Событийная интеграция между системами: очереди и идемпотентность
Событийная интеграция между системами: как выбрать очередь сообщений, сделать обработку идемпотентной и спокойно переживать повторную доставку.
Какая проблема с событиями возникает на практике
Событийная интеграция между системами на схеме выглядит просто: одна система что-то сделала и отправила событие, другая получила и отработала.
В реальности почти всегда всплывает неприятный факт: одно и то же событие может прийти дважды, а иногда и трижды. Для очередей сообщений и распределенных систем это нормальный режим.
Повторы появляются не потому, что кто-то «плохо сделал», а потому что система пытается быть надежной. Отправитель может не получить подтверждение доставки из-за короткого сбоя сети. Брокер может повторить доставку после рестарта. Потребитель может упасть после обработки, но до фиксации результата, и при запуске увидит сообщение снова. Поэтому гарантия часто звучит как «доставим хотя бы один раз», а не «ровно один раз».
Проблема в том, что дубликат события почти всегда превращается в дубликат действия. Самые болезненные зоны - деньги (повторное списание или возврат), склад (двойное списание остатков), статусы (заявка дважды перескакивает этап), уведомления (два одинаковых письма или SMS).
Плохая интеграция быстро заметна в операционке: цифры не сходятся между системами, появляются ручные правки в таблицах, сотрудники начинают перепроверять каждую операцию, а расследования занимают часы. Иногда это маскируется фразой «иногда оно само чинится», потому что позже приходит еще одно событие и частично исправляет картину.
Предсказуемая интеграция начинается с принятия факта повторов. Обработку строят так, чтобы повторное событие не ломало данные. Тогда система ведет себя одинаково при любом количестве доставок: либо действие выполнено один раз, либо повтор безопасно игнорируется, а итоговое состояние остается правильным.
События и запросы: в чем разница простыми словами
Запрос - это когда одна система прямо спрашивает другую: «Дай мне ответ сейчас». Например, сервис оплаты делает запрос в сервис заказов: «Этот заказ существует?» и ждет ответ.
Событие - это когда система сообщает факт: «У меня что-то произошло». Например: «Заказ создан», «Платеж прошел», «Статус заявки изменился». Никто не обязан отвечать сразу, а получателей может быть несколько.
Удобная аналогия: запрос - как звонок с вопросом, событие - как сообщение в общем чате. В запросе важен мгновенный ответ. В событии важнее, чтобы информация дошла до всех, кому она нужна.
События хорошо подходят там, где меняется состояние и нужно уведомить несколько систем без жестких связей. Это смена статусов, изменения данных, уведомления, аудит.
В событийной схеме есть две роли. Продюсер (producer) публикует событие и не «просит», а «сообщает». Консьюмер (consumer) получает событие и решает, что делать: обновить свою базу, отправить уведомление, запустить расчет.
События почти всегда асинхронные: продюсеру не нужно ждать, пока все консьюмеры обработают сообщение. Он отправил событие в очередь и продолжил работу. Это повышает устойчивость к нагрузке и сбоям, но добавляет новую реальность: события могут приходить позже, не по порядку и иногда повторно.
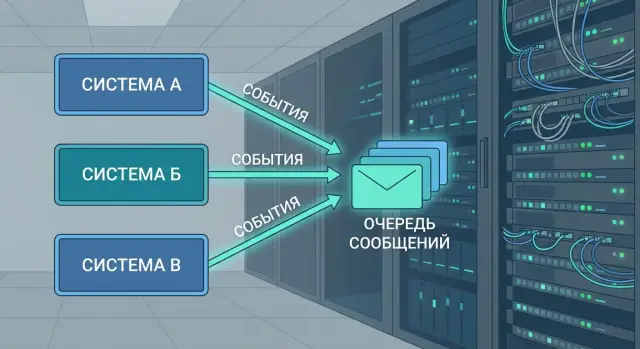
Как работает очередь сообщений и что она дает
Очереди сообщений связывают системы так, чтобы они не зависели друг от друга каждую секунду. Вместо прямого вызова «сделай сейчас» одна система отправляет событие (сообщение) в очередь, а другая забирает его тогда, когда готова.
Очередь работает как буфер. Если потребитель временно недоступен (обновление, сбой, сетевые проблемы), события не теряются сразу, а накапливаются и ждут обработки. Это важно, когда отправитель не должен «падать» только потому, что получатель на паузе.
При пиках нагрузки очередь тоже спасает. Например, в 9:00 много пользователей одновременно создают заявки, и отправитель генерирует всплеск событий. Без очереди получатель может захлебнуться. С очередью всплеск превращается в ровный поток: потребитель обрабатывает сообщения с той скоростью, которую выдерживает, а очередь временно хранит остальное.
Когда потребитель успешно обработал сообщение, он отправляет подтверждение (ack). Это сигнал очереди: «все хорошо, можно считать сообщение доставленным и убрать». Если ack не пришел (потребитель упал, завис, не успел), очередь обычно попробует доставить сообщение снова. Отсюда главный вывод: очередь повышает надежность, но не отменяет необходимость готовиться к повторной доставке.
Еще один миф - что очередь всегда сохраняет идеальный порядок. На практике порядок может нарушаться из-за параллельной обработки несколькими потребителями, повторной доставки после сбоя или особенностей распределенной очереди. Поэтому лучше проектировать обработку так, чтобы она была устойчивой и к дублям, и к «слегка не тому порядку».
Гарантии доставки и почему повторы неизбежны
В очередях сообщений чаще всего встречается гарантия «хотя бы один раз». Она означает честный компромисс: система старается не потерять событие, даже если ради этого придется доставить его повторно.
Повторы появляются не потому, что «очередь сломалась», а потому что реальный мир шумный. Потребитель мог обработать событие, но не успеть подтвердить это очереди. Очередь видит, что подтверждения нет, и отправляет сообщение снова.
Частые причины повторной доставки: таймауты сети, перезапуски потребителя, ретраи на стороне очереди или приложения, длительная обработка (когда сообщение «протухло» по таймеру видимости), конкурентная обработка несколькими экземплярами сервиса.
Почему тогда не сделать «ровно один раз»? Потому что для этого нужен общий «источник правды» о том, что уже обработано, и он должен меняться вместе с бизнес-данными в одной надежной операции. Как только обработка затрагивает базу данных, внешние сервисы, файлы или две разные транзакции, появляется риск: где-то успели, где-то нет. Под нагрузкой и при сбоях это быстро становится дорогой и сложной задачей.
Поэтому для бизнес-событий обычно выбирают «не теряем, но возможны повторы». А дальше требования переходят к коду потребителя: повтор должен быть обычным случаем, а не аварией.
Идемпотентность: что это и где она должна быть
Идемпотентность означает простую вещь: если одно и то же действие выполнить повторно, итог останется тем же, а лишних побочных эффектов не появится. Для событий это критично, потому что повторная доставка случается регулярно: из-за ретраев, сетевых сбоев, перезапуска потребителя.
Важно различать две идеи.
Идемпотентная операция - это бизнес-действие, которое можно безопасно повторить (например, «установить статус заявки в ОПЛАЧЕНО»).
Идемпотентный обработчик события - это код, который получает событие и делает набор шагов так, чтобы повторное получение того же события не ломало данные и не запускало второй раз дорогие действия.
Неидемпотентность быстрее всего проявляется в деньгах и логистике: один и тот же платежный ивент обработали дважды и получили двойное списание; повторили «заказ подтвержден» и отгрузили два раза; начислили бонусы повторно, потому что обработчик «прибавляет», а не приводит к нужному состоянию.
Чаще всего удобнее обеспечивать идемпотентность на стороне потребителя. Издатель событий может быть чужой системой (или их несколько), а вот потребитель отвечает за свои данные и побочные эффекты.
Быстрая самопроверка обработчика:
- есть ли у события уникальный идентификатор, и сохраняете ли вы факт обработки;
- приводите ли вы объект к нужному состоянию, а не делаете «прибавить еще раз»;
- отделены ли необратимые действия (списание, отгрузка, отправка письма) и защищены ли они от повторов.
Если повтор того же события не меняет результат, эксплуатация становится заметно спокойнее.
Базовые приемы защиты от дубликатов
Дубликаты появляются даже в хорошо настроенной очереди: брокер может повторно доставить событие после сбоя сети, таймаута или перезапуска потребителя. Поэтому в событийной интеграции между системами почти всегда нужна защита на стороне потребителя, а не надежда на то, что «повторов не будет».
Основа - уникальный идентификатор события (event_id). Его обычно задает система-источник, потому что именно она создает событие и может гарантировать уникальность в своем контуре. Если event_id генерирует потребитель, вы защититесь только от своих повторов, но не от повторной доставки того же сообщения.
Дальше нужен реестр обработанных событий: таблица в базе, key-value хранилище или отдельная коллекция. Принцип один: перед тем как выполнять действие, вы проверяете, видели ли этот event_id. Если да - подтверждаете сообщение и ничего не меняете. Если нет - выполняете работу и записываете факт обработки.
Чтобы это работало предсказуемо, полезно хранить минимальный контекст: event_id, время первой обработки, статус/результат, ключ сущности (например, order_id, ticket_id), номер попытки (если есть).
Отдельная тема - внешние вызовы в соседние системы. Если потребитель создает платеж, заявку или пользователя через API, нужен идемпотентный ключ (idempotency key). Его передают во внешний запрос так, чтобы повторный вызов не создавал второй объект, а возвращал тот же результат. Часто таким ключом становится event_id или пара «тип события + id сущности».
Пример: событие «Счет оплачен» пришло два раза. Без проверки вы дважды начислите доступ. С реестром обработанных событий второй раз вы увидите тот же event_id и просто пропустите действие, сохранив систему в правильном состоянии.
Пошагово: как сделать потребителя устойчивым к повторам
Повторная доставка - нормальная часть жизни очередей. Если потребитель не готов, одна и та же бизнес-операция может выполниться дважды: списались деньги, два раза выдали доступ, дважды создали заявку. Решение не в запрете повторов, а в устойчивой обработке.
5 шагов, которые работают в большинстве случаев
Сначала договоритесь, что каждое сообщение несет уникальный идентификатор события. Это может быть event_id (UUID) и, если нужно, ключ сущности (например, order_id) и тип события.
Дальше выберите, где хранить факт обработки. Важно, чтобы это было место, которому вы доверяете: обычно база данных потребителя (таблица обработанных событий) или хранилище, доступное тому же сервису.
Затем сделайте обработку и фиксацию результата одним «неделимым» действием. Практичный вариант - в одной транзакции: (1) проверить, не видели ли уже event_id, (2) выполнить бизнес-изменение, (3) записать, что событие обработано. Тогда при повторной доставке вы быстро поймете, что это дубль, и безопасно завершите обработку.
После этого настройте повторные попытки так, чтобы они помогали, а не ломали. Повторы должны быть ограничены по количеству и по времени, а «ядовитые» сообщения должны уходить в отдельный поток для разбора, а не бесконечно крутиться.
Наконец, договоритесь о правилах изменения схемы события. Добавляйте поля так, чтобы старые потребители могли их игнорировать, и явно передавайте версию (или хотя бы тип и дату изменения). Это снижает риск, что повторная доставка старого события сломает новый код.
Реалистичный пример: статус заявки и двойная обработка
Представьте госорганизацию: в одной системе живет заявка на закупку, а бухгалтерия ведет проводки в другой. Когда заявка меняет статус, интеграция отправляет событие в очередь сообщений.
Критичный момент начинается на статусе «Оплачено». Потребитель в бухгалтерии получает событие и создает проводку. Но очередь может доставить то же событие еще раз (например, после таймаута подтверждения). Если потребитель не защищен, результат простой: двойная проводка, лишняя сверка, ручные исправления.
Дедупликация обычно решает это без магии: каждое событие несет уникальный идентификатор (event_id) и ключ предметной области (например, request_id + статус). Бухгалтерия перед созданием проводки проверяет, не обрабатывала ли уже этот event_id или не проводила ли оплату по этой заявке.
Чтобы это работало предсказуемо, стоит заранее договориться о правилах: кто генерирует event_id и гарантирует его уникальность, какой ключ считать «уникальной оплатой» (заявка, счет, платеж), где хранится журнал обработанных событий и сколько времени, что делать, если событие пришло раньше данных, кто отвечает за разбор инцидентов.
Если событие пришло раньше нужных данных, безопаснее не «додумывать». Либо отложите обработку с повторной попыткой, либо запросите недостающие данные отдельно. Проводку делайте только когда условия выполнены и дубликаты отфильтрованы.
Ретраи, ошибки и наблюдаемость без лишней сложности
Ретраи (повторные попытки) помогают пережить временные сбои: короткий сетевой обрыв, перегрузку базы, краткую недоступность внешнего сервиса. Но они вредят, если ошибка постоянная. Например, пришло событие с некорректными данными, и сервис честно пытается обработать его снова и снова, превращая очередь в склад «мертвых» сообщений.
Правило простое: ретраи нужны для временных проблем, а для постоянных - быстрый выход и понятный «карман» для разборов.
Очередь ошибок и отложенная обработка
Обычно используют два механизма: отложенную повторную обработку (сообщение возвращается в очередь с задержкой, например 1 минута, потом 5, потом 30) и очередь ошибок (dead-letter), куда сообщение уходит после N неудачных попыток, чтобы не блокировать поток.
Это особенно важно там, где одно зависшее событие не должно держать всю ленту, например при синхронизации статусов заявок или заказов.
Что логировать и какие метрики смотреть
Логов должно быть минимум, но по делу: event_id, ключ сущности (order_id, ticket_id, user_id), номер попытки и причина ошибки, результат обработки (успех, пропуск как дубль, отправлено в ошибки).
Из метрик обычно достаточно: лаг (насколько отстает потребитель), доля ретраев, процент ошибок и размер очереди ошибок.
Понять, где проблема (в продюсере или в потребителе), помогает простая проверка: если один и тот же event_id падает одинаково у всех потребителей, вероятнее всего, данные некорректные у источника. Если падает только один сервис или зависит от нагрузки, чаще виноват потребитель (код, ресурсы, внешние зависимости).
Типичные ошибки и ловушки при событийной интеграции
Самые болезненные проблемы обычно не про «какую очередь выбрать», а про ожидания. Люди переносят привычки из синхронных API и удивляются, когда события ведут себя иначе.
Частая ловушка - считать порядок событий надежным. На практике сообщения могут приходить с задержкой, «обгонять» друг друга после ретраев или попадать в разные партиции. Если логика зависит от строгой последовательности, рано или поздно вы получите неверное состояние.
Вторая ошибка - верить, что очередь избавляет от дублей. Даже при хороших настройках повторы возможны из-за таймаутов, повторных отправок, падений потребителя и сетевых сбоев. Правильный подход - закладывать повторную доставку как норму и проектировать обработку так, чтобы она не ломала данные.
Часто систему ломают побочные эффекты до фиксации факта обработки: сначала списали деньги, создали запись или отправили письмо, а потом не успели сохранить «событие обработано». При повторе получится двойное действие.
Еще одна ловушка - игнорировать версионирование. Поля меняются, добавляются, переименовываются, и старый потребитель начинает падать или молча неверно трактует данные. Договоритесь о правилах совместимости и храните версию события явно.
Наконец, многие не продумывают восстановление после инцидента. Минимальный набор: понятный способ переиграть события за период (replay) без удвоения эффектов, журнал обработанных сообщений или ключей идемпотентности, процедура ручной сверки и исправления данных, метрики и алерты на рост дублей и ретраев, ответственность (кто и как принимает решение о повторном проигрывании очереди).
Короткий чеклист перед запуском в прод
Перед релизом событийной интеграции полезно пройтись по базовым пунктам. Они не делают систему «идеальной», но резко снижают риск ночных инцидентов, когда очередь растет, а данные «разъезжаются» между сервисами.
- В каждом сообщении есть уникальный идентификатор события и понятный ключ сущности (например,
order_id,user_id). - Обработчик безопасно переживает повторы: при двойной доставке результат в данных тот же, что и при одной обработке.
- Есть надежное место, где отмечается «это событие уже обработано» (таблица обработанных
event_id, уникальный индекс на целевую запись или аналогичный механизм). - Ретраи настроены осознанно: сколько попыток, с какой паузой, и что происходит дальше (отдельная очередь проблемных сообщений или понятная ручная процедура).
- По логам и метрикам можно быстро ответить «какое событие сломалось и почему», а на крайний случай есть процедура ручной коррекции данных.
Проверка на здравый смысл: возьмите реальный сценарий (например, смена статуса заявки) и прогоните три теста - повторная доставка, задержка события на пару минут и падение обработчика посередине. Если после этого данные сходятся, вы близки к спокойному запуску.
Следующие шаги: как подойти к внедрению и поддержке
Чтобы событийная интеграция между системами не превратилась в бесконечную отладку, начните не с брокера, а с ясной картины: какие решения реально зависят от событий и какова цена ошибки. Практичнее идти от бизнес-сценариев (заказ создан, счет оплачен, заявка отменена), и только потом обсуждать топики, очереди и формат событий.
Дальше помогает рабочий план: собрать карту систем и событий (кто публикует и кто читает), зафиксировать гарантии (что допустимо, а что нет), решить, где хранится состояние обработки, подготовить тесты на нагрузку и сбои, определить поддержку (мониторинг, алерты, правила ручного вмешательства и обновлений).
Отдельно продумайте хранение истории. Если важно отвечать на вопрос «почему статус изменился», одного текущего значения мало. Нужен след: идентификатор события, время, результат обработки, ошибка и количество попыток.
Если инфраструктура для таких интеграций делается в крупных организациях (госсектор, финансы, здравоохранение), вопрос часто упирается в надежные серверы, прозрачную поддержку и понятную ответственность. В Казахстане это, например, закрывают системные интеграторы и производители вроде GSE.kz (gse.kz), у которых помимо интеграционных услуг есть собственные серверы S200 Series и круглосуточная техническая поддержка с сервисной сетью по стране.
FAQ
Почему одно и то же событие может прийти два или три раза?
Потому что большинство брокеров и очередей дают гарантию доставки «хотя бы один раз». Если потребитель обработал сообщение, но не успел отправить `ack` (или `ack` потерялся из‑за сети), брокер считает доставку не подтвержденной и отправляет событие повторно. Это нормальный механизм надежности, а не обязательно ошибка интеграции.
Когда лучше использовать события, а когда — запросы (API)?
Запрос нужен, когда вам важен ответ «прямо сейчас» и без него нельзя продолжать, например проверка существования заказа перед оплатой. Событие подходит, когда система сообщает факт изменения состояния и это должны узнать несколько получателей без жесткой связки по времени. Практичное правило: если вы «спрашиваете» — делайте запрос, если «уведомляете» — публикуйте событие.
Какие поля должны быть в событии, чтобы проще переживать дубликаты?
Минимум — уникальный `event_id`, который задает система‑источник, и ключ предметной сущности вроде `order_id`, `request_id` или `payment_id`. `event_id` помогает отфильтровать повторную доставку одного и того же сообщения, а ключ сущности помогает защититься от логических дублей, когда одинаковое действие может прийти разными событиями. Если `event_id` генерирует потребитель, он не спасает от повторной доставки, пришедшей извне.
Где хранить информацию, что событие уже обработано?
Обычно это таблица или коллекция «обработанных событий» в базе потребителя. В нее сохраняют `event_id`, ключ сущности, время и итог обработки, чтобы при повторе быстро понять, что событие уже было, и безопасно завершить работу. Важно, чтобы запись о факте обработки появлялась надежно, иначе повтор снова запустит бизнес‑действие.
Нужно ли делать обработку события и запись «обработано» одной транзакцией?
Чаще всего — да, в одной транзакции: проверили, что `event_id` еще не встречался, внесли бизнес‑изменение, зафиксировали «обработано». Тогда при падении посередине вы не получите ситуацию, когда действие уже выполнено, а отметки об обработке нет. Если транзакция невозможна, старайтесь хотя бы сделать необратимые шаги (деньги, отгрузка, отправка письма) защищенными отдельным идемпотентным ключом.
Как избежать двойного создания платежа/заявки при внешнем API-вызове из обработчика?
Передавайте идемпотентный ключ во внешний запрос, чтобы повторный вызов не создавал второй объект и не запускал вторую операцию. На практике ключом часто делают `event_id` или комбинацию «тип события + id сущности», если это стабильнее для бизнес‑смысла. Тогда повтор события приведет к повторному запросу, но внешняя система вернет тот же результат вместо создания дубля.
Можно ли рассчитывать на порядок событий в очереди?
Не стоит строить логику на предположении «события всегда по порядку». Под нагрузкой и при параллельной обработке сообщения могут приходить позже, «обгонять» друг друга или повторяться после ретраев. Надежнее приводить объект к целевому состоянию и проверять актуальность по версии/времени/статусу, чем делать цепочку «раз пришло после — значит можно применять».
Как правильно настроить ретраи, чтобы не получить бесконечный цикл ошибок?
Ретраи полезны для временных проблем вроде краткого сбоя сети или перегрузки базы. Если ошибка постоянная (битые данные, несовместимая схема), бесконечные повторы только забивают очередь и мешают нормальным сообщениям. В таких случаях лучше ограничить число попыток и отправлять проблемные события в отдельную очередь ошибок для разбора.
Что делать, если событие пришло раньше, чем нужные данные появились в базе?
Безопаснее не «додумывать» данные и не выполнять необратимое действие. Обычно выбирают отложенную повторную обработку, чтобы дождаться появления нужных данных, либо делают отдельный запрос за недостающей информацией и продолжают только при выполненных условиях. Главное — чтобы повторная попытка оставалась безопасной и не создавала дублей благодаря идемпотентности.
Что логировать и какие метрики смотреть, чтобы быстро находить проблемы в интеграции?
Нужны логи, по которым можно быстро найти проблемный `event_id`, ключ сущности и результат обработки: успех, пропуск как дубль или ошибка. Из метрик чаще всего достаточно видеть отставание потребителя (лаг), долю ретраев, процент ошибок и размер очереди ошибок, чтобы отличать временные сбои от системной проблемы. Это экономит часы расследований, когда «цифры не сходятся» между системами.