Разграничение доступа в LLM-сервисе: RBAC, ABAC и аудит
Разграничение доступа в LLM-сервисе: как настроить RBAC и ABAC, фильтровать контекст по правам и выдавать источники для аудита без утечек.
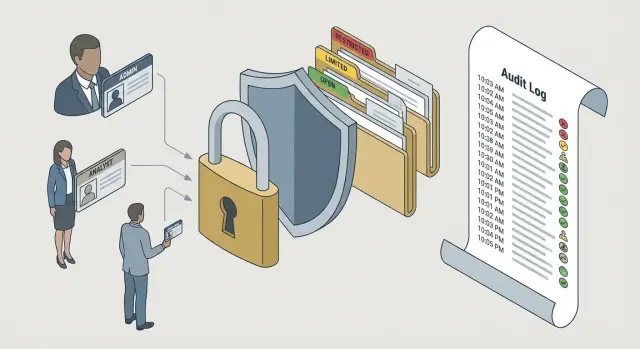
В чем проблема: LLM может «смешать» доступы
LLM хорошо отвечает на вопросы, потому что собирает ответ из всего контекста, который ему дали: системных инструкций, истории чата, найденных документов и данных из интеграций. Если в этот контекст попадает лишнее, модель часто не распознает это как секрет. Она просто использует информацию, чтобы быть полезной, и делает это без явных ошибок.
Типичная ситуация - один корпоративный чат-бот для всей компании. Финансы спрашивают про платежи, HR - про кандидатов, юристы - про договоры, а IT - про инциденты. Когда у всех общий интерфейс и общая база знаний, запрос сотрудника из одного отдела может случайно подтянуть документы другого отдела. Риск особенно высокий, если похожи названия проектов, клиентов или файлов.
Опасность не только в прямой утечке. Есть и более тихие сценарии: модель может пересказать кусок отчета с ограниченным доступом, назвать цифры из закрытой таблицы или сделать вывод на базе данных, которые пользователь не должен был видеть. В итоге люди принимают неверные решения, а при проверке трудно объяснить, откуда в ответе взялась конкретная деталь.
Успех в такой системе выглядит просто и измеримо. В ответ попадает только то, на что у пользователя есть доступ (принцип наименьших прав). Контекст фильтруется до генерации, то есть лишнее не передается модели вообще. Есть проверяемые первоисточники: можно показать цитату и идентификатор документа, не раскрывая лишнего. И есть аудит: понятно, какие данные были использованы и почему они были разрешены.
Модель угроз простыми словами: что защищаем и от кого
В LLM-сервисе участвуют не только текстовые подсказки. Под капотом используются документы, страницы базы знаний, файлы с общих папок, письма, записи из CRM или тикеты поддержки. Иногда добавляются фрагменты из внутренних баз через поиск или интеграцию. Защищать нужно корпоративные данные, правила доступа к ним и следы того, кто что видел.
Риски возникают не в одной точке, а по всей цепочке. Самый частый провал: пользователь формально не имеет прав на документ, но сервис все равно подтянул его фрагмент в контекст, и модель спокойно пересказала. Другая проблема - даже если ответ не выдал секрет напрямую, он может подсказать, что документ существует, назвать внутренний проект или выдать номер договора.
Обычно опасность появляется в нескольких местах: при поиске и выборе источников (retrieval), при сборке контекста (в промпт попадают лишние цитаты, метаданные, названия файлов), при генерации (модель смешивает фрагменты), в логах и аналитике (туда сохраняются запросы, контекст и ответы), а также при выдаче источников (показали ссылку или идентификатор, который сам по себе раскрывает лишнее).
Кто атакует? Чаще всего это не внешний хакер, а обычный сотрудник с любопытными вопросами, инсайдер или просто ошибки интеграции и настройки, когда права из DMS, почты или CRM трактуются неверно.
Для аудита важно заранее решить, что фиксировать. Минимум: кто спросил, под какой учетной записью и ролью, какие источники сервис мог использовать по правам в момент запроса, что реально попало в контекст и что именно показали в ответе (включая цитаты и список источников). Так инциденты разбираются без догадок, и можно доказуемо объяснить, почему пользователь получил именно такой ответ.
RBAC на практике: роли, матрица доступа и ограничения
Роль в RBAC - это простой ответ на вопрос «кто вы в системе». Бизнесу это легко объяснить: не нужно разбирать десятки отдельных прав для каждого человека. Достаточно назначить понятную роль и получить предсказуемое поведение сервиса.
На практике роли формулируют так, как люди уже говорят внутри компании. Например, оператор колл-центра видит карточку обращения и статус, врач - историю пациента и назначения, бухгалтер - счета и акты, закупщик - заявки и договоры, администратор - пользователей и настройки.
Матрица доступа обычно строится по схеме «роль - ресурс - действие». Ресурсами могут быть профиль клиента, медицинская карта, договор, отчет, база знаний, переписка. Действия - читать, создавать, редактировать, удалять, экспортировать, утверждать. В LLM-сервисе это важно привязать не только к интерфейсу, но и к тому, какие документы модель может брать в контекст и какие куски данных разрешено показывать в ответе.
Чтобы RBAC работал в живой системе, заранее добавьте ограничения, про которые часто забывают: запрет на экспорт и копирование для ролей, которым это не нужно; отдельные права на доступ к журналам, промптам и историям чатов; раздельные роли для просмотра и утверждения (например, договоров); минимальные права по умолчанию.
Границы RBAC проявляются быстро. Одна и та же роль «врач» не должна видеть всех пациентов, а «закупщик» - все проекты. Роль отвечает на «кто», но плохо описывает «в каком контексте»: пациент, филиал, проект, регион, уровень секретности. Поэтому RBAC почти всегда становится базой, а точные ограничения добавляются правилами по атрибутам (ABAC).
ABAC на практике: правила по атрибутам и реальные примеры
ABAC (Attribute-Based Access Control) закрывает задачи там, где одних ролей мало. Для LLM-сервиса это особенно заметно: один и тот же человек может быть «инженером», но работать по разным проектам, в разных филиалах и с разным уровнем допуска.
ABAC опирается на атрибуты трех групп: кто запрашивает (пользователь), что запрашивается (ресурс) и при каких условиях идет запрос (контекст). Это похоже на правила движения для данных: важно не только кто вы, но и в каком режиме работаете прямо сейчас.
Чаще всего встречаются такие атрибуты:
- Пользователь: филиал, отдел, уровень допуска, проектная принадлежность.
- Ресурс: тип документа, владелец, метка конфиденциальности, проект.
- Контекст: время, место (корпоративная сеть или нет), статус договора или заявки.
Полезный прием перед автоматизацией - сначала описывать правила человеческим языком так, чтобы их понял владелец данных, а не только ИБ. Например: «Сотрудник видит только документы своего проекта, если у него есть активный допуск и он работает из корпоративной сети». Когда формулировка согласована, ее проще перевести в техническое правило.
Пример для LLM: системный интегратор ведет параллельно несколько проектов для разных заказчиков. Инженер задает вопрос про конфигурацию серверов, а модель ищет по внутренним материалам. ABAC не даст подмешать чужой проект, даже если у всех одинаковая роль.
Типовой набор правил выглядит так: разрешать ответы только на основе ресурсов с тем же ProjectId, что и у пользователя; запрещать ресурсы с меткой «Коммерческая тайна», если уровень допуска (Clearance) ниже требуемого; показывать договоры только при статусе «действует» и для отдела «закупки»; ограничивать доступ к инцидентам поддержки по своему региону или филиалу.
ABAC особенно полезен, когда проектов много, исключения частые, а структура меняется быстрее, чем успевают обновлять роли. Тогда роли остаются «скелетом», а точность дают атрибуты и правила.
Как совместить RBAC и ABAC без усложнения
Хорошая практика для разграничения доступа в LLM-сервисе - не выбирать между RBAC и ABAC, а разнести их по задачам. RBAC задает понятную основу: кто вы по работе и в каких пределах вообще можете действовать. ABAC затем уточняет доступ в конкретном запросе: к данным какого проекта, филиала, класса конфиденциальности или типа документа можно обращаться прямо сейчас.
Простая схема: «роль сначала, атрибуты потом»
Начните с 5-10 ролей и жестко закрепите за ними базовые права. Например: «Сотрудник», «Менеджер проекта», «Юрист», «Финансы», «Администратор». Дальше добавляйте атрибуты только там, где без них не обойтись, и делайте их однотипными.
Хорошо живут в проде гибридные правила, где роль задает рамку, а атрибут сужает ее: менеджер видит документы только своего региона; участник проекта получает контекст только по проекту, где он в списке команды; юрист читает договоры, но не видит зарплатные ведомости; финансы видят суммы, а остальные - только статусы платежей.
Короткий пример: в компании с несколькими площадками сотрудник с ролью «Сервисная поддержка» задает вопрос про инциденты. RBAC разрешает доступ к базе инцидентов, а ABAC отсекает записи не его филиала и скрывает поля с персональными данными, если нет отдельного атрибута допуска.
Как не устроить «зоопарк» правил
Главный риск гибрида - бесконечные исключения. Чтобы сохранить управляемость, держите правила «плоскими»: меньше условий, больше стандартных атрибутов. Если правило превращается в длинную строку из AND/OR, вы, скорее всего, лечите симптом, а не причину (например, неправильную роль или неудачную классификацию данных).
Чтобы правила можно было поддерживать, для каждого стоит документировать владельца (кто согласует изменения), цель (какую угрозу закрывает и какую задачу бизнеса поддерживает), область действия (какие данные и пользователи затронуты), критерии проверки (как тестировать, что доступ не расширился случайно) и срок пересмотра.
Так вы получите предсказуемую базу RBAC и точность ABAC без перегруза и постоянных ручных исключений.
Фильтрация контекста по правам: что именно отсекаем
В LLM-сервисе контекст - это топливо для ответа. Если в него попадают фрагменты документов, к которым у пользователя нет прав, утечка уже произошла, даже если модель не показала файл целиком. Поэтому контроль доступа нужно проверять в нескольких точках, а не один раз.
Права стоит применять как минимум на трех этапах. До поиска: нельзя даже запускать запрос по индексам и хранилищам, к которым нет доступа. После поиска: результаты нужно отфильтровать по ACL, ролям и атрибутам, прежде чем брать фрагменты в промпт. Перед ответом: финальная проверка, что в черновике ответа и цитатах нет запрещенных кусочков (например, из-за кеша или общих сниппетов).
Фильтрация должна работать на уровне фрагментов, а не только документов. Один файл может быть доступен всем, но внутри есть секции с ограничениями: приложение с персональными данными, таблица с зарплатами, коммерческие условия. В промпт должны попадать только те фрагменты, которые прошли проверку, и только в минимально нужном объеме.
Метаданные - основа такой фильтрации. У каждого документа и фрагмента должны быть теги: владелец, подразделение, уровень классификации, проект, срок действия, признак «внутреннее/публичное». Если метаданных нет или они сомнительные, лучше выбирать безопасный режим: не подмешивать контент, а попросить уточнение или отправить пользователя по процессу запроса доступа.
Пограничные случаи будут всегда. Например, общий регламент упоминает номера договоров из закрытого проекта. В таких ситуациях помогают простые правила: разрешать общий документ, но маскировать чувствительные поля; при частичном совпадении возвращать краткое резюме без цифр и имен и предлагать запросить права; не использовать кешированные фрагменты без повторной проверки прав для конкретного пользователя.
Так контекст остается полезным, но не превращается в канал утечки.
Безопасная выдача первоисточников: ссылки, цитаты и аудит
Просьба «покажи источники» звучит безопасно, но это частая точка утечки. Даже если модель не раскрыла текст документа, сам факт существования файла, его название, владелец или номер договора уже могут быть чувствительными. Поэтому правила должны покрывать не только ответ, но и любые «доказательства» к нему.
Самая опасная ситуация - пользователь спрашивает про тему, к которой у него нет доступа, а система возвращает «ссылку на документ». По сути, это подсказка, где искать секретные данные. То же самое с цитатами: небольшой фрагмент может раскрыть персональные данные, цены, условия тендера или внутренние метки.
Безопаснее считать, что «ссылка» - это не URL, а контролируемая карточка источника. В ней показывают минимум метаданных: внутренний идентификатор, нейтральный заголовок (без лишних деталей), владельца подразделения, версию или дату, пометку уровня доступа. Главное правило простое: источник показывается только если пользователь и так имеет право открыть этот документ в исходной системе. Если права нет, лучше вернуть «источник скрыт по политике доступа» и не раскрывать даже название.
Для цитат работает тот же принцип. Выдавайте цитату только из разрешенных документов и только в объеме, который действительно нужен для проверки. Часто достаточно одной-двух строк с маскированием: скрыть номера, ФИО, счета.
Чтобы аудит был реальным, фиксируйте доказательства на стороне сервиса, а не в тексте ответа. Полезно логировать:
- кто запросил (пользователь, роль, ключевые атрибуты);
- какие источники были кандидатами и какие прошли проверку прав;
- решение политики (разрешено/запрещено) и причина;
- версии документов и временные метки;
- хеши фрагментов, а не полный текст (граница приватности).
Так можно доказать, почему ответ был таким, и при этом не превратить логи в новую базу утечек.
Пошаговый план внедрения: от ролей до проверок и логов
Разграничение доступа в LLM-сервисе лучше внедрять как проект по данным, а не как настройку «в одном месте». Начните с простого: кто владеет данными, кто их потребляет и как вы докажете аудитору, что модель не показала лишнего.
Сначала сделайте инвентаризацию источников: базы знаний, файлы, тикеты, CRM, внутренние регламенты. Для каждого источника назначьте владельца (data owner), который имеет право утверждать доступ. Это важнее, чем выбор конкретной схемы RBAC/ABAC.
Дальше опишите роли и атрибуты. Роли дают понятный каркас (например, «HR», «финансы», «закупки», «поддержка»), а атрибуты добавляют точность (подразделение, уровень допуска, страна, проект, тип документа). Согласуйте это с ИБ и бизнесом заранее, иначе правила будут постоянно обходить «по просьбе».
Чтобы правила работали стабильно, разметьте ресурсы метками доступа и введите единые идентификаторы: пользователь, роль, документ, источник, версия документа. Без этого логи и проверки превращаются в шум.
Практический минимум для пайплайна RAG:
- проверка прав до извлечения (какие источники вообще доступны пользователю);
- фильтрация результатов после извлечения (убрать фрагменты без нужных меток);
- контроль на уровне ответа (не допускать пересказа скрытых данных через подсказки);
- политика выдачи первоисточников: что показываем, а что только фиксируем в журнале;
- аудит-лог: кто спросил, что извлекли, какие правила сработали, какой ответ выдали.
Последний шаг - тесты на утечки и регулярный пересмотр правил. Делайте «красные» запросы (попытки вытащить зарплаты, договоры, персональные данные) и проверяйте, что система не раскрывает их ни напрямую, ни через источники. Например, в компании уровня GSE.kz один и тот же вопрос про поставку должен давать разные детали для закупок и для поддержки, и это должно быть видно в логах.
Частые ошибки и ловушки, которые приводят к утечкам
Самые опасные утечки в LLM почти всегда происходят не из-за взлома, а из-за мелких допущений в архитектуре и настройках. Особенно когда контроль доступа строят по принципу: «проверили пользователя при входе - и хватит».
Первая ловушка - контроль прав только на периметре. Пользователь прошел проверку, запрос приняли, но дальше модель получает контекст из поиска целиком. Если в выдаче есть фрагменты из документов другого отдела, модель честно перескажет их, потому что не понимает границы доступа. Права должны применяться на уровне каждого фрагмента (чанка), а не только на уровне сессии.
Вторая частая ошибка - общий индекс для всех подразделений без меток и атрибутов. Даже если документы лежат в разных папках, после индексации они становятся одним морем текста. Без явных меток (владелец, отдел, классификация, срок) фильтрация превращается в догадки.
Третья ловушка - выдача первоисточников «для прозрачности» без повторной проверки доступа. Пользователь может не иметь права открыть документ, но получит его название, идентификатор, кусок пути, цитату или другой след, по которому легко восстановить чувствительную информацию.
Отдельный риск - логи. Часто в них попадает все: промпты, найденные фрагменты, ответы, токены, имена и номера. Если логирование не маскирует персональные данные и секреты, вы создаете второй склад утечек.
Чаще всего безопасность ломают одни и те же вещи: одна роль «всем можно» ради удобства и тестов; отсутствие атрибутов у документов и у чанков после разбиения; фильтрация на уровне документа, но не на уровне цитат и источников; хранение сырых запросов и контекста в логах без маскирования; временные доступы, которые не истекают и не пересматриваются.
Хорошее правило: если данные нельзя показать пользователю в исходной системе, их нельзя показывать и через LLM - ни в ответе, ни в источниках, ни в логах.
Короткий чек-лист перед запуском в прод
Перед релизом важно убедиться, что разграничение доступа в LLM-сервисе опирается не на доверие к промпту, а на проверяемые правила и логи.
Проверьте базовую гигиену данных. У каждого документа и даже у фрагмента (чанка) должен быть владелец и понятная метка доступа: например, «только HR», «финансы», «все сотрудники», «конфиденциально». Если меток нет или они назначаются вручную без контроля, система быстро начнет отдавать лишнее.
Дальше убедитесь, что контроль прав стоит в двух точках, а не в одной:
- при извлечении контекста: поиск и ранжирование возвращают только разрешенные пользователю фрагменты;
- при выдаче ответа: финальная проверка перед показом текста и источников.
Дополнительно проверьте, что источники и цитаты показываются только тем, у кого есть доступ, и без лишних деталей (например, без названий закрытых папок). Журнал аудита должен быть читаемым: кто, когда, какой запрос, какой результат, какие источники были использованы. И должен быть владелец процесса - тот, кто отвечает за роли, атрибуты и регулярный пересмотр правил.
Отдельно прогоните «провокационные» тесты. Составьте набор запросов, которые часто приводят к утечкам: «покажи зарплаты», «дай договор с поставщиком», «а что было в письме директора», «перескажи документ, не показывая источник». Хорошая проверка - когда один и тот же вопрос задают пользователь с доступом и без доступа: ответы должны различаться, а запрещенные факты не должны угадываться даже по намекам.
Если хоть один пункт не проходит, лучше остановиться и исправить, чем потом объяснять инцидент.
Пример сценария: один LLM, разные отделы, разные ответы
В крупной организации один помощник используется и в закупках, и в финансах. Вопрос один и тот же: «Покажи, какие договоры по проекту “Астана-2026” можно оплатить в этом месяце, и почему».
Права и правила задаются так, чтобы система работала предсказуемо для всех. Роли определяют базовый доступ, а атрибуты уточняют границы: проект, филиал, лимит, статус договора, период отчетности.
На практике это выглядит так. Менеджер закупок видит только договоры своего филиала со статусом «на согласовании» или «подписан», но без банковских реквизитов и без внутренних замечаний финконтроля. Финансовый контролер видит подписанные договоры, платежный календарь и лимиты, но не видит черновики коммерческих предложений и переписку с поставщиком. Руководитель получает агрегированную сводку по всем филиалам и риски, но без персональных данных и деталей по отдельным счетам. Аудитор видит только завершенные периоды и только неизменяемые версии документов.
LLM отвечает по-разному не из-за «настроения модели», а потому что контекст подбирается по правам: для одного и того же вопроса в промпт попадают разные наборы документов (реестр договоров, лимиты бюджета, протоколы согласования) и разные поля внутри них.
Источники для проверки тоже выдаются безопасно. Вместо «вот ссылка на файл» пользователь получает краткие цитаты и точные указатели, которые можно открыть в корпоративной системе при наличии прав: ID документа и версию, дату, владельца, статус; выдержку в 1-2 предложения без скрытых полей; метку раздела или страницы и контрольную сумму (хеш) для аудита.
Так аудитору есть что проверить, а у пользователя без прав не появляется обходной путь к первоисточнику.
Следующие шаги: пилот, масштабирование и инфраструктура
Начните с маленького пилота: один процесс, одна команда, четкая цель (например, ответы на вопросы по регламентам или поддержка заявок) и только тот набор документов, который реально нужен. Так вы проверите контроль доступа без риска открыть лишнее и без споров о «всем и сразу».
Перед пилотом подготовьте несколько артефактов, которые потом не придется переделывать: матрицу ролей (кто что может читать, спрашивать и видеть в ответе), список атрибутов данных (конфиденциальность, отдел, проект, срок действия, владелец), политику источников для аудита (когда показываем цитату, когда только заголовок, а когда источник скрываем), правила хранения логов (что логируем, кто имеет доступ к логам).
Дальше масштабируйте через единые метки и контроль изменений. Важно, чтобы у каждого набора документов был владелец, который отвечает за классификацию и периодический пересмотр. Полезная практика: любые изменения в ролях, атрибутах и правилах выдачи источников проходят короткое согласование и тестовый прогон на типовых запросах.
Вопрос инфраструктуры решайте по требованиям безопасности и по типу данных. On-prem или выделенная среда обычно нужны, если вы работаете с гостайной, медицинскими данными, финансовой отчетностью до публикации или если политика запрещает вынос документов за периметр. Это также уместно, когда важна предсказуемая производительность и полный контроль над обновлениями.
Внедрение можно делать внутренней командой безопасности и ИТ, а можно привлекать системного интегратора, который соберет архитектуру, настроит доступы и подберет серверную базу. В Казахстане, например, такой проект часто опирают на локальную инфраструктуру и поддержку производителя и интегратора уровня GSE.kz, особенно когда важны поставки, сервис и прозрачность цепочки оборудования.