NVIDIA DGX для on-prem ИИ: план внедрения и готовность ЦОД
NVIDIA DGX для on-prem ИИ: как собрать требования, проверить питание и охлаждение, выбрать сеть и мониторинг, и подтвердить готовность к эксплуатации.
С чего начинается проект DGX on-prem и почему это важно
On-prem ИИ выбирают не из упрямства, а из практики: данные нельзя выносить наружу, нужны предсказуемые задержки, стабильная стоимость владения и полный контроль над доступами. Это особенно заметно в госсекторе, банках, медицине и образовании, где требования к безопасности и аудиту часто важнее скорости старта.
NVIDIA DGX для on-prem ИИ можно воспринимать как готовый вычислительный «двигатель» для обучения и инференса: внутри несколько мощных GPU, быстрые сетевые интерфейсы и настроенная базовая платформа. Но в архитектуре он не живет сам по себе. Ему нужны «органы» - сеть, хранилище, питание, охлаждение, процессы доступа и мониторинг. Если хотя бы один из них слабый, GPU будут простаивать, а запуск затянется.
Проект чаще «ломают» не сами серверы, а инфраструктурные детали, которые всплывают слишком поздно. Типовые причины: недооценили потребление и резервирование питания (и реальную нагрузку на ИБП), не рассчитали тепло и воздушные потоки в стойке (горячие точки, шум), сделали сеть «как для обычных серверов» и уперлись в задержки, разместили данные так, что вычисления постоянно ждут загрузку, не договорились о правилах доступа и ответственности.
Заранее стоит зафиксировать решения, которые дорого менять: где стоит DGX, сколько нужно стойко-мест, какая схема питания и охлаждения, какие сетевые скорости и топология, где будут данные и как их защищать. А то, что можно докрутить уже после старта, лучше отделить сразу: детальные политики доступа по ролям (если базовая модель уже понятна), тонкую настройку мониторинга, оптимизацию пайплайнов данных, выбор конкретных инструментов (если требования к совместимости известны).
Практичный старт выглядит так: один ответственный от бизнеса формулирует сценарии (например, обучение модели на внутренних документах), а команда ЦОД и интегратор проверяют, выдержит ли площадка «железные» требования. Когда в проекте участвуют локальные производители и сервисная сеть, часть вопросов по эксплуатации и поддержке удобно закрыть заранее, еще до закупки и поставки. Например, GSE.kz как системный интегратор и производитель может подключиться на этапе обследования и требований, чтобы меньше сюрпризов осталось на день монтажа.
Сбор требований: задачи, данные, безопасность, сроки
Чтобы внедрение NVIDIA DGX для on-prem ИИ не превратилось в набор догадок, начните с простого: что система должна делать каждый день и как вы поймете, что она справляется.
Задачи и метрики
Сценарии обычно смешиваются: обучение моделей, инференс в продуктиве, поиск по корпоративным данным (в том числе RAG), аналитика для команд данных, иногда VDI для ИИ и графики. У каждого сценария свои ожидания по скорости и доступности, поэтому метрики лучше согласовать заранее.
Достаточно 4-5 измеримых целей. Например: время обучения типовой модели или этапа (условно «ночной прогон укладывается в 8 часов»), задержка инференса для одного запроса и при пике нагрузки, окно доступности (когда допускаются работы и перезапуски), сколько пользователей или команд работает параллельно, и какой «план Б» при сбое (допустимый простой).
Данные, безопасность и ограничения
Дальше уточните данные: текущий объем, рост на 6-12 месяцев, где они хранятся и насколько они чувствительные. Важно решить, что остается строго внутри периметра, что можно обезличить, и какие наборы данных должны быть доступны быстро, чтобы GPU не ждали загрузок.
По безопасности лучше сразу описать границы: сегментация сети, роли и доступы (админы, ML-инженеры, аналитики), аудит действий, изоляция проектов и порядок выдачи учетных записей. Для госорганизаций и финансового сектора часто добавляются требования регуляторов и внутренние политики.
И в конце - «земные» ограничения: сроки закупки и поставки, бюджет, требования к локальному производителю и сервису. Если работаете с интегратором, удобно заранее собрать требования в документ приемки: так позже меньше споров о том, что именно должны были запустить и к какому сроку.
Готовность площадки: стойка, место, доступ и обслуживание
До того как обсуждать питание и сеть, честно ответьте на вопрос: куда именно встанет NVIDIA DGX для on-prem ИИ и как вы будете обслуживать его в обычный рабочий день.
Начните со стойки и механики. Проверьте глубину и крепления, весовую нагрузку (оборудование, кабели), а также пол и направляющие. Заранее продумайте путь заноса: дверные проемы, лифт, повороты, пандусы. Запуск нередко тормозится не из-за ИТ, а из-за того, что коробку нельзя безопасно доставить в серверную.
Отдельная тема - кабельные трассы. Если оптику и силовые кабели уложить «как получится», быстро появятся перегибы, натяжение, путаница при поиске порта и лишние риски при обслуживании. Лучше сразу заложить понятную схему: разнести силовые и слаботочные трассы, предусмотреть запас длины, маркировку и аккуратные точки фиксации. Это мелочь, которая потом экономит часы.
План обслуживания должен отвечать на вопрос: можно ли добраться до фронта и тыла без разборки полстойки. Оставьте рабочие коридоры, убедитесь, что выдвижные рельсы открываются, а фильтры, вентиляторы и кабели доступны для замены. Если доступ к тылу перекрыт соседней стойкой, любая замена сетевого модуля превращается в ночное окно простоя.
Проверьте условия помещения: стабильная температура, контролируемая влажность, минимум пыли, понятный режим уборки. Добавьте контроль доступа и журнал работ, чтобы было ясно, кто и когда менял кабели или открывал стойку.
Короткая проверка готовности площадки:
- стойка и пол выдерживают вес, есть место для монтажа и выдвижения
- маршрут доставки согласован и реально проходим
- трассы для силовых и оптических кабелей разведены и промаркированы
- обеспечен доступ к фронту и тылу для обслуживания без остановки соседних систем
- помещение соответствует требованиям по температуре, влажности, пыли и доступу
Если вы работаете с интегратором, полезно заранее попросить шаблон требований к площадке и пройтись по нему на месте вместе с эксплуатацией. Это снижает шанс сюрпризов в день монтажа.
Питание: мощности, резервирование и проверка на практике
Для NVIDIA DGX для on-prem ИИ питание - это не просто «хватит ли киловатт». Важно, выдержит ли площадка пики, как быстро вы заметите перегрузку, и что именно останется работать при аварии.
Начните с расчета потребления: берите паспортные значения каждого узла и добавляйте запас под пики и рост (обычно закладывают минимум 15-30%). Отдельно учтите сетевое оборудование, системы хранения и консольную инфраструктуру. Реальная картина часто отличается, когда одновременно идут обучение модели, интенсивный обмен по сети и активная запись в хранилище.
Дальше - резервирование. Два независимых ввода питания выглядят красиво на схеме, но «независимость» нужно подтвердить: разные трассы кабелей, разные автоматы, разные PDU, по возможности разные источники на уровне щита. Частая ошибка - оба ввода сходятся в один и тот же распределительный узел, и одна авария отключает все.
Проверьте PDU и защиту: номиналы автоматов, нужные разъемы под конкретное оборудование, баланс фаз в стойке (если используется трехфазное питание). Перекос по фазам и перегрев контактов - частая причина нестабильности под нагрузкой, хотя «по сумме киловатт» все сходится.
С UPS и дизелем определите простое правило: сколько минут вы должны держать нагрузку и что именно считается приоритетом. Иногда цель - пережить краткий провал сети и корректно завершить работу. Иногда - сохранить непрерывность сервисов и мониторинга, даже если вычисления временно остановлены.
Перед привозом оборудования сделайте измерения на месте. Минимальный чек-лист:
- фактическое напряжение и просадки под тестовой нагрузкой
- наличие двух независимых линий и корректность переключений
- запас по автоматам/PDU и отсутствие перегрева на соединениях
- баланс фаз в стойке (если применимо)
- поведение UPS: время автономии и корректное завершение работы
Практичный сценарий: подключите временную нагрузку (нагрузочные модули или согласованный эквивалент), прогоните 1-2 часа, зафиксируйте токи, температуру в точках подключения и логи UPS. Если уже на этом этапе видны скачки, срабатывания защиты или перегрев, лучше исправить сейчас, чем искать причину после установки DGX.
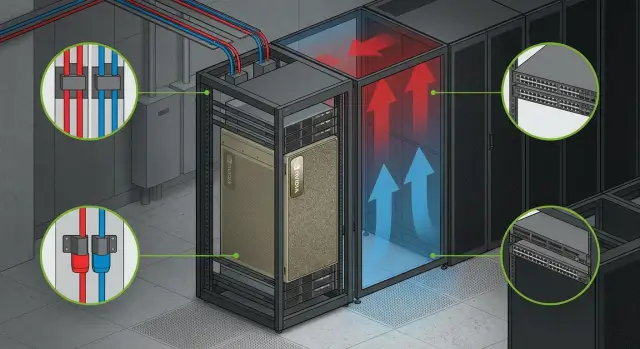
Охлаждение: как не перегреть GPU и не сорвать запуск
Для GPU-серверов угроза не только в «высокой температуре в помещении», а в перегреве на входе в конкретный сервер. Поэтому считать охлаждение «по площади» опасно: два похожих зала могут дать разный результат из-за потоков воздуха, высоты фальшпола, плотности стоек и того, как уложены кабели.
Если вы ставите NVIDIA DGX для on-prem ИИ, начните с простой оценки: сколько тепла будет выделять стойка в рабочем режиме и куда оно уйдет. На практике критична не средняя температура в зале, а стабильная подача холодного воздуха к фронту оборудования и предсказуемый отвод горячего воздуха из горячей зоны.
Холодный и горячий коридор без перестройки ЦОД
Даже без капитальных работ риск перегрева заметно снижается, если соблюсти базовые правила: холодный воздух приходит к лицевой стороне серверов, горячий выходит сзади и не смешивается обратно.
Быстрый эффект обычно дают простые действия: развернуть стойки фронтами в холодный коридор, поставить заглушки (blanking panels) в пустые юниты, закрыть щели вокруг кабельных вводов и между стойками, не перекрывать воздухозабор плотной укладкой кабелей, проверить, что вентиляторы в стойке и сервере не «борются» друг с другом по направлению потока.
Датчики и точки измерения
Температуру стоит мерить там, где она важна: на входе в сервер (фронт стойки) и на выходе (тыл). Полезно иметь датчики вверху, середине и внизу, потому что в плотных стойках верх часто оказывается горячее.
Обычно ориентируются на рекомендации производителя (часто 18-27 C на входе) и следят, чтобы температура не «гуляла» при скачках нагрузки. Важен и перепад между входом и выходом: резкий рост часто означает проблемы с потоком воздуха.
Приемочный тест по температуре
Перед вводом в эксплуатацию проведите короткий, но честный тест: создайте устойчивую вычислительную нагрузку (обучение модели или синтетический стресс) и проверьте, что система не уходит в троттлинг.
Критерии приемки можно зафиксировать так:
- нагрузка держится непрерывно 2-4 часа без аварийных остановок
- температура на входе в сервер стабильна и не превышает порог
- нет признаков троттлинга из-за перегрева (падение частот, резкое снижение производительности)
- горячий воздух не «закольцовывается» в холодный коридор
Если тест не проходит, часто помогает не «добавлять кондиционеры», а исправить мелочи в стойке и коридорах. В проектах системной интеграции такие проверки обычно делают до финальной приемки, чтобы запуск не сорвался из-за одной щели или неверного направления потоков.
Сеть: схема подключений и требования к пропускной способности
Сеть в проекте NVIDIA DGX для on-prem ИИ решает две задачи: дать GPU быстрый доступ к данным и не мешать администрированию. Типовая ошибка выглядит так: железо готово, но обучение идет медленно из-за «пробки» между сервером, хранилищем и пользователями.
Практичный подход - разделить трафик по смыслу. Обычно делают отдельные сегменты для management (доступ админов и сервисов), data (обмен между узлами и приложениями), storage (доступ к хранилищу) и out-of-band (удаленное управление, если основная сеть недоступна). Так проще и безопасность, и диагностика: быстрее видно, где растут задержки.
Топология зависит от масштаба: один DGX или рост до кластера. Для одиночной стойки часто хватает ToR-коммутатора (верх стойки) с понятным планом портов. Если через 6-12 месяцев планируются новые GPU-узлы, имеет смысл заранее смотреть в сторону spine-leaf: дороже на старте, но легче масштабировать без переделки всей схемы.
Узкое место бывает разным. При обучении чаще всего упираются в доступ к датасету и параллельные чтения (GPU ждут данные). При инференсе нагрузка более «рваная»: важны стабильные задержки до приложений и достаточная полоса для выдачи результатов при пике запросов.
RDMA и низкие задержки нужны не всегда. Если у вас один сервер и данные лежат локально, эффект может быть небольшим. RDMA становится важнее при распределенном обучении на нескольких узлах и при интенсивном доступе к сетевому хранилищу.
Чтобы сеть не стала сюрпризом на монтаже, заранее соберите портовую ведомость и правила кабелей:
- какие порты на DGX заняты под data, storage, management и OOB
- типы подключений (оптика или DAC) и длины трасс
- маркировка на обоих концах и единый формат имен
- запас портов и кабелей (обычно 10-20% на рост и замену)
- где и чем измеряете задержки и реальную пропускную способность
Если интеграцию ведет команда интегратора, полезно запросить не только схему, но и результаты тестов: измеренную полосу до хранилища и стабильность задержек под нагрузкой. Так подтверждается, что сеть готова к эксплуатации, а не просто «подключена».
Хранилище и данные: чтобы GPU не простаивали
Даже если GPU в NVIDIA DGX для on-prem ИИ готовы к работе, обучение может упираться в хранилище. Симптом простой: загрузка GPU прыгает, а обучение идет заметно медленнее ожиданий.
Начните с профиля нагрузки. Для большого последовательного чтения важнее пропускная способность в ГБ/с. Для множества мелких файлов и параллельных потоков важнее задержка и IOPS. Если данные лежат далеко (например, на другом сегменте сети или через медленный шлюз), даже хорошее хранилище будет казаться медленным из-за задержек.
Полезно заранее разложить потоки данных по типам: датасеты для обучения (много чтения, часто параллельно), чекпойнты модели (периодическая запись крупных файлов, критично для восстановления), артефакты (экспорты и результаты), логи и метрики (много мелких записей, важна стабильность).
Резервное копирование проще обсуждать через две цифры. RPO - сколько данных вы готовы потерять по времени (например, последние 4 часа обучения). RTO - за сколько вы должны восстановиться и снова запустить задачи (например, за 2 часа). Эти значения подсказывают, нужны ли частые снимки, отдельная зона для бэкапов и насколько быстро должно подниматься хранилище после сбоя.
Не менее важно, кто имеет доступ к данным. Для организаций с чувствительными данными заранее определите сегментацию: где лежат датасеты, кто может читать, кто может удалять, и кто вообще имеет право выгружать результаты наружу. Это проще сделать до запуска, чем потом разбирать инциденты.
Перед вводом в эксплуатацию проведите тест «по вашим сценариям», а не по паспорту: копирование набора файлов, параллельное чтение несколькими задачами, запись чекпойнтов. Минимальный набор проверок:
- стабильная скорость чтения датасета при 2-4 одновременных задачах
- время записи чекпойнта укладывается в допустимое окно
- логи и метрики пишутся без задержек и пропусков
- права доступа проверены на реальных ролях пользователей
- есть понятный план бэкапа и тест восстановления
Если проект делаете с интегратором, имеет смысл включить эти измерения в приемку. Тогда фраза «GPU не простаивали» становится проверяемым критерием.
ПО и доступы: от установки до правил работы пользователей
Когда «железо» уже на месте, судьбу проекта часто решает софт и правила доступа. Для NVIDIA DGX для on-prem ИИ важно заранее выбрать базовый стек и договориться, кто и как запускает задачи. Иначе первые недели уйдут на хаос и ручные правки.
Базовый стек и план обновлений
Начните с понятного, повторяемого образа системы: проверенная версия ОС, драйверы GPU, CUDA-окружение и контейнерный слой (например, Docker с NVIDIA Container Toolkit или Kubernetes, если он уже принят в компании). Контейнеры удобны тем, что команды приносят зависимости в образах, а инфраструктура остается стабильной.
Сразу зафиксируйте окно обновлений: как часто обновляются драйверы, CUDA и прошивки, кто согласует изменения и как быстро можно откатиться. Практичный вариант - тестовый узел или тестовый пул, где обновления проверяют на типовых задачах (обучение, инференс, загрузка данных) до вывода в прод.
Минимум, который стоит утвердить до запуска: матрицу совместимости (ОС, драйвер, CUDA, контейнерный рантайм), стандартные образы для популярных фреймворков и инференса, политику обновлений и отката, учет пакетов и лицензий (если используются коммерческие компоненты), шаблоны конфигураций для сетевых и storage-клиентов.
Доступ, очереди и безопасность
Разделите роли. Админы отвечают за ОС, драйверы, сеть, хранилище и безопасность. Инженеры платформы поддерживают контейнерные образы и пайплайны. Исследователи и дата-сайентисты получают доступ к очередям и рабочим пространствам, но не к системным настройкам.
Чтобы никто не «забрал» все GPU, нужны простые правила планировщика: лимит GPU на пользователя или команду, максимальное время задания, отдельные очереди для экспериментов и для прод-инференса, приоритет для критичных сервисов. Это можно сделать в Slurm или в Kubernetes через квоты и лимиты - важнее, чтобы правила были прозрачными.
По безопасности не ограничивайтесь паролями. Храните секреты (ключи, токены) в хранилище секретов, включите журналы действий админов, ограничьте привилегированные контейнеры и используйте контроль образов (разрешенный реестр, проверка уязвимостей, запрет «неизвестных» образов).
До «боевого» старта должна быть эксплуатационная документация: кто дежурит, как выдаются доступы, как заводятся проекты, как реагировать на инциденты, где смотреть логи, и что считается изменением, требующим согласования. Если внедрение делает интегратор, попросите передать runbook-описания вместе с финальной конфигурацией и контактами ответственных.
Мониторинг и эксплуатация: как держать систему стабильной
Когда NVIDIA DGX для on-prem ИИ уже включен, главная задача меняется: не просто «запустить», а не допустить тихих проблем. У GPU-инфраструктуры сбои часто начинаются незаметно: чуть выросла температура, упала пропускная способность сети, заполнилось хранилище под логи - и через неделю вы получаете простои обучения.
Что мониторить
Мониторинг должен отвечать на один вопрос: почему GPU простаивают или задания падают. Обычно достаточно пяти групп сигналов:
- вычисления: загрузка GPU/CPU, память, ошибки GPU (ECC, Xid), перезапуски драйверов
- температуры и вентиляторы: GPU, CPU, входящая температура воздуха в стойке, скорость вентиляторов
- питание: потребление по серверам и PDU, события по ИБП, просадки и переключения на резерв
- сеть: пропускная способность, потери пакетов, ошибки портов, задержка между узлами
- хранилище: IOPS и задержки, заполнение, деградация массивов, очереди на запись
Алерты лучше делать «умными»: пороги плюс длительность (например, температура выше нормы 10 минут) плюс окно обслуживания. Обязательно настройте эскалацию: кто получает уведомление сразу, кто через 15-30 минут, и что считается инцидентом, а что предупреждением. Так меньше усталости от ложных срабатываний.
Регламенты и дежурства
Логи и аудит храните централизованно и с понятным сроком: отдельно системные события, отдельно журналы доступа пользователей, отдельно изменения конфигураций. Доступ к ним должен быть ограничен, а действия администраторов - фиксироваться.
Внутренний SLA лучше описать простыми правилами: время реакции на критический инцидент и на предупреждение, время восстановления (RTO) и допустимая потеря данных (RPO), график дежурств и каналы связи, регламент обновлений и откатов, а также кто принимает решение об остановке кластера.
По запасным частям заранее решите, что держать на месте (кабели, SFP/оптика, диски, вентиляторы, блоки питания), а что допустимо ждать по поставке. Если поддержка организована 24/7 (внутри или через партнера), закрепите это в регламенте и проверьте на учебной аварии.
Критерии «готово к эксплуатации»: быстрые проверки и приемка
Чтобы запуск NVIDIA DGX для on-prem ИИ не превратился в серию «горячих» исправлений, заранее договоритесь о проверках и о том, что именно считается приемкой. Тогда у команды будет общий ориентир: где риск уже закрыт, а где еще нет.
Быстрый чеклист перед первым включением
Перед подачей питания убедитесь, что базовые условия выполнены на площадке, а не только «на схеме»:
- питание: выделенная мощность подтверждена измерениями, работает резервирование (A/B), проверены автоматы и PDU
- охлаждение: нужные температура и поток воздуха достигаются на месте, есть запас, датчики настроены
- сеть: порты активны, согласованы скорости и MTU, кабели подписаны, доступ к management-сети есть
- доступы и безопасность: учетные записи и роли заведены, доступ через jump-хост или VPN по правилам компании, журналирование включено
- эксплуатация: есть инструкции «что делать при тревоге», контакты дежурных, порядок изменений и окно обслуживания
Тесты нагрузки и стабильности
Дальше важнее всего прогреть систему под реальной нагрузкой: минимум 1-2 часа на пиковых режимах и сутки на смешанном профиле (обучение, I/O, сеть). Смотрите не только на скорость, но и на отсутствие деградации: троттлинг GPU, рост ошибок памяти, скачки температуры, повторяющиеся перезапуски сервисов.
Сеть проверяйте отдельно: отсутствие потерь пакетов, корректный MTU (если используются jumbo frames), стабильная пропускная способность между узлами и до хранилища. Такие проверки быстро вскрывают «мелочи», которые потом стоят дней простоя.
Сценарии отказов и критерии приемки
Приемка сильнее, если вы имитируете отказы: отключите один ввод питания, один линк, один коммутатор или одну полку хранения (в рамках допустимого). Система должна остаться управляемой, а последствия - понятными.
Готово к эксплуатации, если:
- нагрузка проходит сутки без аварий и критических ошибок
- температуры и питание держатся в пределах норм с запасом
- сеть показывает согласованные показатели и не теряет пакеты
- мониторинг и алерты работают: тревоги приходят, действия понятны
- документы приемки подписаны: схемы, настройки, доступы, план поддержки
Если хотя бы один пункт не выполняется, это не «почти готово», а задача на доработку с конкретным владельцем и сроком.
Реалистичный сценарий внедрения и следующие шаги
Типовой кейс для старта: один шкаф, один узел NVIDIA DGX для on-prem ИИ, команда 2-3 инженера (ЦОД, сеть, системы) и 10-20 пользователей (data science и прикладные команды). Цель простая: запустить обучение и инференс без сюрпризов по питанию, охлаждению, сети и доступам.
План по неделям может выглядеть так:
- неделя 1: сбор требований (модели, объемы данных, окна обслуживания, требования ИБ, список пользователей и роли)
- неделя 2: обследование площадки (стойка, PDU, реальная доступная мощность, охлаждение, трассы кабелей, точки подключения сети и хранилища)
- неделя 3: подготовка ЦОД (дозаказ кабелей и оптики, настройка VLAN/ACL, резервирование питания, проверка охлаждения под нагрузкой)
- неделя 4: монтаж и базовая настройка (установка, маркировка, первичная конфигурация, учет в CMDB, доступы, базовые политики)
- неделя 5: тесты и приемка (нагрузочные прогоны, проверка отказоустойчивости, мониторинг, обучение админов и запуск пилота)
В середине проекта почти всегда всплывают «мелочи», которые съедают сроки: не хватает портов или лицензий на сетевом оборудовании, не согласованы правила доступа для пользователей, есть ограничения по теплоотводу в конкретной зоне, или неожиданно упираются в пропускную способность до хранилища. Хорошее правило - заложить запас 20-30% времени на согласования и доработки и заранее определить, кто утверждает изменения.
Результаты лучше фиксировать не «на словах», а в понятном наборе документов: паспорт стоечного размещения и кабельный журнал, актуальная сетевая схема, регламент бэкапов и обновлений, акт приемки с измерениями (мощность, температура, тесты сети, контрольные прогоны задач).
Дальше логичный путь такой: пилот на 2-4 недели с реальными задачами и квотами, затем масштабирование по узким местам из пилота (узлы, хранилище, сетевую фабрику), обучение персонала (админы, инженеры эксплуатации, пользователи) и договоренность по поддержке и SLA.
Если не хватает рук или опыта, системный интегратор может закрыть обследование, проектирование, внедрение и эксплуатацию. Например, GSE.kz (gse.kz) как производитель и системный интегратор в Казахстане занимается поставкой серверной инфраструктуры, интеграцией в ЦОД и обеспечивает круглосуточную техническую поддержку через сервисную сеть.
FAQ
С чего реально начинать проект DGX on‑prem, чтобы не застрять на «мелочах»?
Начните с конкретных сценариев и метрик: что будет делаться ежедневно (обучение, инференс, RAG, аналитика), какие задержки и окна доступности нужны, сколько команд работает параллельно и какой допустимый простой. Это сразу покажет, где критичны сеть и хранилище, а где важнее правила доступа и очереди. Дальше зафиксируйте то, что дорого менять: место в стойке, питание и резервирование, охлаждение, сетевую топологию и размещение данных.
Какие причины чаще всего срывают запуск DGX в ЦОД?
Самое частое — неподтвержденная готовность площадки: питание «по паспорту» без проверки пиков и ИБП, перегрев на входе в сервер из‑за потоков воздуха, сеть как для обычных серверов с неожиданными задержками, и хранилище, которое не дает нужную скорость чтения. Еще одна причина — отсутствие заранее согласованных ролей и правил: кто администрирует, кто запускает задачи, как выдаются доступы и кто принимает изменения.
Какие метрики стоит согласовать до закупки и монтажа?
Да, если заранее написать 4–5 измеримых целей. Типичный минимум: время обучения эталонной задачи, задержка инференса на запрос и на пике, допустимое окно обслуживания, число параллельных пользователей/команд и допустимый простой при сбоях. С этими метриками проще принять инфраструктуру: вы проверяете не «включилось», а «работает в нужном режиме».
Как правильно описать требования к данным для on‑prem ИИ?
Соберите три вещи: текущий объем и прогноз роста на 6–12 месяцев, чувствительность данных (что строго внутри периметра, что можно обезличить), и требования к скорости доступа для горячих датасетов. Если данные должны быть «быстрыми», продумайте, где они лежат физически и по сети, иначе GPU будут ждать загрузки и реальная производительность окажется ниже ожиданий.
Как понять, что питания точно хватит и резервирование работает?
Проверьте не только общий киловатт, а поведение под нагрузкой: пики потребления, просадки напряжения, корректность работы ИБП и реальную независимость двух вводов A/B. Полезная практика — прогон тестовой нагрузки 1–2 часа с фиксацией токов, температуры соединений и логов ИБП. Это дешевле, чем искать причину уже после установки GPU‑сервера.
Что важнее всего в охлаждении DGX и как это проверить?
Смотрите на температуру на входе в сервер, а не «среднюю по залу». В плотных стойках критичны потоки воздуха, заглушки в пустых юнитах, отсутствие щелей и то, чтобы кабели не перекрывали воздухозабор. Перед приемкой сделайте 2–4 часа устойчивой вычислительной нагрузки и убедитесь, что нет троттлинга и температура на входе держится в пределах нормы.
Какой минимальный подход к сети, чтобы обучение не упиралось в задержки?
Разделите трафик по назначению: управление, данные, доступ к хранилищу и отдельный канал для удаленного управления. Так проще и безопасность, и поиск проблем. Готовность сети подтверждается измерениями под нагрузкой: реальная пропускная способность до хранилища и стабильность задержек, а не только тем, что «линк поднялся».
Как выбрать хранилище и доказать, что оно не станет узким местом?
Сначала определите профиль I/O: большой поток последовательного чтения упирается в ГБ/с, множество мелких файлов — в задержку и IOPS. Разнесите по смыслу датасеты, чекпойнты, артефакты и логи, потому что у них разные требования. Перед запуском прогоните тесты «как в жизни»: параллельное чтение несколькими задачами и запись чекпойнтов в допустимое окно. Если эти проверки не проходят, GPU почти наверняка будут простаивать.
Что нужно решить по ПО и доступам до «боевого» старта?
Зафиксируйте базовый повторяемый образ: ОС, драйверы, CUDA и контейнерный слой. Затем договоритесь об окне обновлений, ответственных и откате, чтобы изменения не ломали рабочие пайплайны. По доступам разделите роли и введите простые правила очередей и квот на GPU, иначе первые недели уйдут на конфликты за ресурсы и ручные разборы.
Какие критерии показывают, что DGX действительно «готов к эксплуатации»?
Приемка должна проверять стабильность, а не только производительность. Минимум — сутки смешанной нагрузки без аварий, нормальные температуры и питание с запасом, сеть без потерь и с согласованными показателями, работающие алерты и понятные действия дежурных. Также важно, чтобы были переданы актуальные схемы, настройки, журнал кабелей и регламенты поддержки. Если проект ведет интегратор, например GSE.kz, это лучше включить в состав сдаваемых материалов и критериев приемки заранее.