Минимальная CMDB для компании 100-500: сущности и связи
Минимальная CMDB для компании 100-500 сотрудников: какие сущности и связи завести, чтобы инциденты и изменения быстро привязывались к активам без бюрократии.
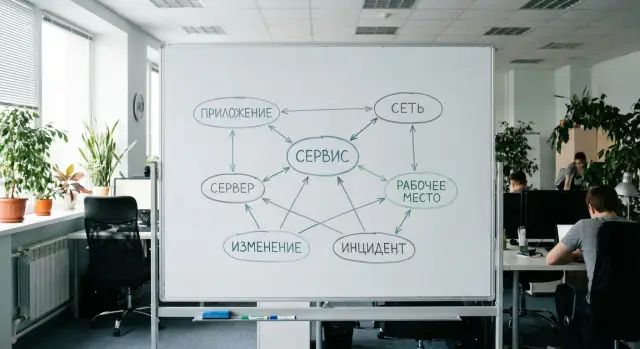
Зачем компании на 100-500 сотрудников минимальная CMDB
В компании на 100-500 сотрудников обычно уже есть сервис-деск, учет техники и какие-то регламенты. Но во время инцидента всплывает одна и та же боль: тикет живет отдельно, а ответы на простые вопросы приходится искать вручную. Что именно сломалось, какие пользователи пострадали, где это стоит, что меняли вчера и кто отвечает.
Минимальная CMDB нужна не ради «красивой базы», а ради связки инцидент - актив - изменение. Когда у инцидента есть привязка к конкретному ИТ-сервису и его ключевым компонентам, причину находят быстрее, повторяемость становится виднее, а улучшения надежности можно подтверждать фактами. Когда изменения фиксируются на тех же объектах, становится понятно, какие работы реально повышают стабильность, а какие создают новые сбои.
Избыточная детализация почти всегда ломает внедрение. Если пытаться описать все кабели, каждую настройку и весь софт на каждом ПК, CMDB превращается в бесконечный проект. Данные устаревают, и команда перестает ей пользоваться. Для старта важнее покрыть только то, что влияет на простои и массовые обращения.
Успех на первом этапе видно по простым признакам:
- большинство инцидентов привязано к сервису или активу, а не к абстрактному «не работает интернет»
- по каждому крупному сбою понятно, какие изменения были перед ним
- время на первичную диагностику заметно сокращается
- в отчетах появляется топ проблемных компонентов, а не только список тикетов
Пример: «не работает 1С» перестает быть одним типом жалобы и превращается в конкретный инцидент по сервису, связанному с сервером или ВМ, сетевым узлом и последним изменением (например, обновлением). Даже в смешанной инфраструктуре, где есть рабочие места и серверы (в том числе локальные), такой минимум дает контроль без бюрократии.
Где заканчивается учет активов и начинается CMDB
Учет активов отвечает на вопрос «что у нас есть и где это находится». CMDB отвечает на другой: «что влияет на работу сервисов и как это связано с инцидентами и изменениями». Если объект не помогает быстрее чинить, безопаснее менять или яснее понимать влияние, ему не место в CMDB.
Граница на практике простая. В учете, на складе и в договорах обычно живут цены, амортизация, серийные номера, гарантия, накладные, комплектация и «сколько мышек выдано». В CMDB оставляют то, что нужно поддержке и управлению изменениями: кто владелец, где стоит, чем управляется, к какому сервису относится, что от чего зависит.
Принцип 80/20 для минимальной CMDB работает отлично: лучше иметь немного данных, но всегда актуальных. Самые полезные 20% - те, по которым вы за 2 минуты отвечаете на три вопроса: что сломалось, кого затронуло, что меняли рядом.
Чтобы CMDB не превратилась в «реестр всего подряд», введите правило допуска: каждая сущность должна отвечать на вопрос поддержки или изменения. Удобно проверять по короткому списку:
- поможет ли это быстрее найти причину инцидента?
- поможет ли оценить влияние (кого и что затронет)?
- поможет ли безопаснее провести изменение и откат?
- есть ли у этого объекта владелец и ответственный за актуальность?
- сможете ли вы поддерживать эти данные без ручной рутины?
Пример. В компании упал доступ к бухгалтерии. Если в CMDB есть связь «ИТ-сервис Бухгалтерия -> приложение -> сервер/ВМ -> площадка», дежурный быстро видит, что проблема на конкретной ВМ в филиале, и что вчера там меняли сетевые правила. А «какая модель монитора у бухгалтера» для такого инцидента почти никогда не нужна - пусть остается в учете имущества.
Сущность 1: ИТ-сервис как главный объект
Если вы строите минимальную CMDB, начинайте не с железа, а с ИТ-сервисов. Сервис - это то, что пользователь понимает как «работает или не работает»: почта, 1С/ERP, VPN, корпоративный Wi-Fi, печать, доступ к файлам.
Так вы связываете инциденты и изменения с понятным объектом. Пользователю проще выбрать «Почта», чем «SRV-EXCH-03». Вам проще увидеть, какие компоненты и какие команды поддержки стоят за этим сервисом.
Чтобы не утонуть в согласованиях, у сервиса достаточно минимального набора полей:
- название и короткое описание «для кого и зачем»
- владелец сервиса (один человек) и группа поддержки (одна команда)
- критичность (например: высокая, средняя, низкая)
- окно поддержки (например: 9:00-18:00, 24/7)
- кому предоставляется (отделы или группы пользователей)
Владелец нужен не для сложных процедур, а чтобы быстро решать спорные вопросы: что восстанавливать первым, можно ли делать изменение в рабочее время, кого уведомлять.
Связь «сервис - пользователи/подразделения» держите на уровне списка, без детальной модели ролей. Например: «VPN - все сотрудники + подрядчики», «1С/ERP - бухгалтерия и закупки», «Wi-Fi - офис и переговорные». Этого достаточно, чтобы при инциденте быстро оценить охват, а при изменении - риск.
Пример: если падает «Почта», инцидент заводится на сервис, подтягивается группа поддержки и критичность. При плановом обновлении почтового сервера изменение тоже привязывается к сервису, и сразу видно, какие пользователи затронуты и какое окно поддержки подходит.
Сущность 2: Приложения и компоненты сервиса
Если ИТ-сервис отвечает на вопрос «что получает бизнес», то приложение отвечает на вопрос «за счет чего это работает». В минимальной CMDB приложения удобно вести как часть сервиса, а не как отдельный «зоопарк систем». Тогда по инциденту быстрее видно, что именно могло сломаться и где искать причину.
Приложение стоит описывать не «по максимуму», а ровно настолько, чтобы инциденты и изменения связывались без ручных расследований. Обычно хватает деления на клиентскую часть (рабочие места или браузер) и серверную часть (API, веб-сервер, фоновые задачи). Даже если приложение монолитное, это полезно: вы отделяете «пользователь не может войти» от «бэкенд не отвечает».
Минимальный набор полей для карточки приложения:
- название и к какому сервису относится
- среда: продуктив или тест (часто достаточно prod и non-prod)
- ответственный: техлид/админ/владелец поддержки (кому звонить в 2 ночи)
- поставщик или подрядчик (если есть), чтобы понимать границы ответственности
Связи важнее полей. Приложение должно быть связано с узлами (серверы и ВМ), где оно реально работает. Тогда в инциденте сразу видно affected CI: например, «портал заявок недоступен» связан с приложением, а оно связано с двумя ВМ и балансировщиком.
Базы данных не нужно описывать полностью. Но если они критичны для простоя, заведите их как отдельные элементы и свяжите с приложением. Тогда при изменении (патч БД, перенос, настройка бэкапов) риск для продактива виден сразу.
Сущность 3: Узлы (серверы и виртуальные машины)
Для компании на 100-500 сотрудников удобно завести один тип конфигурационной единицы - «узел». В него попадают физический сервер, виртуальная машина и даже облачный экземпляр. Так минимальная CMDB не превращается в набор сущностей, а инциденты проще привязывать к одному понятному объекту.
Держите карточку узла короткой. Поля должны отвечать на вопрос «что это, где это и кто за это отвечает». Обычно хватает:
- имя (hostname) и уникальный ID
- роль (например, web, БД, файловый, терминальный)
- среда (prod, test, dev)
- расположение (площадка, серверная, при необходимости стойка)
- ОС и владелец (команда или ответственный)
С кластерами лучше не усложнять. Вместо детальной топологии заведите логическую группу «кластер» и связывайте с ней узлы, которые вместе дают один результат (например, «кластер БД бухгалтерии»). В инциденте вы отмечаете группу, а дальше видите список узлов. Обычно этого достаточно, чтобы оценить риск и масштаб.
Связи у узла должны быть практичными. Минимум - «узел -> приложение/компонент», чтобы понимать, какой сервис пострадает. Часто полезно добавить «узел -> сеть/сегмент» (например, DMZ или офисная сеть) и «узел -> площадка/стойка», если это реально влияет на простои.
Пример: ночью пропадает доступ к порталу. Инцидент привязывают к приложению «Портал» и узлу WEB-PROD-01. По связям видно, что узел в DMZ на площадке А и входит в логическую группу «кластер веб». Дальше проще проверить, было ли недавно изменение по этому узлу или по сегменту сети, и не тратить время на поиск «где это вообще работает».
Сущность 4: Рабочие места и пользователи
Рабочее место имеет смысл заводить как конфигурационную единицу не всегда. В минимальной CMDB это оправдано, когда проблемы часто затрагивают сразу много сотрудников (массовые инциденты после обновления ОС, сбой антивируса, дефект партии ноутбуков) или когда важна безопасность (кто работал на устройстве, где оно находится, какие политики применены).
Чтобы рабочие места реально помогали поддержке, держите карточку короткой, но однозначной. Обычно достаточно того, что легко собрать из закупок, образов ОС и учета пользователей:
- текущий пользователь (или владелец)
- подразделение
- модель
- серийный номер
- версия ОС
Дальше снова важнее связи, а не детали. Самая полезная цепочка выглядит так: рабочее место -> пользователь -> группа поддержки. Тогда заявка от человека быстрее «понимает», какое устройство затронуто, и куда ее направить (Service Desk, рабочие места, информационная безопасность).
Пример: после обновления Windows у бухгалтерии перестал печатать клиент-банк. Если рабочие места связаны с пользователями и подразделениями, видно, что это одна модель ноутбука и одна версия ОС. Это уже похоже на один массовый инцидент и одно изменение, а не на 30 отдельных обращений.
Границы здесь особенно важны. Периферию (мыши, гарнитуры, мониторы) учитывайте как CI только если по ней часто заводят заявки или она реально влияет на простой. Иначе будет много карточек и мало пользы: поддержка начнет тратить время на учет вместо решения проблем.
Сущность 5: Сеть и площадки (только то, что влияет на простои)
Сеть легко превратить в бесконечный чертеж. В минимальной CMDB лучше заносить только то, что реально помогает быстрее чинить и безопаснее менять, когда что-то упало.
Обычно достаточно описать опорные элементы: главный маршрутизатор на площадке, ключевые коммутаторы, контроллер Wi-Fi (если от него зависит офис), межфилиальные и интернет-каналы, а также точки подключения, через которые проходят критичные сервисы. Остальное (порты, второстепенные коммутаторы, подробная L2/L3-топология) храните в сетевой документации, а не в CMDB, если этим не пользуются каждый день.
Чтобы карточка сети работала, поля должны быть понятны любому дежурному:
- площадка (офис, филиал, дата-узел)
- роль (ядро, edge, Wi-Fi, канал)
- ответственный (внутренний владелец/команда)
- провайдер и контакты эскалации (для каналов)
- критичность (что будет, если элемент недоступен)
Самое важное - связь «сеть -> сервисы». Для каждого канала или узла сети отметьте несколько сервисов, которые от него зависят (почта, телефония, ERP, терминалы в торговой точке). Тогда при инциденте «Нет интернета в филиале» вы быстрее понимаете, какие сервисы считать затронутыми, кого предупреждать и какие обходные варианты проверять.
Пример: провайдер меняет оборудование на канале. Если канал связан с сервисом «кассы» и «VPN в головной офис», то изменение сразу получает понятный риск и список проверок после работ. Без полной схемы сети, но с нужными связями.
Связи с инцидентами и изменениями: что должно работать всегда
Если CMDB небольшая, но связи в ней надежные, вы уже выигрываете. В минимальной CMDB для компании на 100-500 человек важнее не количество карточек, а то, чтобы инцидент и изменение всегда приводили к понятному ответу: что пострадало, что меняли и кто отвечает.
Минимальная карточка изменения
Карточка изменения должна быть короткой, чтобы ее реально заполняли. Но в ней обязаны быть данные, без которых потом невозможно разобраться в простое:
- что меняем (кратко и конкретно)
- когда меняем (окно работ)
- ответственный (один владелец)
- затронутые CI (сервис, приложение, узел)
- план отката (что делаем, если стало хуже)
Ключевое правило: изменение не закрывается, пока не заполнена связь «изменение -> CI». Не нужно описывать все зависимости. Достаточно указать 1-3 CI, которые реально могут вызвать инцидент.
Как привязывать инциденты, чтобы искать причину за минуты
В инциденте должна быть связь «инцидент -> CI». Если пользователи жалуются на «не работает почта», выбирается CI сервиса «Почта», а не конкретный сервер, если он неизвестен на старте.
Второй обязательный шаг: если перед проблемой было изменение, инцидент связывается с ним как с «последним релевантным изменением». Пример: после обновления драйвера на рабочих местах часть сотрудников потеряла доступ к корпоративной системе. Тогда инцидент привязывается к CI «Рабочее место» (или группе рабочих мест) и к изменению «обновление драйвера». Дальше проще увидеть масштаб и быстро откатиться.
Согласование тоже можно держать без лишней нагрузки:
- владелец сервиса подтверждает влияние на пользователей
- техвладелец компонента подтверждает техническую часть
- CAB (или ИТ-руководитель) нужен только для рискованных изменений в рабочее время
Как внедрить минимальную CMDB за 30-60 дней
Минимальная CMDB работает, когда вы описываете только то, что реально помогает связывать инциденты, активы и изменения. Цель на 30-60 дней простая: чтобы дежурный и инженер за минуту понимали, какой сервис пострадал, на каком узле, и какое изменение могло повлиять.
План на 5 шагов
-
Выберите 5-10 самых критичных для бизнеса ИТ-сервисов и заведите их как конфигурационные единицы. Начните с тех, из-за которых чаще всего бывают простои или жалобы: почта, 1-2 ключевые бизнес-системы, интернет-доступ, телефония.
-
Для каждого сервиса добавьте приложения и только ключевые компоненты. Ориентир: 1-3 приложения на сервис и 3-10 узлов (серверы, ВМ, важные базы данных), без попытки описать все подряд.
-
Введите правило: у каждого инцидента должно быть заполнено поле CI. Если пользователь не знает, что выбрать, пусть выбирает сервис. Дальше диспетчер уточняет до приложения или узла. Это быстро формирует привычку и дает статистику.
-
Запустите управление изменениями только для критичных CI. Не заставляйте команду оформлять изменения на каждом ноутбуке. Достаточно фиксировать то, что может уронить сервис: обновления, настройки, миграции, замены узлов.
-
Раз в месяц делайте короткую чистку: убирайте дубли, уточняйте связи, закрывайте пробелы там, где инциденты регулярно привязывают к «неизвестному».
Практический ориентир: если ночью падает «Бухгалтерия», инженер открывает сервис, видит связанные приложения и узлы, проверяет последние изменения по ним и быстрее находит причину. Так минимальная CMDB начинает приносить пользу без лишней бюрократии.
Типичные ошибки и как их избежать
Самая частая ошибка - пытаться описать в CMDB все активы и все зависимости с первого дня. Для компании на 100-500 сотрудников это обычно заканчивается тем, что база становится большой, но пустой по смыслу: половина карточек не нужна для разборов простоев, а актуальность теряется через пару месяцев. Начинайте с того, что реально помогает связывать инциденты, активы и изменения.
Ошибка 1: «Заполним все поля и будет порядок»
Когда в карточке 20 обязательных полей, люди перестают ее заводить или начинают писать «123» и «неизвестно». Лучше оставить минимум, который можно поддерживать каждый день: понятное имя, тип CI, владелец, среда (prod/test), критичность и ключевые связи (к сервису, узлу, пользователю).
Рабочее правило: новое обязательное поле появляется только если оно уже помогло хотя бы в 3 реальных разборах инцидентов.
Ошибка 2: CMDB без владельцев и без изменений
Если у конфигурационной единицы нет владельца, актуальность становится ничьей задачей. А если изменения не оставляют след в CMDB, она превращается в справочник, который красиво выглядит, но не объясняет, почему все упало.
Набор привычек, который обычно работает:
- назначьте владельца на каждый сервис и на ключевые узлы (не на все подряд)
- привязывайте каждое плановое изменение к затронутым CI хотя бы на уровне «сервис - узел»
- договоритесь о едином шаблоне имен (например, APP-ERP, SRV-DB01)
- раз в неделю разбирайте 5-10 «сомнительных» карточек: без владельца, без связей, с непонятным названием
- при обнаружении дубля не создавайте третий: объединяйте и фиксируйте «правильное» имя
Пример: после ночного обновления на ВМ с базой данных пошли инциденты в бухгалтерском сервисе. Если изменение связано с ВМ и сервисом, поиск причины занимает минуты. Если связи нет, команда часами перебирает версии: сеть, пользователи, приложение, лицензии.
Короткий чеклист: достаточно ли вашей CMDB для работы
Минимальная CMDB считается рабочей не тогда, когда в ней «все учтено», а когда она помогает быстро ответить на два вопроса: что именно сломалось и что меняли перед этим.
Проверьте себя по признакам:
- есть короткий список критичных ИТ-сервисов (обычно 10-30), и у каждого есть владелец, который может назвать приоритет
- в каждом инциденте выбран хотя бы один CI: сервис (если проблема массовая) или рабочее место (если точечно)
- в каждом изменении указаны затронутые CI и есть понятный план отката
- есть небольшой набор сетевых и площадочных CI (примерно 10-20), которые реально влияют на простои: основной интернет-канал, ключевой коммутатор, VPN-шлюз, гипервизорный кластер, площадка/офис как объект
- раз в месяц вы делаете короткую проверку актуальности: убираете дубли, объединяете «двойные» записи, закрываете пробелы по критичным сервисам
Быстрый тест на практике
Откройте последние 10 инцидентов с самым высоким влиянием. Если в 7-8 из них есть привязка к CI и рядом видны последние изменения по этим CI, значит минимальная CMDB уже выполняет свою роль. Если нет, чаще всего не хватает не данных, а дисциплины: выбирать CI при регистрации и указывать CI при изменении.
Когда чеклист «зеленый», но пользы мало
Так бывает, если CI слишком детализированы. Для компании на 100-500 сотрудников лучше один «Сервис: почта» и «Узел: почтовый сервер», чем 50 компонентов, которые никто не обновляет.
Пример из жизни: как связать инцидент с активом и изменением
В понедельник с утра пользователи жалуются: ERP открывается по 20-30 секунд, а печать счетов «замирает». В сервис-деск приходит один общий инцидент, но важно быстро понять, где узкое место, не собирая «всю инфраструктуру компании» в CMDB.
Диспетчер открывает инцидент и в поле «Затронутые CI» выбирает не «сервер №17», а сначала ИТ-сервис: «ERP и печать документов». Это сразу отделяет проблему сервиса от единичной поломки рабочего места.
Дальше по связям в CMDB видно, из чего сервис собран:
- сервис: «ERP и печать документов»
- приложение: «ERP backend» и «Print Gateway»
- узлы: VM-ERP-01 и VM-PRINT-01 (или физический сервер, если печать на нем)
- сеть/площадка: VLAN-Office-3 и коммутатор SW-3F-12 (только если реально влияет на простои)
Пара быстрых проверок показывает, что у части пользователей ERP тормозит, а печать срывается только на 3-м этаже. Это наводит на мысль про сеть. Инженер открывает карточку коммутатора SW-3F-12 и смотрит «последнее изменение». Там запись: «в пятницу вечером обновили прошивку и поменяли настройки QoS». Теперь есть конкретная гипотеза и конкретный объект, а не «все медленно».
Исправление оформляют как изменение и привязывают к тем же CI: SW-3F-12, VLAN-Office-3 и сервис «ERP и печать документов». В плане указывают простые шаги: вернуть прошлый профиль QoS, проверить нагрузку порта, сделать контрольный тест печати. После выполнения в инциденте видно, какое изменение его закрыло.
Что реально помогло: имя сервиса, список ключевых приложений, привязка к узлам и история изменений по узлу или сетевому устройству. Лишним оказалось хранить в этой цепочке серийные номера всех принтеров, полные схемы этажей и описание каждого порта, если это не участвует в разборе простоев.
Следующие шаги: как расширять CMDB без лишней нагрузки
Минимальная CMDB не обязана вырастать в огромный справочник. Ее стоит расширять только там, где это снижает простои и ускоряет решения. Начните с трех сервисов, где час недоступности действительно стоит дорого (например, бухгалтерия, контакт-центр, электронная регистратура).
Дальше важно не добавлять новые сущности, пока не понятны правила обновления. У каждой конфигурационной единицы должен быть владелец: не «ИТ в целом», а конкретная роль или команда. Владелец отвечает за то, чтобы изменения в сервисе отражались в CMDB хотя бы на уровне связей.
Чтобы не спорить о полях, заранее договоритесь о минимальных шаблонах. Они должны оставаться короткими: что это, где находится, кто владелец и с чем связано. Когда это закреплено, расширение превращается в повторяемую привычку.
Порядок расширения, который обычно не создает бюрократии:
- добавляйте новые CI только после 2-3 повторяющихся инцидентов на одном и том же участке
- сначала фиксируйте связи (сервис -> приложение -> узел), а детали заполняйте по мере необходимости
- закрепите правило: каждое изменение в критичном сервисе обновляет CMDB в тот же день
- раз в месяц делайте короткую проверку: 10 случайных CI и их связи
Если вы упираетесь в инфраструктуру или в стык процессов (инциденты, изменения, мониторинг), иногда проще подключить системного интегратора. Например, GSE.kz (gse.kz) как производитель и системный интегратор помогает с инфраструктурой под критичные сервисы, подбором серверов и рабочих станций, а также с поддержкой, чтобы CMDB опиралась на реальную, управляемую базу оборудования.
FAQ
Зачем вообще нужна минимальная CMDB, если уже есть сервис-деск и учет техники?
Минимальная CMDB нужна, чтобы в каждом инциденте было понятно, *что именно* сломалось (сервис/компонент), *кого* задело и *что меняли* перед этим. Это снижает время первичной диагностики и помогает видеть повторяющиеся причины, а не просто считать тикеты.
С чего начать CMDB, чтобы не утонуть в объеме?
Начните с ИТ-сервисов, а не с железа. Выберите 5–10 самых критичных сервисов, заведите владельца и группу поддержки, затем привяжите к каждому сервису 1–3 приложения и несколько ключевых узлов (серверы/ВМ/экземпляры), на которых реально держится работа.
Где проходит граница между учетом активов и CMDB?
Учет активов отвечает на «что у нас есть и где», а CMDB — на «что влияет на работу сервисов и как связано с инцидентами и изменениями». Если объект не помогает быстрее восстановить сервис, оценить влияние или безопаснее провести изменение, оставьте его в учете имущества, а не тащите в CMDB.
Какие поля должны быть у ИТ-сервиса в минимальной CMDB?
Достаточно короткой карточки: название, краткое описание «для кого и зачем», владелец (один человек), группа поддержки, критичность и окно поддержки. Добавьте простую привязку к аудитории (какие отделы или группы пользователей), чтобы при сбое быстро понять масштаб и приоритет восстановления.
Что выбирать в инциденте: сервис или конкретный сервер/ВМ?
Если пользователь не знает инфраструктуру, он должен выбирать сервис, а не сервер. Правило простое: инцидент регистрируется на сервис, а диспетчер при разборе уточняет до приложения или узла, когда это стало понятно. Так вы не теряете время на угадывание CI в момент регистрации.
Как связать изменения с CMDB, чтобы реально находить причину сбоев?
Записывайте изменения коротко, но обязательно связывайте их с 1–3 затронутыми CI (сервис, приложение, узел) и фиксируйте окно работ, ответственного и план отката. Без этой связи потом почти невозможно доказать, что сбой связан с конкретными работами, и команда начинает «перебирать версии».
Как правильно описывать серверы и виртуальные машины, чтобы не усложнять модель?
Сведите их в один тип CI «узел», куда попадают физические серверы, ВМ и облачные экземпляры. В карточке держите минимум: hostname/ID, роль, среда (prod/test), расположение и владелец. Кластера проще вести как логическую группу, чтобы не усложнять топологию, но видеть состав и риск.
Нужно ли включать рабочие места пользователей в CMDB?
Заводите рабочие места как CI, когда это помогает ловить массовые инциденты (после обновлений, сбоев антивируса, проблем с политиками) или важно для безопасности. Минимум в карточке — пользователь/владелец, подразделение, модель, серийный номер и версия ОС; остальное добавляйте только если это реально участвует в разборе инцидентов.
Как описывать сеть в CMDB, не превращая ее в бесконечную схему?
Добавляйте только опорные элементы, которые реально влияют на простои: ключевые каналы, пограничные устройства, ядро на площадке, контроллер Wi‑Fi (если критичен), основные точки отказа. Важно не описать каждый порт, а связать сетевые CI с сервисами, чтобы при «упал интернет в филиале» сразу было ясно, какие сервисы считаются затронутыми.
Как понять, что минимальная CMDB уже работает и приносит пользу?
Поставьте простые метрики: доля инцидентов с заполненным CI, видимость «последнего релевантного изменения» рядом с крупными сбоями и снижение времени первичной диагностики. Практический тест — открыть последние 10 инцидентов с высоким влиянием: если в большинстве видно, какой сервис/узел пострадал и что меняли перед этим, CMDB уже дает пользу.