сервис, где документация, как развернуть, какие зависимости, кто владелец, какие проверки обязательны.
Обычно внутри есть несколько базовых блоков: каталог сервисов и других сущностей (библиотеки, компоненты, базы данных, очереди), шаблоны проектов и "золотой путь", документация, привязанная к сервисам, стандарты и политики (например, логирование, мониторинг, требования безопасности), а также операции самообслуживания (типовые запросы и действия без ручных заявок).
Портал полезен не только разработчикам, потому что роли пересекаются. Разработчики быстрее находят нужное и создают новые сервисы по шаблону. Владельцы продуктов видят ответственность и статус ключевых систем. SRE/DevOps получают единые ожидания по метрикам, алертам и релизам. Безопасность фиксирует обязательные проверки и исключения. Поддержка понимает, куда эскалировать инцидент и где искать runbook.
В крупных организациях с системной интеграцией и несколькими командами (например, у производителей и интеграторов уровня GSE.kz) портал помогает удерживать единые правила, даже когда сервисов становится много и они живут в разных репозиториях и средах.
Backstage: когда подходит и что в нем главное
Backstage часто выбирают как основу для внутреннего developer portal, когда хочется собрать все в одном месте, но не писать портал с нуля. Идея простая: есть каталог сущностей (сервисы, библиотеки, компоненты, команды, окружения), а вокруг него подключаются плагины. Плагины добавляют документацию, шаблоны проектов, поиск, интеграции с CI/CD, мониторингом и внутренними системами.
Самое важное заранее - не код, а договоренности. Если их нет, каталог быстро превратится в свалку или, наоборот, будет пустым, потому что никто не понимает, что и как описывать.
Перед стартом полезно договориться о четырех вещах:
- модель каталога: какие типы сущностей реально нужны в первые 1-2 месяца
- источники данных: откуда брать "правду" (репозитории, Kubernetes, CMDB, Jira, ручной ввод)
- владение: у каждой сущности должен быть владелец (команда или роль)
- правила качества: что считается минимально заполненной карточкой сервиса
Backstage хорошо подходит, когда у вас много команд и сервисов, и уже болит: сложно найти владельца, непонятно, как запускать новый сервис, документация разбросана, стандарты не проверяются. В такой среде единый каталог и повторяемые шаблоны дают быстрый эффект.
Сложнее в маленьких командах или там, где нет владельца платформы. Backstage требует поддержки: обновлений, настройки плагинов, разборов конфликтов в модели данных, помощи командам с онбордингом. Если некому заниматься этим хотя бы на 0.5-1 ставки, портал начнет раздражать быстрее, чем приносить пользу.
Аналоги Backstage и более простые варианты
Backstage хорош, когда нужны каталог, шаблоны и интеграции. Но часто начать можно проще, если цель сейчас не "идеальная платформа", а понятный вход для разработчиков и единые правила.
Вариант 1: облегченный портал на базе wiki и репозитория
Самый быстрый путь - договориться о структуре страниц в wiki и хранить шаблоны проектов в отдельном репозитории. "Порталом" станет одна стартовая страница с навигацией: как создать сервис, где документация, где стандарты, кто владелец.
Так обычно делают, когда сервисов пока десятки, а не сотни. Например, команда запускает новый внутренний API и по чеклисту сразу создает репозиторий из шаблона, заводит страницу с владельцем и SLA, добавляет запись в таблицу каталога.
Вариант 2: коммерческие платформы developer portal
Коммерческие решения экономят время на сборке и поддержке, но требуют аккуратного выбора. Важно, чтобы у платформы был каталог с владельцами и поиском, шаблоны и автоматизация (создание репозиториев и окружений), интеграции с SSO, CI/CD, трекером и мониторингом, права доступа и аудит изменений, а также понятная модель расширений и внятная стоимость владения.
Вариант 3: портал на корпоративном портале или CMS
Иногда достаточно раздела на корпоративном портале. Это удобно для новых сотрудников и смежных команд. Но следите, чтобы данные о сервисах не превращались в статичные страницы без владельцев и обновлений.
Чтобы не ошибиться с внутренним developer portal, начните с обязательного минимума: каталог сервисов (кто отвечает и где прод), один "золотой" шаблон и проверяемые стандарты. Все остальное - витрина метрик, сложные плагины, красивые дашборды - можно отложить до пилота.
Каталог сервисов: что описывать и как не утонуть в деталях
Каталог сервисов во внутреннем developer portal работает как справочник: быстро понять, что делает сервис, кто за него отвечает и куда идти, если что-то сломалось. Главная ошибка на старте - пытаться описать все сразу, как в полноценной архитектурной документации.
Ориентируйтесь на карточку, которая помогает принять решение за 30 секунд. Если поле не помогает в работе дежурного, разработчика или менеджера, его можно отложить.
Минимум для каждой карточки
Набор небольшой, но он должен заполняться всегда:
- назначение сервиса: 1-2 предложения, что он делает и для кого
- владельцы: владелец продукта и технический владелец (по одному, без размытых "все из команды")
- контакты: канал поддержки и путь эскалации (дежурный или ответственный)
- критичность: насколько больно бизнесу при простое и какие ожидания по восстановлению
- статус: активен, в разработке, на выводе из эксплуатации
Связи, которые экономят время
Связи добавляйте по мере надобности, но обычно быстро окупаются: зависимости от других сервисов, команды, основные API, база данных или хранилище, окружения (dev/test/prod). Тогда при инциденте видно, что могло повлиять, и кто нужен в чат.
Чтобы каталог не стал кладбищем устаревших карточек, сделайте обновление частью обычного процесса: изменение сервиса - изменение карточки. Назначьте ответственных, добавьте простые напоминания (например, раз в квартал) и минимальную проверку при релизе. В компаниях с несколькими направлениями работ, как у GSE.kz (производство, интеграция, поддержка), это помогает не терять владение на стыке команд и проектов.
Шаблоны и золотой путь для команды
Шаблоны в developer portal нужны не ради красоты, а чтобы каждый новый проект стартовал одинаково предсказуемо. Команда получает репозиторий с базовой структурой, настроенным CI и минимальным набором проверок. Это экономит часы на обсуждениях и снижает риск, что сервис собирается только на ноутбуке автора.
Начните с нескольких шаблонов, которые реально встречаются в работе: новый сервис (API или worker), библиотека или общий модуль, регулярная job по расписанию, инфраструктурный модуль (например, IaC для окружения). Главное, чтобы шаблон задавал понятный "золотой путь": куда класть код, где конфиги, как запускать тесты, как выкатываться.
Что стоит "вшить" в шаблон
Добавляйте только то, что вы готовы поддерживать и проверять. Обычно хватает:
- соглашений по именованию (сервисы, команды, окружения)
- базового логирования и единого формата полей
- метрик и health checks по умолчанию
- заготовки тестов (unit и простой smoke)
- проверок качества в CI (линтер, тесты, сборка)
Согласования без тормозов
Согласования работают, когда они короткие и максимально автоматизированные. Сделайте обязательными 1-2 шага (например, проверку секретов и минимальные тесты), а остальное переведите в "мягкие" подсказки.
Практичный сценарий: разработчик создает сервис через шаблон. Портал сразу добавляет владельца, регистрирует сервис в каталоге, включает метрики и запускает CI. Если не заполнен owner или нет health check, сборка не проходит. Остальные требования (например, расширенная документация) можно дотянуть позже, не блокируя первый релиз.
Документация и стандарты: сделать понятно и проверяемо
Документация в портале ценна не количеством страниц, а тем, что помогает действовать без лишних вопросов, особенно в стрессовой ситуации. Хороший минимум закрывает жизненный цикл сервиса: от первого запуска до аварийного отката. Тогда внутренний developer portal становится рабочим инструментом, а не витриной.
Чаще всего помогают несколько коротких страниц: как запустить сервис локально (зависимости, переменные, тестовые данные), как деплоить (окружения и где смотреть статус), как откатить релиз, как дежурить (алерты, пороги, типовые инциденты, контакты), как запросить доступы и секреты.
Единый формат, который реально читают
Договоритесь об одном шаблоне короткой страницы: цель сервиса, владельцы, как запустить, как проверить здоровье, как чинить типовые проблемы. Добавляйте примеры команд и ожидаемый результат, чтобы человек мог просто повторить.
Ночной сценарий хорошо показывает ценность: падает интеграция, дежурный видит алерт и открывает runbook. Там три шага диагностики, команда для проверки конфигурации и понятный путь отката. Если у вас поддержка 24/7, это экономит десятки минут на каждом инциденте.
Стандарты, которые можно проверять
Стандарты (безопасность, код-ревью, ветвление, версии, работа с секретами) лучше закреплять не текстом, а проверками. Например: линтеры и форматтеры в CI, обязательные файлы (owners, runbook, changelog), правила по секретам (сканер и запрет коммита ключей), обязательные поля в каталоге (владелец, критичность, репозиторий), чеклист на pull request для релизных изменений.
Так стандарты перестают быть "рекомендациями" и становятся правилами, которые выполняются автоматически.
Доступы, безопасность и интеграции
Когда появляется внутренний developer portal, он быстро становится витриной разработки. Поэтому вопрос не только в удобстве, но и в том, кто и что может увидеть, поменять или запустить.
Начните с простого разделения: что полезно видеть всей компании (название сервиса, владелец, статус, краткое описание), а что должно быть ограничено командой или проектом (переменные окружения, внутренние адреса, детали архитектуры, уязвимости). Обычно хватает ролевой модели и групп из корпоративного каталога, без отдельной системы прав.
Полезно заранее ответить на несколько вопросов: кто имеет право менять метаданные сервиса, какие разделы читают все, а какие только участники проекта, нужны ли гостевые роли для смежных команд, как фиксируются действия (кто создал шаблон, кто выдал доступ, кто запустил релиз), как устроен доступ подрядчиков (срок, минимальные права, отзыв по окончании работ).
Интеграции выбирайте не по принципу "подключим все", а по тому, что экономит время каждый день. Чаще всего это связки с репозиториями, CI/CD, мониторингом и инцидентами: разработчик открывает карточку сервиса и видит, где код, как собрать, где алерты и кто дежурит.
Чтобы не плодить копии данных, договоритесь об "едином источнике правды": владельцы и команды - из IAM, код и история - из репозитория, инфраструктура - из IaC или оркестратора, статусы - из CI/CD. Портал должен показывать и связывать эти данные, а не хранить их заново.
Безопасность и комплаенс проще встроить в стандарты и шаблоны. Для организаций с жесткими требованиями (госсектор, финансы) это обычно означает: обязательные поля в карточке сервиса, минимальный набор проверок в пайплайне и понятный аудит действий. Тогда правила соблюдаются автоматически, а не через ручные согласования.
Внедрение по шагам: от пилота к масштабу
Частая причина провала портала - попытка сразу охватить всех и описать все сервисы идеально. Лучше идти маленькими шагами и проверять пользу на реальной работе.
Начните с пилота: 1-2 команды и небольшой набор живых сервисов (например, 5-10), которые часто меняются и регулярно задают вопросы в поддержке.
Пять шагов, которые обычно срабатывают
- Сформируйте пилотную группу и список сервисов, которые точно попадут в каталог первыми.
- Договоритесь о минимальной карточке сервиса и едином формате документации: что обязательно, а что можно добавить позже.
- Запустите один типовой шаблон и попросите команду пройти путь "с нуля".
- Подключайте интеграции по очереди, начиная с тех, что дают ежедневный эффект. Назначьте владельца платформы, который держит правила в актуальном виде.
- Расширяйте охват через понятные правила входа: что команда делает, чтобы новый сервис появился в портале.
Через 2-3 недели соберите обратную связь: где люди спотыкаются, какие поля никто не заполняет, что реально помогает. В компаниях с системной интеграцией и поддержкой 24/7 обычно быстро становятся критичными поля "владелец", "канал поддержки", "SLA" и "зависимости".
Хороший признак прогресса: портал отвечает на типовые вопросы без личных сообщений, а новые сервисы заводятся по шаблону за часы, а не за дни.
Пример сценария: запуск нового сервиса без хаоса
Представьте: появляется новый сервис для внутренней системы. В работе участвуют две команды разработки, плюс эксплуатация и безопасность. Уже через неделю начинаются вопросы: кто владелец, где репозиторий, какие зависимости, как деплоить, кому писать при инциденте. Ответы живут в чатах, а часть людей даже не в курсе, что сервис существует.
Внутренний developer portal превращает это в понятный маршрут. Команда начинает с карточки сервиса в каталоге. Это занимает 10-15 минут, но сразу фиксирует базовую "правду": владельца и контакты дежурных, репозиторий и пайплайн, окружения, краткое назначение и ключевые зависимости, критичность и правила эскалации, статус (черновик, пилот, прод).
Дальше разработчик создает сервис по шаблону: репозиторий уже с правильной структурой, настройками CI/CD, базовой наблюдаемостью и минимальными проверками стандартов. Документация появляется как скелет: как запускать локально, как деплоить, как откатить. Остается дописать детали.
Для поддержки и безопасности главное изменение простое: они быстрее находят ответственных и видят согласованные правила. Не нужно угадывать, где лежат инструкции и какие требования обязательны.
Чтобы понимать, что портал реально помогает, следите за несколькими метриками: доля сервисов с заполненными владельцами и контактами, среднее время онбординга в новый сервис, процент сервисов с актуальными runbook, время поиска ответственного при инциденте, число отклонений от стандартов на ревью или в пайплайне.
Частые ошибки и ловушки
Самая частая ошибка - пытаться описать все сразу: весь каталог, всю документацию, все стандарты. В итоге внутренний developer portal превращается в бесконечный проект, который никто не использует. Делайте пилот на 10-20 сервисах, проверьте, что карточки реально помогают, и только потом расширяйте.
Вторая ловушка - делать портал "только для разработчиков" и забывать про поддержку и безопасность. Если у сервиса нет контактов дежурных, критичности и понятной инструкции, поддержка все равно будет искать людей в чатах. А если нет базовых отметок по данным и доступам, безопасность начнет стопорить релизы, потому что ей нечего проверять.
Отдельная проблема - отсутствие владельца платформы и ответственных за карточки сервисов. Когда "всем понемногу" отвечает никто, каталог быстро устаревает: ссылки ломаются, команды меняются, репозитории переезжают. Работает простой принцип: у портала должен быть хозяин (платформенная команда или назначенный owner), а у каждого сервиса - конкретный владелец карточки и техподдержки.
И наконец, слишком сложные шаблоны и правила. Если создание сервиса требует десяти форм, редких знаний и недель согласований, команды начинают обходить процесс: копируют старый репозиторий, настраивают вручную, а портал остается "для галочки". Держите золотой путь коротким: минимум обязательных полей, 1-2 шаблона для самых частых случаев, постепенное ужесточение правил только после того, как команды привыкли и видят пользу.
Полезная проверка на здравый смысл:
- Можно ли завести новый сервис за 30-60 минут без помощи "эксперта по порталу"?
- Понимает ли поддержка, куда идти при инциденте, не спрашивая в чатах?
- Есть ли у каждой карточки живой владелец, а не "команда X" без контакта?
- Не заставляют ли шаблоны делать лишнее, если сервис маленький или экспериментальный?
Если на эти вопросы сложно ответить "да", портал стоит упростить, а не расширять.
Быстрый чеклист и следующие шаги
Чтобы внутренний developer portal начал приносить пользу быстро, держите фокус на базовых вещах. Не пытайтесь сразу описать все сервисы и все правила. Запустите минимальный набор и закрепите привычку им пользоваться.
Чеклист "минимум, который должен работать"
Проверьте то, что можно обсудить за один созвон и закрыть одной правкой в репозитории:
- Назначен владелец портала, и есть понятное правило, как принимать изменения.
- Определена простая модель каталога: что считается сервисом, что считается библиотекой, какие поля обязательны (владелец, критичность, контакты, репозиторий, окружения).
- Есть хотя бы один рабочий шаблон проекта с базовыми настройками (CI, линтер, структура папок).
- Есть один стандарт документации и пример "эталонной" страницы (как запускать, как деплоить, куда смотреть логи, как откатывать).
- Настроены доступы: кто видит каталог, кто редактирует карточки, и как фиксируется обновление (через PR/ревью или заявку). Выбраны 1-2 метрики качества (например, доля сервисов с владельцем и свежесть карточек).
Что сделать на следующей неделе
Выберите небольшой пилот, где результат заметен за 1-2 недели, и проведите короткий воркшоп:
- за 60-90 минут договоритесь об обязательных полях каталога и одном шаблоне
- заведите карточки для 1-2 сервисов, напишите по одному runbook, прогоните создание сервиса через шаблон
- в конце недели посмотрите метрики и список того, что мешало, и уберите 1-2 самых болезненных препятствия
Интегратора имеет смысл подключать, когда у вас много разрозненных систем (CI/CD, IAM, CMDB, мониторинг) и нужен единый подход к интеграциям, ролям и поддержке. Если параллельно стоит задача по инфраструктуре и надежной эксплуатации (серверы, рабочие станции, поддержка), GSE.kz может быть полезен как системный интегратор и производитель оборудования под такие процессы.
FAQ
Как понять, что компании уже нужен внутренний developer portal?
Если у вас регулярно теряется время на поиск репозитория, владельца, переменных окружения, дашбордов и инструкций, портал уже окупится. Практичный ориентир: если онбординг тянется неделями и на инцидентах люди сначала ищут контакты и runbook, единая точка входа быстро снижает потери времени.
Что такое developer portal простыми словами?
Это единое рабочее место, где по каждому сервису можно быстро увидеть, что он делает, где код и документация, кто владелец, как запускать и как поддерживать. Он не заменяет репозиторий, трекер и wiki, а связывает их так, чтобы на типовые вопросы отвечать за минуты, а не через переписку в чатах.
Из каких частей обычно состоит хороший внутренний портал?
Обычно начинают с каталога сервисов, привязанной к ним документации и одного-двух шаблонов проектов для «золотого пути». Дальше добавляют стандарты, которые можно проверять в CI, и базовые операции самообслуживания, чтобы меньше делать вручную через заявки.
Когда Backstage действительно подходит, а когда лучше не начинать?
Backstage подходит, когда сервисов и команд много, и уже болит поиск, владение и единые правила. Он особенно полезен, если вы готовы договориться о модели каталога, источниках данных и правилах качества карточек, а также выделить человека или команду, которые будут поддерживать портал в живом состоянии.
Какие поля должны быть в карточке сервиса в каталоге в первую очередь?
Начните с минимальной карточки, которая помогает принять решение за 30 секунд: назначение, владельцы, контакты для поддержки, критичность, статус и ссылки на код и пайплайны. Остальные детали добавляйте только если ими реально пользуются, иначе карточки быстро перестанут заполнять.
Какие шаблоны проектов стоит сделать первыми?
Лучше всего работают шаблоны, которые встречаются каждый день: новый API/worker, библиотека и простой инфраструктурный модуль. Шаблон должен давать предсказуемый старт: структура репозитория, базовый CI, минимальные проверки, а также заготовку документации и наблюдаемости, чтобы сервис не жил «только на ноутбуке автора».
Какую документацию важно закрепить в портале, чтобы она реально работала?
Держите короткий набор страниц, которые помогают действовать без уточнений: локальный запуск, деплой, откат, здоровье сервиса и типовые инциденты. Главный принцип — меньше текста, больше повторяемых шагов и ожидаемых результатов, чтобы дежурный мог выполнить инструкцию даже ночью.
Как правильно настроить доступы и безопасность в developer portal?
Сразу разделите, что можно видеть всем (название, владельцы, статус, назначение), а что должно быть ограничено (внутренние адреса, детали уязвимостей, секреты и чувствительные параметры). Дальше зафиксируйте, кто может менять метаданные сервиса и как это аудируется, чтобы изменения проходили прозрачно и без ручных «договоренностей в личке».
Как начать внедрение, чтобы не утонуть в масштабе?
Рабочий пилот — это 1–2 команды и 5–10 живых сервисов, где есть частые релизы и вопросы от поддержки. За 2–3 недели можно проверить пользу: завести карточки, подключить базовые интеграции, прогнать создание сервиса через шаблон и собрать обратную связь по полям, которые мешают или не заполняются.
Какие ошибки чаще всего делают при внедрении внутреннего портала?
Чаще всего ломает проект попытка описать всё сразу, отсутствие владельца платформы и слишком тяжёлый процесс создания сервиса. Ещё одна типичная проблема — игнор поддержки и безопасности: без контактов, критичности и runbook портал не поможет на инцидентах, а без проверяемых минимумов по доступам и секретам релизы будут стопориться.