Уровни RAID для надежности данных: что выбрать под нагрузку
Уровни RAID для надежности данных: сравнение 0/1/5/6/10 по скорости и емкости, риски rebuild и когда вместо RAID нужны другие подходы.
Зачем вообще нужен RAID и где его часто переоценивают
RAID решает две практические задачи: помогает системе продолжать работу при отказе диска и снижает риск простоя. Иногда он дает прибавку к скорости, но это побочный эффект, а не гарантия.
Самая частая ошибка - путать RAID с резервным копированием. RAID не спасет от случайного удаления, вируса-шифровальщика, повреждения базы из-за сбоя приложения, ошибки администратора, пожара или кражи оборудования. В таких ситуациях проблема почти всегда затрагивает весь массив сразу. Поэтому логика "RAID есть, значит бэкапы не нужны" обычно заканчивается потерей данных.
Перед выбором уровня полезно честно ответить, что для вас важнее: простой, риск потери данных или бюджет. Для бухгалтерии и документов даже небольшой риск может быть неприемлем, а для тестового стенда чаще важнее цена и простота. Для 1С и баз данных обычно важны и скорость, и предсказуемое восстановление.
Сначала проясните четыре вещи: сколько часов простоя вы выдержите, сколько данных допустимо потерять (0, час, день), как быстро растет объем и как устроены резервные копии (где лежат, кто делает, проверяли ли восстановление).
Если сервер покупается под критичные сервисы (госорганизация, банк, клиника, учебное заведение), RAID стоит рассматривать как часть общей схемы надежности. В таких проектах системный интегратор вроде GSE.kz обычно начинает не с вопроса "какой RAID выбрать", а с требований к простою, восстановлению и поддержке 24/7.
Базовые понятия: емкость, отказоустойчивость, производительность
RAID часто выбирают ради спокойствия, но важно разделять два понятия:
- Отказоустойчивость: сервер продолжит работать при поломке диска.
- Сохранность данных: у вас есть копия, которую можно восстановить после удаления, вируса, ошибки администратора или сбоя контроллера.
RAID повышает доступность, но не заменяет бэкапы.
В основе большинства уровней RAID всего две идеи. Striping - данные режутся на полосы и пишутся сразу на несколько дисков, поэтому растет скорость, но один отказ может уничтожить весь массив. Mirroring - данные дублируются на другой диск, чтение часто быстрое, но полезная емкость уменьшается.
Емкость и надежность сильно зависят от числа дисков и их размера. Чем больше диск, тем дольше идет перестройка (rebuild) после замены, а значит дольше период повышенного риска. Чем больше дисков в массиве, тем выше шанс, что за годы работы один из них выйдет из строя.
Производительность тоже не сводится к уровню RAID. На результат влияют тип нагрузки (мелкие запросы или большие файлы), кэш и его защита у RAID-контроллера, интерфейс и класс дисков (HDD против SSD), а также реализация (аппаратный контроллер, HBA с программным RAID или софт-RAID).
Например, в типовом сервере для бухгалтерии и файлового архива на 8 дисках один и тот же RAID 6 может вести себя по-разному: с хорошим контроллером и кэшем запись будет заметно быстрее, чем на простом HBA без ускорения. Поэтому выбор начинается не с цифры RAID, а с понимания, что вы защищаете и какой простой недопустим.
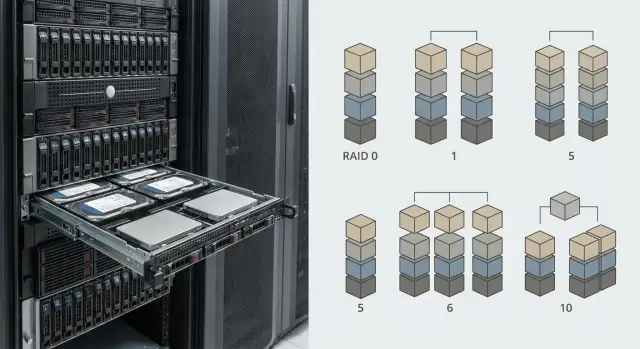
Короткий разбор уровней RAID 0/1/5/6/10
Когда говорят про уровни RAID для надежности данных, легко запутаться: одни дают скорость, другие - защиту, третьи пытаются совместить и то и другое. Ниже - практичный взгляд на самые популярные варианты.
- RAID 0 (striping): максимальная скорость и полный объем, но отказ одного диска = потеря всего массива. Подходит для временных данных: кэш, тестовые стенды, промежуточные файлы, которые можно быстро пересоздать.
- RAID 1 (mirror): данные дублируются на двух дисках. Просто и надежно, чтение часто быстрое, но полезная емкость вдвое меньше. Уместен для системного раздела или небольших критичных наборов данных.
- RAID 5 (parity): баланс по объему и защите (переживает отказ одного диска). Запись обычно медленнее из-за вычисления четности, а rebuild может быть долгим и рискованным на больших дисках.
- RAID 6 (double parity): выдерживает два одновременных отказа, что особенно важно при длинном rebuild. Цена - меньше полезного объема и заметнее просадка скорости записи.
- RAID 10 (mirror + stripe): сочетает зеркалирование и полосование. Часто дает более предсказуемую производительность и проще переживает восстановление, но примерно половина емкости уходит на зеркала.
Простой ориентир: для файлового хранилища отдела, где важнее объем, чаще смотрят на RAID 6. Для базы данных или виртуализации, где много мелких записей и важна стабильная задержка, чаще выигрывает RAID 10.
И оговорка, которую лучше держать в голове постоянно: RAID помогает пережить отказ диска, но не спасает от удаления, шифровальщика или ошибок приложения.
Скорость: что реально ускоряет, а что тормозит
Скорость RAID почти всегда упирается не в название уровня, а в характер операций: чтение или запись, мелкие запросы или длинные последовательные потоки. Один и тот же набор дисков может показывать разные цифры на разных задачах.
Чтение и запись: где теряется время
Чтение обычно дается проще. В RAID 0/5/6 данные читаются параллельно с нескольких дисков, и на больших файлах это дает прирост.
Запись часто становится "дорогой", особенно там, где есть четность. В RAID 5 и RAID 6 на небольших случайных записях появляется штраф: нужно прочитать старые блоки, посчитать новую четность и записать несколько блоков. RAID 10 чаще выигрывает на записи, потому что пишет "зеркально", без расчета parity.
Если сильно упростить:
- много мелких записей (база данных, 1С, почта) - чаще лучше RAID 10, хуже RAID 5/6;
- много чтения и больших файлов (архивы, раздача контента) - RAID 5/6 часто достаточно;
- почти только чтение (каталоги, справочники) - разница между уровнями может быть меньше, чем кажется.
IOPS против потоков и роль кэша
Мелкие операции (IOPS) зависят от задержек, очередей и того, как контроллер обрабатывает запросы. Большие последовательные потоки зависят от ширины массива и скорости дисков.
Кэш контроллера и режим write-back могут сильно ускорить запись: система подтверждает операцию быстрее, а на диски данные уходят "пакетом". Но это безопасно только при защите кэша от потери питания (батарея или суперконденсатор). Иначе при отключении электричества можно потерять последние записи.
На поведение также влияют размер stripe, выравнивание разделов, тип файловой системы, глубина очереди, фоновые проверки (scrub) и то, идет ли сейчас rebuild. Поэтому файловый сервер с крупными документами может отлично чувствовать себя на RAID 6, а та же полка дисков под базой начнет тормозить на мелких транзакциях.
Риски rebuild: время, второй отказ и скрытые ошибки
Rebuild (восстановление массива) начинается после замены сбойного диска: система заново пересчитывает данные и записывает их на новый накопитель. На больших дисках это занимает много часов или даже сутки, потому что нужно прочитать огромный объем данных и паритета.
Во время rebuild массив становится более уязвимым. Для уровней, где допускается только один отказ (например, RAID 5), второй сбой в этот период часто означает потерю всего массива. Чем дольше идет восстановление, тем дольше окно риска.
Есть и менее очевидная опасность: URE (невосстанавливаемая ошибка чтения) и "тихая" порча данных. Во время rebuild система активно читает остальные диски. Если на одном из них есть проблемные сектора, чтение может сорваться. В зависимости от уровня RAID и реализации это приводит либо к повреждению части данных, либо к остановке восстановления.
Обычно помогают базовые меры: регулярные проверки массива (scrubbing, patrol read), мониторинг SMART, адекватная нагрузка на время rebuild и нормальные резервные копии (именно они спасают в худших сценариях).
Нагрузка во время rebuild почти всегда заметна пользователям: растут задержки, а запись на RAID с паритетом может ощутимо замедлиться. Поэтому rebuild лучше планировать на менее загруженные часы и заранее закладывать запас по производительности.
Какие уровни подходят под разные нагрузки
Универсального RAID нет: один и тот же массив может быть отличным для чтения файлов, но слабым местом для виртуализации или базы данных. Если нужен выбор RAID под нагрузку, ориентируйтесь на профиль запросов и допустимый простой.
Быстрые рекомендации по типам задач
Чаще всего на практике получается так:
- Общие папки и файловые хранилища: RAID 6, если дисков много и важна защита от второго отказа во время rebuild. RAID 5 - только при умеренных объемах и если длительное восстановление не критично.
- Виртуализация (много ВМ): RAID 10 из-за более предсказуемой задержки и лучшей работы со смешанным чтением/записью.
- Базы данных и транзакционные системы: RAID 10 обычно самый спокойный вариант. RAID 6 возможен, но запись тяжелее, и нагрузка на контроллер выше.
- Видеонаблюдение и потоковая запись: часто выбирают RAID 6 или RAID 5, но при большом числе камер и постоянной записи RAID 6 обычно безопаснее.
- Архивы и дисковые бэкапы: RAID иногда лишний. Для резервных копий важнее разнесение и проверка восстановления, чем "красивый" массив.
Как не промахнуться в реальности
Представьте сервер под офис: общие документы, почта, 1С и несколько виртуальных машин. Если дисков немного и нужна простота - RAID 10 даст ровную работу и быстрый rebuild. Если дисков много и вы больше про объем (например, файловый архив отдела), RAID 6 даст лучшую защиту, но восстановление будет дольше, а полезный терабайт выйдет дороже.
В стойковых серверах выбор тоже часто делят по важности данных: RAID 10 на быстрых дисках для критичных сервисов и отдельный RAID 6 для емких хранилищ. В таких сценариях важно не складывать в один массив базу и архив "ради удобства".
Пошагово: как выбрать RAID без лишней теории
Начните с простого: что для вас хуже - простой сервиса на несколько часов или потеря части данных? Если простой критичнее (касса, почта, база клиентов), нужен упор на отказоустойчивость и быстрый возврат в работу. Если данные важнее всего (архивы, медицинские записи), выбирайте схему, где ниже риск потери во время отказов и восстановления.
Дальше посчитайте емкость и рост. Берите не впритык, а с запасом на 1-3 года: новые проекты, логи, рост пользователей. Переполненный массив почти всегда работает хуже и сложнее переживает восстановление.
Затем оцените нагрузку. Много мелких записей (базы данных, виртуальные машины) чувствительны к задержкам и штрафу на запись. Большие последовательные файлы (видеоархив, обменник) чаще упираются в пропускную способность.
Рабочий порядок выбора выглядит так:
- сформулировать цель (минимальный простой или минимальный риск потери);
- оценить объем сейчас и рост на 1-3 года;
- описать нагрузку (чтение или запись, мелкие операции или крупные файлы);
- подобрать уровень RAID и число дисков под условия и бюджет;
- заложить hot spare и понятный план замены.
Пример: сервер для бухгалтерии и 1С с мелкими записями чаще разумнее строить на RAID 10 (4-8 дисков), чем на RAID 5 при тех же дисках. А для файлового архива RAID 6 обычно безопаснее, чем RAID 5, особенно на больших дисках.
Hot spare - не "роскошь". Он сокращает время между отказом и началом rebuild, а значит уменьшает окно риска.
Пример из практики: офисные сервисы и важные документы
Сценарий простой: небольшая школа или госорган. Есть файловая папка с документами, почта или совместная работа, и 1С (часто как виртуальная машина). Команда небольшая, а данные важные, поэтому цель обычно не рекорды скорости, а минимальные простои и понятные действия при сбоях.
Разумный подход - разделить нагрузки. Для критичных виртуальных машин (1С, контроллер домена, базовые сервисы) выбирают RAID 1 или RAID 10: он проще переживает отказ диска и быстрее восстанавливается, что снижает риски в рабочее время.
Для файлового хранилища, где главное - объем и спокойная работа с документами, часто берут RAID 6. Он выдерживает отказ двух дисков, что полезно, если диски большие и rebuild идет долго. Да, полезная емкость меньше, но для архива документов этот компромисс обычно оправдан.
Чтобы RAID действительно добавлял надежности, к нему стоит добавить несколько дисциплинированных вещей: hot spare, мониторинг массива и дисков, регламент проверок и тестовое восстановление из резервной копии хотя бы раз в квартал.
По бюджету это обычно выглядит так: RAID 10 для критичных VM дороже по дискам, зато снижает риск простоя. RAID 6 для файлов дает больше объема, но чаще медленнее на записи и требует аккуратности во время rebuild.
Частые ошибки и ловушки при выборе RAID
Главная ошибка - считать RAID страховкой от любых проблем с данными. Он защищает в основном от отказа диска (иногда двух), но не от удаления, шифровальщика, ошибок администратора и сбоев приложения. Поэтому RAID - про доступность сервиса, а бэкапы - про возможность вернуть данные.
Вторая ловушка - собрать массив из дисков "что было": смешать модели, объемы и партии. Это иногда работает, но усложняет прогноз по отказам и заменам. А диски из одной партии часто стареют одинаково и могут выйти из строя близко по времени. Лучше заранее определить, какие диски считаются допустимой заменой, и держать хотя бы один совместимый запасной.
RAID 5 по привычке выбирают даже для очень больших дисков. Проблема в том, что rebuild идет долго, а в это время массив уязвим. Если у вас диски 12-20 ТБ и выше, особенно трезво сравните RAID 5 vs RAID 6 и подумайте о RAID 10 для критичных записей.
Проверки тоже часто пропускают. Минимальный набор, который экономит нервы: регулярный просмотр SMART и счетчиков ошибок, плановый scrub/patrol read, тест восстановления из бэкапа (а не только "отчет успешно"), а также проверка, что сервер и контроллер действительно отправляют понятные уведомления о деградации.
Наконец, не стоит держать "один RAID на все". База данных, файловый архив, видеонаблюдение и бэкапы имеют разный профиль нагрузки. Часто два массива или разнесение по задачам дает меньше сюрпризов при росте и при восстановлении.
Быстрый чеклист перед покупкой и настройкой
Перед тем как заказывать диски и собирать массив, проверьте не только уровень RAID, но и то, что будет вокруг него. Именно это часто решает, превратится ли отказ диска в пару часов работы или в неделю простоя.
Сначала закрепите базовую гигиену: RAID не заменяет резервные копии. Если данные важные, держите отдельные копии хотя бы по упрощенной схеме 3-2-1: несколько копий, на разных типах носителей, одна копия отдельно от сервера.
Дальше - бэкапы должны проверяться восстановлением. Практичный сценарий: раз в месяц выбирайте одну папку или одну виртуальную машину и восстанавливайте в отдельное место. Это быстро показывает, что реально поднимается, а что нет.
И еще до запуска настройте контроль железа: мониторинг дисков (SMART, ошибки контроллера) и уведомления о деградации массива, чтобы вы узнали о проблеме сразу.
Короткий список, который стоит закрыть заранее:
- есть отдельные копии данных (упрощенный 3-2-1);
- бэкапы проверяются восстановлением;
- настроены мониторинг и уведомления;
- предусмотрены hot spare и запас дисков на замену;
- есть понятный план действий при отказе.
Еще один момент, который часто забывают: договоритесь, кто и как действует при инциденте. Если массив ушел в деградацию ночью, а утром бухгалтерия не может открыть базу, без ролей и шагов начинается хаос.
Если сервер покупается для организации, где важны сроки ремонта и стабильность (госструктуры, медицина, финансы), заранее уточняйте поддержку и доступность замены. У производителей и интеграторов с сервисной сетью по стране, вроде GSE.kz, это обычно проще организовать: запасы, регламенты и реакция на инциденты закладываются сразу.
Когда RAID недостаточно: другие подходы к надежности данных
RAID защищает в основном от отказа диска. Он не спасает от случайного удаления, вируса-шифровальщика, ошибки администратора или повреждения данных на уровне файловой системы. Поэтому даже правильно выбранные уровни RAID для надежности данных должны быть только частью плана.
Самые полезные дополнения - бэкапы, снапшоты и репликация. Снапшоты удобны для быстрых откатов (например, после неудачного обновления). Бэкап нужен, чтобы пережить худшие сценарии (шифровальщик, удаление, пожар). Репликация помогает сократить простой, если важны часы и минуты.
Часто помогает и простой прием: разделить задачи по разным массивам. Например, вынести базу на отдельный RAID, а архивы и "файлопомойку" - на другой. Так нагрузка не мешает сама себе, а rebuild не "роняет" все одновременно.
Если данных много и рост быстрый, иногда уместны распределенные хранилища и erasure coding. Это дает гибкость по масштабированию, но заметно повышает требования к поддержке и мониторингу.
Следующие шаги: как превратить выбор RAID в рабочую систему
После того как вы выбрали RAID, закрепите решение так, чтобы оно работало в реальной жизни. Начните с двух цифр для бизнеса:
- RPO - сколько изменений можно потерять (часы или дни).
- RTO - как быстро сервис должен вернуться в работу.
Например, для бухгалтерии RPO в 1 день иногда терпим, а для базы заказов - нет. Эти цифры быстро показывают, хватит ли одного RAID или нужны частые бэкапы, репликация, второй сервер.
Дальше соберите понятную спецификацию, чтобы не было сюрпризов при закупке и настройке: уровень RAID и число дисков (с учетом полезной емкости), hot spare, тип и класс дисков, контроллер (кэш и защита кэша), план расширения на следующий год.
Затем запланируйте поддержку: оповещения о деградации массива, регламент замены диска, где лежит запас, кто отвечает за действия и как фиксируются шаги. И главное - тестируйте восстановление из резервной копии.
Если RAID строится на сервере под высокой нагрузкой и с требованиями к сопровождению, заранее проверьте совместимость дисков, контроллера и прошивок, а также продумайте, кто будет отвечать за интеграцию и поддержку 24/7. В таких проектах логично смотреть на производителей и интеграторов, которые закрывают железо и сервис в одной модели поддержки, например GSE.kz (gse.kz), особенно когда важны сроки реакции и понятный жизненный цикл оборудования.
FAQ
Зачем вообще нужен RAID, если можно просто делать бэкапы?
RAID нужен в первую очередь для **доступности**: чтобы сервер продолжал работать при отказе одного (иногда двух) дисков и вы могли заменить диск без остановки сервиса. К сохранности данных RAID относится косвенно: он не защищает от удаления, шифровальщика, логической порчи базы или ошибок администратора.
Правда ли, что RAID заменяет резервное копирование?
Нет. RAID защищает в основном от **отказа диска**, а бэкап — от **потери данных по любым причинам**. Минимум, что стоит иметь помимо RAID: - отдельные резервные копии (не на том же массиве); - регулярную проверку восстановления; - понятный план действий при инциденте.
Какой RAID лучше для 1С и других баз данных?
Для 1С чаще всего важны **мелкие записи** и стабильная задержка, поэтому по умолчанию безопасный выбор — **RAID 10**. RAID 6 возможен, но запись обычно тяжелее (из-за паритета), и во время rebuild просадка может быть заметнее.
Что выбрать для файлового сервера с документами: RAID 5 или RAID 6?
Для общих папок и архивов обычно выбирают **RAID 6**, особенно если дисков много и/или они большого объема — так вы переживете два отказа диска. RAID 5 имеет смысл только при умеренных объемах и когда вы готовы к более рискованному восстановлению при длинном rebuild.
Когда RAID 0 — нормальный вариант, а не ошибка?
Если нужна максимальная скорость и данные можно легко пересоздать, подойдет **RAID 0**. Практичные примеры: - временные данные и кэш; - тестовые стенды; - промежуточные файлы в обработке. Для важных данных RAID 0 — плохая идея: отказ одного диска обычно означает потерю всего массива.
Почему все так боятся rebuild и что там реально может пойти не так?
Главный риск — **долгий rebuild**. Пока идет восстановление, массив работает в более уязвимом режиме: для RAID 5 второй отказ часто означает потерю массива. Кроме времени есть риск ошибок чтения на оставшихся дисках (URE). Поэтому важно иметь бэкапы и следить за состоянием дисков до аварии, а не после.
Нужен ли hot spare и когда он реально полезен?
Hot spare сокращает время между отказом диска и стартом rebuild: контроллер начинает восстановление автоматически, без ожидания, пока вы приедете и вставите новый диск. Это уменьшает «окно риска», особенно ночью, в выходные и в организациях без постоянного дежурства.
От чего на самом деле зависит скорость RAID, кроме самого уровня?
Смотрите не на «уровень RAID», а на сочетание факторов: - **тип нагрузки** (много мелких операций или большие файлы); - **кэш контроллера** и режим записи; - защита кэша от потери питания (батарея/суперконденсатор); - класс дисков (HDD/SSD) и их количество. Один и тот же RAID 6 может быть быстрым с хорошим контроллером и заметно медленнее на простом HBA.
Можно ли держать базу, файлы и бэкапы на одном RAID «для удобства»?
Не стоит. Разные задачи конфликтуют по нагрузке и по последствиям rebuild. Практичный подход: - отдельный массив (часто RAID 10) для баз/ВМ; - отдельный массив (часто RAID 6) для архивов и файлов. Так проще прогнозировать производительность и меньше шанс, что восстановление «положит» все сервисы сразу.
Что делать, если одного RAID все равно недостаточно для надежности?
RAID — только часть схемы. Дальше обычно добавляют: - **бэкапы** с проверкой восстановления; - **снапшоты** для быстрых откатов после обновлений/ошибок; - **репликацию** или второй узел, если простой должен быть минимальным; - мониторинг и регламенты замены. Если система критичная (госорганизации, медицина, финансы), имеет смысл заранее обсудить требования к RTO/RPO и поддержку 24/7 — с интегратором это часто проще оформить в рабочие процессы.