Отказоустойчивость on-prem приложения: сессии и кэш
Практические приемы, чтобы повысить отказоустойчивость on-prem приложения: сессии, sticky sessions, state, кэш, деградация функций и действия при сбоях.
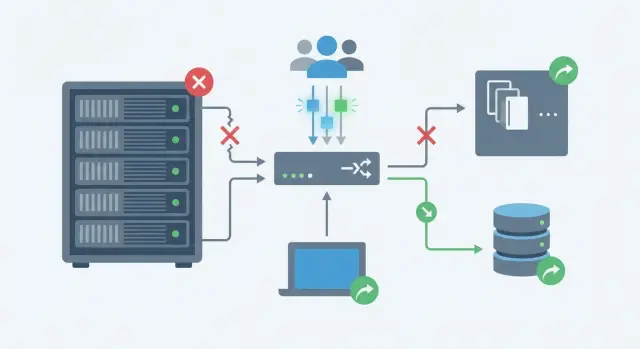
Где обычно теряется состояние и почему это больно
Сбой редко выглядит как полный «аут» системы. Чаще падает один узел приложения или начинает сбоить зависимость. И именно состояние делает проблему заметной: человек уже вошел, что-то выбрал, нажал кнопку, а сервис внезапно «забывает» его.
Самые болезненные места почти всегда одинаковые. При коротком обрыве соединения пользователь видит разлогин, корзина пустеет, в платежах появляется «повторите попытку», поиск то показывает результаты, то нет. Обычно это не потому, что код стал хуже, а потому что state оказался привязан к конкретному процессу, памяти узла или нестабильной цепочке зависимостей.
Есть важная разница между падением узла приложения и деградацией зависимостей. Если упал один экземпляр, балансировщик отправит запрос на другой, но вместе с этим вы теряете локальную сессию, локальный кэш и счетчики в памяти. Если же ничего не падает, но медленно отвечает кэш, база или внешний сервис, приложение формально «живое», а пользователю хуже: таймауты, повторы запросов, странные задержки.
Типичные симптомы:
- Вход проходит, но следующий запрос снова просит авторизацию.
- Корзина или фильтры «сбрасываются» после обновления страницы.
- Платеж зависает или дает ошибку, а статус заказа непонятен.
- Поиск и каталоги то пустые, то с устаревшими данными.
- Ошибки идут «волнами» при пиках нагрузки.
Боль в том, что такие сценарии трудно воспроизвести локально. Они всплывают в проде, на реальных on-prem кластерах и серверах, когда сетевые сбои, перезапуски процессов и задержки зависимостей случаются регулярно, пусть и коротко.
Цели и границы: что считаем отказом и что нужно сохранить
Чтобы отказоустойчивость on-prem приложения не превратилась в бесконечный проект, сначала договоритесь о цели. Не «чтобы не падало», а чтобы ключевые пользовательские действия продолжали работать даже при сбоях отдельных узлов.
Начните с критичных потоков. Для интернет-банка это «войти и увидеть баланс», для портала госуслуг - «подать заявление», для внутренней системы - «создать заявку и не потерять данные». Для каждого потока уточните, что считается сбоем для пользователя: ошибка 500, долгая загрузка, разлогин, потеря корзины.
Дальше нужны две метрики:
RTO - сколько времени сервис может быть частично недоступен, пока вы переключаетесь или восстанавливаетесь (например, 5 минут).
RPO - сколько данных вы готовы потерять при аварии (например, 0 для платежей, 5 минут для аналитики).
Полезно выписать компоненты, где возможен отказ, чтобы потом не спорить «а разве балансировщик тоже ломается». Обычно в цепочке есть балансировщик и DNS, веб-узлы (приложение), хранилище сессий и кэш, база данных, внешние сервисы (почта, SMS, платежи, LDAP).
И наконец, разделите состояние по важности:
- Сессия - «кто вы» и иногда «на каком шаге».
- Кэш - ускоритель, который можно пересоздать, но он влияет на задержки и нагрузку.
- Пользовательские данные - то, что нельзя терять (заказы, документы).
- Временные данные - то, что допустимо потерять (черновики, прогресс не критичного шага).
Пример: при падении кэша вы можете временно отключить рекомендации и расширенный поиск, но вход и сохранение заявки должны работать, пусть и медленнее. Этот компромисс и есть граница: что сохраняем любой ценой, а что деградируем ради выживания сервиса.
Модель состояния: сессии, кэш и данные, которые нельзя терять
Отказоустойчивость часто ломается не на «железе», а на состоянии (state). Поэтому полезно заранее разложить данные приложения на три слоя: сессия, кэш и «истина» (долговременные данные).
Stateless подход проще переживает падение узла: любой запрос можно обработать на любом сервере. Полностью stateless бывает не всегда, но практичный шаг - сделать stateless все, что не требует памяти между запросами: рендер страниц, чтение справочников, получение списка товаров, поиск, формирование отчетов из уже сохраненных данных.
Сессия - это то, что нужно пользователю «прямо сейчас»: кто он, какие права, какой у него сценарий в процессе. Хранить сессию можно по-разному, и выбор влияет на поведение при сбое:
- Память узла (быстро, но при перезапуске все пропадает и нужны sticky sessions).
- Общий стор (распределенное хранилище сессий) - переживает падение узла, но добавляет зависимость от сети.
- Токены (например, подписанные) - минимум серверного state, но сложнее отзыв и контроль.
- База данных - надежно, но дороже по задержке и нагрузке.
Кэш - это ускоритель, а не источник правды. Он бывает локальным (в процессе), распределенным (между узлами), HTTP-кэшем на прокси, или прикладным кэшем в самом сервисе. Критично заранее решить, что будет, если кэш очистится или станет недоступен: система должна замедлиться, но не «переписать историю».
Простое правило по потерям при перезапуске: допустимо терять кэш поисковой выдачи или прогретые справочники; недопустимо терять подтвержденные операции, права доступа, платежные статусы, результаты голосований. Если пользователь заполняет заявку, черновик должен жить в базе (или в отдельном надежном хранилище), а не в памяти узла, иначе падение сервера превращается в потерю работы.
Sticky sessions: когда подходят и чем платим
Sticky sessions (липкие сессии) - настройка балансировщика, при которой один и тот же пользователь всегда попадает на один и тот же узел приложения. Обычно это делается по cookie, IP или специальному идентификатору. Часто это самый быстрый способ «заставить работать» приложение, которое хранит состояние в памяти процесса.
Плюс очевиден: меньше зависимостей. Не нужно сразу поднимать общее хранилище сессий, меньше сетевых вызовов, проще отлаживать. Для отказоустойчивости on-prem приложения это выглядит заманчиво, потому что можно быстро пережить рост нагрузки без большой переделки кода.
Цена тоже понятная. Если узел падает, пользователь теряет сессию и вынужден логиниться заново или повторять шаги. Масштабирование становится менее предсказуемым: нельзя свободно перераспределять трафик, а «горячий» узел может перегружаться, пока другие простаивают. Еще одна проблема - сложнее делать выкаты: часть пользователей «прибита» к узлу, и вы не можете мягко вывести его из пула.
Sticky sessions оправданы, когда риск потери сессии приемлем: сессии короткие, повторный вход не критичен, функция не несет денег и не влияет на безопасность, трафик относительно ровный, и у вас есть план миграции.
План выхода стоит наметить заранее, иначе «временный костыль» останется на годы:
- Вынести сессии в общий стор и хранить только ключ в cookie.
- Минимизировать данные в сессии: токен, роли, пару флагов, но не большие объекты.
- При потере сессии сохранять черновики и шаги в базе.
- Протестировать падение узла: что ломается у пользователя и сколько запросов нужно повторить.
- Переводить поэтапно: часть пользователей уже без sticky, часть еще со sticky, с метриками ошибок.
Так sticky sessions становятся не ловушкой, а переходным этапом, который вы контролируете.
Пошагово: как сделать сессии устойчивыми к падению узлов
Устойчивые сессии начинаются с простого правила: веб-узел должен быть заменяемым. Если один сервер умер, другой должен продолжить работу так, будто ничего не произошло. Это особенно важно для отказоустойчивости on-prem приложения, где обновления, аварии питания и сбои сети случаются чаще, чем хотелось бы.
Шаги настройки
-
Выберите модель хранения сессии. Либо общий стор сессий (отдельный сервис или база), либо «безсерверная» сессия в виде токена, который можно проверить на любом узле. Общий стор проще для сложных сценариев, токены удобны, когда в сессии мало данных.
-
Держите сессию минимальной. Храните только идентификаторы: user_id, роли, id корзины или черновика. Все «тяжелое» (состав корзины, шаги анкеты, файлы) храните в базе или отдельном хранилище черновиков, чтобы падение узла не обнуляло прогресс.
-
Настройте срок жизни и правила обновления. TTL должен соответствовать реальному поведению пользователей (например, дольше для длинных форм). Добавьте ротацию идентификатора сессии после логина и чувствительных действий, а также понятную инвалидизацию при выходе из аккаунта и смене пароля.
-
Ограничьте размер и частоту записи. Сессии, которые раздуваются, становятся источником задержек и ошибок. Введите лимит (например, в килобайтах) и пишите изменения только по делу, а не на каждом запросе.
-
Продумайте поведение при сбое. Если стор сессий временно недоступен, лучше вернуть аккуратное сообщение и переключить часть функций в режим «только чтение», чем бесконтрольно создавать новые сессии и плодить дубликаты.
Как проверить, что работает
Смоделируйте реальную аварию: пользователь заполняет форму на 5 шагов, затем вы принудительно выключаете один узел (или перезапускаете сервис) и продолжаете с другого. Правильный результат: пользователь не разлогинен, черновик на месте, а максимум - один повтор запроса без потери данных. Если вы строите on-prem инфраструктуру на собственных серверах и интеграции (как часто бывает у заказчиков GSE.kz), такие тесты стоит включать в регулярные прогоны перед релизом.
Кэш без сюрпризов: TTL, прогрев и защита от лавины
Кэш помогает ускорить частые чтения и защитить базу данных от пиков. Но если кэш настроен «как попало», он сам становится причиной инцидентов: массовое истечение ключей, лавина запросов в БД, ситуации «то есть, то нет».
Сначала договоритесь, что именно кэшируете и зачем. Хорошие кандидаты: справочники, права доступа, карточки товаров, результаты тяжелых отчетов. Плохие кандидаты: то, что меняется каждую секунду и критично по точности, например баланс или статус транзакции.
По способу записи обычно выбирают одно из трех. Cache-aside (приложение само читает из кэша, при промахе берет из БД и кладет в кэш) часто хорошо подходит для on-prem. Write-through (пишем сразу в кэш и в БД) дает более свежие чтения, но сложнее и дороже. Write-behind (сначала в кэш, потом в БД асинхронно) рискован, если потеря данных недопустима.
TTL и прогрев без массового истечения
TTL должен отражать смысл данных: для справочников это минуты или часы, для динамики - секунды. Добавьте джиттер (случайную прибавку или убавку к TTL), чтобы ключи не истекали одновременно и не создавали пик.
Прогрев делайте только для действительно «горячих» ключей. Например, после перезапуска узла заранее заполните кэш топовыми справочниками и ролями, а остальное пусть наполняется по мере обращений.
Защита от лавины и план при падении кэша
Когда ключ истек, сотни запросов могут одновременно пойти в БД. Работают простые приемы: single flight (один запрос пересчитывает значение, остальные ждут), короткая блокировка на ключ с таймаутом, soft TTL (отдавать слегка устаревшее значение, пока идет пересчет), ограничение параллелизма к БД при промахах, негативное кэширование для «не найдено».
Если кэш недоступен, включайте «обход на БД», но с ограничениями: rate limit, очередь, упрощенные ответы для тяжелых страниц. Это часть отказоустойчивости on-prem приложения: лучше временно замедлиться и урезать второстепенное, чем уронить базу и весь сервис.
Консистентность: что можно ослабить и как не потерять данные
Консистентность - это договоренность: какие данные обязаны быть точными прямо сейчас, а какие могут быть чуть устаревшими. Для отказоустойчивости on-prem приложения важно заранее определить эти правила, иначе при сбоях кэша или узла вы получите то двойные списания, то жалобы на «пропавшие» изменения.
Где нужна строгая консистентность
Строгая консистентность нужна там, где ошибка сразу превращается в финансовый или юридический риск: платежи, лимиты, права доступа, подтверждение заказов, выдача токенов. Такие операции должны опираться на источник истины (обычно БД) и защищаться от повторов.
В остальном часто достаточно «умеренно устаревших» данных: каталог товаров, лента новостей, список доступных слотов, агрегированные метрики. Эти части можно отдавать из кэша даже при задержке обновления, если вы заранее приняли допустимое окно устаревания.
Как не потерять данные при кэше и повторах
Главный риск - рассинхронизация «кэш-DB» и двойная запись. Не делайте кэш вторым источником истины. Если запись прошла в БД, кэш должен либо пересчитываться из БД, либо обновляться по четкому правилу.
Практики, которые работают:
- Идемпотентность для записи: у запроса есть idempotency key (например, UUID операции). Повтор после таймаута не создает дубль, а возвращает уже созданный результат.
- Инвалидация по событию: после коммита в БД публикуете событие «объект обновлен», а читатели сбрасывают кэш по ключу.
- TTL как страховка: даже если событие потерялось, запись в кэше сама устареет.
- Версионирование: храните версию сущности (или timestamp обновления). Если в кэше версия старее, вы не принимаете ее как актуальную.
- Write-through осторожно: если обновляете кэш вместе с БД, делайте это после коммита и будьте готовы к тому, что кэш обновится не всегда.
Пример: в on-prem системе на кластере серверов (например, в стойках уровня GSE S200) узел приложения перезапускается, клиент повторяет запрос «создать заявку». При идемпотентности заявка не дублируется, а кэш по событию обновляет список заявок. Если событие не дошло, TTL гарантирует, что список исправится сам.
Чтобы не спорить в проде, задокументируйте допуски: что может быть устаревшим, на сколько секунд или минут, и что пользователь увидит (например, «список обновится через 30 секунд», «статус платежа только из БД»).
Деградация функций: как сохранить сервис при отказах компонентов
Деградация функций - заранее продуманный режим работы, когда часть возможностей выключается, но «ядро» сервиса остается доступным. Идея простая: лучше дать базовую операцию за 1-2 секунды, чем держать соединение 30 секунд и все равно упасть.
Сначала зафиксируйте уровни деградации и что именно считается «ядром». Например, для внутреннего портала это вход, просмотр карточки, создание заявки. А рекомендации, история, подсказки, расширенный поиск и тяжелые дашборды можно отключать первыми.
Режимы удобно описать так:
- Норма: доступны все функции, кэш и внешние зависимости работают.
- Легкая деградация: выключаем второстепенное, оставляем чтение и создание.
- Сильная деградация: отключаем тяжелые операции (поиск, отчеты), оставляем базовые операции и упрощенные экраны.
- Аварийный режим: только критичные действия, остальное закрыто с понятным сообщением.
Дальше важно, чтобы сбой одного компонента не «поджег» остальные. Нужны короткие таймауты и лимиты, чтобы запрос быстро завершался, а не копил висящие потоки. Circuit breaker помогает перестать дергать зависимость, которая уже «лежит», и переключиться на запасной сценарий (кэш, упрощенный ответ, очередь).
Практический пример: поиск зависит от отдельного сервиса и кэша. Если кэш недоступен, вы переключаете поиск в режим «минимум» или временно убираете его из интерфейса, но оформление заявки продолжает работать.
Что стоит подготовить заранее: таймауты на каждый вызов зависимости и общий лимит времени на запрос, circuit breaker с понятными порогами и временем восстановления, очередь для не срочных задач (уведомления, индексация), понятные сообщения пользователю, безопасные повторы (идемпотентность или ключ запроса).
Частые ошибки в сессиях и кэше, которые всплывают в проде
Самая частая проблема со state - он незаметно разрастается. В сессию складывают профили, права, корзины, результаты запросов, и все это лежит в памяти конкретного узла. В момент рестарта или аварии пользователь «вылетает», а нагрузка прыгает, потому что каждый запрос снова пересчитывает то, что раньше брал из сессии.
Sticky sessions часто воспринимают как страховку, хотя это скорее удобный костыль. Пока узлы живы, все выглядит стабильно. Но при падении одного сервера часть пользователей попадает на другой, где их сессии нет. Без регулярных тестов отказа (выключили узел, проверили логин, корзину, оформление) такие сценарии обнаруживаются уже в проде.
С кэшем типовая ошибка - один TTL «на все». Данные с разной природой (справочники, авторизация, остатки, тарифы) протухают одновременно, и кэш «падает в ноль». Если еще и нет джиттера, вы получаете лавину запросов к БД или внешним сервисам.
Отдельная категория - поведение при сбоях. Нет таймаутов, ретраи бесконечные или слишком агрессивные, и проблема умножается: вместо одного медленного компонента падает весь контур. Проверьте, что в коде и клиентах есть предохранители: таймауты на каждый сетевой вызов и обращения к кэшу, ограниченные ретраи с паузой и общим лимитом по времени, защита от thundering herd (лок на ключ, single flight, очереди), понятный фолбэк.
И самая дорогая ошибка - кэш становится «источником истины». Если критичные данные живут только в кэше, то рестарт, очистка или смена ноды превращаются в потерю данных. Правило простое: кэш ускоряет, но не хранит то, что нельзя потерять.
Короткий чеклист перед релизом и нагрузочными тестами
Перед релизом полезно прогнать несколько проверок, которые быстро показывают, выдержит ли приложение сбой узла, проблемы с кэшем и пиковую нагрузку. Лучше делать это на стенде, максимально похожем на прод, и фиксировать результаты: что ломается, сколько длится восстановление, какие функции надо «урезать» при сбоях.
Быстрые проверки отказоустойчивости
Проверьте, что можно перезапустить один узел без «побочных эффектов» для пользователя. Простой сценарий: пользователь вошел, положил товар в корзину, открыл вторую вкладку и делает еще пару действий. В этот момент перезапускается один из узлов. Ожидаемое поведение: логин не слетает, корзина сохраняется, а повтор запроса не приводит к дублям.
Еще одна обязательная проверка: что происходит, когда кэш недоступен или отвечает медленно. Нужны жесткие таймауты и понятное поведение по умолчанию: показывать данные чуть «старее», отключать второстепенные блоки, но не вешать весь запрос. Замерьте, как меняются задержки и сколько запросов уходит в базу при деградации.
Нагрузка: что ломается первым
Под нагрузкой часто всплывает лавина при истечении ключей: много запросов одновременно пытаются пересчитать одно и то же. Проверьте, что есть защита (разнесение TTL с джиттером, блокировка на пересчет, stale-while-revalidate), и что пересчет не забивает пул соединений к базе.
Отдельно проверьте идемпотентность критичных POST-операций (оплата, создание заявки, списание, резерв). Смоделируйте повтор запроса из-за ретрая балансировщика или клиента и убедитесь, что результат не дублируется.
В конце убедитесь, что мониторинг и алерты действительно помогают: есть метрики задержек (p95/p99), доля ошибок, таймауты кэша и БД, длины очередей, а также понятные пороги. Если у вас on-prem инфраструктура на своем железе, проверьте, что алерты приходят раньше, чем пользователи успевают заметить проблему.
Пример из жизни: как пережить падение узла и проблемы с кэшем
Утро, 9:05. В госоргане сотрудники массово заходят во внутренний портал: табель, заявки, согласования. Пик длится 20-30 минут. Приложение работает on-prem в двух узлах за балансировщиком, рядом отдельный кластер кэша. База данных одна, и у нее уже есть привычка «тяжелеть» на пиках.
В этот день один узел приложения падает (например, из-за утечки памяти). Почти одновременно кэш начинает отвечать медленнее: растет очередь запросов, часть операций записи в кэш не успевает. Пользовательский эффект зависит от того, как устроены сессии.
Если включены sticky sessions и сессия хранится только в памяти узла, часть людей сразу видит разлогин или потерю черновика. Они жмут «войти» еще раз, делают повторы запросов и тем самым добивают кэш и базу. Балансировщик уводит новых пользователей на живой узел, но «приклеенные» к упавшему теряют состояние.
Если sticky sessions нет, а сессии вынесены в общее хранилище (кэш или отдельный session store), падение узла чаще выглядит как короткая пауза и один повтор запроса. Пользователь остается авторизован, а живой узел подхватывает его сессию.
Дальше спасает деградация. Как только мониторинг видит рост ошибок кэша и задержек, приложение временно отключает вторичные блоки: ленту новостей, виджеты статистики, автоподсказки, фоновые пересчеты. Важное остается: вход, основные формы, отправка заявок. Если кэш не отвечает, читающие функции переходят в упрощенный режим (например, без персонализации), а записи в критичных местах идут напрямую в БД с ограничением частоты.
Понять, что план сработал, помогают метрики: доля 5xx и таймаутов по ключевым ручкам (логин, отправка формы), p95 времени ответа на них, процент принудительных разлогинов и пересозданий сессий, hit ratio и задержки кэша, число ошибок операций, нагрузка на БД (QPS, блокировки, рост времени запросов).
Если при падении узла пользователи в основном продолжают работать, а БД не уходит в «красную зону», значит выбранная схема state и деградации держит удар.
Следующие шаги: план внедрения и что проверить в инфраструктуре
Чтобы отказоустойчивость on-prem приложения не осталась на бумаге, начните с короткого плана работ. Цель простая: понять, где живет state, как он переживает сбои, и что будет с пользователем, если один компонент пропадет.
Сначала соберите карту компонентов и зависимостей. Не нужно рисовать идеальную архитектуру. Важнее честно отметить, где у вас хранится состояние: сессии, кэш, локальная память сервиса, файлы, очереди, фоновые задачи. Обычно хватает 2-3 самых рискованных мест, которые и ломают весь опыт.
Дальше зафиксируйте последовательность внедрения:
- Выберите 2-3 точки state, от которых зависят логин, корзина, права доступа или платежи.
- Опишите, что происходит при падении узла: как восстанавливается сессия, что делаем со sticky sessions, что видит пользователь.
- Определите режимы деградации: что отключаем первым, что оставляем всегда.
- Добавьте «правила экономии»: при росте ошибок или задержек уменьшаем нагрузку, ужимаем таймауты, включаем упрощенные ответы.
Параллельно запланируйте тесты отказов как повторяемую процедуру: выключение узла приложения, отключение кэша, искусственные задержки сети между сервисом и хранилищем. На таких тестах быстро видно, выдерживает ли отказоустойчивость on-prem приложения реальность, или держится на удаче.
Что проверить в on-prem инфраструктуре
Устойчивость сессий и кэша упирается в железо и базовую платформу: есть ли резервирование, кластер, запас по CPU, RAM и дискам, отдельные сети для хранения и сервисов, понятные лимиты и мониторинг.
Практический ориентир: если при потере одного узла вы не можете держать нужную нагрузку, деградация будет не «аккуратной», а аварийной.
Если нужен внешний взгляд на схему и подбор серверов под on-prem, это часто делают вместе с системной интеграцией. У GSE.kz, помимо поставки и интеграции, есть 24/7 поддержка и опыт построения инфраструктуры на отечественном оборудовании. Это удобно для организаций с требованиями к локальному производителю и прозрачности поставок.
FAQ
Почему при сбое одного узла меня разлогинивает или пропадает корзина?
Чаще всего теряется то, что хранится в памяти конкретного узла: сессия, локальный кэш, счетчики и временные шаги формы. При перезапуске или переключении балансировщика пользователь попадает на другой узел, а состояние «осталось» на старом, поэтому возникают разлогин, пустая корзина и непонятные повторы операций.
Стоит ли включать sticky sessions в on-prem кластере?
Sticky sessions оправданы как временная мера, когда приложение хранит state в памяти и быстро переделать нельзя. Но при падении узла часть пользователей неизбежно потеряет сессию, а балансировка становится хуже, поэтому лучше сразу держать план миграции на общий session store или токены.
Что именно можно хранить в сессии, чтобы не было сюрпризов при рестарте?
Базовое правило: держите в сессии только идентификаторы и минимальные флаги, а все «тяжелое» храните в базе или отдельном надежном хранилище черновиков. Тогда перезапуск узла не обнулит прогресс, а новая нода подхватит пользователя без потерь.
Что выбрать для сессий: общий стор, токены или базу данных?
Если данных в сессии мало и их не нужно быстро отзывать, удобны подписанные токены, потому что любой узел может их проверить. Если нужны сложные сценарии, отзыв, хранение шагов процесса или централизованный контроль, проще использовать общий стор сессий, но с короткими таймаутами и понятным поведением при недоступности.
Как настроить кэш, чтобы он не создавал инциденты сам по себе?
Начните с того, что кэш — ускоритель, а не источник истины, и падение кэша не должно ломать критичные операции. Выставьте разные TTL по смыслу данных и добавьте джиттер, чтобы ключи не истекали одновременно и не вызывали лавину запросов в базу.
Как избежать thundering herd, когда один ключ истек и все пошли в БД?
Сработают простые защиты: single flight на пересчет значения, короткий лок на ключ с таймаутом и возможность отдавать слегка устаревшие данные, пока идет обновление. Дополнительно ограничьте параллелизм запросов к базе при промахах кэша, чтобы не «забить» пул соединений.
Что делать, если кэш стал медленным или недоступным?
По умолчанию лучше перейти на чтение из базы с ограничениями и урезать тяжелые функции, чем пытаться «перетерпеть» и уронить БД. Важно заранее задать жесткие таймауты на кэш и зависимости и включать режим деградации с упрощенными ответами и rate limit.
Где нужна строгая консистентность, а где можно позволить устаревшие данные?
Сразу определите, где нужна строгая точность: платежи, права доступа, подтверждения операций и лимиты должны идти из источника истины и быть защищены от повторов. Остальное можно отдавать чуть устаревшим, если вы заранее приняли допустимое окно и объяснили его в логике сервиса.
Как защититься от дублей при ретраях и непонятных статусах операций?
Сделайте критичные записи идемпотентными с ключом операции, чтобы повтор после таймаута не создавал дубль. Обновляйте кэш по событию после коммита в БД и держите TTL как страховку, чтобы даже при потере события данные со временем исправились сами.
Какие тесты нужно сделать перед релизом, чтобы убедиться в отказоустойчивости?
Проверьте практические сценарии: пользователь логинится, заполняет форму, вы перезапускаете один узел и продолжаете на другом без потери черновика и разлогина. Отдельно отключите кэш или добавьте задержки и посмотрите, что система деградирует управляемо, а метрики p95/p99, доля таймаутов и нагрузка на БД не уходят в критическую зону.