Loki или OpenSearch для логов: сравнение для небольшой команды
Loki или OpenSearch для логов: сравнение хранения, скорости поиска, стоимости дисков и требований к эксплуатации для небольшой команды.
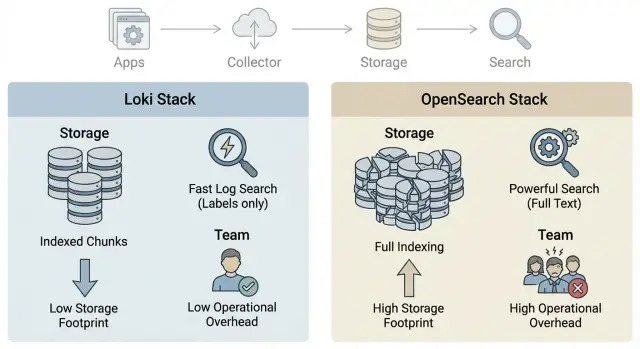
Зачем вообще сравнивать Loki и OpenSearch
Пока логов мало, почти любая схема кажется удобной: пишем в файл, смотрим через grep, иногда грузим в один индекс и не думаем о будущем. Но когда сервисов становится больше, а логов - десятки гигабайт в день, появляется типичная боль: нужная строка ищется минутами, место на дисках заканчивается внезапно, а команда тратит время не на продукт, а на аварии.
Поэтому вопрос "Loki или OpenSearch для логов" обычно возникает не из любопытства, а из усталости. Выбор хранилища напрямую влияет и на бюджет (сколько и каких дисков нужно, сколько дней хранить), и на нервы команды (сколько времени уйдет на поддержку, обновления и восстановление после сбоев).
Логирование решает разные задачи, и они тянут систему в разные стороны. Чаще всего нужно:
- быстро найти ошибку по trace-id или фрагменту сообщения
- восстановить цепочку событий перед инцидентом (таймлайн)
- выполнить аудит: кто, когда и что сделал
- получить простые счетчики и метрики из логов
Сравнение Loki и OpenSearch важно еще и потому, что они по-разному "платят" за удобство. Один вариант может быть дешевле на хранении, другой - быстрее и гибче в поиске, но заметно дороже по ресурсам и эксплуатации.
Дальше без усложнений: представим небольшую команду, которая сама эксплуатирует систему, ограничена по времени и хочет предсказуемые расходы, а не проект на полгода.
Базовые понятия простыми словами
Путь логов обычно простой: приложение пишет строки (или JSON), агент на сервере их подхватывает, отправляет в хранилище, а вы ищете и смотрите результаты в интерфейсе. Разница между Loki и OpenSearch начинается именно на этапе хранения и поиска.
OpenSearch (как и Elasticsearch) делает ставку на индексы. Проще всего думать об индексе как об оглавлении: заранее подготовленная структура, которая помогает быстро находить записи. За скорость платите диском и ресурсами, потому что хранится не только исходный текст логов, но и служебные данные для поиска.
Loki чаще хранит логи ближе к "архиву": основной упор на сжатый текст и метки (labels). Идея такая: по меткам вы быстро отбираете нужный поток (например, service=api и env=prod), а уже внутри выбранного диапазона ищете по тексту. Индексации содержимого обычно меньше, поэтому хранение выходит дешевле, но поиск "по любому слову везде" может быть тяжелее. Он сильнее зависит от того, насколько хорошо продуманы метки.
Если свести к двум подходам:
- OpenSearch: больше структуры и индексов, быстрее сложные запросы, дороже хранение и эксплуатация.
- Loki: меньше индексов, дешевле хранение, важнее дисциплина меток, поиск по тексту чаще упирается в правильную предфильтрацию.
Вокруг любой из систем почти всегда есть одни и те же компоненты: сборщик логов на узлах, доставка (буфер и повторы), хранилище и визуализация с дашбордами и алертами. Если команда небольшая, заранее решите, кто отвечает за схему полей или метки, сроки хранения и доступы. Эти "мелочи" потом определяют и скорость, и цену, и количество ночных инцидентов.
Хранение логов: объем, срок и тип дисков
Хранение решает большую часть споров про Loki и OpenSearch. Эти системы по-разному складывают данные, и из-за этого по-разному тратят диски.
В OpenSearch логи превращаются в индексы и сегменты на диске. Это удобно для сложного поиска, но индекс часто занимает заметно больше места, чем исходный текст. Обычно используют локальные SSD в кластере, иногда делят данные на "теплый" и "холодный" уровни.
В Loki индекс минимальный (в основном метки), а сами логи сохраняются в сжатые чанки. Для небольшой команды самый экономный вариант часто получается, когда чанки лежат в объектном хранилище (S3-совместимое или аналог), а на локальных дисках остается только то, что нужно для работы и кеша.
Рост объема редко связан только с количеством сервисов. Гораздо сильнее влияют уровень детализации (INFO против DEBUG), частота однотипных событий и формат. Если каждое событие пишется как большой JSON с дублирующимися полями, хранение раздувается в разы.
Срок хранения (retention) почти всегда важнее выбора диска. 7 дней и 30 дней отличаются не "чуть-чуть", а в 4+ раза по месту, а значит по цене, бэкапам и времени восстановления.
Чтобы держать стоимость под контролем, заранее определите, что будет горячим (последние 3-7 дней на SSD), а что может стать холодным (недели или месяцы на более дешевом хранилище). Заодно решите, какие логи можно хранить короче (например, отладочные), и какие поля точно не нужны в каждом сообщении.
Небольшой пример: команда пишет 50 ГБ логов в день. При retention 30 дней это уже 1,5 ТБ исходных данных, а с индексами, репликами и запасом под рост получится в несколько раз больше. Поэтому "сколько дней хранить" и "где лежит холодный слой" обычно дают больший эффект, чем попытки выиграть пару процентов на типе диска.
Скорость поиска: что реально влияет
Под "скоростью" обычно имеют в виду простые задачи: найти ошибку по trace-id, посмотреть события конкретного пользователя, отфильтровать ответы 500 или быстро собрать выборку по сервису за последние 15 минут. Здесь важна не только платформа, но и то, как вы описали данные.
В OpenSearch скорость держится на индексах и полях. Если вы заранее выделили нужные поля (trace_id, user_id, status_code, service, env) и они индексируются, точечные запросы работают быстро даже на больших объемах. Если же все складывается как один большой текст, системе приходится делать тяжелый поиск, и время ответа растет.
В Loki ключевую роль играют метки и предфильтрация по ним. Хороший запрос сначала сужает поток по нескольким меткам (например, service + env + pod), и только потом ищет строку или шаблон в тексте. Если меток мало или они слишком общие, Loki будет читать больше данных, и поиск станет заметно медленнее.
Обычно ускоряют поиск в обеих моделях одни и те же вещи: четкая схема (как называются поля), узкое окно времени, фильтры по источнику (сервис, окружение, кластер), а уже потом полнотекстовый поиск. Помогают и стабильные форматы логов: структурированный JSON почти всегда проще фильтровать, чем "текст обо всем".
Чаще всего замедляет обратное: полнотекстовый поиск без фильтров и без ограничения времени, запросы уровня "покажи все ошибки за месяц" без понятной цели, слишком широкие метки или поля, а также непродуманная кардинальность (когда уникальные значения растут бесконтрольно, например request_id в метках).
Оценивать скорость честно стоит на одинаковом объеме данных и одинаковых запросах, которые реально делает команда. Выберите 3-5 типовых сценариев (trace-id, пользователь, 500, конкретный сервис, пик нагрузки) и прогоните их на одном и том же периоде. Часто "медленно" оказывается не из-за Loki или OpenSearch, а из-за того, что логи пишутся без структуры, и фильтровать просто нечем.
Стоимость: диски, ресурсы и скрытые расходы
Разговор о стоимости почти всегда начинается с дисков, но заканчивается тем, сколько узлов придется держать ради приемлемой скорости.
Бюджет складывается из пяти частей: место под данные, CPU и RAM для приема и запросов, сеть (особенно на пиках), резервное копирование и время людей на поддержку. В OpenSearch вы платите не только за объем, но и за то, что индексы любят память и быстрый I/O. В Loki часто дешевле хранение (особенно с объектным хранилищем), но сложные запросы и высокий параллелизм тоже требуют ресурсов.
Дешевый диск может стать дорогим, если он тормозит. Переход на HDD иногда снижает цену за 1 ТБ, но из-за медленного чтения и записи может потребоваться больше узлов, чтобы пережить пики. Итоговый счет вырастет, а команда будет чаще разбирать аварии.
Чаще всего забывают заложить рост логов в 2-3 раза за год, пики (релиз, инцидент, массовые ретраи), реплики (часто x2 к диску) и запас под перестройку данных после падений. Туда же относятся бэкапы, тест восстановления (а не "галочка") и временные файлы под компакцию. Наконец, есть цена времени: если поиск медленный, инженер тратит часы вместо минут.
Удобно считать в простых величинах: цена за 1 ТБ в месяц при нужном сроке хранения. Берете средний объем логов в день, умножаете на дни хранения, добавляете запас на рост и пики (например, +50%), затем умножаете на коэффициент репликации. Так получается, сколько терабайт вы реально оплачиваете. Дальше сравниваете два сценария: больше дешевого места с более тяжелым поиском или меньше, но быстрее, где запросы не заставляют раздувать кластер.
Эксплуатация в небольшой команде: где будет боль
Когда у вас 2-5 человек на всю инфраструктуру, главный вопрос не "что быстрее", а "что не разбудит нас ночью". Инструменты часто выбирают по функционалу, но выигрывает тот вариант, который проще держать в порядке без выделенного SRE.
Что обычно съедает время
Боль приходит не в первый день, а через 2-4 недели, когда логи растут, а задачи по продукту никуда не делись. Время чаще всего уходит на обновления и совместимость версий (агенты, хранилище, визуализация), ретеншн и контроль заполнения дисков, бэкапы и проверку восстановления, алерты и разбор ложных срабатываний. Отдельная категория - инциденты, когда "поиск ничего не находит", хотя проблема точно была.
У OpenSearch операционных задач обычно больше: кластер, шарды, состояние индексов, планирование ресурсов. Зато он знаком тем, кто уже работал с Elasticsearch. Loki часто проще по хранению, но требует дисциплины по меткам: если команда начнет делать метки из всего подряд, можно быстро упереться в нагрузку и стоимость.
Практики, без которых будет боль
В небольшой команде лучше заранее договориться о минимальных правилах, иначе система постепенно "разъедется".
Нужен мониторинг самой системы логирования: задержка ingestion, ошибки записи, заполнение дисков, латентность запросов. Нужен контроль роста: лимиты на объем, понятные сроки хранения для prod и stage, регулярный пересмотр. Важно разграничение доступа: кто видит все, кто только свои сервисы, где лежат секреты. И обязательно план действий на сбои: что делаем при переполнении диска, недоступности хранилища или падении узла.
Не менее важно договориться о формате логов: одинаковые поля (service, env, trace_id), чтобы поиск не превращался в угадайку. Простой пример: кто-то добавил в метки Loki поле user_id, и через неделю кардинальность взлетела. Или в OpenSearch включили слишком подробную индексацию, и кластер начал тратить CPU на сегменты. Такие вещи редко заметны сразу, поэтому полезен короткий регламент и одно место, где команда ежедневно смотрит здоровье логов.
Как выбрать: пошаговый план для команды
Начните не с названий инструментов, а с того, как люди реально ищут и читают логи. Тогда выбор превращается в проверку гипотез, а не спор вкусов.
Соберите команду на 30 минут и пройдите по шагам:
- Запишите 3-5 самых частых запросов: по сервису, по ошибке, по пользователю, по времени инцидента. Сразу уточните, нужны ли агрегации и отчеты (например, топ ошибок за день) или чаще нужно "найти конкретный след".
- Определите срок хранения и терпимую задержку доставки: 7 дней или 90, нужны ли свежие логи за последние минуты, что приемлемо при задержке 5-10 минут.
- Зафиксируйте формат и минимум полей. Обычно хватает timestamp, уровня (info/warn/error), сервиса, окружения (prod/stage), trace_id или request_id и текста сообщения.
- Сделайте пилот на реальных данных за 7-14 дней: тот же объем, те же источники, те же боевые запросы.
- Сведите итоги в таблицу: стоимость хранения и рост объема, скорость типовых запросов, сколько часов в неделю уходит на поддержку (обновления, ретеншн, алерты, разбор ошибок индексации).
И отдельно закрепите правила письма логов: кто отвечает за структуру, как именуются поля, что нельзя писать (секреты, персональные данные), и как проверять качество логов перед релизом. Один короткий документ часто дает больше пользы, чем замена системы.
Частые ошибки и ловушки
Самая частая проблема - попытка собрать все логи и хранить их "на всякий случай". В проде включают максимальную детализацию, не ставят лимиты на объем и не режут шум (health-check, debug от библиотек, частые 404). Через неделю заканчивается место, а искать в этом море становится только сложнее.
Вторая ловушка - отсутствие правил, как именовать поля и метки. В Loki это проявляется как "взрыв" меток (слишком много уникальных значений), а в OpenSearch - как хаос в схемах, когда одно и то же событие в разных сервисах описано по-разному. Итог одинаковый: запросы не совпадают с данными, и люди начинают "искать глазами" по сырым строкам.
Нередко срок хранения выбирают наугад: "давайте 90 дней". Но без оценки дневного объема, сжатия, репликации и типа дисков это превращается в лотерею. Особенно если выводы делаются по текущему маленькому объему.
Еще одна опасная ловушка - доступ "всем ко всему". Логи часто содержат имена пользователей, токены, адреса, детали ошибок. Без ролей, маскирования и базовых правил риск утечки резко растет. Для организаций с требованиями к безопасности (например, в госсекторе или финансах) это легко становится блокером проекта.
И наконец, пилот на крошечном объеме дает ложное ощущение, что "все летает". На 5 ГБ в день поиск быстрый, а через пару месяцев при 200-500 ГБ в день внезапно не хватает ни дисков, ни памяти, ни времени на поддержку.
Короткая проверка, которая обычно спасает:
- Ограничьте уровни логирования в проде и отрежьте шумные источники.
- Утвердите единые имена полей и обязательные метки (сервис, среда, версия).
- Посчитайте хранение от фактов: ГБ в день x срок x репликация, затем выбирайте диски.
- Настройте роли и доступ по командам и окружениям.
- Проверьте масштабирование на данных, близких к "через полгода", а не к "сегодня".
Короткий чеклист перед решением
Чтобы снять споры на уровне вкуса, за 20 минут соберите ответы на несколько вопросов.
Сначала договоритесь о цифрах: текущий объем логов в сутки и рост на 3-6 месяцев. Типичная ошибка - взять среднее за неделю и забыть про пики (релизы, инциденты, сезонность). Пики часто решают, какие диски и сколько узлов понадобятся.
Затем уточните правила хранения. Разделите логи по типам и срокам: логи приложений часто можно держать короче, а аудит и безопасность - дольше. Разные сроки проще контролировать и по цене, и по рискам.
Проверьте, что именно вы ищете каждый день. Составьте список самых частых запросов (хотя бы 10) и отметьте, какие должны открываться быстро. Обычно это поиск ошибок по сервису и времени, фильтр по пользователю или заказу, поиск по trace-id или request-id, расследование инцидента по нескольким ключевым полям и выборка за период для отчета.
Отдельно зафиксируйте требования к надежности: что будет, если поиск по логам недоступен 1 час, и сколько времени вы готовы ждать восстановления после сбоя.
И последний пункт часто самый практичный: кто будет дежурить по системе. Назначьте владельца эксплуатации и честно оцените, сколько времени в неделю вы готовы тратить на обновления, место на дисках, ретеншн, бэкапы и разбор алертов. Если ответ "почти некому", выбирайте решение, где меньше ручной работы именно в вашей реальности.
Реалистичный пример: небольшая команда и рост логов
Команда из 8 человек поддерживает 6 сервисов: два монолита на VM и четыре контейнерных сервиса. Релизы идут 2-3 раза в неделю, и главная боль - быстро найти ошибку сразу после выкладки. Реже бывают инциденты, когда нужно поднять цепочку событий за сутки-двое и понять, где началось.
Выделенного инженера по платформе нет. Логи смотрят по очереди: сегодня разработчик, завтра дежурный. Бюджет на диски ограничен, поэтому хранить все месяцами "как есть" не получится. Команда решает начать с 30 дней хранения и пересмотреть позже.
Чтобы сравнение было честным, запускают пилот на одинаковых входных данных. Берут один и тот же набор источников (например, логи API, воркера, базы-прокси и ingress) и прогоняют одни и те же запросы: "ошибки за последние 15 минут", "все события по request_id", "пики 5xx после релиза". Важно заранее договориться, что считается "поиском": от ввода запроса до понятного ответа, а не только скорость движка.
Критерии успеха простые:
- время ответа на 3-5 типовых запросов в часы пик
- стоимость хранения на 30 дней при реальном объеме (включая репликации)
- сколько ручных действий нужно в неделю (ротация, алерты, падения, обновления)
- насколько легко новичку найти нужное (шаблоны запросов, понятные поля)
- как система ведет себя при росте в 2 раза без полной перестройки
Часто по итогу выходит так: Loki проще поддерживать и дешевле на дисках, если вы в основном фильтруете по меткам и времени. OpenSearch выигрывает, когда нужен поиск "как по тексту" и по множеству полей, но за это платите индексами, ресурсами и большей сложностью эксплуатации.
Следующие шаги: пилот, инфраструктура и поддержка
После сравнения не пытайтесь сразу выбрать "победителя". Сведите решение к 2-3 понятным вариантам архитектуры и обсудите их с теми, кто будет дежурить и чинить сбои. На практике спор чаще решает то, как вы реально ищете ошибки, и кто будет обслуживать систему.
Перед запуском пилота зафиксируйте критерии успеха. Иначе через две недели теста окажется, что каждый измерял "удобство" по-своему, а данные собраны не те.
Мини-пилот: что именно проверить
Пилот лучше сделать коротким, но честным: 7-14 дней, реальные логи, реальная нагрузка. Возьмите один критичный сервис и один "шумный", чтобы увидеть крайние случаи.
Проверьте:
- скорость ответа на 3-5 типовых запросов (ошибки по коду, поиск по trace-id, скачок latency)
- стоимость хранения: сколько места заняли логи за сутки и прогноз на 30-90 дней
- надежность: что происходит при падении агента или узла, как быстро восстанавливается прием
- операционные задачи: обновление, бэкапы, ротация, кто и как это делает
- безопасность и доступы: разграничение по командам и окружениям
Инфраструктура и поддержка
Закладывайте запас по дискам и памяти под рост: объем логов почти всегда увеличивается быстрее, чем ожидают. Если логирование начинает влиять на прод, лучше сразу отделить ресурсы под хранение и поиск от бизнес-сервисов. Для таких задач часто используют стойковые серверы уровня GSE S200 Series, чтобы не делить вычисления с приложениями и проще планировать емкость.
Если вы в Казахстане и вам важны предсказуемые поставки и поддержка, можно заранее обсудить вариант с локальным производителем и системной интеграцией от GSE.kz (gse.kz). Это удобно, когда нужно закрыть железо, внедрение и дальнейшую эксплуатацию, а у команды мало времени на ручную сборку и ночные разборы.
Последний шаг - назначить ответственных: кто владелец платформы логов, кто отвечает за доступы, и кто принимает решение по итогам пилота, с конкретной датой.
FAQ
Когда вообще имеет смысл выбирать между Loki и OpenSearch, а не ставить «что угодно»?
Сравнивайте, когда логов стало много и поиск начал занимать минуты, а диски заканчиваются неожиданно. На маленьких объемах обе системы кажутся удобными, но при росте разница в цене хранения и усилиях на поддержку становится заметной.
Что обычно выходит дешевле по дискам: Loki или OpenSearch?
По умолчанию Loki обычно дешевле по хранению, потому что делает упор на сжатые чанки и небольшой индекс по меткам. OpenSearch чаще требует больше диска из‑за индексов и служебных данных, но может выигрывать в сложном поиске и аналитике по множеству полей.
Что будет быстрее в реальных задачах: найти ошибку по trace-id и посмотреть события вокруг инцидента?
Если вы часто ищете по множеству полей и хотите быстрые точечные запросы при хорошем маппинге, OpenSearch обычно быстрее. Если вы почти всегда сначала фильтруете по сервису, окружению и времени, а потом ищете строку в пределах узкого набора, Loki работает нормально и часто проще по стоимости.
Какие данные нужно заранее выделить: метки в Loki или поля в OpenSearch?
Для Loki главное — продуманные метки, которые быстро сужают поток логов до нужного сервиса и окружения, но не раздувают количество уникальных значений. Для OpenSearch важно выделить ключевые поля (например, trace_id, user_id, status_code) и индексировать их, иначе вы будете искать как по обычному тексту и терять скорость.
Какие метки в Loki чаще всего приводят к проблемам?
Не делайте метки из значений, которые почти всегда уникальны, вроде request_id, user_id или полного URL, иначе кардинальность быстро вырастет и система начнет дорого «дышать». Лучше держать в метках то, что хорошо группирует потоки: service, env, cluster, namespace, а уникальные идентификаторы оставлять в тексте или структурированных полях.
С чего начать расчеты: с выбора дисков или с retention?
Начните с срока хранения, потому что он сильнее всего влияет на цену и операционные риски. Дальше измерьте реальный дневной объем, добавьте запас на рост и пики, учтите репликацию и только потом выбирайте диски и размер кластера.
Почему поиск «вдруг стал медленным», хотя вчера все работало?
Обычно виноваты слишком широкие запросы без ограничения по времени и без фильтров по источнику, а не «плохая» система. Сначала сузьте окно времени, затем отфильтруйте по service/env (или индексируемым полям), и только потом используйте поиск по тексту.
Какие метрики и алерты нужны, чтобы система логов не ломалась внезапно?
Минимум — мониторинг задержки приема логов, ошибок записи, заполнения дисков или бакета, а также латентности запросов. Если эти метрики не смотрят ежедневно, проблема обычно обнаруживается уже тогда, когда место закончилось или поиск стал непредсказуемым.
Как безопасно организовать доступ к логам, чтобы не было утечек?
По умолчанию запрещайте попадание секретов и персональных данных в логи и настройте доступы по ролям и окружениям. Дополнительно полезно иметь понятные правила, что именно логировать в проде, чтобы не собирать лишнее и не расширять круг тех, кто видит чувствительную информацию.
Как провести честный пилот Loki против OpenSearch и не обмануться результатами?
Сделайте пилот на реальных логах за 7–14 дней и проверьте одинаковые сценарии: ошибки после релиза, поиск по trace-id, выборки по 5xx и расследование инцидента за сутки. Фиксируйте не только время ответа, но и сколько ручной работы требуется на обновления, ретеншн и разбор сбоев — для небольшой команды это часто решающий фактор.