Open source CMDB для 500-2000 устройств без мертвого реестра
Open source CMDB для 500-2000 устройств: как описать сущности, выбрать источники данных и настроить правила актуализации, чтобы база не устаревала.
Почему CMDB часто умирает через 3 месяца
«Мертвый реестр» - это CMDB, которая формально существует, но ей никто не доверяет. Данные выглядят правдоподобно, но не совпадают с реальностью: устройства уже заменили, владельцы сменились, сервисы переехали, а записи остались прежними. В итоге база становится местом для отчетности, а не для работы.
На масштабе 500-2000 устройств проблема ускоряется. В Excel еще можно удерживать список на 150-300 единиц, когда изменения редкие и их делает один человек. Дальше начинаются постоянные движения: новые рабочие места, ремонты, выдача техники в филиалы, переустановка ОС, изменения в сети. Таблица превращается в очередь правок, где непонятно, какая версия последняя и кто вообще должен обновлять строку.
CMDB «на минималках» должна сначала закрывать несколько приземленных задач, которые дают пользу сразу:
- быстро понять, что это за устройство и где оно находится
- знать ответственного и контакт, чтобы решать инциденты
- видеть базовые связи: устройство - пользователь - отдел - сервис (хотя бы на уровне «какой системе это важно»)
- иметь признаки актуальности: когда данные получены и чем подтверждены
Частая причина смерти - завышенные ожидания. Если пытаться сразу описать все отношения между всеми системами, лицензиями, кабелями и «как оно устроено по ITIL», команда утонет в моделировании. Вторая ловушка - ждать, что «CMDB сама заполнится» без договоренности о первичных источниках: где истина про имя хоста, где истина про владельца, где истина про местоположение.
Полезная настройка на старте: open source CMDB для 500-2000 устройств - это не энциклопедия инфраструктуры, а рабочая карта. Она должна помогать поддержке и админам каждый день. Если этого нет, через 3 месяца ее перестают обновлять, и она снова становится реестром «для галочки».
Цели и границы: что считать CMDB «на минималках»
CMDB «на минималках» нужна не для идеальной картины мира, а чтобы быстро отвечать на практичные вопросы: что это за устройство, где оно стоит, кто владелец, чем оно управляется и что сломается, если его отключить. Для масштаба open source CMDB для 500-2000 устройств это особенно важно: чем шире охват, тем дороже ручная поддержка.
Начните с границ. Выберите то, что вы готовы держать актуальным каждый день, и отложите остальное. Обычно «точно ведем» - серверы, виртуальные машины, сетевое оборудование, рабочие станции в критичных подразделениях, ключевые сервисы (почта, 1С, клиническая система, СКУД). «Пока не ведем» - расходники, каждый монитор, вся периферия, разовые тестовые стенды.
Как измерить успех
Метрики должны быть простыми и видимыми без «отчетного цирка»:
- Актуальность: доля CI с обновлением не старше X дней (например, 14).
- Полнота: доля CI с заполненными обязательными полями (владелец, локация, серийный номер или другой уникальный ID).
- Скорость ответа: сколько времени уходит, чтобы найти владельца и зависимости для инцидента.
- Расхождения: сколько конфликтов между источниками найдено за неделю и сколько закрыто.
Минимальные процессы, без которых база мертвеет
Нужны три договоренности: кто создает CI, кто имеет право менять ключевые поля, и что считается «истиной», если источники спорят. Плюс короткий цикл изменений: закупка или ввод в эксплуатацию создает запись, перемещение обновляет локацию, списание закрывает CI.
Термины тоже лучше зафиксировать заранее.
CI - то, что влияет на работу услуги.
Актив - то, что на балансе (не всегда CI).
Услуга - то, что важно пользователю (например, «доступ к медицинской системе»).
Практичный пример: в больнице с 1200 устройствами все ПК GSE в регистратуре могут быть активами, но CI становятся только те, что участвуют в критичном процессе и имеют владельца и поддержку.
Выбор open source платформы: на что смотреть без фанатизма
Open source CMDB для 500-2000 устройств обычно ломается не из-за «не той» платформы, а из-за дисциплины данных. Некому подтверждать записи, источники не определены, интеграции сделаны «на глаз».
Выбирать стоит прагматично: что быстрее даст живую базу, а не идеальную схему.
Какие классы решений бывают
Под вывеской CMDB часто выбирают один из трех типов систем:
Классическая CMDB фокусируется на сущностях и связях (оборудование, ПО, сервисы).
IPAM и DCIM сильны в сети, адресах, стойках и портах.
ITSM больше про заявки и изменения, а CMDB там часто идет «в комплекте».
На практике это означает: если главная боль - сеть и физическая инфраструктура, начинать удобнее с NetBox. Если нужен «справочник» с процессами и утверждениями, ближе iTop или CMDBuild. Если вы хотите, чтобы CMDB сразу жила рядом с заявками и инцидентами, часто проще GLPI.
Как выбрать без фанатизма
Смотрите не на количество сущностей «из коробки», а на то, как система поддержит вашу дисциплину данных:
- Права доступа и роли: кто может править, кто только смотреть, кто утверждает.
- API и интеграции: можно ли регулярно подтягивать факты из AD, виртуализации, сканеров, MDM.
- Импорт и массовые правки: CSV, шаблоны, сопоставление полей.
- Аудит изменений: кто и что изменил, можно ли расследовать спорные случаи.
- Жизненный цикл: статусы («в эксплуатации/на складе/списано») и простая валидация.
NetBox обычно выигрывает, когда нужен точный учет сети и железа без тяжелых процессов. iTop чаще выбирают, когда важны связи сервисов и контроль изменений. GLPI хорош, если вы стартуете с service desk и постепенно подтягиваете учет. CMDBuild подходит, когда нужна настраиваемая модель и формы под регламент.
Главный критерий простой: платформа должна легко «кормиться» из источников и поддерживать правила актуализации. Остальное донастраивается. Без интеграций и ответственности любая CMDB быстро превращается в реестр.
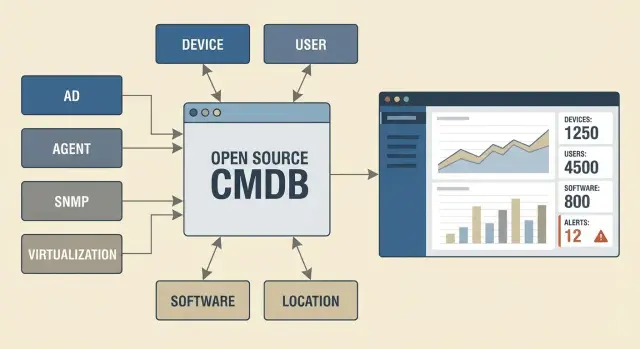
Сущности и связи: простая модель данных, которая живет
Для open source CMDB для 500-2000 устройств лучше начать с модели, которую реально поддерживать каждый день. Если сущностей слишком много, люди перестают заполнять карточки, и база превращается в архив догадок.
Минимального набора обычно хватает, чтобы закрыть большую часть запросов:
- Устройство (ПК, сервер, принтер, сетевое)
- Пользователь (сотрудник или роль, например «дежурная смена»)
- Локация (здание, этаж, кабинет или стойка)
- ПО (ключевые пакеты и версии)
- Сервис (например, «Почта», «1С», «Видеонаблюдение»)
Дальше важнее не количество карточек, а одинаковый минимум полей.
Для устройства: уникальный идентификатор (инвентарный номер или серийник), тип, модель, владелец/подразделение, статус жизненного цикла, дата последнего подтверждения.
Для пользователя: табельный номер или логин, подразделение, статус (работает или нет).
Для локации: код и ответственный за помещение.
Для ПО: название, версия, критичность.
Для сервиса: владелец сервиса и список ключевых компонентов.
Связи делайте только те, которые помогают принимать решения: устройство - пользователь (кто использует), устройство - сеть (сегмент или IP, если есть), сервис - компоненты (какие серверы, базы, приложения его поддерживают).
Пример: у вас 30 серверов и 900 рабочих мест. Если падает сервис «Бухгалтерия», вы быстро видите, какие серверы и какое ПО к нему относятся, и кто владелец.
Жизненный цикл лучше ограничить простыми статусами: «в эксплуатации», «на складе», «в ремонте», «списано». Правило простое: смена статуса обязательна при любом перемещении или выдаче.
На старте не стоит моделировать слишком глубоко. Обычно можно отложить:
- все порты, платы и серийники каждого компонента
- каждую мелкую зависимость между приложениями
- финансовый учет «до копейки» внутри CMDB
- «идеальные» диаграммы, которые никто не обновляет
- ручное заполнение того, что можно получать из систем учета
Источники данных: откуда брать факты, а не мнения
Главное правило для CMDB на минималках: в карточке должны жить только те поля, у которых есть понятный источник истины. Если поле нельзя регулярно подтвердить, оно быстро превращается в спор.
Удобно разделить данные на три слоя: идентификация (что это за объект), присутствие (он реально существует в сети/системе), управление (кто отвечает, где стоит, на каком основании используется).
Каталог и управление устройствами: AD и MDM
Из AD имеет смысл забирать имя компьютера, OU/группы, последнюю активность, владельца (если он ведется) и привязку к домену. Обновление - ежедневно. Поле «последний вход/активность» можно обновлять чаще, если важно быстро ловить «пропажи».
MDM (например, для ноутбуков и телефонов) дает более надежные факты: серийный номер, модель, версия ОС, статус соответствия политике, шифрование. Эти атрибуты полезно обновлять ежедневно, потому что они напрямую влияют на безопасность и поддержку.
Агентский сбор: когда он нужен
Агент оправдан, когда важно видеть состав железа, список ПО, версии, патчи и события. Для 500-2000 устройств это часто единственный способ получать точные данные по ПО без ручных опросов.
Но не собирайте «все подряд». Оставьте минимум: ОС и версия, серийник, CPU/RAM/диски, ключевые приложения (например, офис, браузер, VPN), и дата последнего отчета агента. Если отчета нет 14 дней - это сигнал, что устройству нельзя доверять как «актуальному».
Сеть: SNMP, DHCP, IPAM и факт присутствия
Сеть хорошо отвечает на вопрос «устройство реально было в инфраструктуре». DHCP и ARP-таблицы показывают, что MAC появлялся; SNMP подтверждает управляемые устройства (коммутаторы, принтеры, ИБП) и их базовые параметры.
Важно договориться, что считать фактом присутствия. Практичный вариант: объект считается «живым», если за последние N дней есть хотя бы один надежный сигнал (агент, MDM, DHCP/ARP, SNMP). Тогда CMDB не хранит «вечные» записи.
Виртуализация и облака: что важно
Для виртуализации критичны: гипервизор/кластер, хост, имя VM, CPU/RAM/диски, сеть, теги/проект, и кто владелец сервиса. Самое ценное - связка «VM -> хост -> стойка/площадка» и дата последнего подтверждения.
Закупки и склад: связь без дублей
Учет закупок отвечает на вопрос «на каком основании актив существует». Берите номер договора/заявки, дату, стоимость (если нужно), гарантию и серийный номер. Серийник плюс тип устройства - хороший ключ для склейки с техническими источниками.
Чтобы не плодить дубли, заведите правило: новый актив сначала появляется из закупки/склада как «ожидает ввода», а «живым устройством» становится только после подтверждения из IT-источника (агент/MDM/сеть). Так CMDB остается базой фактов, а не витриной мнений.
Правила актуализации: кто прав и как это закрепить
CMDB живет не за счет выбранной платформы, а за счет правил: кто обновляет данные, как часто и что делать, когда источники спорят. Для open source CMDB для 500-2000 устройств это особенно важно: ручные правки быстро превращают базу в сборник мнений.
Разделите атрибуты и назначьте для каждого источник истины. Серийный номер и модель должны приходить из инвентаризации (агент, скан сети, закупка), а владелец и подразделение - из HR или сервис-деска. Если не договориться, поля начнут переписывать «как кажется правильным».
Закрепите правила коротким регламентом на 1-2 страницы:
- Источник истины по каждому атрибуту: например, серийник - из инвентаризации, расположение - из учета перемещений, статус утилизации - из заявки.
- Матрица ответственности: кто вносит изменения, кто подтверждает, кто только читает. Лучше по ролям (ИТ-эксплуатация, сервис-деск, ИБ, склад), а не по именам.
- Периодичность: железо - по событию (поставка, перемещение, ремонт) и раз в квартал сверка; ПО - чаще (раз в неделю или после обновлений); принадлежность и владелец - по кадровым событиям и раз в месяц контроль.
- Правила для ручных полей: какие можно править руками, а какие только из системы-источника.
- Статусы для спорных объектов: «карантин», «не подтверждено», «к списанию» со сроком.
Конфликты неизбежны: один источник говорит «устройство в офисе», другой - «в удаленной сети».
Как разбирать конфликты
-
Приоритет источников: заранее задайте, кто «побеждает» по каждому атрибуту.
-
Правило свежести: если оба источника допустимы, выигрывает более новое подтверждение.
-
Проверка человеком: если затронуты критичные поля (владелец, локация, статус), создается задача на подтверждение.
-
Карантин: если объект не удается подтвердить за N дней, он помечается как «неопределенный» и исключается из отчетов, где важна точность.
Полезная привычка: изменения должны происходить либо «по событию» (заявка, поставка, ремонт), либо автоматически из источника истины. Все остальное быстро ведет к «мертвому реестру».
Пошаговое внедрение за 4-8 недель: MVP без боли
Чтобы open source CMDB для 500-2000 устройств не стала «мертвым реестром», начните с MVP: минимум сущностей, минимум источников, но четкие правила. Цель на этом этапе - наладить поток фактов и сделать так, чтобы данные обновлялись автоматически или по понятному процессу.
План на 4-8 недель
Двигайтесь короткими итерациями, где каждый шаг дает результат:
- Неделя 1: соберите минимальный каталог устройств и локаций (офисы, этажи, серверные, стойки) и договоритесь о едином формате имен.
- Недели 2-3: подключите 1-2 источника данных и настройте автозаполнение полей (серийный номер, модель, ОС, IP, владелец, последняя активность).
- Неделя 4: добавьте статусы и простой процесс изменений: «создал - изменил - списал», без сложных согласований.
- Недели 5-6: включите сверку и отчеты по расхождениям, чтобы видеть, где база «поплыла».
- Недели 7-8: расширяйте модель только после стабилизации, когда расхождений становится меньше, а обработка понятна.
Заранее решите, какие поля обязательны. Для MVP обычно достаточно: уникальный идентификатор, тип устройства, локация, ответственный, статус, дата последней проверки.
Как избежать перегруза процессами
Назначьте роли так, чтобы не получилось «все отвечают - никто не отвечает»:
- Владелец CMDB: утверждает правила и спорные случаи.
- Ответственные по площадкам: подтверждают локации и перемещения.
- Эксплуатация: ведет статусы и списание.
- Безопасность: задает минимальные требования к учету критичных активов.
Простой пример: ноутбук переехал из офиса в переговорную. Изменение фиксируется одной операцией со сменой локации и датой. Сверка подсвечивает устройства, которые «видны» в сети, но отсутствуют в базе (или наоборот). Если такие отчеты просматривают раз в неделю и закрывают отклонения, CMDB начинает держаться на рутине, а не на энтузиазме одного человека.
Сверка и качество данных: чтобы база не разъезжалась
Когда CMDB начинает «разъезжаться», причина обычно не в инструменте, а в том, что разные источники описывают одно и то же устройство разными словами. Для open source CMDB для 500-2000 устройств важно заранее договориться, как вы сопоставляете записи и что считаете «истиной».
Сопоставление лучше строить на устойчивых ключах, а не на том, что часто меняют руками. Практичный порядок:
- серийный номер (лучший вариант для физического железа)
- UUID/Asset Tag (если реально заполняется и выгружается)
- hostname (вспомогательный, потому что его переименовывают)
- MAC-адрес (осторожно с док-станциями, Wi-Fi/ETH и заменой плат)
Дедупликация должна быть правилом, а не разовой уборкой. Если новый импорт находит совпадение по «сильному» ключу (серийник/UUID), он обновляет существующую запись, а не создает новую. Если совпадение только по «слабому» ключу (hostname), запись попадает в очередь на проверку.
Нормализация спасает от хаоса в справочниках. Если один и тот же ноутбук встречается как «HP 840 G8», «EliteBook 840» и «840G8», вы не сможете нормально фильтровать парк и планировать замены. Заведите единые справочники для моделей, локаций и подразделений и разрешите редактировать их ограниченному кругу.
Отдельно продумайте аудит изменений. Полезно логировать: кто и когда поменял владельца, локацию, статус, серийный номер/идентификатор, а также из какого источника пришло обновление. Это помогает разбирать спорные случаи: «почему устройство пропало», «кто переименовал сервер», «откуда взялся новый актив».
Чтобы держать качество на уровне, обычно хватает трех еженедельных отчетов:
- «Новые и измененные за неделю» (что появилось и что резко поменялось)
- «Конфликты сопоставления» (совпадения по слабым ключам и подозрение на дубль)
- «Устаревшие данные» (устройства без обновлений N дней и пустые критичные поля)
Если эти три отчета регулярно смотрят и по ним есть простой процесс действий, база остается живой.
Частые ошибки и ловушки при open source CMDB
Самая частая причина, почему open source CMDB для 500-2000 устройств превращается в «мертвый реестр», не в выборе инструмента. Проблема в том, что база начинает жить отдельно от реальности: люди меняют оборудование и настройки, а записи остаются прежними.
Что чаще всего ломает CMDB
Первая ловушка - попытка описать все и сразу. Когда модель похожа на энциклопедию (десятки типов сущностей, сотни полей, сложные связи), никто не понимает, что именно важно заполнять и проверять. В итоге данные заносят «для галочки», а потом перестают трогать.
Вторая - отсутствие владельцев данных. Фраза «это задача ИТ» звучит логично, но на практике означает «не отвечает никто». У каждой категории данных должен быть хозяин: кто утверждает «истину» по устройствам, кто по пользователям, кто по сетевым адресам.
Третья - ставка на ручной ввод как на основной способ обновления. Ручная правка нужна, но только как исключение. Если 70% изменений в CMDB делаются руками, база неизбежно будет отставать.
Четвертая - нет статусов и правил жизненного цикла. Устройство может быть списано, отдано в ремонт, потеряно или переехало в другой офис, а в CMDB оно все еще «в эксплуатации». Без статусов вы не отличите актуальные записи от «призраков».
Пятая - CMDB не связана с процессами изменений. Если замены дисков, переустановка ОС, перенос серверов и выдача ноутбуков проходят мимо CMDB, актуальность ломается каждый день.
Мини-проверка на реальном примере
Представьте парк из 1200 устройств: часть ПК переезжает между кабинетами, часть серверов обслуживается по заявкам, новые ноутбуки выдаются пачками.
Если после «переезда» меняется только наклейка на корпусе, а в CMDB не меняется ни место, ни ответственный, ни статус, база уже начала умирать. Спасает простое правило: любое изменение, которое влияет на поддержку (где стоит, кому выдано, в каком состоянии, какие ключевые характеристики), должно оставлять след в CMDB - автоматически из источника или через обязательный шаг в заявке.
Быстрый чеклист: CMDB жива или уже превращается в реестр
CMDB «жива», когда в ней есть не просто карточки, а понятные правила: откуда берется факт, кто за него отвечает и как часто он обновляется. Если вы делаете open source CMDB для 500-2000 устройств, этот короткий самотест помогает быстро увидеть, где база начнет «черстветь».
Пять вопросов для проверки:
- У каждого важного поля есть «источник истины» и владелец.
- У всех устройств есть уникальный идентификатор и понятный статус (в работе, на складе, в ремонте, списано).
- Подключены минимум два источника данных и задано расписание обновлений.
- Есть регулярный отчет по расхождениям и простой процесс исправления.
- Добавление новых устройств и списание проходят без ручных «квестов»: одно действие запускает цепочку (заявка, приемка, присвоение статуса, появление в CMDB).
Если вы отвечаете «нет» хотя бы на два пункта, CMDB уже движется к режиму «мертвый реестр». Начните с самого болезненного: определите источник истины для 5-7 ключевых полей и закрепите владельцев. Это даст эффект быстрее, чем попытка «дозаполнить все поля сразу».
Пример сценария: как удержать актуальность на 1200 устройствах
Исходные условия: 1200 офисных ПК, 80 серверов, 5-7 филиалов. Есть домен AD, часть серверов в виртуализации, сеть с управляемыми коммутаторами. Учет техники ведется в таблицах и «в головах». Цель CMDB на минималках: быстро отвечать на вопросы «что это за устройство, где оно стоит, кто отвечает, и откуда это известно».
Стартуйте не со «всего сразу», а с трех сущностей: Устройство, Локация, Ответственный. Для устройств достаточно 8-10 полей: тип, имя/hostname, серийный номер (если есть), ОС, владелец (подразделение), локация, критичность, источник факта. Так open source CMDB для 500-2000 устройств начинает приносить пользу уже в первые недели.
AD и сеть подключайте с фильтрами, иначе CMDB утонет в шуме. Из AD берите только активные компьютеры и серверы (например, виденные за последние 30 дней) и только нужные атрибуты. Из сети фиксируйте «точки привязки» (MAC, IP, порт, коммутатор) и храните их как наблюдения с датой, а не как «истину навсегда».
Еженедельная рутина должна быть короткой и обязательной:
- Автосбор фактов по расписанию (AD, сканер, гипервизор) и загрузка в CMDB.
- Отчет по расхождениям: «есть в AD, нет в CMDB», «локация изменилась», «устройство не видно 30+ дней».
- Разбор топ-20 расхождений с ответственными и фиксация решения (перенос, списание, замена).
- Обновление правил: что считать источником истины для каждого поля.
Через 2-3 месяца при нормальной дисциплине обычно видно:
- 85-95% устройств имеют подтвержденную локацию и ответственного.
- Новые устройства появляются в CMDB за 1-3 дня, а не «когда-нибудь».
- Списания и замены проходят без потери следов (видно, что и почему изменилось).
- Снижается время на поиск «чей это ПК/сервер» и подготовку инвентаризации для проверок.
Секрет не в объеме данных, а в привычке: каждую неделю закрывать расхождения, а не копить их месяцами.
Следующие шаги: как начать и не остаться с полуфабрикатом
CMDB должна отвечать на 5-10 реальных вопросов, которые болят каждый день. Например: «какие ноутбуки без шифрования», «какие серверы без поддержки», «на чем крутится критичная система», «кто владелец сервиса и где он стоит». Если таких вопросов нет, база почти неизбежно превратится в архив.
Соберите минимальный список сущностей и источников фактов под вашу организацию. Для open source CMDB для 500-2000 устройств обычно достаточно инвентарных объектов (устройства, ПО/агенты, сеть) и 2-3 бизнес-сущностей (подразделение, владелец, критичность).
Зафиксируйте правила изменений и минимальные роли. Без этого вы получите «мнения» вместо данных:
- Владелец данных: кто решает, что считать правдой (по устройствам - команда эксплуатации, по пользователям - HR/AD, по локациям - админ зданий).
- Ответственный за загрузки: кто следит за расписанием импорта и ошибками.
- Правило конфликта: какой источник главнее при расхождении и что делать, если оба «не сходятся».
- Правило свежести: через сколько дней запись считается устаревшей и что происходит дальше.
Пилот лучше строить по принципу «один кусок, но полностью»: одно подразделение или один регион, где вы доведете цикл до конца - сбор, нормализация, сверка, обновления. Например, филиал на 250 устройств: за 2 недели добейтесь 90% покрытия по серийникам и владельцам, затем добавьте второй источник (например, MDM или сканер сети) и проверьте, как работает разрешение конфликтов.
Интегратора имеет смысл подключать, если источников много, есть филиальная сеть, требования аудита или нужно связать CMDB с заявками и мониторингом без ручного «клея».
Если на этапе пилота параллельно нужно обновить инфраструктурную базу (серверы для CMDB, рабочие места, поддержка площадок), это обычно проще делать вместе с системной интеграцией. Например, GSE.kz как производитель и системный интегратор может помочь с инфраструктурными проектами и круглосуточной технической поддержкой, чтобы CMDB не зависела от одного человека и одного «ручного процесса».
FAQ
Почему CMDB часто превращается в «мертвый реестр» уже через пару месяцев?
Обычно CMDB «умирает», когда она не дает ежедневной пользы поддержке и админам. Если данные обновляются вручную, нет источников истины и непонятно, кто отвечает за ключевые поля, база быстро начинает расходиться с реальностью и ей перестают доверять.
С чего реально начать CMDB «на минималках» для 500–2000 устройств?
Начните с того, что вы готовы поддерживать постоянно: устройства, пользователей/ответственных, локации и несколько критичных сервисов. Все остальное добавляйте только после того, как заработали статусы, обновления из источников и регулярная сверка.
Какие поля сделать обязательными в карточке устройства на старте?
Минимум, который дает эффект: уникальный идентификатор (серийный номер или инвентарный), тип и модель, локация, ответственный/подразделение, статус жизненного цикла и дата последнего подтверждения. Это позволяет быстро понять «что это, где оно и кому звонить», не утонув в деталях.
Какие статусы жизненного цикла лучше ввести, чтобы база не разъезжалась?
Выберите простой и понятный набор: «в эксплуатации», «на складе», «в ремонте», «списано», плюс при необходимости «не подтверждено/карантин». Главное правило: любое перемещение, выдача или списание должны менять статус и оставлять дату подтверждения, иначе записи быстро становятся «призраками».
Как договориться, где «истина» по хостнейму, владельцу и местоположению?
Определите источник истины для каждого атрибута заранее. Например, имя хоста и активность логичнее брать из AD, технические характеристики и ПО — из агента или MDM, локацию — из процесса перемещений, а финансовые детали — из учета закупок, если они вообще нужны в CMDB.
Достаточно ли автосбора данных, чтобы CMDB была актуальной?
Автосбор дает скорость и регулярность, но он не заменяет правила. Делайте так: факты подтягиваются автоматически по расписанию, а спорные или критичные поля (владелец, локация, статус) подтверждаются по задаче, если источники конфликтуют или данные устарели.
Как выбрать open source платформу: NetBox, iTop, GLPI, CMDBuild — что брать?
Смотрите на задачу. Если боль — сеть, адреса, стойки и порты, удобнее начинать с решений класса IPAM/DCIM; если нужна связь с заявками и инцидентами, проще жить в ITSM с CMDB рядом; если важны связи сервисов и контроль изменений, пригодится более «классическая» CMDB. Выбирайте то, что легче «кормится» из ваших источников и выдержит дисциплину данных.
Как избежать дублей при импорте из AD, сети, MDM и закупок?
Используйте сильные ключи и правила дедупликации. Для физического железа лучше всего работает серийный номер или UUID/Asset Tag; hostname и MAC подходят как вспомогательные и часто требуют ручной проверки. Важно, чтобы импорт обновлял существующую запись при совпадении по сильному ключу, а не создавал новую.
Какими метриками измерять, что CMDB действительно работает?
Дайте простые метрики: доля объектов с обновлением не старше выбранного срока, доля карточек с заполненными обязательными полями, время поиска владельца и зависимостей при инциденте, количество конфликтов между источниками и скорость их закрытия. Эти показатели видно без сложной отчетности, и они быстро показывают, «жива» ли база.
Как встроить CMDB в процессы закупки, перемещения и списания, чтобы ее не бросили?
Сделайте CMDB частью цепочки изменений: закупка или приемка создает запись со статусом «ожидает ввода», ввод в эксплуатацию подтверждается IT-источником, перемещение меняет локацию и дату, списание закрывает объект. Если у вас параллельно идут обновления инфраструктуры и много площадок, иногда проще закрепить этот процесс через системную интеграцию и поддержку, чтобы актуальность не держалась на одном человеке.