Обновления антивируса и EDR в изолированной сети: практические проверки
Обновления антивируса и EDR в изолированной сети: как настроить локальные зеркала, контролировать актуальность и проверять, что обновилось на самом деле.
В чем проблема обновлений в изолированной сети
Изолированная сеть на практике редко означает «вообще ничего не подключено». Чаще это контур без прямого выхода в интернет, где внешние загрузки идут через строгий шлюз, прокси с белыми списками, перенос через съемные носители или отдельную «перевалочную» площадку (staging). В результате обновления перестают быть фоновым событием и становятся управляемым процессом, в котором легко потерять контроль.
Главная ловушка: «обновление прошло успешно» не равно «защита актуальна». Агент может отчитаться об успешной операции, но фактически применить не тот пакет, откатиться на старую базу после перезагрузки, не получить обновление движка или остаться на прежних правилах детекта из-за несовместимости версий. В изолированном контуре такие расхождения легко живут неделями.
Важно помнить, что обновляется не один «антивирус», а несколько слоев. Обычно это:
- сигнатуры и репутационные базы;
- движок сканирования (компоненты анализа);
- агент на конечном устройстве;
- политики, правила детекта и реагирования;
- модули EDR (сенсоры, телеметрия, драйверы).
Если отстает хотя бы один слой, появляется окно уязвимости. Например, сигнатуры свежие, но движок старый и не понимает новый формат. Или агент обновился, а политики не доехали, и часть детектов просто не включена.
В изолированной сети риски усиливаются из-за рассинхрона: разные площадки получают пакеты в разное время, зеркала обновлений «живут своей жизнью», а отдельные узлы тихо выпадают из процесса. Так появляются «мертвые» машины: в консоли они видны, но давно не получают обновления и не отправляют телеметрию. На фоне сводных отчетов это выглядит как мелкая статистика, пока не происходит инцидент.
Отдельная проблема - зависимость от людей и регламентов. Обычно вовлечены ИБ (требования и контроль), ИТ (инфраструктура и доступы), администраторы площадок (раздача и окна работ) и эксплуатация (заявки, инциденты, учет изменений). Если роли не разделены, ответственность размазывается: «зеркало обновили», «агент обновили», а «почему детекты не работают» - уже непонятно.
Типичный сценарий: филиал получил пакет с базами, но не получил обновление агента из-за ограничения по версии ОС. В отчете зеленый статус «обновлено», а по факту защита частично выключена. Именно такие несовпадения и делают обновления в закрытом контуре сложной темой.
Рабочие схемы: зеркало, staging и офлайн пакеты
В изолированном контуре обновления почти всегда превращаются в отдельный процесс: нельзя просто «дать интернет» агентам, а отчеты консоли нередко показывают не то, что реально применилось на узлах. Поэтому схему стоит выбрать заранее и описать как регламент, а не как разовую настройку.
Три базовые схемы
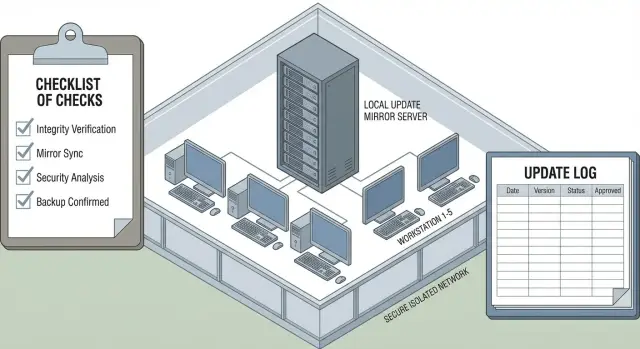
1) Локальное зеркало внутри контура. Один сервер в закрытой сети хранит репозитории обновлений (сигнатуры, движки, правила, модули EDR) и раздает их всем узлам. Зеркало пополняют через контролируемый канал переноса (например, через проверенную точку импорта). Плюсы - единое место контроля, понятная статистика, меньше ручных операций. Минусы - зеркало становится критичной точкой, его нужно резервировать и мониторить.
2) Промежуточная зона (staging). Обновления сначала попадают в выделенную «серую» сеть или DMZ, где их можно проверить, разложить по группам (тестовая и продуктивная), а затем по расписанию передать внутрь. Это удобно, когда нужна предварительная проверка или управление окнами обновлений (ночью, по выходным, по площадкам). Минусы - больше компонентов и больше мест, где может оборваться цепочка.
3) Офлайн пакеты. Обновления скачиваются в открытой среде, упаковываются и доставляются вручную на площадки (USB, защищенный носитель, «курьерский» перенос). Это рабочий вариант для удаленных объектов без канала связи или при самых жестких ограничениях. Минусы - высокая нагрузка на людей и риск ошибки: перепутали пакет, пропустили площадку, забыли применить.
Чтобы выбранная схема не развалилась через месяц, зафиксируйте в одном документе:
- источники обновлений и состав пакетов (что именно обновляется);
- частоту и допустимое отставание для разных типов обновлений;
- точки контроля (где сверяем версии, где подтверждаем применение);
- ответственных и порядок согласований;
- порядок отката и действия при сбое.
Как выбрать подход
Выбор обычно зависит не от вкуса, а от ограничений и масштаба:
- 10-200 узлов в одном месте: чаще достаточно локального зеркала.
- Несколько площадок и разные окна работ: обычно удобнее staging с расписанием и группами.
- Нет канала связи или очень строгие правила переноса: офлайн пакеты, но с жестким журналированием.
- Высокая критичность (больницы, финсектор, госсектор): staging + тестовая группа перед продуктивом.
- Требования регуляторов и аудита: выбирайте схему, где проще доказать цепочку «получили - проверили - применили».
На практике крупные организации часто совмещают схемы: центральное зеркало в головном контуре, staging для проверки и офлайн пакеты как запасной вариант для удаленных точек.
Пошагово: как развернуть локальное зеркало и раздачу обновлений
Перед стартом зафиксируйте, что именно вы обновляете. В контуре часто одновременно живут агенты на рабочих местах и серверах, консоль управления, модули поведения, драйверы, сигнатуры и компоненты для расследований. Если не собрать полный список, получится ситуация «обновилось все», но детектирование осталось на старых правилах.
Подготовка сервера зеркала
Выберите сервер под зеркало и заложите запас по диску. Частая ошибка - считать только размер баз, забывая про кэш, временные файлы, журналирование и хранение нескольких поколений пакетов. Сразу решите, где будут лежать логи (чтобы их не «съедало» место под обновления) и как вы будете делать резервную копию конфигурации.
Даже если у вас нет отдельной DMZ, полезно логически разделить две зоны: staging (куда попадают обновления после загрузки) и production (откуда их раздают внутрь). Это снижает риск раздать «сырые» пакеты.
Схема работ по шагам
Простой порядок, который обычно дает предсказуемый результат:
- Составьте матрицу продуктов и компонентов (AV, EDR, агенты, консоль, плагины, базы, политики и правила). Для каждого пункта запишите, где смотреть версию и дату.
- Поднимите зеркало: каталог хранения, квоты на диск, расписание очистки старых пакетов, журналирование загрузки и раздачи.
- Настройте загрузку в staging (или выгрузку на носитель при офлайне). Сразу определите «окно», когда допустимы трафик и нагрузка.
- Организуйте раздачу внутри контура по группам: тестовая - пилот - остальные. Привяжите к окнам обслуживания, чтобы не обновлять критичные системы в рабочее время.
- Зафиксируйте «ожидаемые версии» для пилота: какие номера баз и версии агентов должны появиться после обновления, и где это проверять на хосте.
После пилота нужен план отката, описанный как конкретные действия: откуда взять предыдущий пакет, как отключить проблемный модуль, как вернуть политику, как быстро исключить группу машин из обновления.
Практический пример: в небольшой изолированной сети обновления раздавали «всем сразу», и при сбое драйвера EDR часть рабочих мест уходила в перезагрузки. После разделения на staging и поэтапную раздачу по группам сбой ловили на 10 тестовых машинах, а не на сотне, и откат занимал минуты, а не часы.
Как контролировать актуальность: версии, даты и допустимое отставание
В изолированном контуре мало отчетов, которым можно доверять без проверки. Контроль актуальности проще строить на измеримых признаках: что загружено на зеркало, что видит консоль и что реально применилось на конечном узле. Один сбой переноса может неделю выглядеть как «все зеленое».
Какие метрики фиксировать
Держите одинаковый минимум для всех площадок, чтобы сравнение было честным:
- дата выпуска сигнатур и дата их установки на узле;
- версия движка (engine) и дата его обновления;
- версия агента EDR и версии ключевых компонентов (сенсор, драйвер, модуль предотвращения);
- дата последней успешной проверки обновлений (last check-in) и источник (локальное зеркало или иной сервер);
- статус политики обновлений (разрешено, приостановлено, по расписанию).
Собирайте это в одном месте (выгрузка из консоли, таблица, простая сводка) и храните историю. Один снимок «на сегодня» не показывает деградацию.
Допустимое отставание: задайте правила заранее
«Норма» отставания зависит от сегмента. В критичных подсетях обычно допустимо меньше, но обновлять там сложнее из-за окон работ. Практичный подход - задать пороги по уровням (критичные, офисные, тестовые) и отдельно для сигнатур, движка и агента. Сигнатуры обычно требуют чаще, а агент EDR можно обновлять реже, но строго по плану, чтобы не копить уязвимости и несовместимости.
Дальше проверяйте состояние на трех уровнях, иначе вы будете спорить «у кого правда»:
-
Зеркало: какие пакеты реально лежат, их даты и признаки целостности.
-
Консоль управления: какие версии она ожидает и что показывает по группам.
-
Конечные узлы: что установлено фактически (локальная версия, дата установки), а не только «последний контакт».
Как находить тихие провалы
Чаще всего проблемы не «кричат», а делают вид, что все работает. Быстро отлавливаются ситуации, когда:
- узел давно не выходил на связь, но в консоли все еще числится в «успешных»;
- агент установлен, но сервисы не запущены или сенсор поврежден после обновления ОС;
- политика запрещает обновления (случайно включили freeze или неверное окно обслуживания);
- узел ходит не на локальное зеркало, а на старый адрес или кеш прокси;
- на зеркале есть сигнатуры, но нет пакета движка, и «обновилось не то».
Раз в неделю полезна выборочная проверка 5-10 машин из каждого сегмента: сравнить версии на узле с тем, что заявляет консоль, и с тем, что есть на зеркале.
Реестр исключений: чтобы «временно» не стало «навсегда»
Исключения неизбежны: сервер нельзя перезагружать, медоборудование привязано к старому драйверу, тестовый стенд отстает по версии. Нужен простой реестр: кто согласовал, что именно отложено (сигнатуры, движок, агент), срок, причина, принятый риск и дата пересмотра.
Проверка «что реально обновилось», а не «что отчиталось»
В изолированной сети легко получить красивый статус «обновлено» в консоли и при этом держать узлы на старых базах. Поэтому полезно разделять два факта: что сказала система управления и что реально изменилось на диске и в службах.
Смысл проверки простой: смотрим не задачу, а артефакты. Это версии файлов и компонентов, дата и номер сигнатур (или контента), номера пакетов, фактическое время применения обновления на узле.
Что именно проверять на узле
Начните с трех источников: локальный лог обновлений, информация о версиях компонентов в агенте и следы обновления в файловой системе (или в реестре, если продукт хранит версии там). Важно различать типы обновлений: сигнатуры меняются часто, движок и агент - реже и обычно требуют больше времени, а иногда и перезапуск.
Практика, которая почти всегда дает ясную картину:
- Снимите «до»: версия агента, версия движка, дата и номер баз/контента, время последней проверки обновлений.
- Запустите обновление штатным способом (по расписанию или вручную).
- Сразу проверьте локальный лог: скачивание, проверка подписи, распаковка, применение.
- Снимите «после»: изменились ли номер пакета, дата баз, версии модулей.
- Повторите на выборке: 2-3 узла в каждом сегменте и на каждой площадке, включая самый удаленный филиал.
Не ограничивайтесь только эндпоинтами. На сервере-зеркале проверьте, что новые пакеты действительно появились: по времени последней синхронизации, размеру и количеству файлов, журналу скачивания. В консоли полезно смотреть не только «успех», но и детали: какой пакет назначили, какой применился и почему мог быть пропуск.
Как фиксировать и что делать при расхождениях
Удобный формат фиксации - короткий протокол «до/после» на одну страницу: дата и время проверки, список проверенных узлов, версии и номера пакетов, источник обновлений (зеркало/промежуточный сервер), результат.
Если консоль говорит «обновлено», а артефакты не изменились, действуйте по нарастающей:
- повторите обновление и проверьте, не попали ли вы в окно, когда пакет уже скачан, но еще не применен;
- очистите кэш обновлений на узле и перезапустите службу агента (по инструкции вендора);
- проверьте доступность зеркала из сегмента: DNS, маршрут, порты, прокси, сертификаты;
- убедитесь, что узел получает правильную политику и не закреплен на старом канале обновлений;
- если расхождение остается, переустановите агент на одном проблемном узле как контрольный эксперимент и эскалируйте с логами.
Мини-сценарий из практики: в закрытом контуре госоргана центральная площадка обновляется, а филиал «успешно» отчитывается неделями. Выборочная проверка по артефактам быстро показывает причину: филиал ходит на старое зеркало из-за записи DNS, и статусы в консоли отражают выполнение задачи, а не применение пакета.
Безопасный перенос обновлений в закрытый контур
В изолированной сети главный риск не в том, что обновление приедет поздно, а в том, что в контур попадет не то. Перенос должен быть процессом с ролями, проверками и следами в журналах. Отчету консоли здесь доверять недостаточно.
Кто что делает
Разделите работу так, чтобы один человек не мог незаметно подменить пакет и сразу же его применить. Удобно фиксировать роли в матрице ответственности и каждый перенос проводить как маленькую поставку:
- подготовка пакета: ИБ (или выделенный администратор) скачивает с доверенного источника и фиксирует версию, дату, размер;
- доставка: сотрудник с допуском перевозит носитель и отвечает за его учет;
- приемка: администратор закрытого контура проверяет целостность и соответствие версии заявке;
- загрузка на локальное зеркало: отдельная учетная запись, без прав на изменение политик EDR;
- подтверждение результата: ИБ сверяет, что обновления реально применились на контрольных узлах.
Между этапами должна быть пауза на проверку, а не «принесли и сразу поставили».
Контроли перед загрузкой
Минимум, который реально работает без сложной инфраструктуры: хэш-сумма (или подпись вендора) плюс независимая сверка версии по документу заявки.
Отдельное внимание - носителям и станциям переноса. Носитель проверяют на «чистой» машине в открытом контуре, затем повторно на машине-приемнике в закрытом контуре. Эти рабочие станции лучше закрепить за задачей, не использовать для офисной работы и держать с актуальной защитой.
Хранение носителей организуйте как для ключей: маркировка, журнал выдачи и возврата, срок жизни (например, плановая замена раз в N месяцев), запрет на личные USB. Если один и тот же носитель используется для разных продуктов, резко растет риск путаницы версий и «хвостов» файлов.
Типовые ошибки с офлайн пакетами обычно простые, но неприятные:
- смешали пакеты разных дат в одной папке и загрузили «не тот»;
- потеряли подтверждение хэша и потом нельзя доказать, что ставили именно этот файл;
- носитель ходит между кабинетами без учета и однажды «вдруг» оказывается зараженным;
- обновление применили на зеркало, но клиенты не получают его из-за неверного пути, прав или расписания.
Набор документов не должен быть толстым: короткий регламент переноса, журнал обновлений (что, когда, кем, чем проверено) и матрица ответственности. Этого достаточно, чтобы процесс был повторяемым и проверяемым.
Типовые ошибки эксплуатации и как их распознать
При обновлениях в изолированной сети чаще ломается не технология, а дисциплина: кто-то не проверил синхронизацию, кто-то сделал одну политику на все, кто-то обновляется «когда получится».
Первая группа проблем связана с локальным зеркалом. Синхронизация может тихо остановиться из-за переполнения диска, сбоя расписания, смены прокси или истечения учетных данных. Опасно то, что часть отчетов еще долго показывает «все нормально», пока не станет заметен рост отставания.
Признаки, что зеркало или раздача идут не так, как вы думаете:
- на зеркале дата последних файлов свежая, а у конечных узлов версия баз не меняется;
- число узлов с «ошибкой обновления» растет скачками после выходных или праздников;
- в одном сегменте появляются разные версии сигнатур без понятного объяснения;
- в логах зеркала повторяются одни и те же ошибки, но на них никто не реагирует;
- узлы «успешно обновились» по отчету, но детект тестового EICAR (или аналогичного теста) не срабатывает.
Вторая типовая ошибка - отсутствие разделения на тестовую и продуктивную группы. Тогда одно неудачное обновление может уронить производительность, сломать совместимость с софтом или вызвать перезапуски, и вы откатываетесь вслепую. Простое правило: сначала небольшой пилот (5-10% типовых рабочих мест и 1-2 сервера), затем расширение.
Третья ошибка - «обновляемся редко, потому что неудобно носить». Если нет планового окна и назначенного ответственного, офлайн перенос превращается в разовую акцию. Это видно по графику: обновления приезжают пачками, затем тишина на недели.
Отдельно стоит EDR: агент может быть установлен, но не работать. Частые причины - нет связи с консолью, истек токен регистрации, сломалась цепочка сертификатов, неверное время на хосте. В инвентаре узел есть, а телеметрии нет.
Чтобы быстро отлавливать такие ситуации, держите простые метрики:
- сколько узлов отстает от «эталонной» версии больше допустимого порога;
- сколько узлов не выходили на связь с консолью EDR более N часов;
- сколько ошибок обновления за сутки и в каких сегментах;
- сопоставление «версия на зеркале vs версия на контрольных узлах» по сегментам;
- еженедельная выборочная проверка 5-10 узлов по логам агента.
Небольшой пример: в одном закрытом контуре отчеты заполняли вручную раз в месяц. Выяснилось, что зеркало две недели не синхронизируется из-за заполненного диска, а «зеленый статус» держался на кэше. Проблему решили не усложнением, а правилами: порог отставания, ежедневная автоматическая сводка по узлам и ответственный, который подтверждает факт обновления по контрольной группе, а не по красивому отчету.
Короткий чеклист проверок для ИТ и ИБ
Чтобы обновления не жили «на доверии», держите один короткий набор проверок. Он должен быть понятен и ИТ, и ИБ, и выполняться по расписанию.
Регулярные проверки по графику
- Ежедневно: проверьте дату и версию баз на локальном зеркале и долю узлов, которые реально обновились за последние 24 часа. Фиксируйте не только «успешно», но и число устройств, которые не дошли до актуального состояния.
- Еженедельно: сделайте выборочную проверку «до/после» на 5-10 узлах из разных сегментов (бухгалтерия, цех, серверная, защищенный сегмент). Снимите версии до обновления, запустите обновление, снимите версии снова и сравните.
- Ежемесячно: сверяйте версии агентов EDR и планируйте обновление отстающих групп. Частая ситуация - агент обновили на пилоте, а на «тяжелых» серверах или старых рабочих местах он остался на прошлой ветке и молча потерял часть функций.
После каждого переноса обновлений добавьте две привычки: проверку целостности пакета и запись в журнал. Журналу достаточно простого формата: дата, кто переносил, источник, хэш/контрольная сумма, что перенесли (базы, движок, агент), куда положили, результат раздачи.
Быстрые проверки «по событию»
При инциденте ключевой вопрос: какая версия была на узле на момент события, а не какая «должна быть» по отчету. Заранее убедитесь, что вы умеете быстро поднять историю: версии баз, движка, агента EDR, время последней успешной синхронизации с зеркалом и ошибки обновления.
Когда нужно эскалировать
- Массово не обновляются узлы (резко упала доля обновившихся за сутки).
- На зеркале свежие базы, а на клиентах одинаково «застыла» старая дата.
- В одном сегменте версии сильно отличаются от остальных без понятной причины.
- Растет число ошибок проверки подписи/целостности пакетов или «битых» загрузок.
- В отчетах все «зеленое», но выборочная проверка «до/после» показывает, что версии не меняются.
Если чеклист выполняется стабильно, проблемы обычно видны за день-два, а не через месяц после первого пропуска обновлений.
Пример из практики: как навести порядок без усложнения
Типичный кейс: три площадки, закрытый контур, интернет недоступен, свежие базы и пакеты привозят раз в неделю на носителе. Формально все выглядело «под контролем», но ИБ не могла уверенно ответить на простой вопрос: кто реально обновился, а кто просто отчитался.
Схему сделали приземленной. Снаружи организовали staging: отдельный узел в открытом сегменте скачивает обновления от вендоров, проверяется и готовит «пакет недели». Внутрь пакеты заносятся по регламенту, после чего на сервере в закрытом контуре работает локальное зеркало. Клиенты получают обновления не «всем сразу», а по группам, чтобы легче было найти место сбоя и не перегружать сеть.
Чтобы перестать жить общими отчетами, добавили проверки, которые занимают минуты, но дают честную картину:
- сверка версий и дат на зеркале с тем, что привезли (чтобы исключить частичную загрузку или неправильный каталог);
- контроль процента обновленных узлов по группам, а не общей цифрой по организации;
- выборочная проверка логов на 5-10 машинах из разных подсетей (кто, когда и откуда брал пакет);
- контроль «допустимого отставания» по времени, например не больше 7 дней для рабочих станций и меньше для критичных.
Через пару недель вскрылась проблема: часть ПК и ноутбуков стабильно не попадала в окно обновления. Кто-то был выключен, кто-то не выходил в сеть на площадке, где обновления раздавались только ночью. Отставание копилось незаметно, пока не появлялись инциденты или вопросы аудитора.
Исправление оказалось не про новые системы, а про дисциплину. Сделали два окна обновлений в разные дни (ночное и дневное), добавили отчет по «спящим» узлам и выделили отдельную группу для критичных ПК, чтобы их догоняли в первую очередь.
Результат был не в «магических 100%», а в прозрачности. Стало видно, где ломается цепочка: на этапе привоза, на зеркале, в раздаче по группам или на конкретных машинах. И когда что-то снова отставало, было понятно, кому и что исправлять, без лишней паники и без усложнения инфраструктуры.
Следующие шаги: закрепить процесс и при необходимости усилить инфраструктуру
Чтобы обновления в изолированной сети не превращались в «ручной ритуал», закрепите процесс на бумаге и в регулярных проверках. Самое важное - простая схема, понятные роли и заранее заданные пороги, когда это уже инцидент, а не «чуть задержалось».
Закрепите регламент в 1-2 страницах
Хороший регламент отвечает на пять вопросов: откуда берутся обновления, кто переносит, кто проверяет, как часто, что считаем нормой. Добавьте точки контроля: проверка хэшей и подписей, сверка версий на зеркале, выборочная проверка на конечных узлах. Отдельно зафиксируйте допустимое отставание (для сигнатур - N дней, для модулей агента - по плану и по критичности).
Чтобы не зависеть от конкретных людей, назначьте роли: владелец процесса (обычно ИБ), исполнитель переноса (ИТ или ИБ) и контролер факта обновления (ИБ с выборочной проверкой на хостах). Если контуров несколько, определите ответственных по площадкам.
Сделайте минимальную еженедельную отчетность
Руководителям ИБ и ИТ обычно не нужен «лог на 500 строк». Нужен короткий снимок состояния, по которому видно, где процесс сломался:
- дата и версия баз/контента на локальном зеркале и отставание от эталона;
- процент узлов, обновившихся за неделю, и список «хвостов» по сегментам;
- 3-5 самых частых причин сбоев (нет связи, переполнен диск, ошибка подписи, агент устарел);
- сколько обновлений агента запланировано и сколько реально поставлено;
- отклонения от порогов тревоги и что сделано.
Если зеркало свежее, но 20-30% хостов «висят» неделями, это почти всегда проблема маршрутизации, прав доступа, расписаний или устаревшего агента, а не «плохих обновлений».
Дальше оцените, тянет ли инфраструктура зеркала нагрузку. Пора усиливать, если:
- свободного места меньше, чем на 2-4 недели обновлений и архивов;
- скорость раздачи падает в окна обновлений, много таймаутов;
- зеркало - один сервер без резерва, и любой простой останавливает обновления;
- нет контроля целостности и журнала, кто и что переносил.
Параллельно проведите инвентаризацию: модели ПК и серверов, версии ОС, где стоят агенты и какого поколения. Часто именно агентская часть требует отдельного плана обновления, особенно в серверных сегментах.
Если выясняется, что нужен отдельный надежный сервер под зеркало и хранение пакетов или требуется поддержка процесса 24/7, это обычно закрывается через системную интеграцию и эксплуатацию. Например, у GSE.kz как у производителя и системного интегратора это часто сводится к понятным вещам: выделенный серверный контур, инфраструктура для репозиториев и мониторинг состояния обновлений как части поддержки.
Следующий практичный шаг - пилот на одном сегменте (например, 50-100 узлов): отладьте перенос, проверки и отчетность, затем расширяйте на все площадки по шаблону.
FAQ
Почему в консоли «обновлено», а защита на самом деле может быть неактуальной?
В изолированной сети «успешно» часто означает, что задача стартовала и отчиталась, но пакет мог не примениться, откатиться после перезагрузки или установиться частично. Надежнее проверять не статус, а факты на узле: версии компонентов, дату баз/контента и записи в локальных логах обновления.
Что именно нужно обновлять в AV/EDR, кроме «сигнатур»?
Обычно обновляются несколько слоев: базы/контент, движок, агент, политики и EDR-компоненты. Если один слой отстает, появляется окно уязвимости, например новые базы не работают на старом движке или агент обновился, а правила детекта не доехали.
Как выбрать схему обновлений: зеркало, staging или офлайн-пакеты?
Для одного офиса чаще всего хватает локального зеркала внутри контура: проще контроль и меньше ручной работы. Если площадок несколько и нужны тестовые окна, удобнее staging-зона с поэтапной передачей в контур. Офлайн-пакеты стоит выбирать, когда нет канала связи или перенос разрешен только через носители, но тогда нужен строгий журнал и контроль версий.
Как определить допустимое отставание обновлений в закрытом контуре?
Задайте пороги заранее и отдельно для разных типов обновлений: базы обычно должны догоняться чаще, агент и EDR-модули — реже, но по плану. Практичный вариант — определить «эталон» (что лежит на зеркале) и максимальное отставание по сегментам, чтобы любое превышение сразу считалось инцидентом, а не «чуть задержалось».
Как быстро проверить на компьютере, что обновление реально применилось?
Проверьте три вещи: локальный лог обновлений, текущие версии компонентов в агенте и реальные артефакты на диске/в реестре (что именно поменялось и когда). Сделайте снимок «до», запустите обновление штатно, затем снимок «после» и повторите на нескольких машинах из разных сегментов, включая самый удаленный филиал.
Что делать, если консоль показывает успех, но версии на узлах не меняются?
Сначала исключите «ожидание применения»: иногда пакет скачан, но еще не установлен по расписанию. Дальше проверьте доступ к зеркалу (DNS, маршрут, порты, прокси, сертификаты), корректность политики обновлений и что узел не закреплен на старом источнике. Если не помогло, очистка кэша обновлений и перезапуск служб по инструкции вендора часто дают результат; один контрольный переустановленный агент помогает понять, где именно сбой.
Как находить «мертвые» машины, которые перестали обновляться и отправлять телеметрию?
Ориентируйтесь на «тихие» признаки: давно нет check-in, телеметрия не приходит, сервисы агента остановлены, а в инвентаре узел числится активным. Регулярная выборочная проверка нескольких машин в каждом сегменте и сравнение «зеркало — консоль — узел» обычно быстро находит выпавшие устройства.
Как правильно распределить ответственность между ИТ и ИБ за перенос и применение обновлений?
Надежный минимум — разделение ролей и пауза на проверку между этапами. Один сотрудник готовит пакет и фиксирует версию, другой доставляет носитель, администратор контура принимает и проверяет целостность, а отдельный контролер подтверждает факт применения на контрольных узлах. Так проще доказать цепочку «получили — проверили — применили» и сложнее случайно занести не тот файл.
Как безопасно переносить обновления через носители в закрытый контур?
Начните с хэш-сумм или проверки подписи вендора и независимой сверки версии с заявкой. Носители и машины переноса держите выделенными, с учетом выдачи/возврата и повторной проверкой на приемке в контуре. Самые частые проблемы — путаница пакетов разных дат и отсутствие подтверждения целостности, поэтому короткий журнал операций реально спасает на аудите и при разборе инцидента.
Зачем нужен пилот и план отката, если обновления «обычно проходят нормально»?
Небольшая тестовая группа снижает риск массового сбоя драйвера, сенсора или совместимости с ПО. До раскатки зафиксируйте ожидаемые версии, а для отката заранее держите предыдущий пакет и понятный сценарий действий: как отключить проблемный модуль, вернуть политику и исключить группу из обновления. Тогда сбой ловится на нескольких машинах, а не на всей организации.