Резервное копирование 3-2-1: внедрение, ошибки и тесты
Резервное копирование 3-2-1: пошагово настраиваем копии, выбираем носители, регулярно проверяем восстановление и избегаем невосстановимых бэкапов.
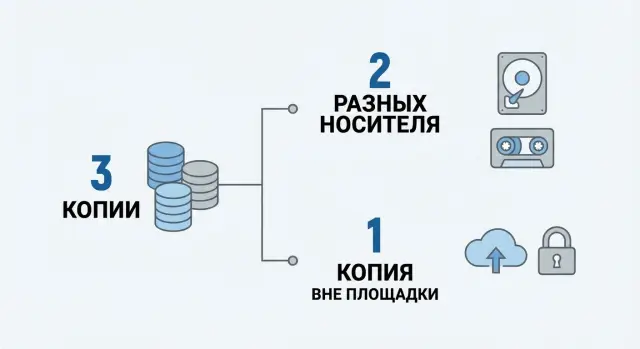
Зачем вообще нужна схема 3-2-1
Данные чаще всего теряются не из-за «кибервойны», а из-за обычных и неприятных событий. Кто-то удалил папку «на минуту», обновление сломало базу, диск внезапно умер, шифровальщик добрался до серверов. Бывает и хуже: пожар, затопление, кража техники.
Проблема в том, что фраза «бэкап есть» еще не означает «мы восстановимся». Копия может оказаться бесполезной по простым причинам: ее делали на один внешний диск, копировали не то, что нужно, файл повредился, пароль потеряли, а сам бэкап зашифровался тем же вирусом, что и рабочие данные. Обычно это выясняется в самый неподходящий момент.
Для бизнеса потеря данных почти всегда превращается в деньги и стресс: простой продаж или производства (или приема пациентов), срыв сроков и договоров, штрафы и проблемы с отчетностью, репутационные потери, срочные траты на восстановление и «ручной» ввод данных.
Схема 3-2-1 нужна именно потому, что она практичная и учитывает реальность. Она снижает риск «одной точки отказа»: если один носитель умер, другой остался; если офис недоступен, копия есть вне площадки; если вирус шифрует все доступное, у вас остается изолированный вариант.
Если коротко, 3-2-1 дает три вещи: запасной план под разные типы аварий, понятную структуру хранения и дисциплину. А дисциплина в бэкапах важнее «идеальной» технологии: в кризис вы действуете по заранее подготовленному сценарию, а не пытаетесь вспомнить, где лежит последняя рабочая копия.
Схема 3-2-1 простыми словами
Резервное копирование по правилу 3-2-1 - это способ не остаться без данных, когда ломается диск, шифруется сервер или кто-то случайно удаляет важную папку. Смысл в том, чтобы у вас всегда было несколько независимых вариантов восстановления.
Правило читается так: должно быть три копии данных, две - на разных типах носителей, и одна - вне основной площадки.
Что именно считается «тремя копиями»
Первая копия - это рабочие данные (то, чем вы пользуетесь каждый день). К ним нужны минимум две резервные копии.
Важно: «у нас есть копия на сервере» - это чаще всего только одна резервная. Для 3-2-1 нужна еще одна, отдельная.
Что значит «разные носители» и «вне площадки»
«Разные носители» - это не два раздела на одном сервере и не два диска в одном RAID-массиве. Это два независимых места хранения, которые не ломаются вместе.
«Вне площадки» - это физически другая локация (второй офис, отдельная серверная, дата-центр) или облачное хранилище. Но не «просто куда-то в облако»: доступы должны быть ограничены, а лучше разделены так, чтобы зараженный сервер не мог удалить и бэкапы.
Практический пример может выглядеть так:
- рабочие файлы и базы на основном сервере в офисе;
- ежедневный бэкап на локальное хранилище другого типа (например, NAS);
- копия этих бэкапов - в другой локации или в облако с отдельными учетными данными.
Если один слой подводит, остается еще как минимум один шанс восстановиться.
С чего начать: инвентаризация и цели (RPO/RTO)
Любая схема 3-2-1 начинается не с выбора дисков или облака, а с простого списка: что именно вы защищаете и насколько больно будет это потерять. Без инвентаризации легко сделать бэкап «всего понемногу», но не того, что действительно важно.
Соберите перечень ключевых данных и систем. Обычно туда попадают бухгалтерия и финансовые базы, CRM/ERP и другие рабочие БД, корпоративная почта и архивы, общие папки с документами и договорами, а также конфигурации серверов, сетевого оборудования и критичных приложений.
Дальше задайте два вопроса, которые задают рамки для всего плана бэкапа для компании.
RPO (сколько данных вы готовы потерять). Это про «на сколько назад можно откатиться». Например, если RPO = 4 часа, значит, копии должны появляться так часто, чтобы при аварии потерять не больше 4 часов изменений.
RTO (как быстро нужно восстановиться). Это про простой. Если RTO = 2 часа, значит, через 2 часа после инцидента работа должна быть восстановлена хотя бы в минимально приемлемом режиме.
Затем классифицируйте данные по приоритетам, чтобы не тратить одинаковые ресурсы на все подряд:
- A: остановка бизнеса (касса, платежи, ключевые базы);
- B: можно пережить день, но с потерями (почта, часть документов);
- C: удобно иметь, но не критично (архивы, старые проекты).
И еще один практичный шаг: назначьте владельцев данных. Запишите, кто отвечает за каждую систему и кто принимает решение при аварии (например, «восстанавливаем сначала базу продаж, потом почту»). Это экономит часы, когда времени нет.
Выбор носителей и мест хранения для 3-2-1
Смысл схемы 3-2-1 не в «трех папках», а в том, чтобы отказ одного устройства, типа носителя или площадки не уничтожал все копии сразу. Поэтому сначала трезво оцените, какие сбои у вас наиболее вероятны: поломка диска, шифровальщик, ошибка администратора, пожар в офисе, потеря доступа к учетке.
Первая резервная копия обычно лежит рядом с рабочими системами, чтобы восстановление было быстрым. Это может быть отдельный сервер под репозиторий, NAS или дисковое хранилище. Важно, чтобы это не была та же машина, где крутятся ваши сервисы, и чтобы у хранилища были отдельные учетные записи и права.
Вторая копия по правилу «другой тип носителя» защищает от одинаковых причин отказа. Если основной бэкап хранится на дисках, второй можно делать на ленту, на внешние диски с ротацией или в хранилище другого класса (например, с другим контроллером, прошивкой или пулом дисков). Идея простая: один дефект или одна ошибка не должны повториться на обеих копиях.
Третья копия должна быть вне площадки. Это может быть облако или вторая площадка (другой офис, серверная в другом здании). Здесь ключевое - условия доступа: отдельные учетные данные, минимальные права, по возможности неизменяемое хранение (чтобы бэкап нельзя было удалить или перезаписать за минуту). Если используете вторплощадку, проверьте, что она не зависит от той же сети, домена и тех же админ-учеток без разделения ролей.
Чаще всего выбор выглядит так:
- небольшой офис: локальный NAS для быстрых восстановлений + внешние диски по графику с хранением вне офиса + облачная копия для критичных данных;
- организация с серверной: отдельный сервер под бэкапы (например, выделенный rack-сервер как репозиторий) + второй носитель (лента или отдельное хранилище другого типа) + внеплощадочная копия в облако или на вторплощадку.
Главная ошибка при выборе носителей - сделать «разные копии», которые на деле зависят от одного и того же: один вендор, один домен, один набор админ-учеток, одна стойка, один источник питания. Если один компрометированный аккаунт может удалить все бэкапы, то носители выбраны неправильно, даже если их три.
Безопасность бэкапов: доступы, шифрование, неизменяемость
Даже правильно собранная схема 3-2-1 не спасет, если злоумышленник получит доступ к хранилищу или если администратор случайно удалит цепочку копий. Безопасность бэкапов - это не только антивирус. Это правила доступа, ключи и защита от удаления.
Начните с ролей и прав. Логика простая: один человек не должен иметь возможность тихо поменять политику, стереть копии и скрыть следы.
- Оператор бэкапа запускает задачи и видит отчеты, но не удаляет хранилища.
- Администратор хранилища управляет дисковыми пулами, но не меняет политики бэкапа.
- Аудитор или безопасник читает журналы и отчеты, без прав на изменения.
- Владелец системы подтверждает RPO/RTO и критичность данных.
- Экстренный доступ оформляется отдельной процедурой и отдельными учетными данными.
Шифрование нужно и при передаче, и при хранении. Ключи не держат рядом с самими копиями: лучше отдельное защищенное хранилище ключей и понятный порядок доступа (кто, когда, по какому основанию). Потеряли ключ - бэкап превращается в архив без замка.
Для защиты от удаления используйте неизменяемые копии (immutable) или режим WORM там, где риск максимальный: для недельных и месячных точек восстановления, а также для копий, которые уходят во вторую площадку или в изолированное хранилище. Это особенно важно для критичных сервисов: шифровальщик часто пытается удалить резервные копии первым же шагом.
Отдельные учетные записи для бэкапа и многофакторная аутентификация - обязательны. Не используйте доменного администратора для ежедневных задач резервного копирования.
Журналы действий должны фиксировать изменения политик, удаление точек и попытки входа. Минимум, что стоит проверять регулярно: кто менял расписания, кто и что удалял, где отключалось шифрование, какие были ошибки доступа к хранилищу, были ли попытки входа с необычных устройств или адресов.
Пошаговый план внедрения 3-2-1
Схема 3-2-1 работает только тогда, когда заранее решены три вещи: какие данные важнее, где физически лежат копии и как вы узнаете о сбое раньше, чем понадобится восстановление.
Начните с разбиения данных на классы. Например: критичные (бухгалтерия, базы 1С, почта), важные (общие файлы отделов), второстепенные (архивы, старые проекты). Для каждого класса задайте частоту и допустимую потерю данных: для базы это может быть каждый час, для общих папок - раз в сутки.
Дальше соберите план в понятные шаги:
- Определите источники и частоту: что копируем (БД, виртуальные машины, файловые шары, ноутбуки руководителей) и как часто для каждого класса данных.
- Настройте расписание и типы копий: ежедневные инкрементальные, еженедельные полные, ежемесячные архивные (если нужно - с отдельным набором правил).
- Реализуйте 3-2-1 по местам хранения: первая копия рядом с системой (быстрое восстановление), вторая - на другом носителе, третья - вне площадки.
- Включите контроль качества: проверку целостности, автоматические отчеты и уведомления об ошибках, чтобы сбой бэкапа не оставался незамеченным неделями.
- Зафиксируйте retention и ответственность: сроки хранения, ротацию (что удаляется и когда), а также короткую инструкцию восстановления (кто делает, где лежит копия, какие пароли или ключи нужны, какой порядок действий).
Простой пример: у небольшой клиники есть сервер с базой пациентов и общий файловый архив. Ежедневно делаются копии на локальное хранилище для быстрых откатов, раз в неделю - полный бэкап на отдельный носитель, а раз в сутки копия уходит вне офиса. Если шифровальщик заденет рабочий сервер, останется изолированная копия, которую можно поднять даже при полном заражении сети.
Документируйте не только «где лежит», но и «как проверить, что восстановится». Это экономит часы в день инцидента.
Политики хранения: частота, глубина, ротация
Политика хранения отвечает на три вопроса: как часто вы делаете копии, как далеко в прошлое можете откатиться и когда старые копии удаляются. Без этого 3-2-1 легко превращается в «папку с бэкапами», которая внезапно заканчивается местом или не содержит нужной версии.
Начните с критичности. Для систем, от которых зависит работа (почта, 1С, базы пациентов, файловые шары отдела продаж), копии должны делаться чаще и храниться дольше. Для «архивов ради истории» обычно достаточно редких копий с длинным хранением.
Частота и глубина: сколько точек восстановления нужно
Выбирайте детализацию под тип данных. Файлам часто нужна возможность вернуть один документ. Виртуальным машинам - быстрый откат целиком. Базы данных лучше копировать так, чтобы восстановление было предсказуемым (например, полный бэкап плюс журнал или инкремент, если вы это используете).
Базовая схема, которую легко объяснить руководству:
- ежедневно: быстрые копии (инкремент/дифф) для рабочих данных;
- еженедельно: полный бэкап ключевых систем;
- ежемесячно: «снимок месяца» для долгого хранения.
Отдельная строка в политике - конфигурации. Бэкапы настроек сетевого оборудования, гипервизора, контроллера домена, систем хранения и «мелких, но важных» сервисов часто забывают. А потом при аварии поднимают сервер, но теряют сеть, роли, политики и доступы.
Ротация: что удаляем, что оставляем надолго
Ротация помогает не упереться в объемы через пару месяцев. Простой подход: храните много коротких точек (например, 14-30 дней), меньше средних (8-12 недель) и совсем немного долгих (12-36 месяцев) - но только для того, что действительно нужно по закону или для отчетности.
Планируйте рост данных заранее. Раз в квартал пересматривайте: сколько добавилось терабайт, насколько выросли окна бэкапа и восстановление, хватает ли места на локальном хранилище и на второй площадке. Если закупаете серверы и СХД под инфраструктуру, закладывайте запас под бэкап не «впритык», а с учетом роста и новых систем.
Частые ошибки и почему бэкапы оказываются невосстановимыми
Главная причина «невосстановимых» резервных копий простая: копирование настроили, а сценарий реальной аварии никто не продумал. В день инцидента выясняется, что копия либо повреждена, либо недоступна, либо восстановление занимает дни вместо часов.
Ошибки, которые чаще всего ломают восстановление даже при формально настроенной схеме:
- Копия хранится рядом с исходными данными: на том же сервере, в той же СХД или в той же виртуальной инфраструктуре. Пожар, шифровальщик или сбой контроллера забирает сразу и рабочие данные, и бэкап.
- Внеплощадочная копия существует только «на бумаге»: ее либо нет, либо она уезжает раз в неделю, хотя бизнесу нужно восстановление за сутки. Задержка репликации (или ручной вывоз диска) не совпадает с ожиданиями по RPO.
- Ошибки бэкапа никто не отслеживает: задачи «крутятся», но логи красные неделями, уведомления выключены, письма приходят на ящик, который никто не читает.
- Резервируют не то, что нужно для запуска: сохраняют папки с файлами, но забывают про базы данных, конфиги приложений, учетные записи сервисов, лицензии, сертификаты и ключи шифрования. Данные восстановили, а система все равно не поднимается.
- Шифрование включили, но не управляют ключами: ключи лежат в доступной всем папке или, наоборот, у одного сотрудника «в голове». Потеряли ключ - получили бесполезный набор файлов.
Отдельная проблема - никто не знает порядок восстановления и реальное время простоя. После атаки шифровальщика команда находит последнюю копию, но не понимает, что поднимать сначала (AD, базы, файловые ресурсы), где лежат пароли, и хватит ли места для развертывания.
Хороший признак зрелости - когда есть короткая инструкция восстановления и понятный ответ на вопрос: «Если сервер не включится прямо сейчас, что мы делаем в первые 30 минут?»
Регулярные тесты восстановления: как проводить и что фиксировать
Резервные копии ценны только тогда, когда вы реально умеете из них подняться. Поэтому тест восстановления должен быть регулярным и запланированным, а не «когда случится авария». Даже при схеме 3-2-1 разумный минимум - ежемесячный тест для одного важного сервиса (например, бухгалтерии, почты или файлового хранилища).
Два уровня тестов: быстро и «по-взрослому»
Начните с малого, но делайте это стабильно. Затем добавляйте более сложные проверки.
- Восстановление файла или папки из нужной точки во времени.
- Восстановление системы целиком: поднять виртуальную машину или сервер «с нуля», включая настройки и доступы.
- Проверка целостности: убедиться, что данные открываются и не повреждены.
- Проверка доступности: убедиться, что пользователи могут войти и работать.
Тестировать лучше не на боевой среде. Подойдет отдельная тестовая площадка или изолированный сегмент сети, где восстановление не перетрет рабочие данные и не «засветит» секреты. Если отдельной среды нет, используйте хотя бы изоляцию по сети и четкие правила: что можно включать и кому.
Критерии успеха и что записывать
Чтобы тест был полезным, заранее договоритесь, что считается успехом: уложились ли вы во время восстановления, не потеряли ли данные, доступен ли сервис пользователям.
По итогам фиксируйте результаты так, чтобы другой человек смог повторить процедуру:
- чеклист шагов и фактическое время (сравнение с RTO);
- какая точка восстановления использована и какой объем данных (проверка RPO);
- логи системы бэкапа и ошибки, если были;
- выводы и задачи: что исправить, кто ответственный, срок.
Пример из практики: как 3-2-1 выглядит в небольшой организации
Представьте небольшую клинику (или школу): есть файловый сервер с документами (договоры, приказы, сканы) и отдельная учетная система с базой данных (расписание, начисления, записи пациентов). Персонал небольшой, отдельного администратора может не быть, поэтому важно, чтобы схема была понятной и проверяемой.
Цели задают правила. Для документов клиника решает: RPO 24 часа (потерять изменения за день терпимо). Для базы учетной системы - RPO 4 часа (иначе придется вручную восстанавливать приемы и оплаты). По времени восстановления фиксируют ориентиры: документы поднять за 2-3 часа, базу - за 1-2 часа.
Дальше собирают 3-2-1 так, чтобы оно работало без героизма:
- Копия 1 (рабочая): данные на сервере.
- Копия 2 (локальная): ежедневный бэкап файлов на отдельное хранилище в той же сети, а база - каждые 4 часа.
- Копия 3 (вне площадки): раз в сутки отправка копии на удаленную площадку (второй офис или защищенное облако). Плюс раз в неделю - архив на отдельный носитель, который не подключен постоянно.
Через месяц случается типичный инцидент: сотрудник открывает вложение, шифровальщик добирается до сетевых папок, а затем начинает портить файлы на сервере. Здесь важна деталь: локальное хранилище для бэкапов недоступно по обычным учеткам и не смонтировано как сетевой диск «для всех».
Действия по шагам:
- отключают зараженный компьютер и сервер от сети, фиксируют время начала инцидента;
- проверяют, какие бэкапы были сделаны до заражения (по журналам и контрольным файлам);
- поднимают чистую виртуальную машину или переустанавливают сервер;
- восстанавливают базу из последней здоровой копии (например, 2 часа потерь вместо 4), затем документы из ночной копии;
- сверяют работу учетной системы и доступ к ключевым папкам, после чего включают пользователей по очереди.
Итог: базу восстановили за 1,5 часа, документы - за 3 часа, потери по документам уложились в сутки. После разбора добавили улучшения: отдельные учетные записи только для бэкапа, регулярный тест восстановления раз в месяц и правило, что внеплощадочная копия хранится неизменяемо (чтобы шифровальщик не «дотянулся»).
Чеклист и следующие шаги
Быстрый тест: ответьте «да» на каждый пункт.
- Есть минимум 3 копии данных (включая рабочую).
- Копии лежат минимум на 2 разных типах носителей или платформах.
- Одна копия хранится вне площадки.
- Резервируются не только файлы, но и критичные базы, конфиги, ключи и лицензии.
- Есть понятные RPO и RTO для каждой системы.
- Уведомления о сбоях включены и их реально читают.
- Доступы к бэкапам ограничены и отделены от обычных учеток.
- Копии шифруются, ключи хранятся отдельно.
- Есть защита от удаления (неизменяемость или хотя бы отдельные права).
- За последний месяц проводились тесты восстановления, результат зафиксирован.
Если сейчас многое «нет», начните с малого и двигайтесь по плану.
Что реально сделать за 1 день: составить список систем и данных (что спасать в первую очередь), назначить владельца бэкапов и резервного человека на подмену, включить уведомления о провалах заданий и заполнении хранилища, определить минимальные RPO/RTO для 3-5 самых важных сервисов, сделать пробное восстановление одного файла и одной папки на отдельную машину.
Что сделать за 1-2 недели: настроить внеплощадочную копию с отдельными доступами, ввести расписание тестов восстановления (например, еженедельно по одному сервису), описать «инструкцию на 1 страницу» (где лежат бэкапы, кто запускает восстановление, куда звонить), добавить контроль целостности и отчеты, проверить сценарий «все сломалось»: потеря домена, шифровальщик, отказ дискового массива.
Интегратора имеет смысл подключать, если у вас много разрозненных систем (виртуализация, базы, почта, филиалы), есть требования по соответствию и аудитам или у ИТ просто не хватает времени довести процесс до регулярных тестов.
Если нужна опора по инфраструктуре, GSE.kz (gse.kz) может помочь с серверной частью под репозиторий и площадку восстановления, подбором хранения и организацией поддержки, чтобы бэкапы не зависели от одного человека.
FAQ
Что такое правило 3-2-1 простыми словами?
Правило 3-2-1 — это минимальная «страховка» от потери данных: - **3 копии**: рабочие данные + минимум 2 резервные; - **2 разных типа носителей/платформ**: чтобы один и тот же сбой не убил все копии; - **1 копия вне площадки**: чтобы пережить пожар, кражу, недоступность офиса или полное заражение сети.
Что считается «тремя копиями», и почему рабочие данные тоже считаются?
Обычно считают так: - **Копия №1** — рабочие данные (сервер/ПК/виртуальная машина/БД); - **Копия №2** — первая резервная (для быстрых восстановлений рядом); - **Копия №3** — вторая резервная (независимая) и/или внеплощадочная. Важно: «бэкап на том же сервере» или «на другом диске в том же RAID» — это почти всегда **не отдельная копия** в смысле 3-2-1.
Подойдут ли два диска в одном сервере вместо «двух носителей»?
Нет. Два раздела, два тома или два диска в одном массиве часто падают по общей причине: контроллер, питание, ошибка админа, шифровальщик, который видит все сетевые ресурсы. Хороший ориентир: если одним действием (одной учеткой или одной аварией) можно потерять обе копии — это **не разные носители**.
Какие носители чаще всего используют для 3-2-1 в реальной компании?
Рабочая схема для небольшого офиса: - локальная копия на отдельное хранилище (NAS/сервер-репозиторий) для быстрых откатов; - вторая копия на **внешние диски с ротацией** или **ленточное хранение**; - плюс **внеплощадочная** копия (вторая площадка или облачное хранилище с отдельными учетками). Если бюджета мало, начните с внеплощадочной копии критичных данных и строгих прав доступа — это дает максимум эффекта.
Что лучше для «вне площадки»: облако или вторая площадка?
По умолчанию выбирают вариант, который реально обслуживать: - **вторая площадка** (другой офис/серверная/дата-центр) — удобно для больших объемов и предсказуемой скорости; - **облако** — удобно для небольших и средних объемов и как «страховка» от потери площадки. Главное требование: внеплощадочная копия должна быть с **отдельными учетными данными**, минимальными правами и желательно с защитой от удаления (неизменяемость/WORM).
Как определить RPO и RTO, чтобы схема 3-2-1 была адекватной?
Начните с грубых, но понятных чисел: - **RPO**: сколько данных можно потерять (например, 4 часа — значит, копии нужны чаще, чем раз в 4 часа); - **RTO**: за сколько нужно восстановить работу (например, 2 часа — значит, восстановление должно быть быстрым и проверенным). Практичный шаг: разделите системы на классы **A/B/C** и задайте разные RPO/RTO, чтобы не пытаться одинаково «спасать всё».
Как настроить частоту и срок хранения бэкапов, чтобы не закончился объем?
Базовый план, который легко внедрить: - ежедневные копии для рабочих данных (обычно инкрементальные); - еженедельная полная копия ключевых систем; - ежемесячная «точка месяца» для долгого хранения. Дальше добавьте ротацию: много точек за последние 14–30 дней, меньше — за 2–3 месяца, и только нужные — на 1–3 года (если есть требования по отчетности).
Как защитить бэкапы от шифровальщика и случайного удаления?
Минимум, который реально помогает: - отдельные учетные записи для задач бэкапа, не доменный админ; - MFA там, где возможно; - разделение ролей (оператор/админ хранилища/аудит); - шифрование при передаче и хранении, а ключи — отдельно; - **неизменяемые** точки (immutable/WORM) хотя бы для недельных/месячных копий. Цель простая: чтобы шифровальщик или ошибка человека не могли удалить все точки восстановления за минуты.
Как часто нужно тестировать восстановление и что именно проверять?
Потому что «бэкап есть» не означает «мы восстановимся». Минимальный регулярный тест: - восстановить один файл/папку из нужной даты; - раз в месяц — восстановить целиком сервис (виртуальную машину или базу) в изолированной среде; - зафиксировать фактическое время и сравнить с RTO. Если тесты не проходят — лучше узнать об этом сегодня, а не в день аварии.
Какие самые частые ошибки из‑за которых бэкапы оказываются невосстановимыми, и когда стоит звать интегратора?
Чаще всего ломают восстановление такие вещи: - копии лежат «рядом» и зависят от одной площадки/домена/учеток; - резервируют не всё нужное для запуска (конфиги, сертификаты, сервисные учетки, ключи); - нет уведомлений и контроля ошибок — бэкапы «красные» неделями; - ключи шифрования потеряны или доступны всем; - нет короткой инструкции: что поднимать первым и кто принимает решение. Если у вас много систем и филиалов или нет времени довести процесс до регулярных тестов, разумно подключать интегратора. Например, GSE.kz может помочь собрать серверную часть под репозиторий/площадку восстановления и организовать поддержку, чтобы бэкапы не держались на одном человеке.