Синтетический мониторинг инфраструктуры: проверки без шума
Синтетический мониторинг инфраструктуры помогает планово проверять DNS, VPN, RDP и HTTP, отделять сбои сети от сервиса и снижать шум.
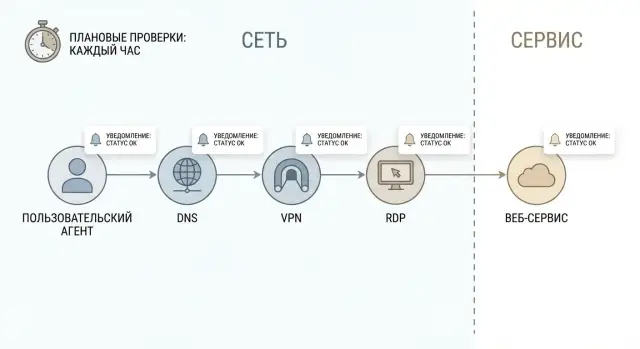
Проблема: есть алерты, но непонятно, что именно сломалось
Почти в каждой компании бывает одно и то же: уведомления сыпятся весь день, а реальный сбой замечают только после жалоб пользователей. Причина простая: многие алерты смотрят на «внутренние» признаки (CPU, ошибки в логах, падение процесса), а пользователю нужен понятный ответ - сервис открывается и в него можно войти или нет.
Синтетический мониторинг инфраструктуры закрывает эту дыру. Он по расписанию повторяет короткие действия, похожие на реальные, и фиксирует результат. Например: удалось ли разрешить DNS-имя, поднялся ли VPN-туннель, открывается ли RDP, возвращает ли сайт HTTP 200 и за какое время. Это не замена метрик и логов, а независимая проверка «снаружи», даже если приложение само считает, что «все работает».
«Шум» в алертах - это сообщения, которые не требуют действий или не помогают разобраться в причине. Опасность очевидна: команда привыкает игнорировать уведомления, а важные события тонут среди ложных. В итоге теряется время, растет риск пропустить реальную аварию.
Хорошо настроенная синтетика помогает быстро ответить на главные вопросы и сузить поиск:
- Это сеть или сам сервис?
- Проблема в DNS, маршрутизации, доступе к порту или в приложении?
- Сбой локальный (одна площадка или провайдер) или общий?
- Когда именно началось и как менялась задержка?
Простой пример: пользователи не открывают корпоративный веб-сервис. Если DNS не резолвится - это одна ветка. Если DNS в порядке, но HTTPS не устанавливается - другая. Если HTTPS есть, но возвращается 500 - уже похоже на проблему приложения или базы. Такой разбор экономит часы переписок между сетевиками и владельцами сервиса.
Что проверять по расписанию: DNS, VPN, RDP, HTTP простыми тестами
Смысл плановых проверок в том, чтобы имитировать путь пользователя: от имени до сервиса и обратно. Тогда синтетический мониторинг инфраструктуры показывает не просто «порт открыт», а где именно начинается сбой - в сети, в доступе или в самом приложении.
DNS лучше проверять не одним запросом, а короткой цепочкой: резолвинг нужных имен (A/AAAA, CNAME), время ответа и тип ошибки. NXDOMAIN обычно означает опечатку или неверную запись. SERVFAIL чаще указывает на проблему DNS-сервера или его рекурсивной части. Имеет смысл тестировать и внутренние зоны (например, intranet.local), и внешние домены, если сервис доступен извне.
VPN проверяйте как пользователь: доступность шлюза, успешность аутентификации и время установки туннеля. Если «шлюз пингуется», но туннель поднимается долго или не поднимается вовсе, это уже не «просто сеть». Частые причины - сертификат, учетная запись, перегрузка концентратора, политики доступа.
Для RDP мало проверить порт 3389. Важно дойти до реального экрана входа и измерить время до него. Бывает, что порт отвечает, но служба зависла, закончились лицензии, контроллер домена недоступен или профиль грузится бесконечно - пользователь все равно не сможет войти.
HTTP/HTTPS тест делайте «как браузер»: код ответа, редиректы, время до первого байта, валидность TLS и срок сертификата. Разница между 200, 302, 401 и 503 уже подсказывает, что сломалось.
Практичный набор базовых тестов (в каждом фиксируйте статус и время):
- DNS: резолвинг + ошибка (NXDOMAIN/SERVFAIL) + задержка
- VPN: handshake/логин + время поднятия туннеля
- RDP: TCP + появление экрана входа
- HTTP/HTTPS: код + TLS + цепочка редиректов + TTFB
- Сквозной шаг: пройти все по очереди от имени до конкретного URL
Сквозной тест особенно полезен: если он падает, а точечные проверки «зеленые», проблема часто в связке - маршрутизация, прокси, ACL, балансировщик или внешняя зависимость приложения.
Откуда и как часто запускать проверки, чтобы картинка была честной
Чтобы синтетический мониторинг инфраструктуры показывал реальную ситуацию, важно не только что проверять, но и откуда. Один и тот же сервис может быть доступен из дата-центра, но недоступен из офиса из-за провайдера, маршрутов или корпоративных правил доступа.
Начните с 2-4 точек запуска, которые отражают реальные пути трафика: офисная сеть (как у сотрудников), дата-центр (как у внутренних систем), внешняя точка ближе к клиентам (как у пользователей из интернета), плюс крупный филиал или проблемный регион.
Частота зависит от цены простоя и терпимости к «миганию». Для критичных вещей (вход в VPN, основной веб-сервис) обычно хватает 1-5 минут. Для второстепенных проверок (резервные каналы, неосновные зоны) часто достаточно 15-60 минут. Простое правило: чем дороже простой, тем чаще проверка.
Окна техработ закрепляйте заранее. В это время алерты либо отключаются, либо переводятся в режим «информирование без эскалации». Иначе команда получит серию ложных инцидентов и начнет игнорировать уведомления.
Таймауты задавайте жестко. Если HTTP проверка «висит» 2 минуты, теряется смысл частых запусков и накапливаются очереди. Типичные ориентиры: DNS 2-3 секунды, VPN/RDP 10-20 секунд, HTTP 5-15 секунд. Затем добавьте 1-2 повтора с короткой паузой, чтобы единичный сетевой сбой не превращался в тревогу.
Пошагово: как собрать плановые проверки из простых шагов
Сначала опишите реальный пользовательский путь, а не «проверить порт». Например: сотрудник подключился к VPN, открыл RDP к рабочему серверу и зашел во внутренний портал. Такой сценарий сразу показывает, где может быть «узкое место».
Дальше разложите путь на этапы, которые можно проверять отдельно. Удобная логика: DNS - сеть - TLS - HTTP - авторизация. Важно, чтобы каждый этап давал понятный вывод: проблема в доступности, в маршрутизации, в сертификате или уже в приложении.
Сборка проверок по шагам
Каркас, с которого обычно начинают:
- Зафиксируйте входные данные: имя хоста, IP (если фиксированный), порт, URL, тестовый пользователь.
- Сделайте отдельные проверки: DNS-резолв, TCP-доступность (SYN), TLS-рукопожатие, HTTP-ответ, логин или проверка роли.
- Для каждого шага записывайте результат и время (успех, таймаут, отказ, неверный код).
- Добавляйте минимум контекста: какой DNS-сервер, какой IP вернулся, какой код HTTP, какой сертификат.
- Сводите шаги в один сценарий, но сохраняйте детализацию по этапам.
Время на каждом шаге и базовая линия
Измеряйте время отдельно для DNS, подключения и ответа сервиса. Тогда «медленно» тоже станет сигналом, а не загадкой.
После настройки прогоните проверки и в рабочее время, и ночью. Если ночью все стабильно, а днем растет время DNS или TCP, это часто сеть или перегрузка пограничных устройств. Если DNS и TCP быстрые, TLS проходит, но HTTP дает 500 или авторизация падает, проблема скорее в сервисе.
Пример: портал не открывается. Тест показывает, что DNS иногда возвращает разные IP и время резолва скачет, а HTTP на «хорошем» IP отвечает быстро. Значит, начинать стоит с DNS и маршрутизации, а не с команды приложения.
Как отделить сетевую проблему от проблемы сервиса
Главный принцип синтетического мониторинга инфраструктуры: проверяйте цепочку по шагам и фиксируйте, на каком звене все ломается. Тогда вместо спора «это сеть» или «это приложение» появляется факт: какой этап не прошел.
Держитесь простого порядка: сначала имя, потом путь, потом сервис. Если не резолвится имя, нет смысла «пинать» HTTP или RDP. Если имя резолвится, но до адреса нет связности, проблема чаще в сети или маршрутизации. И только когда путь жив, имеет смысл разбирать сам сервис.
Диагностическая цепочка, которая почти всегда работает:
- DNS: доменное имя дает ожидаемый IP и не «прыгает» без причины
- Сеть: есть связность до IP или шлюза (задержка и потери в норме)
- Порт: нужный порт доступен (443 для HTTPS, 3389 для RDP и т.д.)
- Сценарий: сервис делает то, что должен (логин, ответ API, загрузка страницы)
Чтобы быстрее находить точку отказа, сравнивайте ответы разных DNS: внутренний (как видят сотрудники и серверы) и внешний (как видит интернет). Если внешний резолвит, а внутренний нет - это почти всегда зона ответственности локальной инфраструктуры. Если наоборот - возможна проблема у внешнего провайдера DNS или с публикацией записи.
Еще один надежный прием - параллельные проверки одного и того же HTTP с разных точек. Если из офиса не открывается, а из дата-центра открывается, подозревайте корпоративный VPN, межсетевой экран или маршруты. Если не открывается нигде, вероятнее проблема в самом веб-сервисе или зависимости (база, балансировщик, сертификат).
Не путайте «порт доступен» и «сервис работает». RDP может слушать 3389, но вход не проходит из-за политики, перегрузки, зависшего профиля или недоступного контроллера домена. Поэтому после контроля порта добавляйте проверку сценария: установить сессию, дойти до экрана входа, выполнить тестовую авторизацию (или хотя бы получить ожидаемую реакцию).
Чтобы передавать инциденты без лишних уточнений, в каждом алерте фиксируйте три вещи: на каком шаге цепочки произошел сбой (DNS, сеть, порт, сценарий), откуда запускалась проверка (точка, подсеть), и что именно увидели (код HTTP, таймаут, неверный IP). Так уведомление сразу попадает в нужную команду.
Пороги и правила, чтобы уведомления были без шума
Шум в алертах обычно появляется из-за того, что все события считаются одинаково важными. Для синтетики полезно заранее разделить два типа сигналов: время ответа (latency) и ошибки (fail). Они ведут себя по-разному и требуют разных порогов.
HTTP может отвечать 200, но «тянуться» 8-10 секунд. Это боль для пользователей, но не всегда авария. А вот 3 подряд таймаута или серия 5xx чаще означает реальную недоступность.
Рабочая схема - два уровня: warning для деградации и critical для недоступности.
Минимальный набор правил, который убирает большую часть шума
- Разделяйте пороги для latency и для ошибок.
- Делайте разные условия для warning и critical (warning - медленно, critical - не работает).
- Включайте подтверждение: алерт после 2-3 неудач подряд, а «выздоровление» - после 2 удачных проверок.
- Гасите повторы: один инцидент на проблему, а не десятки одинаковых сообщений.
- Учитывайте плановые работы: на время окна отключайте критичные уведомления или переводите их в «информирование».
Как это выглядит на практике
Если проверка VPN дала один таймаут, а следующая прошла, это повод записать событие в историю, но не повод будить людей ночью. Если 3 проверки подряд не могут установить туннель, а параллельно DNS и HTTP из другой точки тоже ухудшились, это уже похоже на сетевую проблему. Если сеть «жива», а падает только RDP к одному хосту, вероятнее проблема сервиса или конкретной машины.
Цель правил не в том, чтобы «меньше мониторить», а в том, чтобы уведомления совпадали с реальными инцидентами.
Уведомления и эскалация: как не потерять важное и не перегрузить людей
Даже лучшая синтетика бесполезна, если алерты приходят не тем людям или выглядят как загадка. Один сигнал должен подсказывать: кто берет в работу и с чего начать.
Разделите получателей по типу сбоя:
- Сеть (DNS, VPN, RDP, потери, таймауты) - дежурный по сети или NOC
- Безопасность (отказ по сертификату, блокировки, подозрительные ответы) - SOC или ответственный за ИБ
- Приложение/сервис (HTTP 5xx, логин не проходит, ошибка в API) - дежурный по приложению или владелец сервиса
- Платформа (балансировщик, прокси, SSO) - команда платформы
- Провайдер/канал (подтверждено с нескольких точек) - ответственный за поставщика услуги
Канал уведомления тоже должен соответствовать риску. Сообщения в чат подходят для «падает одна точка запуска» или «нестабильно, но сервис жив». Звонок нужен, когда есть явный простой или риск: несколько точек подтверждают отказ, затронут критичный сервис, SLA под угрозой.
Чтобы не начинать переписку «а где сломалось?», добавьте в каждое уведомление минимум полей:
- точка запуска и сеть (офис, дата-центр, внешний узел)
- шаг сценария (DNS, TCP, TLS, HTTP, логин) и на чем остановилось
- код или текст ошибки (NXDOMAIN, timeout, 401, 502) и измеренное время
- окно наблюдения (сколько проверок подряд) и время первого сбоя
- текущий статус эскалации (L1, L2) и контакт ответственного
Эскалация по времени должна быть прописана заранее. Например: 0-5 минут подтверждение дежурным, 5-15 минут подключение второй линии, 30 минут уведомление владельца сервиса. Если проблема не подтверждается, фиксируйте как флап и пересматривайте пороги и точки запуска, вместо того чтобы «глушить» проверку навсегда.
Пример сценария: «не открывается корпоративный веб-сервис»
Утро, пользователи пишут: «портал не открывается через VPN». Если реагировать только на один алерт «сайт недоступен», легко потратить час на спор, это сеть или сам сервис.
Плановые проверки идут по цепочке: DNS, затем VPN, затем доступ к узлу по нужному порту, и только потом HTTP. В нашем примере картина такая: имя портала резолвится, VPN-туннель поднимается, базовая сетевая доступность есть, но HTTP возвращает 502.
502 обычно означает, что до веб-точки вы дошли, но «внутри» что-то не так: балансировщик, upstream, пул бэкендов, лимиты, промежуточный прокси. Важный вывод: сеть жива, копать нужно в сервисе или на балансировщике. Так синтетический мониторинг инфраструктуры и снижает шум: вы получаете не «все красное», а понятный слой, который упал.
Контрпример: те же проверки запускаются из головного офиса и из филиала. В офисе DNS отвечает, а из филиала DNS не отвечает или резолвит неправильный адрес. HTTP тест даже не стартует, потому что нет IP. Это уже больше похоже на локальную проблему: DNS-сервер в филиале, правила в межсетевом экране, split-DNS, кеш, политика VPN для конкретной подсети.
Чтобы быстро передать задачу нужной команде, удобно оформлять итог короткой сводкой: где и у кого не открывается, что проверили (DNS -> VPN -> порт/маршрут -> HTTP), где упало (точный шаг и код), какие ключевые факты «зеленые», и почему это похоже на сеть или на сервис.
Частые ошибки при синтетическом мониторинге
Самая частая ошибка - ограничиться пингом и успокоиться. Пинг показывает, что узел где-то отвечает, но почти ничего не говорит о DNS, авторизации, сертификатах, доступности веб-страницы или работе VPN. В итоге «зелено», а пользователи все равно не могут зайти.
Вторая типовая проблема - запускать проверки только из одной точки, например из дата-центра. Тогда вы не увидите, что у филиала в другом городе проблемы с провайдером, маршрутом или локальным DNS. Минимум - 2-3 точки запуска: центральная сеть, внешний интернет и пара ключевых площадок.
Ложные падения часто появляются из-за слишком жестких таймаутов. Если HTTP тесту дали 1 секунду, а «норма» для сервиса 2-3 секунды в пиковые часы, вы получите поток уведомлений без реальной аварии. Таймауты подбирайте по измерениям и пересматривайте по фактам.
Еще одна ошибка - смешивать сетевые и прикладные алерты в один неразличимый поток. Когда в одном уведомлении лежат «DNS не резолвится», «VPN не поднялся» и «HTTP 500», дежурный тратит время на гадание. Нужна простая классификация: где сломалось - резолвинг, канал, доступ к порту, логин, или уже сервис.
И наконец, многие не хранят историю замеров. Без нее нет базовой линии «как обычно», и деградация, которая копилась неделями, проходит незаметно.
Короткая проверка, чтобы избежать большинства ошибок:
- Держите отдельные тесты для DNS, TCP-порта, логина (VPN/RDP) и HTTP.
- Запускайте проверки минимум из двух разных сетей.
- Настройте таймауты по реальным измерениям и пересматривайте их.
- Разделяйте события по типу: сеть vs сервис.
- Сохраняйте историю и используйте ее как «норму» для порогов.
Быстрый чеклист перед запуском в прод
Перед тем как включать синтетический мониторинг инфраструктуры для всех и будить дежурных, проверьте базовые вещи. Это занимает час-два, но потом экономит дни разборов.
Сначала зафиксируйте «критичные пути пользователя». Не «VPN работает», а конкретно: «сотрудник подключается к VPN, открывает RDP на терминальный сервер, заходит в веб-сервис по HTTPS». У каждого пути должен быть владелец сервиса и владелец сети, чтобы алерт не висел в воздухе.
Дальше разложите каждый путь на шаги и ожидаемые результаты: DNS возвращает нужную запись за X мс, VPN поднимается за Y секунд, RDP доводит до экрана входа, HTTP отдает 200 и страницу логина, редирект ведет туда, куда ожидаете. Важно заранее задать таймауты и границы времени ответа, иначе проверки будут то «нервными», то «молчаливыми».
Чеклист перед продом:
- Список критичных путей согласован, назначены владельцы (сервис, сеть, безопасность).
- Для каждого шага описаны ожидаемые результаты: коды, таймауты, допустимое время.
- Проверки запускаются минимум из двух точек (например, из офиса и из внешней сети).
- Есть подтверждение алерта: срабатывание только после N неудач подряд и подавление повторов.
- Уведомление читаемое: какой шаг упал, из какой точки, какая ошибка, сколько заняло времени.
И финальная проверка: сделайте один тестовый инцидент сами. Например, временно поменяйте тестовую запись DNS или закройте доступ к тестовому порту и посмотрите, как быстро и насколько ясно придет алерт. Если сообщение не помогает принять первое решение, его нужно дописать до запуска в прод.
Следующие шаги: небольшой пилот и аккуратное расширение
Начните с малого. Выберите 3-5 сервисов, без которых бизнес реально останавливается: корпоративный портал, VPN для удаленных, RDP к ключевым серверам, DNS резолвинг, один внешний HTTP endpoint. Возьмите один типовой сценарий пользователя (например, «сотрудник из дома подключается по VPN и открывает веб-сервис») и проверяйте именно его.
Заранее согласуйте, какие показатели пойдут в SLA и отчеты. Обычно это не «все зеленое», а конкретные метрики: процент успешных проверок, 95-й перцентиль времени ответа, среднее время восстановления. Отдельно решите, как разбирать спорные случаи, когда сеть жива, а сервис стабильно медленный.
Чтобы пилот не превратился в набор разрозненных логов, сразу настройте хранение результатов. Нужна история, иначе вы увидите только текущий сбой и не заметите, что время ответа растет уже две недели. Минимум, который стоит сохранять: статус шага, длительность, точка запуска, причина ошибки.
Дальше расширяйтесь по плану, а не по эмоциям после каждого инцидента: добавьте 1-2 точки запуска в филиалах и у внешнего провайдера, расширьте сценарии (логин, загрузка ключевой страницы, запрос к API), введите проверки после релизов и изменений в сети, пересматривайте пороги раз в месяц по фактическим данным.
Если для мониторинга нужна надежная база (серверы под систему наблюдения, рабочие места для диспетчеров, сопровождение), GSE.kz (gse.kz) как производитель и системный интегратор может помочь с инфраструктурой, интеграцией и круглосуточной поддержкой, чтобы пилот уверенно перешел в постоянный процесс.
FAQ
Что такое синтетический мониторинг и зачем он нужен, если уже есть метрики и логи?
Синтетический мониторинг — это плановые проверки, которые повторяют короткие действия пользователя и фиксируют результат: получилось или нет, и за сколько времени. Он дополняет метрики и логи, потому что смотрит на сервис «снаружи» и быстрее показывает реальную недоступность для пользователей.
С чего начать: какие проверки поставить в первую очередь?
Начните с цепочки, которую проходит пользователь: DNS-резолвинг, доступность сети до нужного адреса, доступность порта, затем реальный сценарий (например, HTTPS-ответ или экран входа RDP). Такой порядок сразу показывает, на каком звене происходит отказ, и снижает спор «это сеть или приложение».
Как правильно проверять DNS, чтобы быстро понять причину сбоя?
DNS стоит проверять не одним запросом, а ожидаемый тип записи и время ответа, а также фиксировать тип ошибки. NXDOMAIN обычно означает неправильное имя или запись, а SERVFAIL чаще говорит о проблеме DNS-сервера или рекурсии. В алерте полезно сохранять, какой DNS-сервер отвечал и какой IP вернулся.
Почему недостаточно пинга и проверки порта для VPN и RDP?
Пинг и «порт открыт» показывают только частичную картину: узел может отвечать, но пользователь все равно не зайдет. Для VPN важно проверить успешность установки туннеля и время подключения, а для RDP — дойти до экрана входа. Эти проверки ловят типовые проблемы вроде зависшей службы, ошибок аутентификации или перегрузки узла.
Какие параметры HTTP/HTTPS важнее всего проверять в синтетике?
Сделайте запрос «как браузер»: проверьте код ответа, редиректы, время до первого байта, TLS-рукопожатие и срок сертификата. По кодам уже видно направление поиска: 200/302/401 — разные ситуации, а 5xx и таймауты чаще указывают на реальную проблему сервиса или его зависимостей.
Откуда запускать проверки, чтобы результаты были честными?
Минимум — две разные сети, которые отражают реальный путь: например, офисная сеть и внешняя точка из интернета. Если нужно точнее, добавьте дата-центр и один-два филиала или проблемный регион. Это помогает отличить общий отказ сервиса от локальной проблемы провайдера, маршрутов или корпоративных правил доступа.
Как выбрать частоту проверок без лишней нагрузки и «мигания»?
Для критичных путей обычно подходят интервалы 1–5 минут, чтобы быстро замечать простой. Для второстепенных проверок часто достаточно 15–60 минут, чтобы не создавать лишний шум и нагрузку. Держите правило простым: чем дороже простой, тем чаще проверка.
Какие таймауты и повторы ставить, чтобы не ловить ложные падения?
Ставьте жесткие таймауты, чтобы тесты не зависали и не забивали очередь, а затем добавьте 1–2 повтора, чтобы единичный сетевой сбой не превращался в инцидент. Практичные ориентиры: DNS — считанные секунды, HTTP — несколько секунд, VPN/RDP — десятки секунд. После запуска подстройте значения по реальным измерениям в пиковые часы.
Как настроить пороги и правила, чтобы алерты были без шума?
Разделите сигналы на деградацию и отказ: медленно — это warning, не работает — это critical. Срабатывание делайте только после нескольких неудач подряд, а восстановление — после нескольких успешных проверок, чтобы убрать флап. И важно гасить повторы, чтобы один инцидент не превращался в десятки одинаковых сообщений.
Что обязательно писать в алерте, чтобы его можно было сразу взять в работу?
В уведомлении должно быть видно три вещи: где запускалась проверка, на каком шаге упало (DNS, TCP, TLS, HTTP, логин) и что именно увидели (таймаут, код, неверный IP) с временем. Тогда сразу понятно, кому эскалировать и с чего начать диагностику. Дополнительно полезно указать, сколько проверок подряд не прошло и когда был первый сбой.