Сравнение Kafka RabbitMQ NATS ActiveMQ для корпоративных систем
Сравнение Kafka RabbitMQ NATS ActiveMQ для корпоративных систем: гарантии доставки, транзакционность, мониторинг, и реальная стоимость сопровождения.
Зачем корпоративной системе message broker
В корпоративной интеграции брокер сообщений нужен там, где системам важно обмениваться событиями и заданиями без тесной связки. Вместо того чтобы каждый сервис вызывал каждый напрямую, продюсеры публикуют сообщения в брокер, а получатели забирают их, когда готовы.
Синхронные API хороши для запросов в стиле «дай ответ прямо сейчас», но они плохо переживают пики нагрузки и зависят от доступности партнера. Если бухгалтерия или склад недоступны 10 минут, прямые вызовы начинают сыпаться, пользователи видят ошибки, а данные легко потерять. Асинхронная очередь позволяет принять запрос, положить его в буфер и обработать позже.
На практике боль обычно не в том, как отправить сообщение, а в том, что происходит при сбоях: сообщения теряются, дублируются на ретраях, растет задержка, а диагностика превращается в угадайку. Поэтому в сравнении Kafka, RabbitMQ, NATS и ActiveMQ важно сразу понять, какие сценарии вы закрываете и какую цену платите за надежность.
Чаще всего брокер помогает:
- переживать временные падения зависимых систем без потерь
- разгружать пики нагрузки через буферизацию
- отделять скорость продюсеров от скорости консюмеров
- упрощать маршрутизацию событий между множеством систем
- делать обработку повторяемой и управляемой
Почти всегда в проекте участвуют несколько команд. Разработка проектирует контракты сообщений и идемпотентность, эксплуатация отвечает за стабильность и мониторинг, безопасность задает правила доступа, шифрование и аудит. Если хотя бы одна сторона подключается поздно, «технический» выбор брокера быстро превращается в организационную проблему.
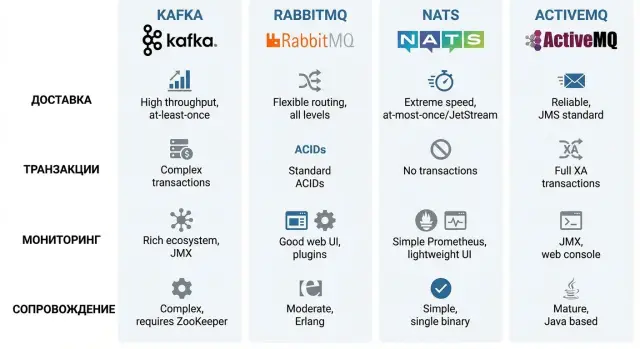
Kafka, RabbitMQ, NATS, ActiveMQ - в двух словах
Kafka чаще выбирают не как «очередь задач», а как журнал событий. Сообщения хранятся на диске, их можно перечитывать, подключать несколько независимых потребителей и восстанавливать состояние сервиса из истории. Это удобно для аналитики, событийных интеграций и потоковой обработки, но требует дисциплины в схемах данных и аккуратного управления ретеншном и партициями.
RabbitMQ - классический брокер очередей с сильной маршрутизацией: очереди, exchange, разные типы доставки и понятные паттерны (work queue, pub/sub, request/reply). Обычно он удобен для сценария «передай задачу воркеру и получи подтверждение», особенно когда важны гибкие правила маршрутизации и быстрый старт.
NATS - легковесный брокер для низких задержек и простого pub/sub. В базовом режиме он про скорость и минимализм. Если нужны хранение, подтверждения и повторная доставка, обычно включают JetStream, и тогда это уже другой режим эксплуатации и другой набор компромиссов.
ActiveMQ - зрелый вариант из мира enterprise-интеграции, часто рядом с JMS и привычными корпоративными подходами к очередям и темам. Он уместен там, где важны совместимость и предсказуемое поведение, но конкретные возможности сильно зависят от версии и конфигурации.
Перед тем как сравнивать, зафиксируйте, что именно вы сопоставляете: продукт или конкретную сборку, режим работы (например, NATS vs NATS JetStream), требования к хранению (сколько и как долго), тип нагрузки (поток событий или очередь задач), модель потребления (один потребитель, группа, несколько независимых читателей).
Как сравнивать: критерии и вопросы к требованиям
Чтобы сравнение Kafka, RabbitMQ, NATS и ActiveMQ было полезным, начните не с названий, а с того, что именно вы переносите через брокер: события, команды, документы, логи. От этого зависят требования к надежности, хранению и скорости.
Соберите вводные в одном месте, коротко и конкретно: пики по сообщениям, средний размер, насколько критична потеря, нужно ли хранить поток неделями или достаточно минут.
Вопросы, которые быстро проясняют выбор
Ответьте на них до пилота:
- Какие SLO вам реально нужны: допустимая задержка, доступность, и за сколько минут или часов система должна восстановиться после сбоя.
- Сколько будет потребителей и кто они: микросервисы, интеграции с ERP/CRM, аналитика, внешние контрагенты.
- На каких языках пишут команды и какие клиенты им удобны: это влияет на время внедрения и поддержку.
- Что важнее в вашем кейсе: строгий порядок, повторное чтение истории, сложная маршрутизация или простота для разработчиков.
Затем проверьте ограничения, которые часто ломают планы ближе к финалу. Например, если инфраструктура изолирована и действуют внутренние регламенты по сертификации и доступам, часть вариантов отпадет независимо от функциональности.
Мини-сценарий для проверки требований
Представьте цепочку: касса отправляет продажу, склад списывает остатки, бухгалтерия формирует проводки, аналитика считает отчеты. Если аналитике нужно перечитывать историю за месяц, требования будут одни. Если важнее, чтобы склад реагировал за секунды и не путал порядок, акценты сместятся.
Гарантии доставки и как жить с повторами
Обычно выделяют три уровня доставки: at-most-once (иногда теряем, но без дублей), at-least-once (не теряем, но возможны повторы) и exactly-once (звучит красиво, но почти всегда с оговорками). В реальной эксплуатации большинство корпоративных интеграций живет в режиме at-least-once и учится спокойно относиться к дублям.
Если говорить упрощенно: Kafka по умолчанию дает надежное at-least-once и неплохо переживает временные проблемы с потребителями; RabbitMQ и ActiveMQ чаще строятся вокруг подтверждений (ack) со стороны consumer; NATS в базовом режиме ближе к «доставили и забыли», а надежная доставка обычно связывается с JetStream и его настройками подтверждений и хранения.
Механика надежности упирается в базовые вещи: продюсер должен понимать, что сообщение принято (ack), консюмер должен подтверждать обработку, а система должна уметь повторять попытки при сбоях. Повторы появляются не потому, что «кто-то ошибся», а потому что в момент сбоя непонятно, успела ли обработка завершиться.
Чтобы дубли не ломали бизнес-логику, заранее закладывают защиту: идемпотентность обработчика, уникальный ключ (например, order_id + версия), дедупликацию на стороне хранилища (уникальный индекс или таблица обработанных id), аккуратные ретраи с лимитами, чтобы не устроить шторм.
DLQ (очередь проблемных сообщений) нужна, когда часть событий будет «битой» или потребует ручного разбора. Не усложняйте: на старте достаточно договориться, сколько ретраев делаете и кто отвечает за разбор DLQ.
Практическая проверка простая: запустите потребителя, обработайте 100 сообщений, затем «уроните» его посередине (или обрубите сеть) и посмотрите, что будет после перезапуска. Хороший результат - потерь нет, а повторы либо безопасны, либо отфильтрованы по ключам.
Транзакционность и точно-один-раз: что реально
Транзакция в брокере сообщений не равна транзакции в базе данных. В БД вы фиксируете изменение данных. В брокере - факт публикации (а иногда еще и чтение) сообщения. Проблема начинается на стыке: запись в БД и отправка события происходят в разных системах, и «одной кнопкой» зафиксировать их вместе обычно нельзя.
Exactly-once почти никогда не является магической опцией. Это набор условий и дисциплины. У Kafka есть транзакции и идемпотентный продюсер, и это помогает внутри ее модели. Но end-to-end «точно один раз» между сервисами все равно упирается в обработчики, базы, повторные попытки и сетевые сбои. Часто дешевле принять «как минимум один раз» и сделать обработку устойчивой к повторам.
Самый практичный способ согласовать БД и события - паттерны outbox и inbox. Пример: сервис выставления счетов записывает счет в свою БД и туда же, в таблицу outbox, кладет событие «Счет создан». Отдельный процесс читает outbox и публикует в брокер. На стороне потребителя inbox хранит уже обработанные message_id, чтобы повтор не ломал данные.
Если распределенные транзакции слишком тяжелые, нормальны компенсации: «заказ создан» и «заказ отменен» вместо попытки откатить все сразу.
Чтобы это работало предсказуемо, правила обработки лучше закрепить в контракте команды или события: уникальный message_id и ключ идемпотентности, какие повторы допустимы и как их распознавать, что считается успехом обработки (и что делать при частичном успехе), сроки хранения и порядок (где обязателен, а где нет), какие компенсационные действия разрешены.
Порядок, хранение и повторное чтение сообщений
Разница между брокерами не только в скорости, а в том, как они хранят сообщения и как потребители их читают.
Очередь и топик задают разную модель. Очередь обычно означает, что сообщение забирает один из потребителей, и дальше оно исчезает (или уходит в DLQ при ошибке). Топик ближе к журналу: несколько групп потребителей могут читать одно и то же, а данные живут по правилам ретеншна.
Порядок тоже имеет цену. Строгий порядок чаще гарантируется только внутри одного потока (например, внутри очереди или партиции). Чем жестче требование к порядку, тем меньше свободы для параллелизма: аккуратнее ключи распределения, осторожнее масштабирование, больше ожиданий при сбоях. Если бизнесу важен порядок только «внутри клиента» или «внутри заявки», это обычно решают ключом, чтобы все события одной сущности шли в один поток.
Хранение и ретеншн важны, когда нужен replay. В интеграции бухгалтерии, склада, сервис-деска и других систем они часто расходятся во времени, и возможность восстановить состояние из потока событий становится практичной страховкой.
Заранее решите, где нужен replay: пересчет витрины или отчета за период, восстановление после падения потребителя, подключение нового сервиса к прошлым событиям, расследование инцидента по временной линии.
Отдельная тема - схемы данных. Без версионирования форматов (хотя бы правило «добавляем поля, не ломаем старые») повторное чтение быстро превращается в боль: старые сообщения должны оставаться понятными новым потребителям.
Мониторинг и диагностика в продакшене
В продакшене брокер сообщений ценен ровно до первой ночной аварии. Мониторинг должен отвечать на вопрос «где причина» (клиент, сеть, брокер, диск), а не просто показывать «что-то не так».
Базовые метрики, без которых нельзя
Смысл метрик примерно одинаков для Kafka, RabbitMQ, NATS и ActiveMQ, даже если названия разные:
- отставание потребителей (lag) и динамика его роста
- входная и выходная скорость (messages/sec, bytes/sec)
- ошибки публикации и потребления, доля отказов
- ретраи и размер очередей повторной доставки (или DLQ, если она есть)
- заполнение диска и скорость роста (для систем с хранением)
Метрики важно связывать с контекстом: какой сервис, какой топик или очередь, какой тип сообщений. Тогда вы видите не «упал брокер», а «сервис биллинга перестал успевать».
Логи, трассировка и алерты, которые не игнорируют
Логи брокера полезны, но чаще показывают симптом. Причину быстрее всего дает связка: корреляционный id в сообщении, структурированные логи клиента и распределенная трассировка (если она есть в системе).
Алерты должны быть редкими и понятными. Рабочие примеры:
- lag растет непрерывно 10-15 минут и не уменьшается при нормальной входной скорости
- диск выше 80% или прогноз заполнения меньше суток
- доля ошибок публикации больше 1% за 5 минут
- ретраи или DLQ растут быстрее, чем обрабатываются
Отдельно следите за «здоровьем» кластера (доступность узлов, репликация, выбор лидеров) и клиентов (число переподключений, таймауты, версии протокола).
Для эксплуатации нужен дашборд «что горит сейчас». Для бизнеса - простой экран: сколько сообщений прошло, сколько в задержке, сколько ушло в ретраи. Тогда эффект интеграции виден не только инженерам.
Безопасность и контроль доступа без лишней бюрократии
В корпоративных системах безопасность брокера сообщений упирается не в «какой продукт лучше», а в то, как вы выдаете доступы и как это живет годами. В сравнении Kafka, RabbitMQ, NATS и ActiveMQ одинаково важны и протоколы, и процессы.
Начните с простого правила: доступы выдаются не людям, а приложениям. Для каждого сервиса заведите отдельную учетку (или сертификат) и ограничьте права на публикацию и чтение только нужными топиками или очередями. Тогда компрометация одного сервиса не открывает весь обмен.
Шифрование трафика (TLS) почти всегда must-have, но «боль» обычно в сертификатах: срок действия, ротация, доверенные центры. Договоритесь с ИБ, кто выпускает сертификаты, как они обновляются, и как быстро вы сможете заменить ключ без простоя.
Разделяйте среды жестко. Если тестовые сервисы читают продовые сообщения «для проверки», это почти гарантированный инцидент. Проще всего держать отдельные кластеры, но иногда достаточно строгих неймспейсов и отдельных учеток, если ИБ это устраивает.
В аудит-логах имеет смысл фиксировать: выдачу и изменение прав, создание и удаление топиков (очередей), неудачные попытки аутентификации, изменения TLS и сертификатов, операции админов в консоли и через API.
Чтобы не делать все руками, согласуйте стандартные роли и шаблоны заявок: «читатель», «публикатор», «админ проекта». Автоматизация через единый каталог и утвержденные политики дает ИБ контроль, а командам - скорость.
Эксплуатация и стоимость сопровождения
Стоимость брокера сообщений редко равна цене лицензии. Основные траты появляются после запуска: обновления, инциденты, настройка производительности, бэкапы, обучение команды и дежурства.
Kafka обычно дороже в эксплуатации из-за требований к дискам и сети. Она много пишет на диск, требует планировать хранение (ретенцию) и внимательно следить за задержками, размером партиций и балансировкой. Это оправдано, когда важны большой поток и повторное чтение, но администрировать ее заметно сложнее.
RabbitMQ часто проще для команды, особенно когда вы решаете задачи очередей и маршрутизации. Но кластеры, политика зеркалирования, большие очереди и «застрявшие» consumers тоже требуют опыта. NATS выбирают за легкость и быстрый старт, но стоимость может вырасти, если вам нужны хранение, воспроизведение и строгие гарантии. ActiveMQ обычно понятен тем, кто давно в Java-стеке, но в крупных установках важно заранее проверить масштабирование и наблюдаемость.
Эксплуатационное время чаще всего съедают: планирование емкости (CPU, RAM, диск, сеть и рост на 6-12 месяцев), обновления и совместимость клиентов, управление схемами и версиями событий, бэкапы и восстановление, инциденты (задержки доставки, повторы, переполненные очереди, отвалившиеся потребители).
Кадровый фактор важен не меньше. Найти инженера с опытом Kafka обычно сложнее и дороже, чем администратора RabbitMQ, а обучение занимает время.
Оценивая TCO, считайте вместе: железо (часто решающее для Kafka), лицензии (если есть), поддержка и, самое неприятное, простои. В корпоративной среде это быстро превращается в вопрос: сколько людей нужно, чтобы система работала предсказуемо 24/7, и есть ли у вас инфраструктура и сервисная поддержка под это.
Отказоустойчивость и масштабирование: практичный взгляд
Отказоустойчивость начинается не с названия продукта, а с того, как он развернут: есть ли кластер, как устроена репликация, кто принимает решение при потере узла (quorum), и что происходит с сообщениями в момент сбоя.
RPO и RTO простыми словами
RPO - сколько данных (сообщений) вы готовы потерять при аварии. RTO - за какое время сервис должен вернуться в работу. Для интеграции между учетной системой и складом RPO часто хотят близким к нулю, а RTO - минутами, иначе копится ручная работа и растет число ошибок.
Чтобы это было не на словах, заранее фиксируйте план восстановления: где хранится состояние, как поднимается новый узел, кто принимает решение о переключении.
Геораспределение и тесты поломок
Геораспределение нужно, когда простой одного дата-центра недопустим. Но оно добавляет риски: задержки, разделение сети (split brain), более сложные обновления и дороже мониторинг. Часто разумнее начать с надежного кластера в одном ЦОД и понятных процедур восстановления.
Проверяйте отказоустойчивость регулярными тестами:
- отключение одного узла кластера во время нагрузки
- потеря сети между узлами (частичная деградация)
- переполнение диска или резкий рост задержек диска
- перезапуск брокера во время активной публикации
- падение клиента-потребителя с последующим восстановлением
Масштабировать стоит там, где узкое место измерено: диск и сеть для хранения и репликации, число партиций или очередей, лимиты соединений, тяжелые потребители. Иначе легко переплатить за лишние узлы, а причина останется в медленном диске, неверных настройках подтверждений или в одном сервисе, который не успевает обрабатывать сообщения.
Как выбрать брокер сообщений пошагово
Начните не с выбора технологии, а с описания ваших событий. Один и тот же брокер может быть отличным для логов, но не подойти для платежей. Сначала зафиксируйте требования, а уже потом сравнивайте возможности.
Рабочий порядок обычно такой:
- Составить карту потоков: кто публикует события, кто читает, что будет, если событие потеряется или придет дважды.
- Определить модель потребления: очередь для команд, pub/sub для уведомлений, стримы и replay для аналитики и восстановления.
- Согласовать доставку и повторы: допускаете ли дубликаты, как делаете идемпотентность, какие лимиты на ретраи и что уходит в dead-letter.
- Продумать наблюдаемость: обязательные метрики (lag, скорость, ошибки), алерты, регламент разбора инцидентов.
- Сделать пилот на 1-2 реальных интеграциях и измерить задержку, нагрузку, сложность эксплуатации, время восстановления после сбоя.
После пилота закрепите стандарты: формат события и версионирование, правила ключей и партиционирования, сроки хранения (retention) и политику доступа.
Простой пример: для интеграции учетной системы и склада потеря события недопустима, а повтор возможен. Значит, вы заранее закладываете дедупликацию у потребителя и проверяете, как это работает при сбоях в тестовом кластере.
Пример сценария: интеграция нескольких систем без потерь
Представим компанию, где учетная система создает заказ, CRM ведет клиента, а портал заявок принимает обращения от сотрудников и партнеров. Каждое изменение превращается в событие: «Заявка создана», «Заказ оплачен», «Контакт обновлен». Эти события уходят в брокер сообщений, а остальные системы подписываются и обновляют свои данные.
Требования простые и жесткие: заявки терять нельзя, повторы допустимы, нужен аудит, чтобы потом ответить на вопрос «кто и когда обработал событие».
Чтобы не терять события и спокойно жить с повторами, обычно хватает нескольких правил: подтверждать обработку только после успешной записи в свою базу (ack после коммита), делать ретраи с паузой и ограничением по числу попыток, отправлять безнадежные сообщения в DLQ, добавлять ключ идемпотентности (например, request_id) и хранить отметку «уже обработано», писать минимальный аудит (id события, время, результат, ошибка).
Состояние интеграции видно не по «все зеленое», а по метрикам: lag, число ошибок у потребителей и время обработки. Если время выросло в 2 раза, пользователи почувствуют это раньше, чем сервис упадет.
По сопровождению заранее решите, кто дежурит и что делается ночью без разработчиков. Держите короткие runbook: как остановить потребителя, как безопасно переиграть DLQ, как увеличить лимиты, как найти «ядовитое» сообщение. Автоматизируйте алерты и типовые действия, чтобы не собирать чат из 10 людей при каждой просадке.
Частые ошибки при внедрении и как их избежать
Брокер сообщений редко ломает интеграцию сам по себе. Чаще проблема в ожиданиях: команда думает, что «правильные настройки» заменят аккуратную работу с данными и процессами.
Ошибки, которые дорого обходятся
Типичные проблемы в продакшене:
- Пытаться «вылечить» бизнес-логику параметрами брокера. Работает другое: идемпотентные обработчики, уникальные ключи сообщений, дедупликация и понятные правила повторов.
- Сваливать разные типы событий в один топик или очередь «для простоты». Лучше разделять каналы по смыслу, иметь явные контракты, версию схемы и правила обратной совместимости.
- Не планировать хранение. Ретеншн, рост дисков, место под пики и бэкапы нужно считать до запуска, иначе внезапно закончится диск и остановится весь поток.
- Не проверять падения и сеть, но ждать высокой надежности. Нужны тесты: отключение узла, задержки, разрывы связи, переполнение очередей и восстановление.
- Иметь мониторинг, но не иметь реакции. Должны быть пороги, ответственные, время реакции и понятный план действий.
Мини-сценарий из практики
Если бухгалтерия отправляет платежи, а склад подтверждает отгрузку, повторное сообщение может создать дубль операции. Решение простое: каждый платеж и отгрузка получают уникальный идентификатор, а потребитель хранит статус обработки и игнорирует повторы. Тогда сбой сети превращается в задержку, а не в финансовый инцидент.
Короткий чеклист и следующие шаги
Перед выбором между Kafka, RabbitMQ, NATS и ActiveMQ полезно быстро проверить требования, а не названия. Один и тот же брокер может быть идеальным или болезненным в зависимости от того, что важнее: повторное чтение, строгий порядок, простое сопровождение или минимальная задержка.
Чеклист по поведению сообщений (ответы лучше фиксировать письменно):
- Какая доставка нужна: at-least-once, at-most-once, есть ли реальные требования к exactly-once
- Нужен ли порядок: по всему потоку или только по ключу (заказ, клиент, устройство)
- Как делаете ретраи: сколько попыток, какие задержки, где держите «зависшие» сообщения
- Есть ли DLQ и кто ее разбирает: команда, регламент, сроки
- Нужны ли ретеншн и повторное чтение: сколько дней хранить и кто будет перечитывать
Отдельно проверьте эксплуатацию, она часто важнее теории про гарантии:
- План обновлений: кто и как делает rolling update, есть ли окно работ
- Емкость: прогноз трафика на 6-12 месяцев, пики, запас по диску и сети
- Мониторинг и алерты: задержка обработки, размер очередей, ошибки потребителей, место на дисках
- Бэкапы и восстановление: что реально бэкапится, RPO/RTO, тест восстановления
- Дежурства и эскалации: кто поднимается ночью и что считается инцидентом
До запуска подготовьте контракты сообщений (схема, версии, совместимость), правила именования топиков и очередей, а также регламенты инцидентов: что делать при дублировании, при отставании потребителей и при росте DLQ.
Если систем много, требования ИБ жесткие и нужна работа 24/7, иногда проще подключить интегратора. В проектах такого типа GSE.kz обычно помогает закрыть не только софт, но и практичные вещи вокруг него: расчет инфраструктуры (в том числе на отечественных серверах), настройку мониторинга и организацию поддержки.
Следующие шаги: выберите 1-2 критичных потока, сделайте пилот с реальными нагрузками, посчитайте ресурсы и стоимость сопровождения, затем зафиксируйте SLA и план ввода по этапам.
FAQ
Зачем вообще нужен message broker, если у нас уже есть API?
Брокер нужен, когда сервисам важно обмениваться событиями и заданиями без прямых вызовов друг друга. Он помогает переживать временные недоступности зависимых систем, сглаживать пики нагрузки и отделять скорость продюсеров от скорости консюмеров.
Как понять, что мне нужна Kafka, а не RabbitMQ?
Для задач и команд, где важны подтверждения обработки и гибкая маршрутизация, чаще удобнее RabbitMQ или ActiveMQ. Для потока событий с хранением, возможностью перечитывать историю и подключать новых потребителей задним числом чаще подходит Kafka.
Когда имеет смысл выбрать NATS и что меняется с JetStream?
NATS обычно выбирают, когда важны низкие задержки и простой pub/sub без сложной модели хранения. Если вам нужны подтверждения, повторная доставка и сохранение сообщений, смотрите на режим JetStream и заранее закладывайте его эксплуатацию как отдельный класс сложности.
В каких случаях ActiveMQ — нормальный выбор сегодня?
Если у вас уже есть привычные корпоративные интеграционные подходы, стек на Java и требования к совместимости с JMS, ActiveMQ может быть предсказуемым выбором. Перед финальным решением стоит проверить конкретную версию, режимы кластера и то, как вы будете мониторить и масштабировать установку.
Какие гарантии доставки реально выбирать: at-most-once, at-least-once или exactly-once?
В большинстве корпоративных интеграций практичный базовый режим — **at-least-once**: потерь нет, но возможны повторы. Дальше ключевой вопрос не «как убрать дубли», а «как сделать обработку безопасной при дублях» через идемпотентность и дедупликацию.
Как правильно жить с дублями сообщений, чтобы не ломать бизнес-логику?
Повторы появляются из-за сбоев в момент, когда непонятно, завершилась ли обработка. Типовой минимум — уникальный message_id или бизнес-ключ, идемпотентная логика обработчика и запись факта обработки в свою базу, чтобы повтор распознавался и не менял состояние второй раз.
Что такое DLQ и когда она действительно нужна?
DLQ нужна для сообщений, которые не удалось обработать после понятного числа попыток и пауз между ними. На старте достаточно договориться о лимите ретраев, формате ошибки и ответственном за разбор, иначе DLQ быстро превращается в «склад проблем», который никто не трогает.
Почему «точно один раз» почти никогда не решает все и что делать вместо этого?
Транзакции в брокере и транзакции в базе — разные вещи, и «одной кнопкой» зафиксировать запись в БД и отправку события обычно нельзя. Самый практичный подход — outbox/inbox: событие сначала фиксируется рядом с бизнес-данными, а публикация и защита от повторов делаются отдельной, контролируемой механикой.
Какие метрики и алерты обязательны для брокера в продакшене?
Минимальный набор — lag (отставание потребителей), скорость входа/выхода, доля ошибок публикации и обработки, ретраи и рост DLQ, а также диск и его скорость заполнения для систем с хранением. Важно привязывать метрики к конкретному сервису и очереди/топику, чтобы видеть, кто именно не успевает, а не просто «что-то красное».
Как организовать доступы и шифрование в брокере без постоянных ручных операций?
Начните с отдельной учетки или сертификата на каждый сервис и выдавайте права только на нужные топики или очереди. Почти всегда нужен TLS, а самая частая сложность — ротация сертификатов и быстрый отзыв доступа без простоя, поэтому эти процессы лучше согласовать заранее.