Расчет стоимости лицензий SIEM: EPS, GB в сутки и хранение
Покажем расчет стоимости лицензий SIEM по EPS и GB в сутки, оценку хранения и запас на рост, чтобы не упереться в лимиты через 6 месяцев.
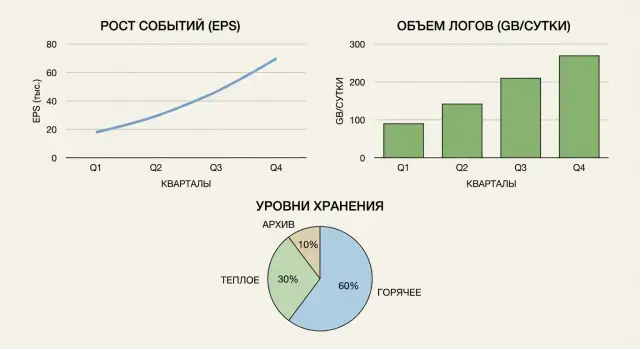
Зачем заранее считать EPS, GB в сутки и хранение
SIEM почти всегда растет быстрее, чем ожидают. Сегодня все работает потому, что подключены не все источники, включены не все правила корреляции, а часть журналов еще не отправляется. Через 3-6 месяцев появляются новые системы, аудит просит больше данных, команда ИБ включает более подробные события, и вы внезапно упираетесь в лимиты.
Поэтому расчет лицензии лучше начинать не с прайса, а с понимания, какие ограничения заложены в модели лицензирования и как они изменятся при росте инфраструктуры.
Чаще всего встречаются лимиты по:
- EPS (события в секунду), иногда отдельно средний и пиковый
- GB в сутки (объем принимаемых или индексируемых логов)
- объему и сроку хранения (онлайн и архив)
- числу источников (хостов, агентов, коннекторов)
- доступным функциям (корреляция, UEBA, SOAR, ретеншн по уровням)
Недооценка быстро приводит к неприятным последствиям: SIEM начинает отбрасывать события, задерживать обработку или отключать часть источников. В этот момент вы теряете видимость, а значит и шанс вовремя заметить инцидент. Часто приходится срочно докупать емкость по невыгодной цене или ставить внедрение на паузу, пока не согласуют бюджет.
Переоценка тоже болезненна. Вы переплачиваете за запас, который не используется, и замораживаете деньги, которые могли бы пойти на правила детектирования, интеграции и обучение.
Этот расчет важен сразу нескольким ролям. ИБ нужно не терять события и закрывать требования регуляторов. ИТ важно оценить нагрузку на сеть, хранилище и инфраструктуру. Финансам - заранее заложить рост и избежать внеплановых закупок. Владельцам систем - согласовать, какие логи реально нужны.
Простой ориентир: если вы планируете подключать новые источники или расширять аудит, считайте EPS, GB в сутки и хранение с учетом роста, а не только по текущей картине.
Термины: EPS, GB в сутки и уровни хранения простыми словами
Чтобы сравнивать предложения и не упереться в лимиты через несколько месяцев, сначала стоит договориться о терминах. У разных решений одно и то же может считаться по-разному.
EPS: что это и почему цифры «прыгают»
EPS (events per second) - это количество событий в секунду, которые SIEM принимает и обрабатывает. Событие при этом не всегда равно «одной строке лога». У одних решений событием считается любая полученная запись, у других - уже распарсенная запись, у третьих - только то, что прошло фильтры и попало в индекс.
На итоговый EPS сильно влияют детали:
- что считается событием: сырой лог, нормализованное или «обогащенное» событие
- как учитываются дубли, повторные отправки и ретраи
- есть ли агрегация (несколько похожих логов превращаются в одно событие)
- включена ли глубокая нормализация и корреляция «на входе»
GB в сутки: сырье против «готового продукта»
GB в сутки - это объем данных, которые вы генерируете и отправляете в SIEM за день. Но есть два разных объема: «сырые» логи (как пришли от источников) и данные после обработки (нормализация, поля, обогащение, индексация). Второй почти всегда больше. Если лицензия или хранение считаются по объему в день, заранее уточните, какой именно объем берется в расчет.
Уровни хранения: горячее, теплое, архив
Хранение обычно делят по скорости доступа и цене. Горячий слой нужен для быстрых поисков и расследований и обычно хранится недолго. Теплый слой дешевле, но поиск медленнее и срок хранения чаще больше. Архив - для требований и редких запросов: это самый дешевый уровень, но доступ к данным обычно менее удобный.
Сроки задают требования регуляторов и внутренние правила (например, 30 дней в «горячем» и 1 год в архиве).
Среднее и пики: что брать в расчет
Средние значения EPS и GB в сутки помогают планировать бюджет. Но лимиты чаще «съедают» пики: массовые обновления, сканирование уязвимостей, инциденты, всплеск аутентификаций. Если не учесть пики, SIEM начнет отбрасывать данные или ставить их в очередь в самый неподходящий момент.
Какие входные данные собрать перед расчетом
Чтобы расчет не оказался «в вакууме», начните со списка того, что реально будет отправлять события, и как это меняется со временем. Дальше эти данные переводятся в EPS, GB в сутки и требования к хранению.
-
Составьте полный перечень источников логов и их роль. Часто забывают «мелочи», которые потом внезапно съедают лимит: прокси, DNS, почтовые шлюзы, облачные журналы, логи бизнес-приложений. В базовый набор обычно входят AD/LDAP, VPN, EDR/антивирус, межсетевые экраны, серверы Windows/Linux, сетевое оборудование, базы данных и ключевые приложения.
-
Соберите фактический объем логов по замеру, а не «на глаз». Практичный минимум - выборка за 7-14 дней, отдельно будни и выходные. Если возможно, снимите для каждого источника два числа: средний EPS и объем в GB/сутки (по данным на диске или в текущей системе логирования). Так сразу видно, что, например, VPN почти молчит ночью, а EDR дает стабильный поток весь день.
-
Отдельно отметьте сезонность и пики. Они часто связаны не с атаками, а с обычной жизнью: патч-окна, плановые аудиты, закрытие месяца, миграции, обучение сотрудников. Полезно фиксировать «пиковые дни» как отдельную категорию, чтобы не размазывать их по среднему.
-
Зафиксируйте планы на 6-12 месяцев: новые филиалы, подключение дополнительных систем, переход в облако, внедрение EDR, расширение периметра. Это меняет нагрузку сильнее, чем кажется. Например, добавление сегмента на 500 рабочих мест может дать заметный рост событий от AD и EDR.
Как оценить EPS: базовый расчет и учет пиков
Для лицензии и для инфраструктуры обычно важны две цифры: средний EPS (как система живет каждый день) и пиковый EPS (как она переживает всплески).
Начните с базового расчета по источникам. Если источник не дает EPS напрямую, возьмите количество событий за период и разделите на число секунд. Например, 8 640 000 событий в сутки = 8 640 000 / 86 400 = 100 EPS.
Дальше зафиксируйте пики: массовые обновления, утренние входы пользователей, сканирования уязвимостей, инциденты, сбои сети. Важно учитывать не только высоту пика, но и длительность. Короткий всплеск можно пережить буферами, а длинный пик легко превращается в потери.
Практичная логика такая:
- соберите таблицу источников со средним и пиковым EPS
- сложите средние значения и получите baseline
- сложите пики и получите worst case для одновременных всплесков
- заложите запас: +20-30% на рост и отдельный запас под пики (часто 1,5-2x от baseline, либо ориентир на ваш worst case)
- уточните, как именно лицензируется прием: по среднему, по пику, ступенями, либо есть жесткий «кап» на секунду
Небольшой пример: в среднем 60 EPS (AD, EDR, firewall, серверы), но раз в день 10 минут идет 250 EPS из-за сканирования и лавины алертов. Тогда «емкость приема» должна держать 250 EPS плюс запас на рост, иначе вы упретесь в лицензионный лимит или начнете терять события.
Параллельно проверьте не только лицензию, но и узкие места инфраструктуры: очереди и буферы на коллекторе/агенте/брокере, скорость парсинга и нормализации, лимиты соединений от источников, запись на диск и переполнение очередей, отбрасывание событий при backpressure.
Если пик держится дольше, чем живут ваши буферы, это уже не «шум», а новая норма. Ее надо учитывать и в лицензии, и в мощности приема.
Как оценить GB в сутки: что считать и как не ошибиться
GB в сутки отвечает на вопрос, сколько данных вы будете загружать в SIEM каждый день. От этого зависит не только цена, но и то, как быстро вы упретесь в лимиты и начнете в спешке «резать» логи.
Опирайтесь на фактические замеры хотя бы за 7-14 дней. Если SIEM еще нет, снимайте данные с текущих систем: коллекторов, syslog-серверов, EDR-консолей, облачных журналов.
По каждому ключевому источнику полезно зафиксировать:
- объем в GB/сутки (сырой экспорт или текущая выгрузка)
- количество событий и средний размер события (если доступно)
- долю «шумных» типов логов (DNS, прокси, NetFlow, firewall allow)
- включенные уровни детализации (debug, audit, verbose)
- периоды, когда объем резко растет (обновления, сканы, отчеты)
Учтите, что объем «на входе» и «внутри SIEM» часто отличаются. После парсинга, нормализации и обогащения (поля, теги, гео, справочники, контекст) событие может стать тяжелее. Иногда наоборот: часть мусора отбрасывается. Поэтому имеет смысл заложить коэффициент, который вы проверите на пилоте, например +20-50% к объему, если планируете активное обогащение и хранение большого числа полей.
Отдельно разберите, где «шум», а где «смысл». Пример: прокси пишет все запросы, но для расследований часто важнее блокировки, редкие домены и аномалии по объему. В таких случаях помогает простой принцип: полную детализацию хранить недолго, а дальше переходить на агрегации.
Фильтровать или агрегировать можно без потери смысла, если заранее ответить:
- какие события реально участвуют в корреляциях
- что нужно для расследования (минимальный набор полей)
- какие логи нужны только для отчетности
- какие источники можно перевести на выборочную запись или семплинг
Так получается честный GB/сутки, а не цифра, которая хорошо выглядит в закупке и ломается через полгода.
Планирование хранения: сроки, уровни и простой расчет емкости
Хранение - место, где бюджет чаще всего расходится с реальностью. Здесь важно заранее понять, сколько дней какие данные должны лежать в быстром доступе, а что можно хранить дешевле.
Сначала разделите требования на два слоя: операционные нужды (расследования, поиск по свежим событиям, отчеты для SOC) и аудит/регуляторика (сроки хранения часто длиннее, но не всегда требуют мгновенного поиска).
Дальше разложите логи по уровням:
- горячее (hot): быстрый поиск и корреляции, обычно самый дорогой слой
- теплое (warm): поиск возможен, но медленнее; сюда часто уходит основная история
- архив (cold): для проверок и редких запросов, доступ обычно ограничен или через выгрузку
Базовая оценка емкости простая: суточный объем умножить на дни хранения и добавить запас.
Емкость = GB_сутки x Дни_хранения x Кзапаса
Кзапаса стоит закладывать отдельно для роста и непредвиденных источников. На практике часто берут 1.2-1.5, если нет точных прогнозов.
Но реальная потребность в дисках зависит не только от GB/сутки. Обычно забывают про три множителя:
- сжатие (коэффициент сильно зависит от типа логов)
- индексацию (для быстрого поиска нужен индекс, и он добавляет место, особенно в горячем слое)
- репликацию (если храните копии для отказоустойчивости, умножайте емкость на число копий)
Пример: 120 GB логов в сутки. Требования: hot 14 дней, warm 90 дней, архив 365 дней. Считаем по слоям: 120 x 14 = 1680 GB (hot), 120 x 90 = 10800 GB (warm), 120 x 365 = 43800 GB (архив). Суммарно 56300 GB, затем умножаем на запас (например, 1.3) и отдельно учитываем индексацию и репликацию там, где они включены.
Методика расчета шаг за шагом (без привязки к вендору)
Логика простая: сначала считаем фактическую нагрузку (EPS и GB/сутки), затем добавляем запас, и только после этого переводим числа в модель лицензирования конкретного вендора.
-
Соберите список источников логов и прогноз изменений. Отметьте, что появится в ближайшие 3-6 месяцев: новые филиалы, новые сенсоры, включение аудита на критичных системах.
-
Измерьте EPS и GB/сутки на реальных данных. Если SIEM еще нет, снимите метрики с коллекторов/агентов или текущей системы логирования. Отдельно выделите пики (обычный день, патч-окно, инцидент).
-
Добавьте коэффициенты запаса. Типовые ориентиры:
- рост объема: +20-50% (если проект расширяется, ближе к 50%)
- пики: 2-5x для отдельных источников (часто VPN, прокси, EDR)
- накладные расходы обработки: +10-30% на парсинг, нормализацию, служебные события
-
Переведите нагрузку в ограничения лицензии и проверьте лимиты: по EPS, по суточному объему, по числу источников, по доступным функциям и ограничениям на корреляции (если они есть). Сравнивайте отдельно «средний день» и «пиковый день».
-
Посчитайте хранение и инфраструктуру под прием, поиск и архив. Разделите хранение по уровням и проверьте, выдержит ли система одновременно прием пиков и запросы аналитиков.
Мини-пример, чтобы не ошибиться
Если сейчас 1 200 EPS в среднем, а в пики 3 000 EPS, и вы планируете подключить еще EDR и сетевые устройства, лицензирование только по среднему значению почти гарантированно упрется в потолок. Безопаснее заложить пиковую нагрузку плюс рост, а сроки хранения разделить на «для работы» и «для требований».
Типовые ошибки, из-за которых лимиты заканчиваются внезапно
Самая частая причина перерасхода - считать по «красивой» средней нагрузке. В реальности EPS скачет, и если купить лицензию «впритык», через несколько месяцев начинаются дропы событий, задержки корреляции или вынужденное отключение источников.
Вторая ловушка - путать объем входящих логов и объем хранения. GB/сутки - это то, что прилетает на вход. Хранение зависит от того, что происходит дальше: нормализация, обогащение, индексация, сжатие, дубликаты, служебные поля. Без коэффициентов легко ошибиться в 1,5-3 раза.
Еще один сценарий: проект «обрастает» источниками, но расчет не пересматривают. Сегодня это домен и сетевые устройства, завтра добавляются EDR на 500 рабочих мест, журналы облака, WAF, новый бизнес-сервис, аудит БД. На бумаге это «небольшие доработки», но по EPS и объему они могут оказаться больше исходного ядра.
Часто лимиты съедает шум. Если без политики оставляют все подряд (debug-логи приложений, частые allow-события на периметре, многословные прокси-логи), объем растет, а пользы мало. Нужны правила: что фильтруем на входе, что оставляем в агрегате, что вообще не храним.
Наконец, многие планируют хранение одним сроком, без разделения на горячий слой и архив. В итоге либо слишком дорого держать все «быстрым», либо приходится срочно уменьшать ретеншн и терять данные для расследований.
Для самопроверки:
- учтены пики (например, 95-й процентиль или x2 к среднему) и тесты на «шторма» событий
- есть коэффициенты: входной объем vs фактическое хранение (с учетом индексации и служебных данных)
- составлен список источников «плюс 6 месяцев» (EDR, облака, новые приложения) с оценкой прироста
- определены фильтры и базовая гигиена логов, а ретеншн привязан к ценности данных
- разделены горячее хранение и архив, чтобы не платить за скорость там, где она не нужна
Пример из практики: подключили EDR и включили подробный аудит на контроллерах домена «на время пилота». Пилот закончился, настройки остались. EPS и суточный объем выросли, лимит закончился не потому, что SIEM «плохой», а потому что никто не закрепил правила, что считать, что хранить и как часто пересматривать модель.
Пример сценария: расчет на 6 месяцев с учетом роста
Представим компанию на 800-1500 пользователей с несколькими филиалами. За полгода штат и нагрузка растут на 20%. Параллельно подключаются новые источники: EDR на рабочих станциях, прокси, почтовый шлюз и VPN.
На старте подключены AD, Windows-события с серверов, сетевые устройства и пара бизнес-приложений. По замеру за 7-14 дней получаем в среднем 900 EPS и 25 GB в сутки. Пики в рабочие часы доходят до 2500 EPS (например, утром при массовых логинах и обновлениях).
Через 6 месяцев добавились новые источники. EDR обычно резко увеличивает и EPS, и объем. Прокси дает много «болтовни», VPN добавляет всплески при инцидентах и массовых подключениях. До фильтрации и настройки правил это может выглядеть как 1600 EPS и 50 GB/сутки в среднем.
Дальше включаем нормализацию и гигиену логов: убираем явный шум, ограничиваем слишком подробные события там, где они не нужны, настраиваем дедупликацию. Если лицензия считается по сырым входящим данным, это не всегда снижает оплату, но часто снижает хранение и нагрузку на поиск. Для примера возьмем, что после настроек полезный поток для хранения в горячем контуре уменьшился на 20%: 40 GB/сутки, при этом входящий объем для лицензионных лимитов все равно планируем как 50 GB/сутки.
С учетом роста на 20% к концу периода плановая цифра становится около 60 GB/сутки и 1900 EPS (с теми же пиками).
По хранению: горячее 30 дней и архив 180-365 дней. Если считать по 60 GB/сутки, то горячее хранение: 60 x 30 = 1800 GB (1,8 TB) плюс накладные расходы индексов и метаданных, часто 30-50% (итого около 2,4-2,7 TB). Архив на 365 дней: 60 x 365 = 21,9 TB. Если архив сжимается в 2 раза, получится около 11 TB, но безопаснее считать с запасом.
Чтобы не покупать лицензии в пожарном режиме, обычно закладывают:
- запас по EPS на пики: минимум в 2-3 раза от среднего
- запас по GB/сутки: +25-40% на новые источники и «шум» на старте
- отдельный буфер на инциденты (DDoS, массовые срабатывания EDR)
- запас по хранению: +30% к расчетной емкости (индексы, ретеншн, рост)
- план расширения на квартал вперед, даже если закупка раз в год
Короткий чеклист перед закупкой и запуском
Перед тем как покупать лицензии и включать сбор логов, проверьте, что базовые числа и договоренности зафиксированы.
- есть полный список источников логов (AD, VPN, EDR, фаерволы, серверы, бизнес-системы), и у каждого указан владелец
- зафиксированы средние и пиковые EPS по ключевым источникам, указаны период замеров и условия (обычный день, патч-окно, инцидент)
- посчитаны GB/сутки не только «как есть» (сырой поток), но и после обработки (нормализация, обогащение, дубли, служебные поля); если SIEM хранит сырое и обработанное, это два разных объема
Чтобы не упереться в хранение, заранее согласуйте сроки и уровни. Иначе один департамент будет ждать год горячего поиска, а бюджет окажется рассчитан «на две недели».
- утверждены сроки хранения и разбивка по уровням (горячее для расследований, теплое для регулярных проверок, архив для комплаенса)
- заложен запас на рост и новые источники с понятными допущениями (например, +20% событий в квартал и подключение N новых систем)
В конце сверьте, что лицензия, хранение и «железо» не спорят друг с другом:
- модель лицензирования и реальные числа совместимы (лимит по EPS, по объему в сутки, по хранимым данным, если есть)
- производительность выдержит пики: прием событий, парсинг, корреляции и отчеты
Мини-сценарий для самопроверки: если завтра добавится один крупный источник (например, EDR на все рабочие места), вы заранее понимаете, на сколько вырастут EPS, GB/сутки и емкость хранения, и какой лимит станет критичным первым.
Следующие шаги: согласование, пилот и план масштабирования
Когда у вас есть цифры по EPS, GB/сутки и хранению, превратите их в понятные требования для закупки и ИТ. Фиксируйте не только «сколько нужно сейчас», но и «сколько будет через 6-12 месяцев».
Обычно хватает короткого документа на 1-2 страницы: какие источники подключаем, ожидаемая средняя нагрузка и пики, сроки хранения по уровням (например, «горячее» и «архив»), какой запас закладываем на рост. Отдельно стоит прописать, что считается выходом за лимит: потеря событий, задержки поиска, переполнение хранилища или резкий рост затрат.
Чтобы не упереться в потолок через полгода, заранее договоритесь о правилах масштабирования: когда увеличиваем лицензионный лимит по EPS/объему и когда добавляем ресурсы под хранение и обработку.
Пилот полезен, если источников много, данные «шумные» или вы не уверены в пиках. Рабочая схема простая: подключили критичные системы (AD, VPN, EDR, ключевые серверы), поработали 2-4 недели, сняли повторные замеры и обновили расчет перед финальной закупкой.
Если нужна поддержка, GSE.kz может помочь с обследованием и расчетом, внедрением SIEM как системный интегратор, а также с подбором серверов и инфраструктуры хранения. Для масштабирования по нагрузке часто закладывают расширяемые вычислительные узлы, например на базе стоечных серверов S200 Series, и поддержку 24/7, чтобы расширение проходило без простоев.
FAQ
Зачем вообще заранее считать EPS, GB в сутки и хранение для SIEM?
Потому что нагрузка почти всегда растет: добавляются источники, включаются более подробные события, расширяются правила корреляции и требования аудита. Если считать только по текущей картине, через 3–6 месяцев легко упереться в лимиты и начать терять события или получать задержки обработки.
Какие лимиты в лицензиях SIEM встречаются чаще всего?
Обычно это ограничения по EPS (часто отдельно средний и пиковый), по объему данных в сутки (принимаемых или индексируемых), по срокам и объему хранения (hot/warm/архив), по числу источников и по доступным функциям. Важно заранее понять, что именно ограничивает ваш тариф, чтобы не купить «не то» даже при похожей цене.
Что такое EPS и почему у разных SIEM он считается по-разному?
EPS — это сколько событий в секунду SIEM может принять и обработать, но у разных решений «событие» считается по-разному. Где-то это сырая строка лога, где-то распарсенное и нормализованное событие, а где-то только то, что попало в индекс после фильтрации, поэтому цифры при сравнении могут не совпадать.
Как правильно учитывать пики, чтобы не купить лицензию «впритык»?
Сначала зафиксируйте средний EPS для обычных дней, затем отдельно оцените пики в часы обновлений, утренних логинов, сканов уязвимостей и при инцидентах. Для закупки безопаснее ориентироваться на пик плюс запас на рост, иначе как раз в «шторм» событий вы рискуете получить дропы или очередь.
GB в сутки — это входящие логи или то, что хранится внутри SIEM?
GB/сутки — это объем данных, который вы отправляете в SIEM за день, но важна точка измерения. После парсинга, нормализации и обогащения данные часто становятся больше, поэтому уточните, лицензируется ли «входной сырой поток» или объем после обработки и индексации.
Какие данные нужно собрать перед расчетом нагрузки?
Опирайтесь на замеры, а не на оценки «на глаз»: возьмите хотя бы 7–14 дней, разделите будни и выходные и зафиксируйте отдельные пиковые дни. Если EPS напрямую не виден, посчитайте события за период и разделите на количество секунд, чтобы получить понятную базу.
Как выбрать сроки хранения и разделение на hot/warm/архив?
Сначала определите сроки, которые реально нужны для работы (быстрые расследования и поиск), и отдельно сроки для комплаенса и проверок. Затем разнесите данные по слоям хранения, потому что держать весь год в «горячем» слое почти всегда неоправданно дорого.
Как быстро прикинуть, сколько дисков нужно под ретеншн?
Базовая формула простая: суточный объем умножить на дни хранения и добавить коэффициент запаса. На практике итог меняют сжатие, индексация и репликация для отказоустойчивости, поэтому хранение нередко оказывается больше «чистой математики» в 1,5–3 раза.
Какие ошибки чаще всего приводят к внезапному перерасходу лимитов?
Чаще всего ошибаются, когда берут красивое среднее и забывают про пики, путают входной объем с объемом хранения и не пересматривают расчет при добавлении источников. Еще одна типовая проблема — собирать «все подряд» без гигиены логов, из-за чего лимиты съедает шум вместо полезных событий.
Как безопаснее пройти путь от оценки до внедрения и масштабирования SIEM?
Начните с короткого пилота на критичных источниках на 2–4 недели, чтобы уточнить реальные пики и рост объема после обработки. Дальше фиксируйте правила масштабирования и подбирайте инфраструктуру с запасом по CPU, памяти и дискам; если нужна помощь, GSE.kz может взять обследование и расчет, внедрение как системный интегратор и подобрать серверы и хранилище, например на базе стоечных серверов S200 Series, чтобы расширяться без простоев.