Отказоустойчивый кластер виртуализации: сеть, quorum, зависимости
Отказоустойчивый кластер виртуализации: практичная схема сети, quorum и доменных зависимостей, чтобы убрать скрытые точки отказа и правильно тестировать падение узлов.
Какие отказы вы реально хотите пережить
Прежде чем рисовать схему, договоритесь о простом: какие именно поломки должны пройти «без остановки сервиса», а какие вы готовы пережить как плановый простой. Фраза «HA включен» сама по себе ничего не гарантирует. Часто кластер действительно перезапускает виртуальные машины, но бизнес все равно стоит из-за сети, DNS или доступа к данным.
Для отказоустойчивого кластера виртуализации стоит заранее перечислить целевые отказы и границы ответственности:
- отказ одного хоста (узла) виртуализации
- отказ одного коммутатора или одного сетевого линка
- сбой хранилища или потеря одного пути к нему
- разрыв связи между площадками (если их две)
- отказ критичного сервиса инфраструктуры (DNS, AD, NTP)
Дальше нужны метрики, чтобы обсуждать не «ощущения», а цифры. RTO - за сколько минут сервис должен вернуться в норму. RPO - сколько данных допустимо потерять. Полезно зафиксировать и «окно деградации»: например, первые 10 минут после аварии пользователи терпят более медленную работу, но доступность сохраняется.
Самые неприятные простои приходят из скрытых точек отказа. Классика: один коммутатор «для кластера», один DNS-сервер, единственная учетная запись доменного админа, один сервер лицензирования или мониторинга, без которого автоматизация не срабатывает. Формально кластер жив, но сервис не поднимается.
Успех теста падения узла - это не просто «ВМ стартовала на другом хосте». Критерии лучше определить заранее:
- пользователи и приложения действительно могут войти и работать
- данные целы, нет рассинхронизации и «потерянных» транзакций
- восстановление укладывается в согласованный RTO/RPO
- понятно, что произошло, и что делать дальше (логи, оповещения, инструкции)
- после аварии система возвращается в предсказуемое состояние без ручных «костылей»
Пример: бухгалтерия сидит в одной ВМ, а домен и DNS - в другой. При падении хоста кластер быстро перезапустит обе, но если DNS поднимется позже, люди увидят «все сломалось», хотя виртуалки уже работают. Такие зависимости нужно выявлять до внедрения.
Базовая архитектура HA без лишней сложности
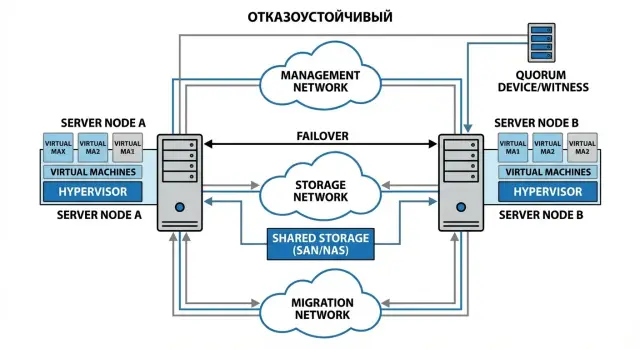
Отказоустойчивый кластер виртуализации проще всего собрать, если начать с минимальной схемы и проверить, что отказ любого одного элемента не «роняет» все сразу. Практический смысл HA - пережить поломку узла, порта, линка или коммутатора без общей остановки.
Минимальная рабочая конфигурация для малого ЦОДа или офиса - 2-3 узла и несколько логически разделенных сетей. Даже если физически портов немного, важно не смешивать все в один «общий» трафик.
Обычно хватает такого набора:
- сеть управления кластером (вход в гипервизор, служебный трафик)
- сеть виртуальных машин (пользовательские сервисы)
- сеть доступа к хранилищу (если хранилище отдельно)
- сеть миграции (перемещение VM между узлами)
Дальше вопрос: разделять по VLAN или по «железу». VLAN часто достаточно, если у вас две независимые физические линии и два коммутатора, а риски перегрузки невысоки. Отдельная пара портов под хранилище или миграцию нужна, когда трафик тяжелый (базы, резервное копирование, VDI) или когда важно, чтобы ошибка в сети VM не повлияла на доступ к хранилищу.
Скрытые SPOF чаще всего появляются там, где «вроде бы все дублировали», но забыли одну точку:
- один аплинк на всю стойку или один коммутатор
- один LACP-агрегат без независимых коммутаторов по сторонам
- один gateway для сети VM (без резервирования)
- один контроллер домена или один DNS, от которого зависят входы и сервисы
По модели размещения есть два понятных пути. Hyperconverged (хранилище внутри узлов) проще по кабелям и администрированию, но требует аккуратного расчета ресурсов и сети. Отдельное хранилище дает ясное разделение ролей, но добавляет еще один критичный компонент и отдельные пути доступа.
Держите в голове простое правило: любой одиночный сбой должен приводить к деградации, но не к полной остановке.
Сеть кластера: разделение трафика и отказоустойчивость
Сеть часто становится «скрытой» точкой отказа в HA: вроде бы два кабеля есть, а из-за одного неверного переключателя падает весь отказоустойчивый кластер виртуализации. Начинайте не со скорости, а с разделения ролей и понятного плана резервирования.
Обычно нужны несколько логических сетей (часто как VLAN), и у каждой своя задача. Management - для управления хостами и кластером, production - для трафика виртуальных машин, storage - для доступа к хранилищу (iSCSI, NFS, FC over IP), replication - для репликации между узлами или площадками, live migration - для миграции ВМ. Если все смешать в одну плоскую сеть, «обычная» нагрузка ВМ будет мешать миграции или доступу к дискам. HA начнет выглядеть как проблема гипервизора, хотя виноват сетевой шум.
Резервирование должно быть реальным: два коммутатора, два аплинка с каждого хоста, по возможности разные трассы кабеля и питание. В небольшом офисе это может быть пара ToR-коммутаторов и по два сетевых порта на каждом сервере, а для критичных систем - отдельные пары для production и storage.
Частый провал - агрегирование каналов. LACP, MLAG и «похожие на MLAG» схемы легко настроить так, что при сбое или ошибке на стороне коммутатора оба линка одновременно уходят в блокировку, и хост теряет сеть целиком. Лучше заранее договориться, кто отвечает за параметры: режим LACP, таймеры, hashing и поведение при отказе одного участника пары.
С MTU и jumbo frames правило простое: включайте только там, где контролируете весь путь. Если на одном участке MTU 9000, а на другом 1500, получите странные тайм-ауты: пинги идут, а хранилище «сыпется».
Минимальный набор проверок перед вводом:
- отключить один порт на хосте и убедиться, что связь и доступ к storage не рвутся
- выключить один коммутатор и проверить, что узлы и ВМ остаются доступными
- создать и поймать петлю в тестовой зоне, проверить STP и защиту портов
- проверить MTU по всему пути (особенно storage и migration)
- посмотреть, что будет при ошибке LACP: не пропадает ли сеть полностью
Если проект делаете с интегратором, фиксируйте эти проверки как обязательные для приемки. В практике системной интеграции (в том числе на базе серверов и инфраструктуры уровня GSE.kz) именно такие тесты быстрее всего показывают, где HA «держится на одном коммутаторе».
Quorum и защита от split-brain
Quorum простыми словами - это правило, по которому кластер решает, кто имеет право продолжать работу, если часть узлов или сеть пропали. Без quorum кластер может попытаться быть «живым» сразу в двух местах, и это почти всегда заканчивается проблемами.
Почему split-brain опасен
Split-brain возникает, когда узлы теряют связь друг с другом, но каждый считает себя «главным» и продолжает запускать виртуальные машины. Самый плохой сценарий - одна и та же VM пишет данные на одно и то же хранилище с двух сторон. Итог - повреждение файловой системы, потеря транзакций, долгий и нервный ремонт.
Quorum нужен именно для того, чтобы в момент разделения кластер выбрал одну «половину» как рабочую, а вторую остановил или перевел в безопасный режим.
Witness: какой бывает и где его держать
Чаще всего к quorum добавляют witness (свидетель) - отдельный голос, который помогает принять решение при споре 1 к 1.
Варианты:
- witness как отдельный сервер или сервис (внешний witness)
- диск-свидетель (общий диск или том, доступный всем узлам)
- witness в другой площадке или сегменте, доступном обоим узлам
Ключевое правило размещения: witness не должен «умереть» по той же причине, что и узлы. Если оба хоста виртуализации и witness зависят от одного коммутатора, одного ИБП или одной линии связи, это не защита, а иллюзия.
Практичный вариант для офиса: два узла стоят в серверной, а witness вынесен в другой шкаф или комнату, либо на небольшой отдельный хост в другом сегменте - с независимым питанием и портом на другом коммутаторе.
Для отказоустойчивого кластера виртуализации полезно заранее прописать тесты и критерии «правильного» поведения:
- разрыв связи между узлами при живом witness (кто остается активным)
- потеря witness при живой связи узлов (кластер должен продолжить работу)
- падение одного узла (VM должны стартовать на втором)
- разрыв одного сетевого сегмента (например, только storage-сети)
- одновременный отказ коммутатора, к которому не должен быть привязан witness
Если проектируете инфраструктуру под закупки и внедрение, включайте эти тесты в приемку вместе со схемой и планом аварийных действий.
Доменные и инфраструктурные зависимости: что может остановить HA
Даже если отказоустойчивый кластер виртуализации переживает падение хоста, он может «встать» из-за внешних зависимостей. Виртуальные машины перезапустятся, но сервисы не поднимутся: не находится DNS, не выдается IP, не проходит вход в домен, ломаются сертификаты, не сходится время.
Самая опасная ситуация - потеря целой площадки. Если все ключевые службы (AD, DNS, NTP, PKI) живут только там, то на резервной стороне кластер вроде бы работает, но пользователи не могут войти, приложения не видят базы, а администратор не может нормально управлять инфраструктурой.
Минимальный набор, который должен быть доступен в аварии (локально на каждой площадке или в отдельной зоне с независимым питанием и сетью):
- DNS (и лучше локальные резолверы для сервисных зон)
- DHCP (или статические адреса для критичных узлов)
- NTP (как минимум один надежный источник времени)
- AD/LDAP (минимум два контроллера домена, разнесенные по отказам)
- PKI/сертификаты и сервисы лицензирования (если без них приложения не стартуют)
Размещайте эти службы так, чтобы отказ одного узла не «утащил» их вместе с кластером. Практичное правило: не держать все «фундаментальные» зависимости на одном гипервизоре.
- отдельные VM для инфраструктурных ролей (не совмещать все в одной)
- разнести по разным хостам и по разным стойкам/UPS
- не размещать единственный DNS/DC на хосте, который чаще всего обслуживается
- предусмотреть доступ к ним при отказе одного коммутатора
Особое внимание времени. Рассинхронизация NTP быстро приводит к отказам входа в домен, проблемам Kerberos, «просроченным» сертификатам и сбоям API. На тестовом падении узла проверяйте не только старт VM, но и реальный вход пользователей и работу сервисов, завязанных на время и сертификаты.
Хранилище и пути доступа: самый частый источник простоя
Данные виртуальных машин живут не на гипервизоре, а на хранилище. Поэтому отказоустойчивый кластер виртуализации часто «падает» не из-за узлов, а из-за того, что второй узел не может быстро и безопасно увидеть те же самые тома. Если хранение недоступно или доступно «частично», HA превращается в долгий простой или, хуже, в риск повреждения данных.
Самая частая скрытая точка отказа выглядит так: хранилище подключено к каждому узлу одним кабелем, через один коммутатор или одну SAN-зону. Формально есть два узла и HA включен, но фактически один порт или один коммутатор решает судьбу всего кластера.
Резервирование путей: минимум, который работает
Хорошая базовая схема строится вокруг независимых путей: два контроллера на СХД (или два независимых узла хранения), два коммутатора, по два сетевых или FC-порта на каждом сервере и multipath на гипервизорах. Тогда при потере любого одного элемента виртуальные машины продолжают читать и писать данные.
Типовые ловушки, которые важно поймать до запуска:
- один «ключевой» том (datastore) без резервной пары или без понятной стратегии восстановления
- одна SAN-зона для всех, из-за которой ошибка в конфиге режет доступ сразу всем узлам
- асимметричные пути (один быстрый, другой «на всякий случай»), из-за чего при аварии задержки резко растут
Что проверить заранее и на тестовом падении
Заранее определите границу ответственности: кластер отвечает за перезапуск VM и порядок действий, а СХД обязана обеспечить корректную блокировку и устойчивый доступ к томам при отказах.
На тестах проверяйте не только «живы ли VM», а поведение под нагрузкой:
- отключение одного пути (порт, кабель, коммутатор) и рост задержек
- переключение между контроллерами СХД и время восстановления
- что multipath не «залипает» на умершем пути
- что после возврата пути нет шторма и повторных сбоев
- что журналирование и консистентность VM не нарушаются
Практичный пример: двухузловой кластер на стоечных серверах (например, уровня S200) может выглядеть надежно, но реальная устойчивость определяется тем, как именно эти два узла видят одно и то же хранилище при любом одиночном отказе.
Пошаговый план проектирования HA кластера
Хороший отказоустойчивый кластер виртуализации начинается не с настройки, а с ясных ожиданий. Если заранее не договориться, какие сбои вы переживаете и за какое время, легко получить «HA на бумаге» и простои в реальности.
1) Зафиксируйте цели и сценарии отказов
Опишите 3-5 самых вероятных ситуаций: отказ одного хоста, падение коммутатора, разрыв линка, недоступность хранилища, проблема с AD/DNS. Рядом укажите требования: сколько минут допустим простой и сколько данных можно потерять (даже если ответ «0»). Это напрямую влияет на выбор quorum, сети и хранилища.
2) Нарисуйте схему: сети, роли, зависимости
На одной схеме должны быть узлы кластера, коммутаторы, отдельные сети (управление, VM-трафик, хранилище, миграции), а также witness и внешние зависимости: AD, DNS, NTP, репозитории обновлений. Частая ловушка: «HA есть, но AD упал, и часть сервисов не поднимается или не принимает вход».
3) Продумайте размещение критичных VM
Заранее решите, какие ВМ нельзя держать на одном узле, и что поднимать первым. Обычно помогают антиаффинити-правила, приоритеты запуска и резерв ресурсов (CPU/RAM), чтобы кластер переживал отказ узла без борьбы за память.
Перед вводом в эксплуатацию зафиксируйте минимум настроек:
- правила размещения и приоритеты запуска критичных ВМ
- параметры quorum и поведение при потере связи
- кто и где выполняет роль witness
- ограничения на overcommit и резервирование ресурсов
- перечень обязательных зависимостей (AD/DNS/NTP/хранилище)
4) Настройте мониторинг заранее
Алерты нужны до запуска: потеря линка, рост задержек, деградация дисков, заполнение датасторов, ошибки кластера и «дрожащие» (флапающие) порты. Важно, чтобы уведомления доходили, даже если часть инфраструктуры недоступна.
5) Составьте план тестов и отката
Сделайте короткий сценарий «как ломаем» и «как возвращаем назад», назначьте ответственных и окно работ. Тестируйте не только падение хоста, но и «половинчатые» аварии: разрыв сети между узлами, отключение одного коммутатора, недоступность witness. После теста обновите схему и инструкции.
Если проектируете кластер на новом железе, заранее проверьте поддержку нужных сетевых карт и накопителей, а также наличие сервиса и запчастей. Для организаций в Казахстане это часто упирается в сроки поставки и поддержку на месте, поэтому локальные производственные и сервисные возможности (например, у GSE.kz) стоит учитывать еще на этапе схемы.
Пример простой схемы для офиса или филиала
Типичный запрос для филиала: нужен отказоустойчивый кластер виртуализации на 2 узла, чтобы пережить падение одного сервера и не потерять ключевые сервисы (файлы, 1С, почта, терминалы). Это хороший минимум, но только если заранее убрать «тихие» точки отказа.
Представим схему: два хоста виртуализации (например, на базе серверов уровня GSE S200 Series), общее хранилище (или локальные диски с репликацией, если платформа это поддерживает) и третий компонент для tie-break: witness. Виртуальные машины: пара бизнес-сервисов и доменные службы.
Чтобы отказоустойчивый кластер виртуализации не упал из-за мелочи, разнесите роли так:
- DNS/AD: минимум два контроллера домена, лучше по одному на каждом узле (это две разные VM). Тогда при падении узла у вас не пропадает логин, DNS и GPO.
- NTP: не «из контроллера домена по умолчанию», а отдельный понятный источник (часто достаточно одного внешнего и одного внутреннего). Важно, чтобы оба узла и обе DC синхронизировались одинаково.
- Witness: не на том же хранилище и не на том же узле. Идеально - маленькая VM или файловая шара в головном офисе, либо отдельное небольшое устройство в филиале на другом питании и другой сети управления.
- Мониторинг: отдельная VM (можно в головном офисе), чтобы во время аварии вы видели, что именно отвалилось: узел, сеть, storage или шлюз.
Самые частые риски в филиале - один коммутатор для storage или один общий gateway для сети управления. Если единственный коммутатор умирает, оба узла «живы», но кластер теряет доступ к дискам. Если падает общий gateway, можно потерять управление и witness одновременно, и получить спор за лидерство.
При падении одного узла сервисы обычно перезапускаются на втором: часть VM стартует быстро, часть дольше (зависит от загрузки, проверки дисков, поднятия приложений). Нагрузка на оставшийся узел резко растет, поэтому его надо проектировать с запасом.
При разрыве связи между узлами решает quorum: «победит» сторона, у которой есть большинство голосов. Witness нужен именно для того, чтобы в схеме 1+1 не случился split-brain: один узел продолжает работать, второй останавливает VM и ждет восстановления связи.
Частые ошибки и «скрытые» точки отказа
Самые неприятные простои в HA редко выглядят как «упал хост». Чаще это мелкая экономия или зависимость, которую никто не считал критичной, пока не случился реальный сбой.
Первая ловушка - сеть. Когда весь трафик кластера, хранилища и управления проходит через один коммутатор или один аплинк, вы получаете один общий выключатель на всю инфраструктуру. В тесте «падение узла» все красиво, а при реальном отказе коммутатора кластер теряет связь одновременно со всеми и начинает вести себя непредсказуемо.
Вторая ловушка - witness в том же месте, что и кластер. Если witness стоит в той же стойке и в той же сети, он не помогает принимать решение при разделении сети. В итоге quorum становится формальностью: при одном инциденте вы теряете и узлы, и точку арбитража.
Третья ловушка - доменные зависимости. Когда AD, DNS и NTP живут на одной виртуальной машине без резерва и без плана восстановления, отказ именно этой VM превращает «отказоустойчивый кластер виртуализации» в набор хостов, которые не могут нормально авторизоваться, разрешать имена и держать время. Простой пример: после сбоя питания VM с AD не поднимается, хосты теряют доступ к хранилищу по имени, часть сервисов не стартует, и вы тратите часы на ручные обходы.
Есть и ошибки ожиданий: HA не заменяет бэкапы, регулярный тест восстановления и простую документацию. Без этого вы переживете отказ узла, но не переживете удаление данных, шифровальщика или ошибку администратора.
Наконец, обновления. Если нет режима планового обслуживания и понятного окна перезагрузок, любое обновление превращается в риск: один хост ушел в ребут, второй перегрузили «на минуту», и кластер уже в аварийном режиме.
Короткая самопроверка перед пилотом:
- есть ли минимум два независимых пути по сети к управлению и к хранилищу
- отделен ли witness по отказодомену (питание, стойка, сеть)
- разнесены ли AD/DNS/NTP и есть ли сценарий их восстановления
- есть ли бэкапы и проверенный тест восстановления
- описан ли порядок плановых работ и кто принимает решения при инциденте
Если строите кластер на новых серверах (например, для филиала или госорганизации в РК), закладывайте эти пункты в ТЗ заранее. Это дешевле, чем «лечить» скрытые точки отказа после первого же отключения.
Чеклист теста падения узлов и разрывов сети
Перед тестом
Тест отказоустойчивости лучше делать как мини-учения: с понятной целью и безопасной точкой возврата. Перед началом проверьте свежие резервные копии ВМ и конфигураций кластера, согласуйте окно работ и подготовьте план отката с конкретными шагами.
Отдельно составьте короткий список критичных сервисов и их владельцев: например, бухгалтерия, почта, 1С, VDI, файловые шары. Так быстрее понять, что именно должно «подняться само» и кто подтверждает результат.
Во время теста
Проверки удобнее вести как сценарии: выполняйте их по одному и возвращайте систему в норму перед следующим шагом.
- Сеть: отключите один порт на хосте, затем целый коммутатор, затем проверьте отказ gateway. Если есть разные MTU (например, для storage), убедитесь, что при аварии не появляются «тихие» потери пакетов.
- Quorum: отключите witness и посмотрите, сохраняется ли кворум. Затем сделайте разрыв связи между узлами и наблюдайте, кто остается активным, а кто уходит в защитный режим.
- Зависимости: проверьте доступность DNS/NTP/AD при аварии. Убедитесь, что администратор может войти в консоль управления, а сервисы, завязанные на сертификаты, продолжают проверку и выпуск по плану.
Простой пример: вы выключаете один хост, и ВМ переезжают за 2-3 минуты, но часть пользователей теряет вход, потому что DNS остался на той же ВМ и не успел стартовать. Это не «ошибка кластера», это скрытая зависимость.
После каждого сценария фиксируйте факты: реальный RTO по сервисам, что сломалось, какие алерты сработали или не сработали, и какие правки нужны (сеть, witness, размещение DNS/NTP/AD, порядок автозапуска).
Следующие шаги: как довести схему до рабочего проекта
Чтобы схема не осталась «на бумаге», оформите проект в понятных артефактах. Тогда отказоустойчивый кластер виртуализации проще согласовать, собрать и проверить без сюрпризов.
Начните с набора документов, который можно отдать на сборку и на проверку:
- схема (физика и логика): узлы, сети, коммутаторы, хранилище, witness, точки управления
- матрица отказов: что ломаем (узел, линк, коммутатор, контроллер домена), что должно произойти (перезапуск ВМ, деградация, останов)
- план тестов: порядок действий, ожидаемые тайминги, кто подтверждает результат
- реестр зависимостей: DNS, AD, NTP, DHCP, PKI, резервное копирование, доступ к консоли
- план отката: как вернуть сервис, если тест или обновление пошли не так
Дальше двигайтесь по приоритету, который обычно дает максимум эффекта. Сначала уберите явные SPOF в сети и в witness (один коммутатор, один линк, witness в той же зоне отказа). Затем проверьте доменные и инфраструктурные зависимости (например, кластер не может поднять ВМ, потому что DNS и NTP недоступны). И только потом доводите до идеала хранилище и все пути доступа.
Железо под HA выбирайте с запасом. Если падает один узел, оставшиеся должны вытянуть нагрузку без «красной зоны» по CPU и RAM. Полезно заранее требовать: два блока питания, достаточное число сетевых портов под разделение трафика, понятная схема дисков (и запас под рост), доступ к удаленной консоли.
Интегратора стоит привлекать, когда есть сложная сеть (несколько VLAN, L3, разные зоны безопасности), две и более площадки, или требования по госзакупкам и подтверждению локального происхождения оборудования.
Если вы в Казахстане, удобно, что серверы и рабочие станции GSE производятся внутри страны, а проектирование и поддержка 24/7 можно получить в одном контуре. Это особенно полезно, когда нужно не просто «собрать», а проверяемо протестировать отказоустойчивость и зафиксировать результаты.
FAQ
С чего начать проектирование отказоустойчивого кластера виртуализации?
Начните со списка отказов, которые вы обязаны пережить без остановки сервиса: **хост**, **коммутатор/линк**, **путь к хранилищу**, **разрыв между площадками**, **DNS/AD/NTP**. Затем зафиксируйте **RTO** (за сколько минут сервис возвращается) и **RPO** (сколько данных можно потерять). Без этих цифр «HA включен» не означает ничего проверяемого.
Почему «кластер пережил падение хоста», а сервис все равно недоступен?
Потому что кластер часто перезапускает ВМ, но **бизнес-сервис не поднимается** из‑за зависимостей: DNS, AD, NTP, доступ к хранилищу, лицензирование, шлюз. Минимальный критерий успеха теста — не «ВМ запустилась», а: - пользователи реально входят и работают; - данные консистентны; - восстановление укладывается в RTO/RPO; - есть понятные алерты и логи; - система возвращается в норму без ручных «костылей».
Какие сети нужно выделять в HA-кластере и зачем?
Для минимально рабочей схемы обычно достаточно: - **management** (управление хостами/кластером), - **production** (трафик виртуальных машин), - **storage** (доступ к СХД или репликации), - **migration/replication** (миграции и/или репликация). Даже если физически портов мало, разделяйте роли хотя бы VLAN-ами и держите понятный план резервирования (2 коммутатора, 2 линка).
Сколько коммутаторов и линков нужно, чтобы HA был «настоящим»?
Рабочий минимум — **две независимые точки**: два коммутатора и по два порта/линка с каждого хоста (по возможности разными трассами и питанием). Типовая ошибка — «два кабеля в один коммутатор». Формально дублирование есть, но коммутатор остается одиночной точкой отказа.
Почему LACP иногда ломает отказоустойчивость вместо того, чтобы помогать?
LACP/MLAG полезны, но их легко настроить так, что при сбое или ошибке на стороне коммутатора **оба линка** уйдут в блокировку, и хост потеряет сеть целиком. Что помогает: - заранее согласовать режим LACP, таймеры и hashing; - проверить поведение при отказе одного участника пары; - иметь план «что будет, если агрегация развалится».
Что такое quorum и чем опасен split-brain?
Quorum — это правило, по которому кластер решает, **кто продолжает работу**, если часть узлов или сеть пропали. Без quorum возможен **split-brain**: две стороны считают себя активными и могут одновременно писать в одни и те же данные. Это риск повреждения файловых систем и потери транзакций.
Где размещать witness, чтобы он реально защищал кластер?
Witness нужен как «дополнительный голос» в конфигурации 1+1, чтобы при споре кластер мог принять решение. Главное правило: witness должен быть в **другом домене отказа** (не та же стойка, не тот же ИБП, не тот же коммутатор/сегмент). Иначе вы потеряете и узлы, и арбитраж одним инцидентом.
Какие инфраструктурные зависимости чаще всего «останавливают» HA?
Минимум — иметь эти сервисы доступными даже в аварии: - **DNS** (лучше несколько резолверов), - **AD/LDAP** (хотя бы два контроллера домена, разнесенные по отказам), - **NTP** (понятный источник времени), - при необходимости **DHCP**, **PKI/сертификаты**, **лицензирование**. Практично: не держать единственный DNS/DC на одном хосте, который «чаще всего обслуживается» или может уйти в ребут.
Почему хранилище — самый частый источник простоя в виртуализации?
Потому что HA зависит от того, сможет ли второй узел **быстро и безопасно** увидеть те же тома. Проверьте заранее: - есть ли два независимых пути (порты/коммутаторы/контроллеры); - настроен ли multipath и не «залипает» ли на умершем пути; - как ведут себя задержки и IOPS при отказе одного пути; - нет ли «одного ключевого datastore», от которого зависит всё.
Какие тесты обязательно провести перед вводом HA-кластера в эксплуатацию?
Базовый набор тестов, который чаще всего ловит скрытые SPOF: - отключить один порт на хосте и убедиться, что связь и storage не рвутся; - выключить один коммутатор и проверить доступность узлов и ВМ; - разорвать связь между узлами при живом witness (кто останется активным); - отключить witness при живой связи узлов (кластер должен продолжить работу); - отключить один путь к storage и посмотреть задержки и переключение multipath. Фиксируйте реальные времена восстановления по сервисам (RTO) и фактическую потерю данных (RPO), а не только «зеленый статус кластера».