RAG для внутреннего документооборота: архитектура пайплайна
Разбираем, как построить RAG для внутреннего документооборота: источники, извлечение текста, индекс, ответы с цитатами и контроль прав доступа.
Какая проблема у внутреннего документооборота на самом деле
Проблема обычно не в том, что документов мало. Проблема в том, что их слишком много: они разбросаны по разным системам, а у каждого есть нюансы - версия, дата, подразделение, исключения, ссылки на другие регламенты. В итоге сотрудник тратит время не на работу, а на поиск и сверку.
Чаще всего люди спрашивают не «где документ», а «как правильно сделать прямо сейчас». Например: как оформить отпуск без содержания, какие поля заполнять в заявке на закупку, какие сроки по закрывающим документам, что делать при утере пропуска. Ответы ищут как получится: в почте, в чатах, в общей папке, у коллеги, который «точно помнит».
Обычный поиск по ключевым словам часто подводит. Он находит 20 файлов с похожими названиями, но не дает точный ответ и не объясняет контекст. В регламенте важны формулировки, условия и исключения. Если вытащить одну фразу без соседних абзацев, смысл легко исказить.
Отдельная боль в RAG для внутреннего документооборота - риск, что «бот увидел лишнее». На практике это выглядит так: сотрудник HR получает подсказку из финансового отчета, бухгалтерия случайно видит персональные данные, или новый сотрудник узнает внутренние тарифы из документа, к которому у него не должно быть доступа.
Обычно приходится балансировать четыре требования: точность (ответ на актуальной версии), скорость (без долгого ожидания), безопасность (доступ как в исходных системах, без обходных путей) и аудит (чтобы было понятно, откуда взялась цитата и кто что спрашивал).
Если это не заложить сразу, чат-бот будет либо «умничать» без доказательств, либо станет источником утечек.
Источники документов: что подключаем и на каких условиях
Качество ответов начинается не с модели, а с того, какие источники вы вообще разрешили читать. Лучше подключить меньше, но понятных и управляемых, чем собрать «все подряд» и получить утечки, споры об актуальности и путаницу версий.
Чаще всего полезны такие источники: общие файловые хранилища (сетевые папки), корпоративная почта с выделенными ящиками (например, «regulations@»), базы знаний и порталы (вики, FAQ), сканы и архивы бумажных документов, системы согласования и документооборота, где хранится финальная версия с датой утверждения.
Сразу назначьте владельца на каждый источник. Это не «технический контакт», а человек или роль, которые отвечают за смысл: что считается официальной версией, кто подтверждает актуальность и что делать при конфликте документов. Например, в компании уровня GSE.kz у HR владелец регламентов по отпускам и командировкам, у бухгалтерии - политики по первичке и закрытию месяца, у ИТ - инструкции по доступам.
Форматы почти всегда смешанные: PDF и DOCX, презентации, изображения (сканы), иногда таблицы (XLSX) и выгрузки из систем. Это лучше зафиксировать заранее: сканы потребуют OCR, а таблицы - отдельной логики извлечения, иначе модель начнет «догадываться».
Условия использования удобно закрепить простыми правилами. В индекс должны попадать только утвержденные документы (не черновики). Персональные данные и коммерческая тайна - только при явном разрешении и с ограничением доступа. Для каждого документа храните статус (действует/утратил силу) и дату утверждения. Исключите «личные папки» сотрудников и неформальные переписки. И для любого источника нужен понятный процесс удаления по запросу.
Наконец, договоритесь о политике обновления: как часто забирать изменения, что считать «удалением» (файл исчез или помечен как недействующий), и кто подтверждает, что старая версия больше не должна участвовать в ответах. Без этого бот будет уверенно цитировать то, что уже отменили.
Извлечение текста: PDF, офисные файлы, сканы и таблицы
Качество RAG часто упирается не в модель, а в то, что именно вы вытащили из файлов. Если на вход попал «кривой» текст, дальше будут неверные цитаты, пропущенные пункты и уверенные ответы не про то.
С «обычными» офисными файлами (DOCX, PPTX, TXT) важно не просто извлечь слова, а сохранить структуру: заголовки, списки, нумерацию, подпункты. Иначе регламент «3.2.1» превратится в набор строк, где теряется, к чему относится исключение или срок.
Сканы, PDF и OCR
PDF бывает двух типов: с текстовым слоем и «картинка в контейнере». Во втором случае нужен OCR. Проверяйте качество не по общим словам, а по тому, что чаще всего ломается: номера приказов, ИИН/БИН, суммы, даты, ссылки на пункты.
Короткий чек на качество распознавания:
- доля «мусорных» символов и пустых страниц
- совпадение ключевых полей (дата, номер, подпись)
- стабильность на казахском и русском в одном документе
- корректность переносов и разрывов строк
Таблицы: не потерять единицы и контекст
Для таблиц важно сохранять не только значения ячеек, но и заголовки колонок, единицы измерения и примечания. Иначе «10» без «дней» или «%» становится ловушкой. Практичный вариант - превращать таблицу в текстовые строки с явными полями.
В конце добавьте нормализацию форматов (даты, номера документов, кодировки, язык) и ведите логи парсинга. Если документ дал ноль символов или подозрительно мало текста, это должно быть видно сразу, а не после жалобы пользователя.
Разбиение на фрагменты и метаданные для надежных цитат
Документ редко стоит класть в индекс целиком. Модели нужен короткий, точный контекст, а пользователю - ясная цитата, которую можно проверить.
Размер фрагмента важен: слишком маленький кусок теряет смысл, слишком большой начинает «тащить» лишнее и ухудшает поиск. Часто хорошо работают фрагменты на 1-3 абзаца, но главное - чтобы они были цельными по смыслу.
Лучше делить текст по естественным границам: заголовки, пункты, подпункты, приложения. Если документ структурирован (например, 3.1, 3.2, 3.3), сохраняйте эту структуру и не смешивайте разные пункты в одном фрагменте. Для таблиц держите рядом подпись и строку с ключевыми колонками, иначе цитата будет непонятной.
Чтобы ответы с цитатами были надежными, каждому фрагменту нужны метаданные. Минимальный набор:
- источник и идентификатор файла (source_id), а также путь/хранилище внутри компании
- место в документе: номер страницы, заголовок раздела, номер пункта
- реквизиты: дата, версия, статус (проект/действует/утратил силу)
- владелец и подразделение
- тип документа (регламент, приказ, договор, инструкция)
Связка фрагмента с исходником должна позволять аудит: по цитате вы находите конкретный файл и точное место (страница и пункт), а не «примерно где-то в документе». Тогда пользователь быстро открывает оригинал и убеждается, что ответ не вырван из контекста.
С версиями и дублями договоритесь заранее. Если HR-инструкция обновилась с 1.2 на 1.3, старые фрагменты лучше помечать как «неактуальные» или убирать из выдачи, иначе бот начнет цитировать устаревшие правила. Для дублей (один и тот же регламент в двух папках) помогает хеш содержимого и правило: в индекс идет один «канонический» источник, остальные - как указатели в метаданных.
Индекс и поиск: как устроить хранение и обновление
Почти всегда нужны две части: индекс для быстрого поиска и отдельное хранилище исходников. В индексе лежат фрагменты и метаданные, а в хранилище - оригинальные файлы (PDF, DOCX, сканы), чтобы можно было открыть первоисточник и проверить цитату.
Поиск редко делают одним способом. Векторный поиск хорошо ловит смысл (например, «как оформить командировку»), но может пропустить точные формулировки. Ключевые слова и фильтры лучше находят конкретику (номер приказа, код формы, точный термин). Поэтому часто выигрывает гибрид: сначала фильтруем по метаданным, затем ранжируем по смыслу и уточняем по ключевым словам.
Заранее решите, по каким полям отсеивать нерелевантное:
- подразделение или роль (HR, бухгалтерия, закупки)
- проект или филиал
- гриф/класс документа (публичный, служебный, конфиденциальный)
- срок действия и версия
- автор или владелец регламента
Качество поиска проще всего проверять набором контрольных запросов. Например: «срок хранения личных дел», «кто согласует платеж на 5 млн», «что делать при утечке данных». Хороший результат - когда в топе 1-3 правильных фрагмента из актуальных документов, без старых версий.
Обновление индекса планируйте заранее: по расписанию (например, ночью), по событию (файл добавили или поменяли) и вручную для критичных регламентов перед публикацией.
Важно хранить связь «фрагмент -> документ -> версия». Тогда при замене файла вы переиндексируете только затронутые части, а ответы не будут ссылаться на старые правила.
Извлечение контекста: что именно попадет в ответ модели
Качество ответа почти всегда зависит не от «умности» модели, а от того, какие фрагменты вы ей дали. Поэтому важно заранее решить, как из вопроса пользователя получается поисковый запрос к индексу.
Обычно вопрос сначала нормализуют: убирают лишние слова, выделяют ключевые сущности (название документа, подразделение, дата, продукт). Например, «Какие сроки реакции по заявкам 24/7 поддержки?» лучше превратить в запрос с акцентом на «SLA», «реакция», «24/7», плюс фильтр по типу документа «регламент/соглашение». Если в компании есть разные контуры (HR, бухгалтерия, ИТ), полезно добавлять роль пользователя и его отдел.
Дальше выбирают, сколько фрагментов забирать. Много фрагментов часто ухудшают ответ: модель тонет в деталях и смешивает разные правила. Практика простая: брать несколько лучших совпадений и добавлять 1-2 «страховочных» фрагмента только если они из того же документа или того же раздела.
Когда источников несколько (политики, приказы, инструкции, база знаний), задайте понятные приоритеты. Обычно важнее свежесть (новый документ важнее старого), доверие (утвержденное важнее черновика), контекст (документ отдела пользователя важнее «общего»), тип источника (политика важнее письма, письмо важнее переписки).
Если документы противоречат, не пытайтесь «выбрать правду» молча. Лучше отметить конфликт и показать оба источника, а критерий выбора оставить понятным: дата утверждения, статус, владелец.
И обязательно логируйте: исходный вопрос, сформированный запрос, примененные фильтры доступа, список найденных фрагментов (с оценками релевантности) и финальный набор контекста. Это ускоряет разбор ошибок и помогает доказать, почему бот ответил именно так.
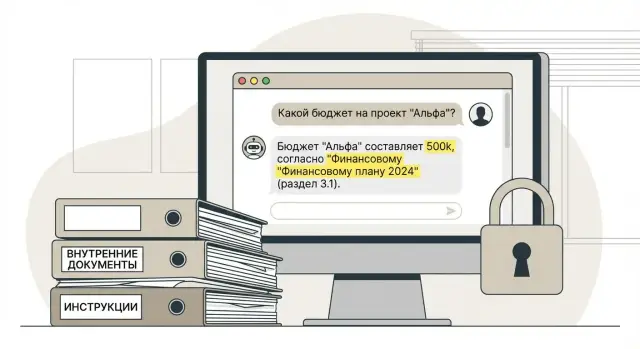
Ответы с цитатами: чтобы было понятно, откуда взята информация
Доверие держится на одном правиле: модель отвечает только на основе найденных фрагментов. Если в контексте нет подтверждения, бот не должен додумывать даже «очевидные» вещи. Это проще объяснить пользователям и легче защищать перед безопасностью и юристами.
Цитата должна быть проверяемой, а не декоративной. Хороший минимум:
- документ (название, номер)
- раздел или пункт (если есть)
- дата версии или утверждения
- страница и/или диапазон строк фрагмента
Тогда пользователь открывает регламент и видит то же самое. Например: «Командировка согласуется за 3 рабочих дня» и рядом: «Положение о командировках, приказ No 12, п. 3.2, версия от 2024-09-01, стр. 4».
Если данных не хватает, лучше прямо сказать: «в предоставленных документах нет информации» и попросить уточнить детали - период, подразделение, тип договора. Это снижает риск ошибок и быстро показывает, чего не хватает в базе.
Формат ответа стоит адаптировать по ролям. Сотруднику хватит 2-3 предложений и одной цитаты. Юристу или комплаенсу - более полный ответ с несколькими цитатами и оговорками (например, «есть исключение для...»), но все равно только из фрагментов.
Качество удобнее мерить не «общей удовлетворенностью», а конкретикой: точность цитат (совпадает ли смысл и место), доля корректных отказов, количество жалоб «цитата не про это», сколько раз пользователи просят уточнить один и тот же вопрос.
Контроль прав: как сделать, чтобы бот не видел лишнего
Главная ошибка - думать, что утечка происходит только когда бот «показывает секретное». Утечка начинается раньше: когда модель получает в контекст фрагменты, которые пользователь не должен был видеть, или когда по ответу можно догадаться о самом факте существования документа.
Начните с простой модели угроз: какие типы данных у вас есть (персональные данные, финансы, закупки, служебные расследования), кто имеет право их читать, и что считается нарушением (цитата, пересказ, намек на содержание, перечисление названий файлов).
Права нужно применять в двух местах, иначе будут обходы:
- до поиска: фильтровать кандидатов по правам (по документам и по фрагментам) до передачи текста модели
- после поиска: перепроверять выдачу, чтобы случайный фрагмент не прошел из-за ошибки метаданных или индекса
- на уровне ответа: не показывать названия документов и цитаты, если у пользователя нет прав на источник
Роли, группы и ACL лучше связывать не только с документом целиком, но и с отдельными фрагментами. Например, общий регламент доступен всем, а приложение с зарплатными вилками - только HR и финансам. Для этого у каждого фрагмента должны быть метки доступа (роль, подразделение, проект, гриф) и идентификатор исходного документа.
Полагаться на промпт «не показывай секретное» нельзя. Модель не проверяет права, она просто продолжает текст. Контроль должен быть в коде и в хранилище.
Нужен аудит. Минимум стоит логировать: кто и когда задавал вопрос, какие фильтры прав применились, какие документы и фрагменты реально попали в контекст, какой ответ был выдан и были ли скрыты цитаты. Так проще расследовать инциденты и улучшать правила доступа без остановки системы.
Пример сценария: бот по регламентам для HR и бухгалтерии
Сотрудник пишет в чат: «Можно ли купить билет на командировку с пересадкой и как оформить аванс?» Проблема в том, что правила менялись: в прошлом году были одни лимиты, в этом году добавили исключения для отдельных проектов.
RAG решает это не «памятью» модели, а тем, что перед ответом находит нужные фрагменты в актуальных документах. При поиске система учитывает метаданные: тип документа (политика, приказ, приложение), дату вступления в силу, подразделение, проект, филиал.
Обычно пайплайн выглядит так. В запросе распознаются темы: командировка, аванс, покупка билетов. Поиск отбирает последние версии регламентов и официальные приложения, а устаревшие редакции исключает. В ответ подтягиваются 2-4 коротких фрагмента, и каждый выводится с цитатой: название документа, раздел, пункт.
Цитаты сильно упрощают согласование. HR или юристы не спорят с формулировкой бота, они проверяют конкретный пункт и говорят: «Да, это наш текущий регламент» или «нужно уточнить формулировку в приложении».
Видимость ограничивается до поиска. Например, сотрудник филиала видит только документы своего филиала, а бухгалтерия - финансовые политики. Персональные данные (ФИО, ИИН, зарплаты) исключаются по ролям или маскируются.
Если вопрос затрагивает несколько политик (например, командировка плюс закупки), бот отвечает частями: отдельно правила по билетам, отдельно по авансу. В каждой части - свои цитаты и оговорки, где нужна проверка согласующей стороны.
Пошагово: как собрать RAG-пайплайн для компании
Чтобы RAG для внутреннего документооборота не превратился в бесконечный проект, начните с маленького пилота и заранее договоритесь, как вы будете мерить пользу: скорость ответа, долю верных цитат, число обращений в поддержку.
Соберите первый рабочий контур так, чтобы его можно было расширять без переделок:
- выберите 1-2 источника и 20-30 типовых вопросов (например, регламенты отпусков и командировок)
- настройте извлечение текста и контроль качества: доля распознанных страниц, пропуски в таблицах, ошибки OCR в сканах
- определите метаданные и правила фрагментации: название документа, версия, владелец, дата, раздел, уровень доступа, отметка страницы для цитаты
- постройте индекс и прогоните тесты на реальных вопросах сотрудников, сравнивая ответы с первоисточником
- подключите контроль прав и аудит: кто спрашивал, что было найдено, какие фрагменты попали в контекст и почему
Дальше расширяйте источники по одному, чтобы не потерять управляемость. На практике чаще всего ломается не модель, а качество входных данных: дубли, старые версии, разные шаблоны файлов.
Перед запуском договоритесь о процессе обновлений. Нужны владельцы документов, понятный цикл публикации (черновик, утверждено, архив) и правила переиндексации.
Если внедряете это как часть системной интеграции, удобно сразу заложить инфраструктуру под рост: отдельные среды для пилота и продакшена, журналирование и регулярные проверки качества на одном и том же наборе вопросов.
Частые ошибки и ловушки при внедрении RAG
Самая частая причина разочарования - не качество модели, а ошибки в данных и правилах доступа. Снаружи все выглядит как «бот ошибся», а внутри это обычно сбой в пайплайне: старый индекс, плохой текст после OCR или неверно собранный контекст.
Неприятная ловушка - индекс обновляется по расписанию, а документы меняются чаще или «тихо» заменяются в источнике. В результате в ответах всплывает устаревшая версия регламента или приказа, и пользователь теряет доверие. Лечится простым правилом: у каждого фрагмента должны быть дата версии, источник и контрольная сумма, а переиндексация должна быть привязана к факту изменения.
Вторая боль - OCR. Если сканы распознаны с мусором, модель будет уверенно цитировать ошибки, потому что «так написано в тексте». Это особенно заметно на печатях, подписях и таблицах. Минимум, который стоит сделать: фильтровать явный шум, хранить уверенность распознавания и не давать в ответы куски с низким качеством без перепроверки.
Ошибки часто начинаются с разбиения на фрагменты. Слишком крупные фрагменты дают расплывчатые ответы и цитаты «не про то». Слишком мелкие рвут смысл, и поиск начинает промахиваться. Ориентир простой: фрагмент должен содержать один завершенный пункт политики или один шаг процедуры, чтобы его можно было честно процитировать.
Самая опасная ловушка - права доступа проверяются не там. Если фильтровать права только на этапе показа ответа, утечка уже случилась: запрещенный контекст мог попасть в промпт. Проверка должна срабатывать до извлечения фрагментов и повторно перед генерацией.
Без логов и воспроизводимости вы не разберете инцидент. Должны сохраняться: какие документы искали, какие фрагменты выбрали, почему, с какими правами и какой версией индекса. Тогда, если сотрудник пожалуется на «странную цитату», вы быстро восстановите цепочку и исправите причину.
Короткий чеклист перед запуском и следующие шаги
Перед запуском важно проверить не «красоту ответов», а управляемость пайплайна: от источника до цитаты, от прав до аудита. Если это не закрепить заранее, бот будет отвечать уверенно, но спорно, и разбор займет больше времени, чем экономия.
Проверьте себя по короткому чеклисту:
- зафиксированы источники, владельцы и правила обновления: кто отвечает за регламенты, кто за приказы, как часто подтягивать изменения, что считать «истиной» при дублях
- настроен контроль качества извлечения текста: для PDF и офисных файлов есть стабильный парсер, для сканов включен OCR, а ошибки (пустые страницы, «каша» из символов) попадают в отчет
- метаданные готовы для фильтрации: подразделение, тип документа, дата версии, уровень доступа, срок действия; по ним же отсекаете устаревшее
- ответы всегда идут с цитатами: модель показывает конкретные фрагменты (номер документа, раздел, страницы) и не дописывает то, чего нет в найденном контексте
- включены аудит и разбор спорных случаев: сохраняются запрос, найденные фрагменты, итоговый ответ и причина отказа; есть понятный процесс «оспорить» и роль владельца документа
Следующие шаги обычно упираются в инфраструктуру и поддержку. Оцените, где будет работать решение (в вашем контуре или в отдельной зоне), какие нужны мощности для индекса и OCR, и как обновлять индекс без простоев.
Если планируете развертывание on-prem, заранее продумайте серверную базу, резервирование и интеграцию с вашими системами доступа. В этом могут помочь поставки серверов и системная интеграция от GSE.kz, если важно держать данные внутри организации и обеспечить поддержку 24/7.
FAQ
С чего лучше начать RAG для внутреннего документооборота, чтобы не утонуть в проекте?
Начните с малого пилота: 1–2 понятных источника, 20–30 типовых вопросов и жесткое правило «отвечаем только с цитатой из найденного фрагмента». Это быстрее дает пользу и сразу показывает, где ломается пайплайн: в тексте, версиях или доступах.
Какие источники документов подключать в первую очередь?
Подключайте только управляемые источники, где ясно, что считается финальной версией, и кто отвечает за актуальность. Если собрать «всё подряд», вы почти гарантированно получите дубли, спорные версии и повышенный риск утечек.
Зачем назначать владельца источника и кто это должен быть?
Владелец источника — это не ИТ-админ, а тот, кто отвечает за смысл и «официальность» документа: какая версия действующая, что делать при конфликте и когда документ считать устаревшим. Без владельца бот будет уверенно цитировать то, что уже отменили, и спорить будет не с кем.
Почему обычного поиска по ключевым словам часто недостаточно?
Обычный поиск дает набор похожих файлов, но не отвечает на вопрос «как правильно сделать сейчас» и плохо учитывает исключения. RAG полезен тем, что вытаскивает конкретный релевантный фрагмент и показывает его в виде проверяемой цитаты, а не пересказа «по памяти».
Что важно при извлечении текста из DOCX/PDF, чтобы ответы были точными?
Критично сохранять структуру: заголовки, номера пунктов, подпункты и связь исключений с основным правилом. Если извлечь просто «плоский» текст, вы потеряете контекст, и цитаты начнут выглядеть правильными, но относиться не к тому пункту.
Как понять, что OCR для сканов работает достаточно хорошо?
Скан в PDF часто не содержит текстового слоя, поэтому нужен OCR, а затем проверка качества на «ломающихся» местах: номера приказов, даты, суммы, ссылки на пункты. Если OCR дал мусор, модель будет уверенно цитировать ошибки, потому что для нее это «истина входных данных».
Как правильно разбивать документы на фрагменты для индекса?
Разбивайте по естественным границам: раздел, пункт, подпункт, приложение, и держите фрагмент цельным по смыслу. Практичный ориентир — один законченный пункт политики или один шаг процедуры, чтобы его можно было честно процитировать и быстро проверить в оригинале.
Какие метаданные обязательно хранить, чтобы цитаты были проверяемыми?
Минимально нужны источник и идентификатор, место в документе (страница, пункт), дата и статус версии, владелец и уровень доступа. Тогда вы можете и показать проверяемую цитату, и отфильтровать устаревшее, и провести аудит, кто что спрашивал и на основании чего бот ответил.
Как сделать, чтобы бот не «видел» документы, к которым у пользователя нет доступа?
Права надо применять до поиска и повторно перед генерацией ответа, чтобы запрещенные фрагменты никогда не попадали в контекст модели. Полагаться на просьбы в промпте вроде «не показывай секретное» нельзя: безопасность должна быть в коде, в ACL и в логике фильтрации.
Что делать, если документы противоречат друг другу или есть несколько версий?
По умолчанию выбирайте более свежий и утвержденный документ, но не пытайтесь «склеить» противоречия незаметно. Правильнее показать, что есть конфликт, и указать, какой критерий использован: дата утверждения, статус версии и владелец регламента, чтобы ответ можно было быстро согласовать внутри компании.