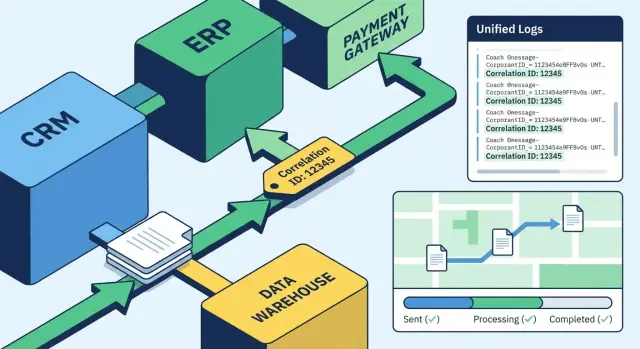
Сквозная трассировка интеграций: Correlation ID и единые логи
Сквозная трассировка интеграций помогает связать Correlation ID, единые логи и карту маршрута документа, чтобы быстрее находить причину инцидента.
Зачем вообще нужна сквозная трассировка
Интеграции ломаются не так, как монолитная программа. Один сбой часто проявляется сразу в нескольких местах: документ не дошел до бухгалтерии, в витрине данных появилась пустая строка, а в поддержке видят только жалобу пользователя. Кажется, что проблема везде, хотя источник обычно один.
Быстро найти причину мешают две вещи. Во-первых, каждая система пишет логи по-своему и хранит их отдельно. Во-вторых, по пути теряются детали: какой документ обрабатывался, на каком шаге он завис, какой сервис изменил данные, сколько времени занял каждый переход.
Сквозная трассировка интеграций нужна, чтобы отвечать на простые вопросы без длинных созвонов и пересылки скриншотов. Например: где сейчас документ (в очереди, в обработке, в ошибке или уже в целевой системе), на каком шаге возникла проблема и кто ее увидел первым, это разовый сбой или массовая история, какие данные поменялись по пути и можно ли доказать, что изменение было легитимным.
Во время простоя бизнес обычно спрашивает: «сколько заявок/платежей/накладных не прошло и когда заработает». ИБ спрашивает другое: «кто отправил запрос, откуда, под какой учетной записью, не было ли подмены данных». Без единого следа по всей цепочке отвечать приходится предположениями.
Пример из жизни: счет уходит из ERP в шину интеграции, затем в систему согласования и в финальную учетную систему. В одной точке пропадает поле с номером договора. В итоге документ отклоняют, а в каждой системе это выглядит как отдельная ошибка. Трассировка делает историю документа цельной и позволяет за минуты увидеть, где именно данные потерялись.
Correlation ID простыми словами
Correlation ID - это единый идентификатор, который присваивают запросу или документу и сохраняют на всем пути через разные системы. Он нужен не «для красоты», а чтобы быстро собрать все логи и события, относящиеся к одному прохождению: от входа в API до последней записи в базе или ответа внешнему сервису.
Correlation ID не равен номеру документа. Номер документа приходит из бизнеса (например, «Счет N 54821»), может повторяться в разных средах, меняться после пересоздания или вообще существовать только в одной системе. Correlation ID технический: появляется сразу на входе и не меняется, даже если документ позже получает другой бизнес-номер.
Он отличается и от request id. Request id часто живет только в рамках одного HTTP-запроса или одного сервиса и меняется при каждом новом вызове. Correlation ID связывает всю цепочку: один входной запрос, несколько внутренних вызовов, сообщения в очереди, обработку в интеграционном слое и обратные ответы.
Где его удобнее всего создавать? На входном шлюзе или в первом сервисе, который принимает запрос извне. Если Correlation ID уже пришел в заголовке, его принимают и проверяют. Если нет - создают новый и дальше протаскивают везде: в заголовках API, в метаданных сообщений очереди, в имени файла или в служебной метке.
Формат Correlation ID должен быть уникальным, коротким и стабильным (чтобы помещался в заголовки и логи), не содержать персональных данных и «смысла» (не кодируйте клиента, сумму и прочее) и при этом быть достаточно читаемым, чтобы оператор мог продиктовать его по телефону. На практике чаще всего используют UUID или короткий безопасный токен фиксированной длины. Важнее всего договориться об одном формате для всех команд и фиксировать его в каждом лог-событии.
Как протащить ID через API, очереди и файлы
Чтобы сквозная трассировка работала, Correlation ID должен ехать вместе с документом всегда, даже если формат обмена меняется.
В API проще всего передавать ID в заголовке (например, X-Correlation-Id). Тогда его легко читать в шлюзе, сервисах и логах, не трогая тело запроса.
В очередях и брокерах сообщений удобнее использовать метаданные (properties/headers). Если такой возможности нет, кладите Correlation ID в тело как отдельное поле. Главное - выбрать одно место и придерживаться его везде.
С файлами сложнее: «заголовков» нет. Обычно помогают три варианта: добавить Correlation ID в имя файла, хранить рядом небольшой файл-метадату или добавить поле в начало содержимого (если формат позволяет). Ключевое требование одно: получатель должен уметь достать ID до начала обработки.
При разветвлении (fan-out) оставляйте один общий Correlation ID как корневой, а для каждой ветки добавляйте вторичный идентификатор (например, Child-Id или Step-Id). При объединении (fan-in) используйте тот же корневой ID и храните список входящих Child-Id, чтобы было видно, что именно сошлось.
Ретраи и дубликаты не должны создавать новый Correlation ID. Оставляйте исходный, а рядом пишите номер попытки (attempt=2) и стабильный ключ идемпотентности. Тогда при разборе видно: это та же операция, просто повторная доставка, а не новая транзакция.
Единый формат логов: что должно быть в каждой записи
Единый формат логов нужен, чтобы по одному запросу быстро собрать историю документа во всех сервисах. Без этого сквозная трассировка превращается в ручной поиск по разным файлам и разным именам полей.
Минимальный набор полей лучше сделать обязательным:
timestamp(с часовым поясом)system(имя сервиса/модуля) иversionenvironment(prod, stage и т.п.)correlation_id(и при необходимостиrequest_id)status(успех, ошибка, отмена, ретрай)
Почти всегда полезно добавлять duration_ms, operation (что делали), endpoint или queue/topic, а также doc_id (внутренний идентификатор документа). Тогда проще сравнивать одинаковые операции между системами и видеть, где растет время.
По уровням логов правило простое: INFO фиксирует факт и результат (начали, закончили, сколько заняло, какие ключевые ID). WARN пишется, когда запрос формально прошел, но есть риск: повторная попытка, деградация, невалидные данные, таймаут на внешней системе. ERROR - когда операция не выполнена и нужен разбор.
Ошибки логируйте единообразно, чтобы их можно было группировать: один и тот же error_code, стабильный тип исключения, короткое сообщение без «уникальных деталей» и отдельное поле error_fingerprint (например, код + место). Стек и сырые ответы лучше класть в отдельные поля и включать по уровню, чтобы не утонуть в шуме.
И последнее: не записывайте лишнее. В логах не должно быть персональных данных, паролей, токенов, ключей API и содержимого документов целиком. Оставляйте только маскированные значения и идентификаторы, по которым можно поднять исходные данные в защищенной системе.
Централизованный сбор и поиск логов
Когда логи лежат в разных местах, расследование превращается в квест: один сервис пишет в файл на сервере, другой - в консоль, третий - в логи шины, а ошибки базы данных живут отдельно. Централизованный сбор решает это просто: все события попадают в одно хранилище, где их можно быстро найти и сопоставить.
Собирать стоит не только логи приложений. «Пропажа» документа часто случается на стыке, поэтому полезны записи от API-шлюза, интеграционной шины, брокера сообщений, фоновых задач, ОС и, где уместно, диагностические события БД. Тогда Correlation ID виден по всей цепочке, а не только в одном сервисе.
С самого начала договоритесь о правилах именования. Если один и тот же сервис сегодня называется "billing", завтра "billing-service", а в тесте еще иначе, фильтры перестают работать. То же самое с полями: лучше один раз закрепить, как пишутся system/service, environment, correlation_id, request_id, error_code, duration_ms.
Для поиска достаточно типового набора фильтров: Correlation ID как основная точка входа, интервал времени с запасом до и после сбоя, система/сервис, код ошибки или класс исключения, среда (dev/test/prod). Рабочий сценарий выглядит так: в проде «завис» счет, оператор берет Correlation ID из ответа API или из сообщения очереди и за полминуты видит цепочку событий: прием запроса, постановка в очередь, ошибка в обработчике, ретраи, финальный статус.
Это работает только если заранее настроены срок хранения логов, доступы (кто что видит) и четкое разделение по средам, чтобы тестовые события не мешали боевым.
Карта маршрута документа между системами
Карта маршрута - это список шагов, через которые проходит один документ (заказ, заявка, счет), вместе со статусами переходов. По сути, это трек-номер для интеграций: где документ был, что с ним сделали и на каком шаге он остановился.
Хорошая карта строится вокруг нескольких событий, которые повторяются почти везде. Обычно достаточно фиксировать: документ принят, обработан, отправлен дальше, получено подтверждение. Эти события должны появляться при каждом переходе между системами, даже если сами системы разные (API, очередь, файл).
Какие статусы реально помогают
Статусы должны разделять ответственность. Простой подход: отделить интеграционные проблемы (доставили/не доставили, таймаут, ошибка передачи) от бизнес-ошибок (валидация, права, не найден контрагент), добавить «ожидание» (в очереди, ждет подтверждения) и четко обозначить «успех» (подтверждено, закрыто).
Не пытайтесь сделать десятки статусов. Лучше 8-12 понятных, чем 40 расплывчатых.
Как связать карту с логами и метриками
Карта маршрута должна опираться на те же идентификаторы, что и трассировка: Correlation ID и, при необходимости, ID документа. Тогда по одному Correlation ID можно открыть централизованные логи и увидеть не только ошибки, но и «нормальные» точки прохождения.
Практичный подход: на каждом шаге писать короткое событие в лог (кто, куда, что сделал, результат) и одновременно обновлять состояние маршрута. А метрики (например, время между «принят» и «подтвержден») покажут, где чаще всего возникают задержки, даже когда явных ошибок нет.
Пошаговый план внедрения без больших переделок
Сквозная трассировка почти всегда буксует не из-за технологий, а из-за масштаба: пытаются охватить все маршруты сразу. Рабочий подход - начать с одного критичного потока и сделать его видимым от начала до конца.
План, который обычно взлетает:
- Выберите один самый болезненный маршрут и коротко опишите шаги: какие системы участвуют, где API, где очередь, где файл.
- Договоритесь о правилах: формат Correlation ID, где он хранится (заголовок, поле сообщения, имя файла), какие поля обязательны в логах (время, система, операция, результат, длительность, Correlation ID).
- Добавьте генерацию и проброс ID на входе и выходе каждого шага. Если шаг принимает запрос без ID, он должен создать новый и передать дальше.
- Настройте централизованный сбор логов и минимальный поиск: «по Correlation ID увидеть все события по документу». Затем добавьте пару сохраненных запросов или простой дашборд.
- Оформите карту маршрута: ожидаемая цепочка шагов и базовые статусы. Поверх этого настройте алерты на зависания (нет следующего шага N минут) и повторяющиеся ошибки.
После первых результатов проведите короткие учения по инциденту. Дайте команде тестовый Correlation ID и попросите за 10 минут ответить: где документ сейчас, на каком шаге сломалось, что было последним успешным действием. По итогам обновите регламенты: кто смотрит логи первым, что прикладывать в тикет, когда эскалировать. Такой подход часто используют и интеграторы вроде GSE.kz на проектах, где важно быстро находить узкое место между системами.
Пример: как проходит документ через 4 системы
Представьте маршрут: бухгалтерия создает счет, он проходит проверку, отправляется контрагенту и попадает в архив. Участвуют 4 системы: ERP (источник), сервис проверки (валидация), интеграционный слой (шина/API), ECM (хранилище документов).
Correlation ID лучше создавать как можно раньше, в момент появления документа. Часто его генерирует система-источник (ERP) при нажатии «Отправить» и дальше передает во все вызовы, сообщения и файлы. Если источник не может, Correlation ID может выдать интеграционный слой, но тогда важно вернуть этот ID назад в источник и записать его в карточку документа.
Дальше документ идет по шагам, и в логах фиксируются одинаковые опорные поля: Correlation ID, Document ID (внутренний номер), system, step, status, timestamp, error (если есть). В карте маршрута это выглядит как цепочка статусов:
- ERP: CREATED -> SENT
- Validation: RECEIVED -> VALIDATED
- Integration: ENQUEUED -> DELIVERED
- ECM: STORED -> INDEXED
Если возникает ретрай, важно отличить повторную попытку от нового документа. Практичный вариант: Correlation ID остается тем же, а для попытки добавляется поле attempt (1, 2, 3) или retry=true. Тогда при поиске по Correlation ID видно: это один и тот же документ, просто была повторная доставка.
Как разбирать инцидент быстрее: короткий сценарий расследования
Скорость расследования почти всегда упирается не в «умение искать», а в отсутствие общей нити между системами. Сквозная трассировка дает эту нить: один Correlation ID и понятный маршрут документа.
Сначала фиксируйте контекст, пока он не потерялся: время (до минут), симптом (что именно не так), кто заметил (пользователь, оператор, мониторинг) и какой маршрут затронут (например: сайт -> CRM -> ERP -> склад). Это сразу сужает область поиска.
Дальше цель простая: быстро найти Correlation ID по внешнему признаку. Внешним признаком может быть номер документа, логин пользователя, сумма и валюта, тип операции, внешний идентификатор заявки.
Короткий рабочий сценарий:
- В логах первой «видимой» системы найдите запись по внешнему признаку в нужный интервал времени и возьмите Correlation ID.
- По этому ID соберите события по всем системам и отсортируйте по времени.
- Сверьте с картой маршрута: где должно быть подтверждение приема (received), обработки (processed) и передачи (sent).
- Если подтверждение пропало на шаге N, проверьте соседние события: был ли ретрай, был ли ответ внешней системы, не было ли таймаута.
- Формулируйте вывод фактами: конкретная строка лога, конкретный шаг, конкретный код ошибки.
Чтобы отделить «ошибка данных» от «ошибка инфраструктуры», смотрите на повторяемость и форму сбоя. Ошибки данных обычно стабильны для одного документа (неверный формат, отсутствует поле, бизнес-правило). Инфраструктурные чаще идут пачкой (таймауты, недоступность сервиса, очередь не потребляется).
Для постмортема сохраните артефакты, пока они доступны: Correlation ID, временной диапазон, список затронутых систем и шаг, исходный payload (с маскированием персональных данных), ключевые строки логов с кодами ошибок и счетчики повторных попыток.
Частые ошибки и ловушки
Самая частая ошибка - Correlation ID появляется слишком поздно. Его генерируют уже внутри одного сервиса, а до этого запрос успевает пройти через API-шлюз, балансировщик или первый микросервис без единого идентификатора, и начало цепочки теряется.
Вторая боль - ID пропадает в асинхронных местах. Очереди, отложенные задачи, планировщики и batch-обработка часто живут своей жизнью: сообщение кладут в очередь с одним набором заголовков, а воркер читает его и пишет логи уже без Correlation ID, потому что никто не перенес его в контекст выполнения.
Отдельная ловушка - время. Когда разные системы пишут его в разных форматах или часовых поясах, события перестают нормально сортироваться. Особенно заметно это при коротких задержках между сервисами.
Часто логи либо слишком шумные, либо слишком бедные. В первом случае тонете в «успешно вызвали метод», во втором - в записях нет ключевых полей, которые склеивают историю: Correlation ID, имя системы, этап обработки, статус, длительность.
Самая опасная ошибка - утечки. В логи случайно попадают персональные данные, токены, пароли, ключи API или содержимое документов целиком. Потом эти данные оказываются в централизованном хранилище логов, к которому обычно имеет доступ больше людей, чем к боевой базе.
Еще одна проблема - разные определения «успеха». Для одной системы 200 OK уже означает, что все хорошо. Для другой успех - это запись в БД. Для третьей - подтверждение от внешнего контрагента. Без общего определения вы не сможете уверенно отличать «в пути» от «зависло».
Быстрая самопроверка:
- Correlation ID создается на самом первом входе и не меняется по дороге.
- ID переносится через очереди и планировщики так же строго, как через API.
- Время пишется единообразно (формат и часовой пояс).
- В каждой записи логов есть минимум: ID, система, шаг, статус, длительность.
- Секреты и персональные данные маскируются или не пишутся вовсе.
Быстрый чеклист перед запуском в прод
Перед выкладкой проверьте, что трассировка работает в реальном инциденте, а не только «на стенде». Самый простой тест: возьмите одну транзакцию (документ, заявку, платеж) и попробуйте найти ее путь за 2 минуты по одному идентификатору.
Минимальные проверки, которые чаще всего спасают ночью в дежурстве:
- Один и тот же Correlation ID присутствует во всех входящих и исходящих вызовах: HTTP-заголовки, сообщения в очереди, имя файла или метаданные при обмене файлами.
- Логи во всех ключевых системах пишутся в одном стиле: одинаковые поля (например,
correlation_id,system,operation,status,duration_ms) и единое время (ISO-формат, один часовой пояс). - Поиск по Correlation ID находит события «от начала до конца» минимум в основных точках: API-шлюз, шина/очередь, сервис обработки, база/хранилище.
- Карта маршрута (пусть даже таблица в мониторинге) показывает текущий шаг и понятную причину остановки: ошибка валидации, таймаут, отказ внешней системы, очередь переполнена.
- Поведение при сбоях определено и проверено: ретраи с ограничением, дедупликация (чтобы не было двойных документов), понятная обработка таймаутов.
Отдельно проверьте безопасность. Убедитесь, что права доступа к логам настроены по ролям, а чувствительные поля маскируются до записи (ИИН, телефоны, номера карт, медицинские данные). Если нужно сопоставление, логируйте безопасный отпечаток (хеш) или последние 4 символа, а не полный идентификатор.
Практичный прогон: отправьте тестовый документ, искусственно вызовите таймаут на одном шаге и проверьте, что по Correlation ID видно, где он остановился и что система сделала дальше (повтор, ожидание, перенос в DLQ, отказ).
Следующие шаги: как закрепить результат и масштабировать
Эффект появляется, когда правила становятся привычкой команды. После первого успеха закрепите стандарты и сделайте их частью разработки и поддержки.
Начните с пилота: выберите 1-2 самых проблемных маршрута документа (например, «CRM -> шина -> ERP») и назначьте владельцев на каждый шаг. Владелец отвечает за то, чтобы Correlation ID не терялся, а логи оставались читаемыми.
Дальше обычно хватает базового набора действий: утвердить короткий стандарт логов (обязательные поля и правила ошибок), проверить проброс Correlation ID через API, очереди и фоновые задачи, заранее настроить хранение и поиск (срок хранения, объем, права доступа, маскирование), договориться о дежурстве и эскалации, вести постмортемы и после каждого заметного сбоя обновлять код, логи и регламенты.
Чтобы масштабирование не превратилось в бесконечный проект, договоритесь о простых метриках: сколько инцидентов разобрали «по одному ID», среднее время до первопричины, сколько раз ID терялся на границе систем.
Если под мониторинг и расследования нужна опорная инфраструктура (серверы под хранение логов, интеграция, поддержка), имеет смысл привлекать системного интегратора с опытом построения таких контуров. Например, в GSE.kz, помимо интеграционных работ, есть практики по инфраструктуре для дата-центров и круглосуточной поддержке, что полезно, когда трассировка должна работать стабильно в проде.
FAQ
Что дает сквозная трассировка интеграций на практике?
Сквозная трассировка нужна, чтобы быстро собрать историю одного документа или запроса через все системы и понять, где именно он «застрял». Без нее приходится вручную сопоставлять разрозненные логи и версии событий, и расследование занимает часы вместо минут.
Что такое Correlation ID простыми словами?
Correlation ID — это технический идентификатор, который сопровождает прохождение одного запроса или документа через разные сервисы, очереди и обработчики. Он создается на входе и дальше не меняется, чтобы по нему можно было собрать все связанные события в одну цепочку.
Почему нельзя обойтись только номером документа вместо Correlation ID?
Номер документа — бизнесовый и может меняться, повторяться в разных средах или вообще отсутствовать в части систем. Correlation ID нужен именно для технической диагностики: он появляется сразу, стабилен и одинаков в каждой точке маршрута, даже если бизнес-атрибуты менялись по пути.
Где правильнее всего генерировать Correlation ID?
Лучше всего создавать Correlation ID на самом первом входе: в API-шлюзе или в первом сервисе, который принимает внешний запрос. Если ID пришел снаружи, его принимают и валидируют; если нет — генерируют новый и обязательно возвращают/передают дальше, чтобы не потерять начало цепочки.
Как передавать Correlation ID через API, очередь и файлы?
В HTTP/API удобнее всего передавать ID в заголовке, чтобы не менять тело запросов. В очередях — в headers/properties сообщения, а если их нет, тогда отдельным полем в теле. Для файлов обычно выбирают один понятный способ, чтобы получатель мог извлечь ID до обработки, например из имени файла или из метаданных рядом.
Нужно ли менять Correlation ID при ретраях и дублях?
Не создавайте новый Correlation ID на ретраях и при повторной доставке, иначе одна операция распадется на несколько историй. Сохраняйте исходный ID, а отдельно фиксируйте номер попытки и признак повтора, чтобы было видно, что это та же операция, а не новый документ.
Какие поля должны быть в каждом логе, чтобы трассировка реально работала?
Достаточно договориться о минимуме обязательных полей, которые есть в каждой записи, чтобы события можно было склеить и отсортировать. Обычно это время с часовым поясом, имя системы и среда, Correlation ID, операция/шаг и итоговый статус, а также длительность для поиска узких мест.
Зачем собирать логи централизованно, если они уже есть в каждой системе?
Централизация нужна, чтобы искать по одному Correlation ID в одном месте, а не прыгать между серверами, консолями и разными форматами. Важно заранее разделить среды, настроить сроки хранения и права доступа, иначе боевые расследования будут мешаться с тестовыми, а доступ к логам станет риском безопасности.
Что такое «карта маршрута» документа и чем она отличается от логов?
Карта маршрута — это понятный список шагов и статусов, через которые должен пройти документ, как «трек-номер» для интеграций. Она помогает сразу увидеть текущий шаг и тип проблемы: доставка/инфраструктура или бизнес-ошибка, а по Correlation ID можно открыть детальные логи для нужного шага.
С чего начать внедрение сквозной трассировки без больших переделок?
Начните с одного критичного маршрута и сделайте его видимым от входа до выхода: единый формат Correlation ID, обязательные поля логов и централизованный поиск по одному ID. Дальше добавьте карту маршрута и простые проверки на «зависания», а затем проведите короткие учения по инциденту; такой подход часто применяют интеграторы вроде GSE.kz, когда нужно быстро локализовать проблему между системами.