RoCEv2 для GPU-кластера: настройка сети и проверка перед ML
RoCEv2 для GPU-кластера: что настроить в PFC, ECN и MTU, какие метрики собрать и как проверить потери, латентность и джиттер до старта обучения.
Что может пойти не так с RoCEv2 в GPU-кластере
RoCEv2 в GPU-кластере обычно выбирают ради быстрых коллективных операций (all-reduce, all-gather) и стабильной передачи градиентов между узлами. Если сеть ведет себя плохо, обучение не просто замедляется - оно становится непредсказуемым: одна и та же модель то укладывается в окно, то внезапно проседает по скорости.
Проблемы часто выглядят как «непонятные» сбои в вычислениях, хотя причина в сети. Типовые симптомы:
- падение throughput на RDMA-потоках и деградация all-reduce;
- рост ретраев/таймаутов и скачки латентности;
- периодические зависания отдельных GPU-воркеров;
- нестабильная загрузка линков (то пусто, то перегруз);
- «микропаузы» на ровном месте, которые портят время итераций.
Важно понимать: «сеть без потерь» для RoCE - это не обещание нулевых dropped packets во всех счетчиках. В реальности в фабрике может быть обычный best-effort трафик, где дропы допустимы. Для RDMA критично другое: не допускать потерь в классе, где идет RDMA-трафик, и не загонять фабрику в состояние, когда PFC разносит паузы по цепочке.
Типичный сценарий: у вас 8 узлов с GPU, обучение идет нормально до момента, когда параллельно стартует выгрузка датасета или бэкап. Если RDMA и «обычный» трафик смешаны без четкого QoS, появляются очереди, ECN не отрабатывает, а PFC начинает паузить соседние порты. В итоге один узел «выпадает» по времени, и вся группа ждет самого медленного.
Много решается еще до тонкой настройки PFC/ECN/MTU. Стоит заранее выбрать скорость и архитектуру (например, 25/100/200G, leaf-spine), определить границы L2/L3 и решить, будет ли отдельная фабрика под storage или отдельные классы трафика под RDMA. Эти решения почти всегда важнее, чем «тюнинг» в самом конце.
Перед стартом: совместимость, топология и границы L2/L3
RoCEv2 работает поверх UDP/IP, поэтому формально может ходить и через L3. Но требования к потерям и задержкам у RDMA выше, чем у обычного трафика. Поэтому сначала важно убедиться, что железо и схема сети действительно поддерживают нужные механизмы управления перегрузкой.
Начните с совместимости на двух уровнях: NIC в серверах и коммутаторы. На NIC критично, чтобы были заявлены RoCEv2 и корректная работа с ECN (и, если планируете, PFC). На коммутаторах важны очереди и приоритеты, поддержка ECN marking на нужных очередях и предсказуемое поведение PFC на выбранном классе.
Дальше определите границы L2 и L3. PFC - это L2-механизм (pause-кадры), он не проходит через маршрутизаторы. Если вы строите RoCEv2 через L3, полагайтесь на ECN и контроль перегрузки end-to-end, а PFC используйте только внутри L2-сегментов, где вы уверены в настройках и буферах. В leaf-spine это часто означает: L2 внутри стойки или пары стоек, а дальше L3.
Почти всегда полезно отделить RDMA-трафик: отдельный VLAN, а в крупных сетях - и отдельный VRF. Так проще держать изоляцию, управлять QoS и не ловить сюрпризы от широковещания и служебных протоколов в общем сегменте.
Перед тем как трогать PFC/ECN, зафиксируйте базовую модель QoS:
- сколько классов нужно (минимум: RDMA и обычный трафик);
- какой PCP/DSCP будет у RDMA и кто его проставляет (хост или коммутатор);
- какие очереди на коммутаторе соответствуют этим классам;
- где разрешен PFC (только на RDMA-классе);
- где включен ECN marking (обычно на RDMA-очереди).
И последнее: единый план адресации и единый MTU по всей цепочке. В RoCEv2 достаточно одного «узкого» места, чтобы получить фрагментацию, неожиданные потери и провалы производительности еще до первого запуска обучения.
MTU и jumbo frames: как выставить и не сломать путь
Для RoCEv2 в GPU-кластере MTU почти всегда стоит делать единым и большим, чтобы уменьшить накладные расходы и снизить риск микропотерь на высокой нагрузке. Типичный выбор - MTU 9000 (иногда на коммутаторах это выглядит как 9216 на уровне L2, но смысл один: кадр должен пройти целиком от GPU-сервера до GPU-сервера без фрагментации).
MTU должен совпадать на всем пути. Один забытый сегмент на 1500 байт (VLAN, bond, uplink, SVI или промежуточный свитч) даст странные симптомы: периодические таймауты RDMA, падение пропускной способности и плавающий джиттер.
Проверьте и зафиксируйте MTU как стандарт конфигурации:
- хосты: физические интерфейсы, bond/team, VLAN-интерфейсы, bridge (если есть), а также overlay (если используете VXLAN/Geneve и похожее);
- коммутаторы: MTU на портах доступа и аплинках, на порт-каналах, и на SVI (если L3 делается на свитче);
- транзит: любые межцеховые/межстоечные линки и устройства, которые могли остаться на дефолтном MTU.
Как проверить, что MTU проходит по всему пути
Сделайте сквозной тест «с DF» (без фрагментации) между двумя узлами в одном RoCE-домене и найдите место, где режется кадр. На Linux удобно начать с ping и при необходимости уменьшать размер до прохождения:
ping -M do -s 8972 <IP_соседа>
Если пакет не проходит, снижайте размер шагами (например, минус 200, затем бинарным поиском) и параллельно смотрите счетчики на портах: ошибки/дропы/giants. Jumbo frames дают выигрыш, но требуют дисциплины: любое несоответствие MTU ломает весь путь. Поэтому лучше сразу закрепить стандарт в шаблонах конфигов и в проверках перед запуском кластера.
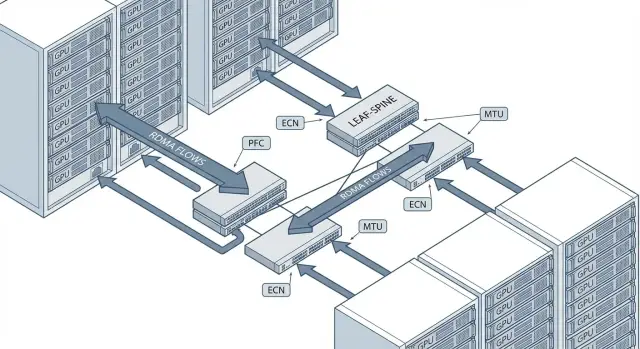
PFC: включаем только там, где нужно
PFC (Priority Flow Control, 802.1Qbb) - это «пауза» не для всего порта, а для выбранного класса трафика. Обычный Ethernet Pause (802.3x) останавливает передачу целиком, из-за чего может внезапно просесть весь трафик на линке. PFC полезен для RoCEv2, потому что RDMA плохо переносит потери, но у PFC есть цена: при неверной настройке он начинает «душить» фабрику, разносит задержки и может вызвать head-of-line blocking.
Главное правило: включайте PFC только для одного приоритета, где идет RDMA, а не «на все сразу». Обычно под RoCE выделяют один 802.1p приоритет (PCP), например 3 или 4, и только на нем включают PFC. Остальной трафик (управление, storage, обычный east-west) должен жить без PFC, иначе при любой перегрузке вы получите цепную реакцию пауз.
Чтобы PFC работал предсказуемо, метки должны корректно доезжать от хоста до коммутатора и обратно. На хосте RDMA-пакеты часто маркируют DSCP, а на L2 это превращается в PCP (802.1p). Проверьте mapping DSCP->PCP на NIC/драйвере и на коммутаторах, и убедитесь, что на транках метки не «обнуляются» политиками и не меняются из-за trust boundary.
Перед включением PFC на портах пройдите короткую последовательность:
- выберите один приоритет для RDMA и включите PFC только на нем на всех портах пути (серверные порты и межкоммутаторные линки);
- настройте доверие к меткам (trust DSCP или trust PCP) единообразно, чтобы классификация была одинаковой на всех устройствах;
- проверьте буферы и пороги PFC с учетом скорости линков и задержки в фабрике: на 100G/200G пауза может быстро заполнить очереди, если пороги слишком высокие;
- убедитесь, что для этого же приоритета включена правильная egress queue и нет случайного шейпинга.
После этого PFC нужно «читать по счетчикам». На коммутаторах и NIC смотрите как минимум:
- PFC Rx/Tx frames по нужному приоритету: редкие события во время пиков допустимы, постоянный рост - признак перегруза;
- PFC pause duration (если доступно): длинные паузы означают, что очередь не успевает разгребаться;
- drops в RDMA-классе: если есть дропы при активном PFC, значит пороги/буферы или классификация неверные;
- ECN/маркировки (если уже включены): если ECN нет, а PFC растет, вы лечите перегруз только «тормозами».
Простой пример: в GPU-узлах под обучение включили PFC на всех восьми приоритетах «на всякий случай». В момент, когда пошел бэкап или большой east-west трафик, паузы начали срабатывать не только для RDMA, и латентность подскочила на всем кластере. После ограничения PFC одним RDMA-приоритетом и выравнивания DSCP/PCP проблема обычно исчезает, а счетчики PFC становятся редкими и понятными.
ECN и контроль перегрузки: чтобы не было микропотерь
В RoCEv2 потери пакетов часто начинаются не с «полного обрыва», а с микропотерь в очереди при всплесках. Для обучения моделей это выглядит как редкие, но болезненные просадки пропускной способности и рост времени итерации. ECN помогает заранее «притормозить» отправителей, пока буфер еще не переполнен.
PFC и ECN решают разные задачи. PFC делает трафик без потерь на уровне L2, но может вызвать head-of-line blocking и, в худшем случае, цепную реакцию пауз. ECN работает мягче: коммутатор помечает пакеты при росте очереди, а хосты сами снижают скорость отправки. В идеале PFC остается как страховка для RDMA-класса, а ECN берет на себя основную работу по контролю перегрузки.
На коммутаторах включают ECN marking именно для очереди RDMA (обычно отдельный QoS-класс/priority). Важно правильно выставить пороги: ранний (когда начинаем маркировать) и верхний (когда маркировка становится агрессивной). Если пороги слишком низкие, маркировка будет даже на пустой сети и снизит скорость. Если слишком высокие - вы все равно поймаете потери и PFC-паузы.
На хостах проверьте, что включена обработка ECN и активен алгоритм контроля перегрузки для RoCEv2 (часто это DCQCN или аналог от вендора NIC). Без этого коммутатор будет маркировать корректно, но отправитель не будет нормально снижать скорость.
Практичная проверка перед запуском:
- дайте фоновую нагрузку и краткие «всплески» (как при all-reduce), затем посмотрите долю ECN-marked пакетов и динамику скорости RDMA;
- убедитесь, что PFC pause-кадры редкие, а не постоянные (иначе вы лечите перегрузку паузами);
- сравните поведение на пустой сети: ECN не должен заметно резать производительность без очередей;
- снимите счетчики очередей/дропов на портах фабрики и счетчики ECN/CNP на NIC.
Если фабрика смешанная (разные модели коммутаторов), заранее согласуйте профили ECN. Одинаковые «цифры порогов» могут означать разный реальный буфер и разное поведение. Практичнее добиваться одинакового результата по метрикам: мало пауз, нет дропов, умеренная маркировка только во время всплесков.
QoS и очереди: как разделить RDMA и «обычный» трафик
Сеть чаще ломается не из-за MTU или PFC, а из-за того, что RDMA-трафик живет в одной очереди с бэкапами, логами и «шумом» от сервисов. Когда фоновые потоки забивают буферы, появляются очереди, микропотери и резкие скачки задержки, которые потом выглядят как «странные» провалы скорости обучения.
Политика QoS, которой обычно достаточно
Проще всего заранее разнести трафик по классам и привязать их к очередям (через 802.1p/PCP или DSCP, в зависимости от вашей схемы). Часто хватает такого разбиения:
- RDMA (RoCEv2) - отдельная очередь;
- storage (например, распределенное хранилище) - отдельная очередь без PFC;
- управление и служебные протоколы (SSH, мониторинг, кластерные агенты) - отдельный класс с гарантированным минимумом;
- остальное - best-effort.
Дальше важно не только «дать приоритет RDMA», но и ограничить фоновый трафик. Шейпинг/полисинг на портах доступа (где сидят шумные источники) часто полезнее, чем попытки лечить перегрузку на магистрали. Цель простая: не позволить бэкапам или массовым копированиям занять буферы и спровоцировать лавину пауз.
Где rate-limit помогает, а где может навредить
Rate-limit уместен на входе от серверов с непредсказуемым best-effort трафиком и на сервисных портах, где легко «разогнаться» случайной задачей. А вот на uplink или на портах, по которым идет RDMA, грубый полисинг может ухудшить задержку и дать джиттер даже без потерь: пакеты начнут копиться и выпускаться рывками.
Проверьте, что приоритет RDMA не приводит к голоданию управления: оставьте для служебного класса небольшой гарантированный минимум и убедитесь по счетчикам очередей, что он реально получает полосу. И обязательно задокументируйте правила маркировки: какие значения PCP/DSCP ставят хосты, какие классы ожидают коммутаторы, и где выполняется trust (хост, ToR, агрегация).
Какие метрики снять до обучения: хосты и коммутаторы
Перед запуском обучения зафиксируйте базовую линию: как ведет себя сеть в «чистом» состоянии (почти без нагрузки) и как она ведет себя под типовым RDMA-трафиком. Это помогает быстрее отделять сетевую проблему от прикладной.
Метрики на хостах (GPU-узлы)
На хостах цель простая: понять, есть ли потери, ретраи и паузы, и где именно они появляются (NIC, очереди, драйвер).
- счетчики RDMA: retries/retransmits, timeouts, ошибки CQ/QP, реакции на ECN (если стек это показывает). Рост ретраев при нормальной загрузке почти всегда означает микропотери или перегрузку;
- статистика интерфейса: drops, errors, FCS/CRC, overruns, missed, а также ошибки по очередям (TX/RX queues). Даже небольшие FCS-ошибки часто указывают на кабель/оптику или проблему порта;
- PFC на хосте: сколько pause-кадров отправили и получили, и на каких приоритетах;
- загрузка: utilization линка, throughput в обе стороны, распределение по очередям. Важно видеть, что RDMA действительно идет в нужном классе QoS;
- латентность и джиттер: p50/p95/p99 на прикладном тесте и на сетевом тесте. Для обучения обычно критичны хвосты (p99), а не среднее.
Метрики на коммутаторах
Коммутаторы должны подтвердить, что они не теряют пакеты в очередях и не уходят в длительные паузы.
- drops по очередям и по приоритетам (особенно в классе RDMA). Нулевые drops при росте нагрузки - хороший знак;
- PFC pause: количество и длительность пауз по классам. Если паузы растут, а буферы забиваются, вы близко к head-of-line blocking;
- ECN marks: сколько пакетов помечается. В норме ECN растет под нагрузкой, но при этом ретраи на хостах не должны «взрываться»;
- buffer occupancy (если доступно): насколько заполняются буферы по портам и очередям. Это лучший индикатор скрытой перегрузки;
- utilization портов и микроберсты: пики загрузки и асимметрия. Часто проблема не в среднем трафике, а в коротких всплесках.
Снимайте метрики дважды: сначала 5-10 минут в простое, затем под типовой нагрузкой, близкой к реальному профилю обучения (количество потоков, размер сообщений, all-reduce). Затем сравните, где появляются первые ретраи, на каких портах растут ECN marks, и совпадает ли это с ростом p99 латентности и джиттера.
Как проверить потери, латентность и джиттер: пошагово
Проверку лучше сделать до первого обучения. У RoCEv2 проблемы часто проявляются не как явные обрывы, а как редкие микропотери и длинные хвосты задержек.
Быстрый план проверки (до запуска ML)
-
Начните с физики: убедитесь, что скорость и режим совпадают на обоих концах, нет flaps, растущих счетчиков ошибок, проблем с FEC. Частая причина джиттера - плохая оптика или нестабильный DAC-кабель, когда «вроде работает», но с коррекцией ошибок на пределе.
-
Проверьте MTU end-to-end по всему пути (сервер, ToR, агрегация). Важно не только выставить jumbo frames, но и убедиться, что нигде нет скрытой фрагментации.
-
Прогоните RDMA-тесты между парами узлов и по схеме all-to-all. Пары помогают увидеть точечные проблемы, а all-to-all быстро показывает «горячие» направления и перегрузку аплинков.
-
Создайте контролируемую перегрузку и посмотрите, как ведут себя PFC и ECN. Цель не в том, чтобы «уронить трафик», а в том, чтобы увидеть рост пауз и маркировок при нулевых дропах на lossless-классе и без лавины пауз на соседних классах.
-
Измеряйте не только среднее, а p99 и p999 по задержке, и фиксируйте джиттер. Для обучения важны хвосты: редкие всплески задержки могут замедлять итерации сильнее, чем небольшое падение средней скорости.
Чем измерять и что записать в «golden»
Минимальный набор команд обычно такой:
# MTU без фрагментации (подберите размер под ваш MTU)
ping -M do -s 8972 <ip>
# RDMA latency/bandwidth (пример для perftest)
ib_write_lat -a <peer_ip>
ib_write_bw -a <peer_ip>
Если в тестах «пара узлов A-B» стабильно дает хорошую латентность, а в all-to-all p999 резко растет только через один ToR, это почти всегда указывает на перегрузку конкретного аплинка или неправильные очереди/QoS на этом участке.
В конце сохраните результаты как «golden baseline»: версии драйверов/прошивок, MTU, настройки QoS и ключевые метрики (drops, PFC pause, ECN marks, p50/p99/p999). Это сильно ускоряет поиск причин, если поведение изменится после обновлений или расширения кластера.
Типовые ошибки в настройке RoCEv2 и как их быстро найти
Большая часть проблем выглядит как «обучение стало медленнее» или «иногда зависают коллективные операции». Ниже ошибки, которые чаще всего дают скрытые потери, паузы и нестабильную задержку, и способы быстро сузить поиск.
PFC: глобальные паузы и неверный класс
Самая болезненная ошибка - включить PFC везде и сразу на несколько приоритетов. Итог: паузы начинают распространяться по фабрике, а один перегруженный порт притормаживает множество потоков.
Вторая частая причина - PFC включен, но RDMA-трафик не попадает в нужный приоритет из-за неверной разметки (DSCP/PCP) или потому что QoS-политика на коммутаторе и на хосте по-разному понимают приоритеты. Быстрый признак: счетчики PFC растут, а drops на очередях все равно есть.
MTU и ECN: «почти работает», но медленно
MTU, отличающийся на одном участке пути (хост, ToR, межкоммутаторные линки), часто не ломает соединение полностью, но провоцирует фрагментацию, лишнюю нагрузку на CPU, скачки RTT и падение пропускной способности. Если одна нода стабильно хуже остальных, MTU - один из первых подозреваемых.
С ECN бывает две крайности: слишком агрессивные пороги дают постоянное «подтормаживание» (низкая утилизация линка), а слишком мягкие или несогласованные параметры приводят к микропотерям в очередях. Сравнивайте рост ECN-marked/CE на портах, размер очередей и фактические drops.
Короткая диагностика, которая обычно быстро показывает направление:
- на коммутаторах: drops/overruns по очередям, PFC pause frames и время паузы, ECN-marked, заполнение буферов;
- на хостах: ошибки NIC, retrans/timeout на RDMA, фактическая скорость портов, счетчики QoS по классам;
- нагрузка: тестируйте не 1 поток, а профиль, близкий к реальному (несколько GPU, несколько пар узлов);
- изоляция: временно отделите «шумный» трафик (хранилище, бэкапы, обновления) от RDMA по очередям;
- сравнение: найдите «хорошую» и «плохую» ноду и сравните разметку и MTU по шагам пути.
На практике удобнее всего завести эталонную конфигурацию для типовых узлов (например, стойка с GPU и ToR) и проверять отклонения перед вводом кластера.
Короткий чеклист перед запуском обучения моделей
Перед тем как отдавать кластер под обучение, сделайте быструю проверку по сети. Здесь важнее всего не «максимальные цифры», а предсказуемость: чтобы не было скрытых потерь, пауз и скачков задержки.
Проверьте базовую гигиену по всему пути (NIC - ToR - spine - ToR - NIC):
- на всех линках одинаковые MTU, скорость и настройки FEC; нет CRC/FCS errors, symbol errors, flaps и других признаков проблем на физике;
- RDMA-трафик размечен (DSCP/802.1p) и стабильно попадает в выделенную очередь, не смешиваясь с «обычным» трафиком;
- PFC включен только для нужного класса (который несет RDMA), а PFC-счетчики не растут постоянно и нет признаков pause-storm;
- ECN включен для RDMA-класса и действительно подсвечивает перегрузку: нет постоянной маркировки при нормальной загрузке;
- на коммутаторах и на NIC нет дропов именно в очереди RDMA (и нет WRED/tail drop там, где они не должны срабатывать).
После этого проверьте качество под нагрузкой. Важно тестировать не «одну пару хостов», а all-to-all и с параллельными потоками, потому что именно так ведет себя обучение.
- латентность и джиттер стабильны в all-to-all тестах при целевой загрузке: нет периодических «пил» и редких пиков, которые совпадают с ростом PFC/ECN;
- при фоне (служебный трафик, хранение, мониторинг) RDMA-очередь сохраняет предсказуемость: метрики не ухудшаются резко.
Если хоть один пункт не проходит, не начинайте обучение «на авось». Исправьте сначала: чаще всего проблема в одном несоответствии MTU/класса QoS или в PFC, включенном шире, чем нужно.
Пример сценария и следующие шаги для ввода кластера
Представим старт: 16 GPU-серверов, 2 leaf-коммутатора и 1 spine, аплинки и хостовые порты 100G. Для RDMA выделен отдельный VLAN (и отдельный приоритет QoS), а «обычный» трафик управления и хранения живет отдельно. Цель перед первым обучением - убедиться, что фабрика ведет себя предсказуемо: нет потерь, нет «залипания» PFC, нет всплесков задержки.
Проверку удобнее делать по этапам, каждый раз фиксируя базовую линию и сравнивая ее с предыдущей:
- 2 узла: RDMA bandwidth/latency тесты, проверка MTU по всему пути, базовые счетчики портов;
- 4 узла: параллельные потоки (несколько пар), проверка справедливости и отсутствия микропотерь под нагрузкой;
- 8-16 узлов: коллективные паттерны (all-reduce/traffic matrix), имитация реального профиля обучения и фоновый «обычный» трафик;
- ночь/длительный прогон: 2-6 часов, чтобы поймать редкие события (bursts, периодические просадки).
После каждого шага смотрите на «красные флаги» в счетчиках. Важно не только наличие проблем, но и динамика: растет ли показатель вместе с нагрузкой или вспыхивает на коротких интервалах.
- drops/discards на портах (особенно при включенном PFC) и рост ошибок по очередям;
- excessive PFC: много пауз, длинные паузы или PFC начинает затрагивать не-RDMA классы;
- рост retries/RNR NAK на RDMA, падение эффективной пропускной способности при стабильной нагрузке;
- ECN: слишком много маркировок вместе со скачками latency (признак неверных порогов или переполнения буферов);
- джиттер: редкие пики задержки, которые совпадают со всплесками PFC или очередями egress.
Отчет лучше оформить как короткий документ на 1-2 страницы: (1) базовая линия (2 узла), (2) тест под нагрузкой (весь кластер), (3) найденные отклонения и причины, (4) план правок с приоритетами и повторными измерениями.
Если это ваш первый кластер на RoCEv2 или нет уверенности в профилях NIC/коммутаторов, перед пилотом полезна независимая валидация фабрики и сетевых профилей. В таких задачах может помочь GSE.kz (gse.kz) как производитель серверов и системный интегратор: важно заранее зафиксировать архитектуру, QoS-модель и критерии «стоп-сигналов» по счетчикам до запуска обучения.