Open source NTP: точное время и контроль дрейфа в сети
Open source NTP: как выстроить иерархию времени в распределенной сети, что логировать, как измерять дрейф и быстро находить проблемы на узлах.
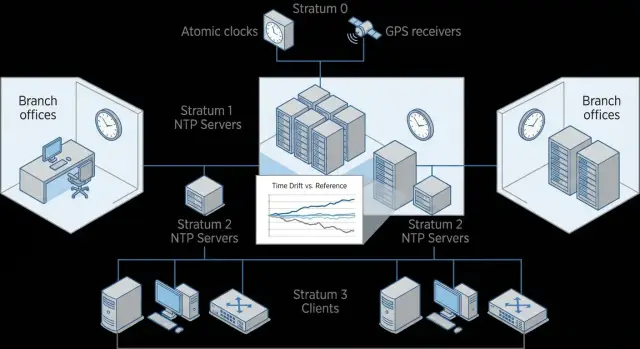
Зачем в распределенной сети нужно единое точное время
Единое точное время в распределенной сети нужно не ради «красоты». Оно делает события сравнимыми: что, где и когда произошло. Без этого журналы, отчеты и расследования превращаются в набор догадок.
Первое, что ломается при расхождении времени, - доверие к логам. Один сервер пишет «вход выполнен», другой в тот же момент фиксирует «вход отклонен», а между площадками это выглядит как разные дни. Для безопасности это критично: SIEM, EDR и обычная корреляция событий держатся на таймлайне.
Дальше страдают учет и процессы. Сроки действия сертификатов, билеты Kerberos, одноразовые коды, расписания задач, репликации и резервные копии завязаны на время. Если часы на рабочих местах уходят вперед, сотрудники внезапно «теряют доступ». Если назад - появляются спорные операции и «пропавшие» действия в отчетах.
Частые симптомы, которые легко списать на сеть или «глюки системы»: ошибки аутентификации и разлогинивания, несходящиеся события в логах между площадками, проблемы с TLS («сертификат еще не действителен» или «уже истек»), странные задержки в расписаниях заданий и мониторинге.
Хорошая новость: правильно построенная иерархия времени NTP и open source инструменты обычно решают большую часть проблем. Они дают единый источник, дисциплинируют часы и позволяют видеть дрейф.
Но есть и ограничения. NTP не вылечит плохие аппаратные часы, «проседающие» каналы с большой задержкой и джиттером, а также блокировки UDP 123 на межсетевых экранах. В таких случаях приходится одновременно улучшать транспорт, выбирать правильные уровни серверов времени и закладывать контроль дрейфа.
Простой пример: в организации с тремя площадками бухгалтерия на одной закрывает день, а склад на другой видит операции «из будущего». После выравнивания времени споры исчезают, потому что все системы начинают говорить на одном языке времени.
Коротко про NTP: термины, уровни и источники времени
NTP (Network Time Protocol) нужен не только для того, чтобы часы «примерно совпадали». Он дает прогнозируемую точность и, главное, понятные показатели качества синхронизации. В большинстве сетей достаточно open source NTP на серверах и рабочих станциях, но важно понимать базовые термины.
SNTP часто называют «упрощенным NTP». На практике разница в том, что SNTP обычно работает без сложных алгоритмов отбора и оценки источников и хуже переносит нестабильные каналы и скачки задержек. Для рабочих мест в простых условиях SNTP иногда допустим, но для серверов, журналов безопасности и распределенных площадок лучше полноценный NTP.
Термины, которые реально помогают
В статусе службы времени чаще всего смотрят не «все ли запущено», а цифры:
- Stratum: «уровень» близости к эталону. Stratum 1 получает время от GNSS или атомных часов, stratum 2 синхронизируется от stratum 1 и так далее.
- Offset: насколько ваш узел опережает или отстает от выбранного источника (обычно в миллисекундах).
- Jitter: насколько «прыгает» offset во времени, показатель стабильности канала.
- Drift: насколько уходит собственная частота часов сервера, если оставить его без коррекции.
Если offset небольшой, но jitter высокий, то время «в среднем правильное», но метки в логах будут гулять. Это особенно заметно, когда часть систем в одном ЦОД, а часть в филиале по перегруженному VPN.
Источники времени: какие бывают и почему одного сервера мало
Источники делятся на внешние (публичные или партнерские), внутренние (ваши опорные серверы) и аппаратные, например GNSS (GPS/ГЛОНАСС) приемники. Внутри компании обычно делают 2-3 опорных сервера и дают им несколько независимых источников.
Один сервер времени на всю компанию - риск. Это единая точка отказа и единая точка ошибки. Достаточно сбоя сети, неправильного времени после перезагрузки или атаки на источник, и «поедут» журналы, Kerberos/AD, сертификаты и задачи по расписанию. Лучше сразу закладывать резерв: два опорных узла в разных стойках или площадках, например на отдельных серверных системах в вашем ЦОД.
Как построить иерархию времени: простая и надежная схема
Самая понятная модель для open source NTP выглядит как цепочка доверия: внешние источники времени -> опорные серверы (core) -> локальные серверы на площадках -> клиенты (серверы, рабочие места, сетевое оборудование). Чем ближе узел к «центру», тем строже требования по надежности и наблюдаемости.
Базовая схема и сколько серверов нужно
Хорошее правило для каждого уровня - минимум три независимых источника. Это снижает риск, что один неверный источник «утащит» всех в неправильное время.
Практичный минимум:
- опорный уровень: 2-3 сервера времени в центральном ЦОД или на основной площадке
- площадка/филиал: 1-2 локальных сервера времени (хотя бы один, если ресурсов мало)
- клиенты: синхронизация только с локальными серверами своей площадки
Если сеть небольшая, можно начать с двух опорных серверов, но третий источник все равно нужен (например, отдельный внешний источник или еще один сервер в другой стойке/зале). Важно, чтобы «независимость» была реальной: разные машины, разные каналы, по возможности разные внешние источники.
Размещение и филиалы с нестабильными каналами
Опорные серверы держите там, где лучше питание, климат и мониторинг. Локальные серверы времени ставьте ближе к потребителям, чтобы уменьшить задержки и влияние качества канала.
Если в филиале связь нестабильна, не заставляйте все рабочие места ходить через WAN в центр. Поднимите локальный сервер времени в филиале, который синхронизируется с центром, а клиенты берут время только у него. При обрывах он продолжит раздавать время «на удержании» (по своей частоте), и у вас не будет скачков времени на каждом ПК.
Небольшой пример: три офиса, у одного канал «плавает». В центре работают 3 опорных сервера, в проблемном офисе один локальный сервер берет время у центра, а все ПК и серверы офиса синхронизируются только с ним. Так дрейф будет заметен и управляем, но не превратится в хаос на клиентах.
Open source инструменты и роли серверов времени
Для распределенной сети чаще всего хватает двух вариантов: chrony и классического ntpd. Оба синхронизируют время, но работают по-разному, и это влияет на стабильность.
Chrony обычно удобнее в современных сетях: он быстрее «схватывает» правильное время после перезагрузки, лучше переживает нестабильные каналы и точнее держит часы на виртуальных машинах и ноутбуках. Ntpd часто выбирают там, где он уже исторически используется, есть готовые шаблоны конфигураций и строгие требования к совместимости со старыми системами.
Роли можно построить по-разному. Идеальный вариант - выделенные внутренние NTP-серверы, которые берут время от внешних источников, а все остальные узлы синхронизируются только с ними. Если выделять отдельные машины не получается, роль NTP можно дать существующим инфраструктурным серверам, но с условиями: они должны быть стабильными, постоянно включенными и не перегруженными.
К железу и ОС требования простые, но важные: стабильные аппаратные часы, исправное питание и предсказуемая сеть. Сервер, который часто уходит в сон, «скачет» по нагрузке или теряет пакеты, станет плохим эталоном. На практике лучше подходят постоянные серверы или надежные платформы в стойке, чем рабочие станции.
Собственный сервер времени особенно нужен там, где цена ошибки высокая: в доменной инфраструктуре (например, AD), в базах данных и очередях сообщений (важен порядок событий), в SIEM и централизованном логировании (нужен общий таймлайн), в VDI и терминальных фермах, а также в критичных бизнес-сервисах, где аудит и расследования завязаны на точные метки.
Если вы разворачиваете новые серверы и рабочие места (например, на отечественных платформах и в нескольких филиалах), заранее определите, какие узлы будут «опорными», и зафиксируйте их роли в документации. Это избавит от ситуации, когда часть сети случайно синхронизируется «откуда получится», и дрейф накапливается незаметно.
Пошаговая настройка: от опорных серверов до клиентов
Настройку начинайте не с конфигов, а с карты: где у вас площадки, какие каналы связи между ними, и где можно разместить опорные узлы времени. Для распределенной сети обычно достаточно 2 опорных площадок (основная и резервная), чтобы переживать сбои канала и плановые работы.
Дальше помогает простой порядок действий:
- Выберите источники времени: минимум 3-4 независимых внешних источника (или GNSS/радиочасы, если есть), плюс список внутренних узлов, которые будут получать время первыми.
- Настройте опорные NTP-серверы: разрешайте запросы только со своих подсетей, закройте управление извне, включите несколько upstream-источников и запретите любым клиентам становиться для вас источником.
- На каждой площадке поднимите локальный сервер времени: пусть он синхронизируется с двумя опорными серверами, а клиенты берут время только у него.
- Настройте клиентов (серверы и рабочие места): укажите 2-3 внутренних сервера времени, включите автосинхронизацию при старте и после выхода из сна, задайте одинаковую политику на всех типовых образах.
- Проверьте состояние и зафиксируйте базовую точку отсчета: измерьте текущий offset, задержку и выбранный источник, затем сохраните результаты для будущих сравнений.
Практический совет: на серверах в ЦОДе держите роль локального сервера времени на выделенных VM или отдельных узлах, чтобы обновления приложений не мешали службе времени.
Для первичной проверки обычно хватает двух команд: убедиться, что синхронизация активна, и посмотреть источники и текущий сдвиг. Зафиксируйте значения (время, hostname, offset, source, reach) в заметке или тикете - потом это сильно ускоряет поиск дрейфа.
Что логировать и какие метрики реально помогают
Даже хорошо настроенный NTP со временем начинает «плыть» из-за каналов связи, перегрузки сервера, виртуализации или проблем с источником времени. Поэтому полезно заранее договориться, что считать инцидентом и по каким цифрам понимать, что все еще нормально.
В первую очередь фиксируйте события, которые меняют картину синхронизации: переключение на другой источник, резкие скачки offset, уход в состояние unsynchronized и возврат в синхронизацию. Именно по ним проще объяснить, почему журналы безопасности на разных площадках «разъехались».
Чтобы логи помогали, записывайте не только факт ошибки, но и контекст. Минимальный набор, который стоит собирать с NTP-сервера и важных клиентов:
- текущий offset (смещение времени) и максимум за интервал
- jitter (разброс) и delay (задержка до источника)
- выбранный источник (peer) и его stratum
- статус синхронизации (synced/unsynced) и причина смены источника
- характер корректировок: step или плавная коррекция
Хранить такие записи лучше так, чтобы их можно было сопоставлять между площадками: единый формат времени (UTC), единые имена хостов и одинаковая периодичность (например, срез раз в 1-5 минут). Если площадок несколько, добавьте метку площадки и роль узла (опорный сервер, распределительный, клиент).
Пороги для алертов задавайте осторожно, иначе будет много шума. Практичный вариант - реагировать на устойчивую проблему:
- unsynchronized дольше 2-5 минут
- рост jitter выше привычного уровня в 3-5 раз на протяжении 10-15 минут
- offset стабильно выше порога (например, 100-500 мс для серверов) несколько измерений подряд
- частые переключения источника (flapping) больше N раз за час
Как проверять дрейф на серверах и рабочих местах
Проверять время стоит регулярно, иначе проблемы всплывают в самый неподходящий момент: при разборе инцидента, сверке логов или работе с сертификатами. Минимум: критичные серверы (аутентификация, базы, журналы безопасности) проверяйте ежедневно, обычные серверы - раз в неделю, рабочие места - раз в месяц или при жалобах на вход в системы и подписи.
Методика простая: сравнивайте не с «интернетом», а с вашим локальным эталоном. Клиент должен показывать небольшое смещение (offset) и стабильный тренд. Если вы используете Chrony, удобно смотреть общее состояние и список источников.
chronyc tracking
chronyc sources -v
В tracking обращайте внимание на offset и частоту (frequency). Разовый небольшой offset не страшен, важнее, растет ли он от проверки к проверке. Заведите простой журнал: дата, offset, jitter, выбранный источник. Через 1-2 недели видно, уходит ли машина «плавно» или проблема случается всплесками.
Чтобы отличить дрейф часов от сетевых проблем, смотрите на характер отклонений:
- плавный уход: offset медленно растет в одну сторону, jitter обычно низкий
- прыжки: offset то плюс, то минус, часто меняется выбранный источник
- после перезагрузки стало хуже: проверьте настройки, запрет синхронизации и аппаратные часы
- удаленная площадка по плохому каналу: jitter выше, но тренд может быть стабильным
Jitter показывает «неровность» измерений. Высокий jitter чаще связан с сетью: задержки, перегрузка, Wi-Fi, VPN. Если при этом источник постоянно переключается, обычно виноваты нестабильные upstream или слишком «разношерстный» набор источников у клиентов. В таких случаях лучше оставить клиентам 2-3 надежных локальных сервера и убедиться, что они сами синхронизируются устойчиво.
Практичный ориентир: если на рабочем месте offset скачет в пределах секунд - это уже повод разбираться. Если на сервере критичного сервиса дрейф заметен даже в десятках миллисекунд и растет, проверяйте источник, сеть до него и состояние самого сервера времени.
Частые ошибки и ловушки при внедрении NTP
Самая опасная ошибка - открыть NTP-сервер наружу без ограничений. Публично доступный UDP 123 быстро становится мишенью: сервер могут использовать в отраженных атаках, а у вас появятся всплески трафика и задержки синхронизации. Минимум - ограничить, кто имеет право опрашивать сервер, и разделить внешние и внутренние роли.
Вторая типовая проблема - один источник времени или один сервер без резерва. Пока он жив, все выглядит хорошо, но при отказе клиенты начинают «искать время» где попало или застывают на старом. В итоге логи перестают сходиться, а инциденты сложно разбирать. Даже в небольшой сети стоит иметь минимум два независимых источника и два внутренних сервера времени.
Часто систему ломают слишком агрессивной корректировкой времени на критичных узлах. Резкий скачок часов может уронить Kerberos, сломать проверку сертификатов, испортить порядок событий в журналах и сбить расписания задач. Там, где важна непрерывность, безопаснее избегать больших шагов времени и заранее продумать, как вы будете исправлять большой увод.
Еще одна ловушка - смешивание разных цепочек времени в одной сети. Например, часть машин получает время от внутренних серверов, а часть от случайных внешних. В итоге в одной подсети появляются «острова» с разной точностью. При разборе инцидента это выглядит так, будто события происходили в разном порядке.
Не забывайте и про человеческий фактор: часовые пояса и ручные правки. Пользователь может поставить «не тот» часовой пояс или вручную подкрутить часы, и рабочая станция начнет конфликтовать с политиками домена и журналированием.
Перед вводом в эксплуатацию полезно проверить базовые вещи:
- NTP не доступен из интернета без явных правил
- есть резервирование источников и внутренних серверов
- ручная смена времени на рабочих местах запрещена там, где это возможно
- у всех площадок единая цепочка синхронизации
- есть план действий при большом дрейфе: кто отвечает и что делает
Простой пример: у компании 3 площадки, и на одной периодически «плавает» канал. Если там оставить один сервер времени и разрешить рабочим станциям брать время снаружи, вы получите разные часы в одном домене и хаос в логах. Если же площадка синхронизируется только с двумя центральными серверами и имеет понятные ограничения, проблемы будут локальными и предсказуемыми.
Быстрый чеклист: что проверить за 15 минут
Если время в сети уже «вроде работает», быстрый аудит помогает поймать самые опасные ошибки: один источник на весь периметр, открытый наружу NTP и тихий дрейф на рабочих местах.
5 проверок, которые дают максимум пользы
-
Наверху иерархии не один источник. В идеале есть несколько независимых опорных источников, и сервер времени не «залипает» на одном.
-
На каждой площадке есть локальная точка времени или понятный план отказа. Если канал до центра плохой, клиенты должны брать время у ближайшего сервера, а не дергать удаленный через WAN.
-
Экспозиция NTP ограничена. Доступ задается по адресам и сегментам: клиентам можно опрашивать, но не всем подряд и точно не «из интернета».
-
Пороги тревог зафиксированы. Нужны допустимый offset и лимит по времени «не синхронизирован».
-
Контроль регулярный, результаты сохраняются. Важны тренды, а не разовые цифры.
Мини-сценарий для самопроверки
Если филиал жалуется на «сломанную подпись» или «прыгающие» события в логах, сравните время на двух серверах и одном ПК, а затем посмотрите, к кому они синхронизируются. Часто оказывается, что сервер берет время по open source NTP от центрального узла, а рабочие места ушли на публичные источники или вообще потеряли синхронизацию.
Эти 15 минут обычно достаточно, чтобы понять: проблема в схеме, в доступах или в отсутствии нормального мониторинга дрейфа.
Пример из практики: 3 площадки и разные качества каналов
Ситуация: есть головной офис в Алматы, два филиала (один в городе, другой в регионе) и отдельный дата-центр. ДЦ подключен к офису по хорошему каналу, городской филиал живет на стабильном VPN, а региональный периодически ловит потери пакетов и скачки задержки.
Иерархию времени проще всего собрать так: в дата-центре держим 2 опорных сервера времени (stratum 1-2, в зависимости от источника), а на каждой площадке ставим по одному локальному серверу (stratum ниже), который раздает время всем клиентам в своей сети. На рабочих местах и прикладных серверах не надо тянуться в ДЦ напрямую. Они синхронизируются с локальным узлом и меньше зависят от качества канала.
В одном таком проекте регион начал жаловаться: «у нас подписи в документах не сходятся по времени, а в логах безопасности порядок событий странный». С open source NTP это часто выглядит как «время прыгает», но причина может быть в канале, источнике или в самих часах сервера.
Чтобы потом можно было доказать корень инцидента, заранее договоритесь, что логировать. Минимум, который реально помогает:
- offset и jitter на локальном сервере площадки
- reachability (reach) и смену выбранного источника
- статус синхронизации (synchronized/unsynchronized) и stratum
- скачки задержки до источников (delay)
- события перезапуска службы времени и ручные правки времени
Когда приходит жалоба, помогает короткий сценарий диагностики. Сначала смотрите локальный сервер филиала, а не клиентов: не потерял ли он источники (reach и смена peer), какой у него offset до ДЦ и до локальных клиентов, совпадают ли всплески delay по времени с инцидентом, не включена ли параллельно «вторая» синхронизация (другой сервис времени).
Отдельные серверы времени стоит выделять на корпоративном оборудовании, когда на площадке много критичных систем, плохой канал или строгие требования аудита. Так служба времени не конкурирует за ресурсы с прикладными нагрузками и проще проходит проверки.
Следующие шаги: как закрепить результат и упростить поддержку
Чтобы NTP не остался разовой настройкой, зафиксируйте, как именно в сети устроено время. Самый полезный артефакт - простая «карта времени», которую понимают и ИТ, и ИБ.
Обычно в нее включают: какие внешние источники используются и какие из них основные; какие NTP-серверы выполняют роль опорных и какой у них stratum; кто отвечает за изменения и как согласуются работы; окна изменений и порядок отката; где хранится конфиг и какие параметры считаются эталоном.
Дальше проще идти как маленьким проектом, а не массовой правкой. Пилот на одной площадке покажет, как ведут себя каналы связи, виртуализация и разные ОС. Практичная схема: выбрать одну площадку и 10-20 разнородных узлов, ввести опорные серверы времени и перевести клиентов на них, неделю наблюдать метрики, зафиксировать «золотые» настройки и масштабировать по площадкам. Отдельно заранее согласуйте, что делать при потере внешнего источника.
Чтобы результат держался годами, добавьте мониторинг и регулярные отчеты. ИТ обычно нужен контроль доступности и качества синхронизации, а ИБ - доказуемость: кто был источником времени, какие были скачки, как быстро система вернулась в норму. Хорошая привычка - еженедельный короткий отчет по дрейфу и инцидентам (даже если их ноль).
Если по ходу работ становится ясно, что нужно связать NTP с общей архитектурой (сегментация, DC, резервирование, требования ИБ), это имеет смысл обсудить с интегратором заранее.
Когда точное время критично для аудита и расследований, помогает стандартизация опорных узлов: стабильные серверы, понятный жизненный цикл и поддержка. В проектах в Казахстане такую роль нередко закрывают решениями и интеграцией от GSE.kz (gse.kz), особенно если параллельно строится инфраструктура ЦОД или обновляется парк серверов и рабочих станций.
FAQ
Почему вообще важно единое точное время в распределенной сети?
Единое время делает события сравнимыми между серверами и площадками. Без него корреляция в SIEM/EDR, расследования и даже обычные отчеты превращаются в спор о том, «что было раньше», потому что метки времени расходятся.
Какие симптомы чаще всего указывают на проблемы со временем, а не на «глюки системы»?
Чаще всего первыми всплывают ошибки входа и разлогинивания, проблемы с TLS (сообщения про «сертификат еще не действителен» или «уже истек»), несходящиеся логи между площадками и странные задержки у заданий по расписанию. Если это происходит «волнами» и без видимых причин, почти всегда стоит проверить синхронизацию времени.
Что выбрать: NTP или SNTP?
NTP использует алгоритмы отбора и оценки источников и лучше переживает нестабильные каналы, задержки и скачки. SNTP может быть приемлем для простых рабочих мест, но для серверов, журналов безопасности и распределенных площадок безопаснее и стабильнее использовать полноценный NTP.
Что означают stratum, offset, jitter и drift и на что смотреть в первую очередь?
Stratum показывает «удаленность» от эталонного источника: чем меньше число, тем ближе к первичному времени. Offset — это текущее смещение ваших часов относительно выбранного источника, jitter — стабильность измерений (насколько скачет offset), drift — склонность собственных часов уходить, если оставить их без коррекции. На практике сначала смотрят offset и jitter: они быстрее всего показывают проблему.
Почему нельзя обойтись одним сервером времени на всю компанию?
Один сервер — это единая точка отказа и единая точка ошибки. Если он «потеряет» источники, загрузится неверным временем после перезагрузки или станет недоступен по сети, у вас одновременно поедут логи, аутентификация, сертификаты и расписания. Минимально закладывайте два внутренних сервера времени и несколько независимых upstream-источников.
Как правильно организовать время в филиале с нестабильным каналом?
Базовый подход — опорные серверы в центральной площадке и локальный сервер времени в каждом филиале, к которому ходят все клиенты филиала. Это снижает влияние WAN: при обрывах связи локальный сервер продолжит раздавать время «на удержании», и рабочие места не будут дергать центр и ловить скачки. Чем хуже канал, тем важнее локальная точка времени.
Что лучше использовать: chrony или ntpd?
Chrony обычно быстрее выходит в нормальную синхронизацию после перезагрузки и лучше работает на виртуальных машинах и при нестабильной сети. Ntpd часто выбирают из-за привычности и совместимости со старыми окружениями. Если вы строите новую схему и ожидаете «плавающие» каналы или много VM, chrony чаще дает более предсказуемый результат.
С чего начать внедрение иерархии NTP, если сейчас все настроено «как получилось»?
Начните с карты площадок и каналов связи, затем определите 2–3 опорных сервера и источники для них. После этого поднимите локальные серверы времени на площадках и переведите клиентов на них, запретив клиентам становиться источниками для других. В конце зафиксируйте базовые показатели (выбранный источник и типичные значения offset/jitter), чтобы потом видеть отклонения.
Что нужно логировать и мониторить, чтобы быстро находить дрейф и проблемы синхронизации?
Логируйте то, что объясняет, почему метки времени могли разъехаться: смену источника, переход в unsynchronized и возврат, скачки offset, рост jitter и задержки до источника. Полезно также фиксировать, была ли коррекция плавной или с резким шагом, потому что шаг времени часто ломает аутентификацию и порядок событий в логах.
Какие ошибки при настройке NTP самые опасные и как их избежать?
Закрывать NTP наружу без ограничений и разрешать запросы «от всех» — опасно и для безопасности, и для стабильности. Вторая частая ошибка — смешивать цепочки времени, когда часть машин берет время у внутренних серверов, а часть у случайных внешних источников. Еще одна проблема — резкие шаги времени на критичных узлах: это может сломать Kerberos, проверки сертификатов и расписания, поэтому такие корректировки нужно заранее продумывать.