Отказоустойчивость PostgreSQL: Patroni и Pacemaker на 3 узлах
Разбираем отказоустойчивость PostgreSQL на 3 узлах: Patroni или Pacemaker, требования к сети, quorum, сценарии failover и проверка RPO/RTO.
Задача: пережить сбои PostgreSQL без сложных и дорогих решений
Отказоустойчивость PostgreSQL нужна не ради «идеальной архитектуры», а чтобы бизнес не вставал из-за типовых поломок. Чаще ломается не сама база, а окружение: железо, сеть, питание или человеческий фактор.
На практике проблемы обычно выглядят так: узел внезапно становится недоступен (завис, ушел в ребут, «умер» блок питания), диск начинает сыпать ошибки или заканчивается место, сеть дает обрывы и «плавающие» потери пакетов, обновление ОС или PostgreSQL проходит неудачно, кто-то правит конфиг или выполняет команду не там.
Самая частая ловушка - идея «поставим одну реплику и хватит». Реплика сама по себе не решает главный вопрос: кто и по каким правилам принимает решение о переключении. Если primary недоступен, нужно быстро и безопасно повысить standby до primary, не получив две активные базы одновременно. А если проблема не в сервере, а в сети, один standby легко превращается в источник риска: каждый узел «думает», что второй умер.
Что реально можно сделать без дорогих решений и SAN:
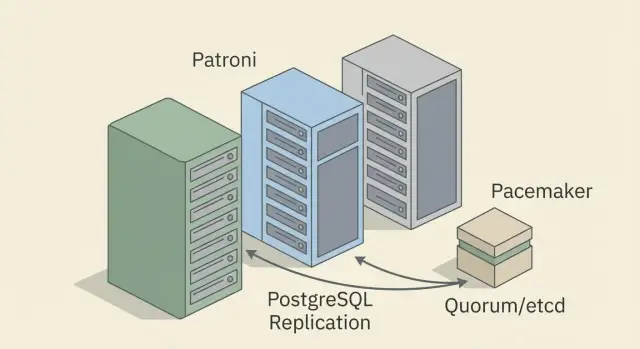
- собрать кластер из 3 участников (1 primary, 1 replica и 1 узел для кворума или координации);
- настроить автоматическое переключение с понятными правилами и таймингами;
- заранее договориться о приемлемых потерях данных (RPO) и времени простоя (RTO);
- регулярно тестировать аварии, а не надеяться на документацию.
Риски все равно остаются. При асинхронной репликации последние транзакции могут потеряться при аварии primary. При сетевых разрывах без корректного fencing легко получить split brain и тяжелое восстановление.
Если говорить максимально просто, Patroni и Pacemaker/Corosync отличаются уровнем, на котором они «мыслят». Patroni ближе к PostgreSQL: он понимает роли репликации и обычно опирается на внешний DCS для выбора лидера. Pacemaker/Corosync - универсальный кластерный менеджер: он управляет ресурсами и зависимостями на уровне ОС и сервисов. Оба варианта дают отказоустойчивость, но цена ошибки почти всегда в настройках сети и правилах переключения, а не в выборе инструмента.
Пример из жизни: в клинике запись пациентов идет весь день. Если сервер с primary уходит в ребут после обновления, кластер должен поднять реплику за минуты. Команда при этом должна заранее знать, сколько данных допустимо потерять и как проверить, что система вернулась в норму.
Базовые термины: HA, репликация, RPO/RTO и quorum
Высокая доступность (HA) для PostgreSQL - это когда база переживает сбои так, чтобы приложение продолжало работать, а переключение на резервный узел происходило быстро и предсказуемо. В простейшем виде есть один primary (принимает запись) и один или несколько standby (получают изменения через репликацию и готовы стать новым primary).
Репликация означает одно: primary отправляет изменения на standby. Если используется автоматическое переключение (failover), отдельный компонент (например, Patroni или Pacemaker) решает, кто сейчас primary и когда standby можно повышать.
RPO: сколько данных можно потерять
RPO (Recovery Point Objective) - допустимая потеря данных по времени. RPO = 0 означает, что вы не готовы терять подтвержденные записи. RPO = 10 секунд означает, что потеря последних 10 секунд изменений приемлема.
RPO напрямую зависит от режима репликации:
- Асинхронная: primary подтверждает запись клиенту сразу, а standby догоняет позже. Быстро, но при падении primary можно потерять часть последних транзакций.
- Синхронная: primary подтверждает запись только после того, как standby тоже ее принял. Это приближает к RPO = 0, но замедляет запись при задержках сети.
RTO: как быстро вернуться в работу
RTO (Recovery Time Objective) - время простоя, которое вы готовы терпеть. Сюда входит обнаружение сбоя, выбор нового primary, переключение клиентов и часто прогрев кэшей и восстановление соединений.
Если сервис должен «оживать» за минуту, то детектирование, таймауты и само переключение должны укладываться в эту минуту. Если мониторинг узнает о сбое через 60 секунд, а failover занимает еще 30, то RTO меньше 2 минут уже недостижим.
Quorum: почему нельзя просто выбрать нового primary
Quorum - правило большинства. Оно нужно, чтобы при проблемах связи кластер не получил split brain, когда два узла одновременно считают себя primary.
Типичный сценарий: сеть разделилась на две части. Если обе стороны «сами себе хозяева», они могут поднять по primary и начать принимать запись. Потом связь восстановится, и данные разойдутся. Свести их обратно будет очень сложно.
Поэтому в HA-кластерах право назначать primary дают только стороне, которая видит большинство участников (или отдельного арбитра). Прежде чем автоматизировать failover, нужно решить, где хранится «истина» о том, кто primary, и как система запрещает второй стороне принимать запись.
Минимальная архитектура: сколько узлов нужно и какие роли
Для автоматического аварийного переключения PostgreSQL минимальная рабочая схема почти всегда упирается в число три. Два узла (primary + replica) умеют реплицироваться, но не умеют надежно договориться, кто прав, если сеть или один из узлов «пошатнется». Третий участник нужен для quorum, иначе легко получить простой или, хуже, два «главных».
Самый понятный минимум - 3 узла в одной площадке (или в двух, если сеть стабильная и задержки предсказуемы). Вариант «2 узла плюс внешний witness» тоже рабочий: witness может быть легкой виртуальной машиной в другом сегменте сети. Его задача - помогать принимать решение, а не хранить данные.
Роли обычно такие:
- Primary - принимает запись и считается единственным источником истины.
- Replica (standby) - получает WAL и готова стать primary.
- Узел для quorum - DCS (например, etcd/Consul) или witness/арбитр (зависит от подхода).
Важно: узел для quorum не спасает данные. Он снижает риск split brain.
Чтобы такая схема реально работала, нужны не только «три машины», но и дисциплина вокруг них. Заранее договоритесь о единых настройках PostgreSQL (репликация, таймауты, слоты, синхронность), о порядке обновлений (по одному узлу, с проверкой реплики) и о том, кто имеет право запускать ручной failover.
Минимум, без которого обычно начинаются сюрпризы: мониторинг задержки репликации и места на диске, одинаковое время на всех узлах (NTP), предсказуемые DNS и имена, а также алерты на само переключение.
И даже при HA бэкапы остаются обязательными. Репликация защищает от падения узла, но не от ошибки человека, удаления данных, «битых» обновлений или тихой порчи. Практичный подход - хранить бэкапы отдельно от кластера и регулярно проверять восстановление. Тогда ваши RPO/RTO будут не на бумаге, а подтверждены тестами.
Patroni или Pacemaker/Corosync: чем они отличаются на практике
Если нужна отказоустойчивость PostgreSQL без «тяжелых» проприетарных кластеров, чаще всего выбирают один из двух подходов.
Patroni управляет именно PostgreSQL и его ролями. Pacemaker/Corosync управляет ресурсами на уровне ОС и может поднимать PostgreSQL как один из ресурсов рядом с другими.
Patroni: управление от логики PostgreSQL
Patroni держит логику кластера ближе к базе: кто primary, кто standby, когда и как делать failover. Решение опирается на DCS (распределенное хранилище состояния) и политики: ограничения на выбор кандидата в primary, допустимый lag реплики, таймауты.
В ежедневной эксплуатации это часто означает более предсказуемое и быстрое переключение, а поведение кластера проще объяснить команде DBA.
Pacemaker/Corosync: управление на уровне ОС
Pacemaker/Corosync подходит, когда в компании уже есть стандарт на Pacemaker, требования к fencing и регламентам строгие, а кластер должен управлять не только базой.
Здесь вы описываете ресурс PostgreSQL, правила размещения, зависимости, мониторинг и сценарий изоляции узла (fencing), чтобы не получить два primary. Этот путь требовательнее к дисциплине: изменения в systemd, сетевых настройках и обновления ОС нужно проверять с учетом правил кластера.
На выбор обычно влияют простые вопросы. Если сильнее экспертиза DBA и важна логика ролей базы - чаще удобнее Patroni. Если уже есть зрелая практика Pacemaker и по политике безопасности обязательно fencing - чаще уместнее Pacemaker/Corosync. Если нужно единообразно управлять несколькими ресурсами (VIP, сервисы, приложения) - Pacemaker часто выигрывает.
Что одинаково сложно в обоих подходах: сеть (задержки и потери), регулярное тестирование отказов, контроль изменений и честная проверка RPO/RTO. Даже на надежном железе ошибки чаще происходят из-за процессов: кто и когда меняет конфигурацию, как откатываемся, что делаем при частичной потере связности.
Требования к сети: задержки, потери, время и доступность
Для отказоустойчивости PostgreSQL сеть часто важнее, чем «толстый канал». Репликация и компоненты quorum живут на небольших сообщениях, но им критичны задержки, потери и предсказуемость. Если сеть «иногда подлагивает», вы получаете не только медленную репликацию, но и ложные аварийные переключения.
Высокая задержка увеличивает отставание реплики и время подтверждения транзакций при синхронной репликации. Потери и джиттер (скачки задержки) бьют по heartbeat между узлами и по соединениям репликации: сессии рвутся, узлы перестают «видеть» друг друга, и кластер начинает принимать неправильные решения.
Время, DNS и «мелочи», которые ломают failover
Единое время на узлах нужно не «для красоты». Неправильный NTP приводит к странным тайм-аутам, неверным метрикам и путанице в логах. DNS тоже должен быть скучным и стабильным: если имя DCS или узла резолвится через раз, failover будет зависеть от удачи.
Перед запуском полезно проверить базовые вещи: стабильную задержку между узлами без регулярных пиков, потери близкие к нулю на межузловом канале, NTP на всех узлах и одинаковый часовой пояс, надежный DNS или статические записи там, где это оправдано. Если возможно, выделите отдельную сеть или VLAN для межузлового трафика (репликация, quorum).
Порты и сегментация
Обычно нужен TCP 5432 для клиентских подключений и репликации PostgreSQL. Дальше зависит от стека: Patroni требует доступности DCS (например, etcd или Consul) и его портов, а Pacemaker/Corosync использует свои каналы для обмена состоянием. Важнее конкретных портов то, что межузловое общение и доступ к DCS должны быть разрешены в обе стороны и не «фильтроваться» по пути.
Признаки, что проблема именно в сети, а не в базе: реплика то догоняет, то резко отстает без явной нагрузки, в логах много reconnect и timeout, менеджер кластера периодически объявляет узел «мертвым», failover срабатывает «на ровном месте», а пинги иногда нормальные, но с редкими всплесками задержки или потерями.
Если вы строите отказоустойчивость без дорогих кластеров, начните с измерений. Замерьте задержку, потери и стабильность на межузловом канале в течение суток. Это дешевле, чем лечить «странные» failover в продакшене.
Quorum, split brain и fencing: как не получить два primary
Split brain - ситуация, когда кластер из-за сетевого разрыва начинает жить как будто он разделился на два независимых кластера, и в каждом появляется свой primary. Самый неприятный сценарий - приложение пишет в один primary, часть сервисов пишет в другой, а после восстановления связи данные расходятся.
Причина обычно не PostgreSQL, а связь: короткие обрывы, асимметричная доступность (A видит B, но B не видит A), проблемы с DNS, задержки и потери. В этот момент HA-менеджер должен быстро и однозначно решить, кто остается primary, а кто обязан остановиться.
На 3 участниках quorum работает по логике «2 из 3». Решения принимает только большинство. Это безопаснее, чем «1 из 2» в двухузловой схеме, где при разрыве связи оба узла могут считать себя единственно живыми.
Где хранится состояние кластера, зависит от подхода. В Patroni «истина» живет во внешнем DCS: там лежит блокировка лидера, TTL и метаданные. В Pacemaker/Corosync роль «памяти» играет сам кластер: Corosync отвечает за членство и quorum, а Pacemaker применяет правила запуска и перемещения ресурсов.
Иногда добавляют witness (arbitrator), чтобы получить большинство без полноценного третьего сервера PostgreSQL. Он помогает голосом, но не решает проблему, если вы все равно не можете надежно определить, кто должен быть primary.
Ключевой механизм против split brain - fencing, часто через STONITH («выстрелить в голову» зависшему узлу). Логика жесткая: если кластер не уверен, что старый primary действительно недоступен, лучше принудительно выключить его (питание, гипервизор, BMC/IPMI), чем рискнуть двумя primary.
Практическое правило простое: если вы не можете гарантировать fencing, вы не гарантируете защиту от split brain.
Перед запуском проверьте хотя бы это: есть ли надежный способ удаленно выключить узел, настроены ли таймауты так, чтобы не реагировать на секундные «мигания» сети, корректно ли считается quorum, и протестировали ли вы именно сетевой разрыв, а не только «остановить процесс postgres».
Пошагово: базовый кластер Patroni на 3 узлах
Типовая схема Patroni выглядит так: два узла с PostgreSQL (primary и standby) и DCS. Минимальный вариант с одним узлом etcd возможен, но уязвим к потере DCS. На практике надежнее иметь кворум и для DCS (например, 3 узла etcd).
1) Подготовка узлов и PostgreSQL
Добейтесь одинаковой базы: одна версия PostgreSQL, одинаковые расширения и пути к данным. Заранее определите порты, имена узлов и DNS. Проверьте синхронизацию времени (NTP), открытые порты между узлами, доступ к диску без «странных» задержек и корректные лимиты на файлы.
Также заранее заведите отдельные учетные записи для репликации и администрирования и зафиксируйте минимальный набор параметров репликации в postgresql.conf.
2) Репликация: WAL, слоты и базовая копия
На будущем primary включите wal_level=replica, задайте max_wal_senders с запасом и настройте archive_mode, если используете архивирование WAL. Для предсказуемого поведения полезны replication slots, чтобы WAL не удалялись раньше, чем их заберет реплика.
Поднимите standby через pg_basebackup или bootstrap Patroni. Важно, чтобы реплика стартовала чисто, видела primary, а lag можно было измерять.
3) DCS (etcd) и проверки доступности
Разверните DCS и проверьте простое: любой узел Patroni должен стабильно читать и писать ключи, а задержка ответов должна быть предсказуемой. Если DCS периодически недоступен, Patroni начнет «нервно» переизбирать лидера.
4) Конфигурация Patroni и политика failover
В patroni.yml задайте имя кластера, параметры подключения к DCS и настройки PostgreSQL. На поведение при сбоях сильнее всего влияют TTL и loop_wait (частота обновления лидерства), retry_timeout, maximum_lag_on_failover, а также ограничения на выбор кандидата (tags).
Продумайте, как подключаются клиенты. Если приложения ходят прямо на IP конкретного узла, после переключения они продолжат ломиться в старый primary. Обычно нужна одна точка входа: виртуальный IP, балансировщик или прокси.
5) Проверка: switchover и авария
Сначала сделайте ручной switchover и убедитесь, что новый primary принимает запись, а бывший primary стал репликой. Затем имитируйте падение (остановка PostgreSQL или обрыв сети на primary) и измерьте время failover.
Полезный минимум тестов: ручной switchover с замером времени, остановка PostgreSQL на primary и ожидание автоматического failover, возврат узла и присоединение как standby без ручной «чистки», проверка потери данных (последние транзакции и lag), проверка приложения (переподключилось ли само).
Если эти тесты проходят повторяемо, базовая схема обычно жизнеспособна, и дальше можно измерять RPO/RTO под реальные нагрузки.
Пошагово: PostgreSQL под Pacemaker/Corosync
Pacemaker/Corosync часто выбирают, когда нужен HA на Linux по «классическим» правилам и с обязательным fencing. Ниже логика для кластера из 3 участников: два узла с PostgreSQL и третий как голос для quorum.
1) Подготовка ОС и Corosync
Зафиксируйте имена узлов, настройте NTP и желательно выделите отдельную сеть или VLAN для кластера. Здесь важнее предсказуемость, чем скорость. Проверьте связность между всеми участниками по адресам Corosync и убедитесь, что DNS или /etc/hosts не «прыгает».
2) Ресурс PostgreSQL: запуск, остановка и промоут
Pacemaker должен понимать, что такое primary и standby. Обычно используют OCF-агент для PostgreSQL, который умеет запускать/останавливать сервис и повышать реплику.
Практически все сводится к трем группам настроек: путь к data directory и параметры health-check, ограничения размещения (primary только на одном узле), правила порядка (что поднимается раньше и что переносится вместе).
Если вы используете синхронную репликацию, согласуйте ее с правилами промоута. Иначе кластер может «честно» ждать подтверждения, которого уже нет.
3) Как подключаются клиенты: виртуальный IP
Самый понятный способ для приложений - виртуальный IP (VIP), который переезжает на активный узел. Клиенты ходят на один адрес, а Pacemaker переносит VIP вместе с ролью primary.
VIP должен подниматься только на primary. Если он окажется на standby, приложения начнут писать не туда или будут получать ошибки.
4) Fencing (STONITH): лучше включить
Fencing нужен, чтобы в спорной ситуации кластер мог жестко выключить «потерянный» узел и гарантировать, что primary один. Идеально, если есть IPMI/iDRAC/iLO или управляемый PDU.
Проверьте два сценария отдельно: «узел завис» и «узел потерял сеть». Без fencing Pacemaker иногда вынужден выбирать между доступностью и безопасностью данных.
5) Мини-тест аварийного переключения
Сделайте короткую проверку: запустите запись в БД и зафиксируйте время, отключите питание или сеть активного узла (не просто перезапуск сервиса), убедитесь, что VIP переехал и второй узел стал primary. Затем проверьте, какие транзакции потерялись (фактический RPO) и сколько заняло восстановление доступа (фактический RTO).
Сценарии аварийного переключения и проверка RPO/RTO
Настроить отказоустойчивость мало. Важно заранее понять, как система ведет себя при реальных сбоях, и подтвердить цифрами ваши RPO и RTO.
Три сбоя, которые стоит отработать
-
Падение primary (процесс, ОС, питание). Проверяйте отдельно каждый тип. Остановка процесса postgres часто «лечится» проще, чем потеря питания.
-
Обрыв сети между узлами и риск split brain. Это самый опасный случай. В правильной схеме его блокируют quorum и fencing: «проигравший» узел должен быть остановлен или изолирован до того, как второй получит право писать. В тесте важно симулировать именно разрыв между узлами при живых машинах.
-
Деградация диска или рост lag репликации. Сбой может быть тихим: primary жив, но реплики отстают, и реальный RPO растет. Проверьте, что мониторинг реагирует на lag и что политика переключения не делает primary узел с большим отставанием.
Как измерить фактические RPO и RTO
Чтобы получить честные цифры, фиксируйте не только время переключения, но и потерю данных. Простой подход: генерировать метки в базе (например, раз в секунду вставлять строку с timestamp) и сравнивать, до какой метки дошла новая primary после аварии.
В каждом тесте полезно записывать: момент инцидента, момент первых ошибок у клиентов, момент восстановления записи (это RTO), последнюю подтвержденную транзакцию до сбоя и первую после (основа для RPO), а также lag до и после.
RPO зависит от режима репликации. При синхронной репликации и правильно выбранном синхронном standby потеря может быть близка к нулю, но RTO часто растет. При асинхронной репликации RTO нередко меньше, но RPO становится «сколько не успело доехать до реплики».
Тесты проводите безопасно: согласуйте окно, держите план отката и фиксируйте результаты (сценарий, RPO, RTO, выводы и правки). После нескольких прогонов почти всегда всплывают «мелочи», которые ломают failover: таймауты, неверный quorum, слишком агрессивные проверки, неготовность приложений к переподключению.
Частые ошибки, быстрый чеклист и следующие шаги
Чаще всего ломается не Postgres, а настройки вокруг него. Система выглядит «живой», пока не начнутся реальные сбои: короткие потери сети, перезагрузка узла, деградация диска.
Типовые ошибки:
- Слишком агрессивные таймауты. Сеть «чихнула» на 2-3 секунды, кластер решил, что primary умер, и начались «качели» ролей.
- Нет реального fencing. Это прямой путь к split brain, где два узла принимают запись.
- Подмена бэкапов репликацией. Репликация не защищает от ошибочных команд, плохих миграций и вредоносных действий.
- Непродуманный способ подключения приложений. Если клиенты ходят на IP узла, после failover они «не знают, куда идти». Нужна одна точка входа (VIP, прокси, балансировщик или DNS с коротким TTL), и ее нужно тестировать так же строго, как переключение.
Быстрый чеклист перед запуском
- Таймауты настроены на основе измерений сети, а не «по ощущениям».
- Fencing настроен, и вы реально умеете безопасно выключить узел удаленно.
- Есть бэкапы и тест восстановления на отдельном стенде.
- Приложение переживает смену primary (переподключение, пул соединений).
- Проведены минимум три учения: падение primary, сетевой разрыв, возврат узла в кластер.
Следующие шаги
Практичный путь - начать с пилота на трех участниках, зафиксировать целевые RPO/RTO, и только потом переносить подход на прод. Параллельно оформите документацию: кто принимает решение о failover, как проверяем целостность, как возвращаем узел, где смотреть метрики и логи.
Если вы упираетесь в платформу (питание, диски, удаленное управление для fencing, стойка под серверы и сеть), это лучше продумать заранее. В таких проектах часто помогает интегратор, который может поставить и поддерживать инфраструктуру под кластер и DCS, а также обеспечить сервисную модель. Например, GSE.kz как производитель и системный интегратор в Казахстане поставляет серверы (в том числе линейку S200) и обеспечивает 24/7 поддержку через сервисную сеть - это удобно, когда fencing и восстановление завязаны на железо и регламент, а не на «память» команды.
FAQ
Почему для отказоустойчивости PostgreSQL почти всегда нужны 3 узла, а не 2?
Минимально рабочая схема для автоматического failover обычно требует трех участников, потому что двум узлам сложно надежно договориться, кто прав при сетевых проблемах. Третий участник нужен для кворума: это может быть отдельный узел для DCS (в случае Patroni) или witness/голосующий узел (в случае Pacemaker/Corosync).
Почему «поставить одну реплику» не равно отказоустойчивости?
Репликация просто копирует изменения с primary на standby, но не решает вопрос управления ролями. При аварии нужен компонент, который однозначно решит, кого повышать до primary, и не допустит ситуации с двумя активными базами. Без этого одна реплика легко превращается в источник риска, особенно при сетевых разрывах.
Как правильно понять и выбрать RPO и RTO для PostgreSQL?
RPO — это сколько данных вы готовы потерять по времени, а RTO — сколько простоя вы терпите. Сначала зафиксируйте эти цифры с бизнесом, а потом под них подбирайте режим репликации, таймауты детекта сбоя и способ переключения клиентов. Без целевых RPO/RTO вы не поймете, успешен ли ваш кластер на практике.
Что выбрать: синхронную или асинхронную репликацию?
При асинхронной репликации primary подтверждает запись сразу, поэтому при его падении можно потерять последние транзакции, которые не успели доехать до standby. При синхронной подтверждение идет только после приема на standby, что приближает RPO к нулю, но делает запись чувствительной к задержкам и потерям сети. Типичный выбор — синхронность для самых критичных операций и асинхронность там, где важнее скорость.
Зачем нужен quorum и чем опасен split brain?
Quorum — это правило большинства, которое помогает кластеру принимать решения при частичной потере связи. Без кворума возможен split brain: два узла одновременно считают себя primary и принимают запись, а потом данные расходятся. Кворум сам по себе не «лечит» сеть, но снижает вероятность катастрофического сценария.
Что такое fencing (STONITH) и почему без него опасно?
Fencing — это принудительная изоляция или выключение узла, чтобы гарантировать, что primary будет только один. Если кластер не уверен, что старый primary реально недоступен, безопаснее остановить его через питание/гипервизор/BMC, чем рисковать двойной записью. Без fencing вы обычно не можете честно обещать защиту от split brain.
Чем на практике отличаются Patroni и Pacemaker/Corosync?
Patroni «думает» категориями PostgreSQL: роли primary/standby, репликационный lag, правила выбора лидера и опирается на DCS для фиксации лидерства. Pacemaker/Corosync управляет ресурсами на уровне ОС: сервисами, VIP, зависимостями и строгими правилами с fencing, что часто требует более дисциплинированной эксплуатации. Выбор обычно упирается в опыт команды и требования к изоляции узлов, а не в «магический» инструмент.
Какие сетевые проблемы чаще всего ломают автоматическое переключение?
Чаще всего проблемы начинаются с нестабильной сети: потери, джиттер и редкие всплески задержки вызывают разрывы репликации и ложные failover. Также ломают кластер рассинхрон времени (NTP), нестабильный DNS и слишком агрессивные таймауты. Перед запуском полезнее измерить сеть сутки и настроить тайминги по фактам, а не по ощущениям.
Как приложения должны подключаться к PostgreSQL, чтобы failover был незаметнее?
Вам нужна одна точка входа, которая «переедет» на новый primary или всегда укажет на него. Это может быть VIP, прокси или балансировщик; важно, чтобы приложения умели переподключаться и переживать разрыв соединений. Если клиенты ходят на IP конкретного узла, после failover они продолжат бить в старый primary и будут получать ошибки.
Как проверить, что RPO/RTO реально выполняются, а не только на бумаге?
Сделайте повторяемые учения: падение primary разными способами, сетевой разрыв между узлами и деградацию диска или рост lag. RTO измеряйте от момента, когда клиенты начали ошибаться, до момента, когда запись снова работает; RPO — по последним подтвержденным данным, которые дошли до нового primary. Самый надежный подход — фиксировать результаты тестов и корректировать таймауты, политику failover и мониторинг.