LLM в закрытом контуре без интернета: референс-архитектура
Как построить LLM в закрытом контуре без интернета: репозиторий моделей, офлайн-обновления, контроль зависимостей, SBOM и сканирование пакетов.
Задача простыми словами: LLM без интернета и сюрпризов
LLM в закрытом контуре без интернета - это когда модель, данные и весь софт для ее запуска работают внутри вашей сети и не обращаются наружу ни за ответами, ни за обновлениями, ни за "мелочами" вроде догрузки библиотек. Такой подход выбирают там, где важны конфиденциальность, контроль поставок и понятные правила эксплуатации.
С LLM сложнее, чем с обычным приложением, потому что кроме кода появляется тяжелый артефакт (веса модели), цепочка зависимостей (драйверы, CPU/GPU-библиотеки, Python-пакеты, контейнерные образы) и привычка многих инструментов "подтягивать" нужное из интернета по ходу работы. В закрытой сети любая такая попытка превращается в сбой или, хуже, в обход политики.
Чаще всего беспокоят три группы рисков. Первое - утечки: промпты, документы, логи или метаданные могут случайно уйти во внешние сервисы. Второе - вредоносные пакеты и подмена артефактов: один компрометированный компонент в цепочке поставки может открыть доступ к контуру. Третье - неподконтрольные обновления: когда модель, библиотека или контейнер меняются "сами", а результат внезапно становится другим.
Ролей здесь обычно больше, чем ожидают. ИБ задает правила изоляции, проверки и допуска артефактов. ИТ отвечает за инфраструктуру, учетные записи, резервное копирование и поддержку. Закупки и комплаенс смотрят на лицензии, происхождение и статус поставщика. Владельцы данных определяют, что можно отдавать модели и как хранить контент.
Успех измеряется не только качеством ответов. Важно, чтобы система была предсказуемой (изменения плановые), проверяемой (понятно, что именно запущено) и воспроизводимой (сборку и запуск можно повторить один в один). Тогда LLM становится управляемым сервисом, а не "черным ящиком", который живет по своим правилам.
Требования и границы: что нужно зафиксировать до дизайна
Прежде чем рисовать схему, договоритесь о правилах игры. В закрытом контуре любые "мелочи" вроде логов, обновлений и прав доступа быстро превращаются в риск или в стопор для эксплуатации.
Начните с классов данных: какие документы модель может видеть, какие нельзя даже загружать в контур, а какие допустимы только в обезличенном виде. Отдельно зафиксируйте запреты на вынос: что считается утечкой (текст ответа, эмбеддинги, метаданные запросов, фрагменты документов в логах) и где граница между "внутренним" и "внешним".
Дальше - журналирование и трассируемость. Нужны понятные ответы на вопросы: кто запускал модель, с какой версией, на каком наборе данных, какие изменения были внесены и кем они одобрены. Сразу определите, что логируем, как долго храним, кто имеет доступ и как защищаем логи от подмены.
Определите уровень изоляции. Контур может быть полностью офлайн, либо иметь редкие контролируемые "окна" для доставки обновлений. Это влияет на все: от процесса патчей до выбора инструментов репликации.
Практические ограничения тоже важны: доступное железо (CPU, GPU, диски, сеть), допустимое время простоя и максимальный срок, за который вы обязаны поставить обновление модели или пакетов. Если парк серверов фиксирован (так часто бывает в госсекторе), архитектуру лучше сразу подбирать под реальную конфигурацию, а не под "идеальные" мощности.
Критерии приемки со стороны ИБ удобнее держать коротким списком:
- утвержденные классы данных и правила обезличивания
- контроль версий моделей и зависимостей с аудитом изменений
- политика логирования и сроков хранения
- процесс офлайн-обновлений с проверками до ввода
- результаты сканирования уязвимостей и план устранения
Когда эти границы записаны, дизайн референс-архитектуры перестает быть спором "как удобнее" и становится задачей "как выполнить требования без обходных путей".
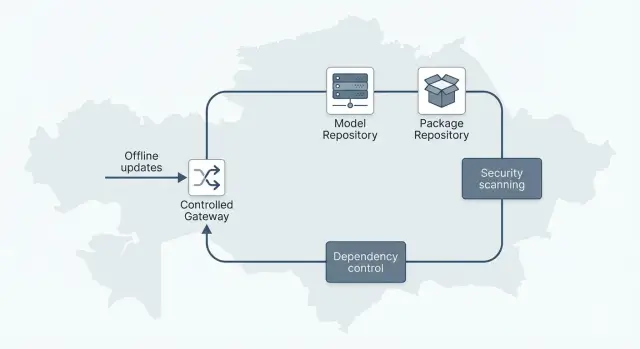
Референс-архитектура: из каких частей состоит контур
Чтобы LLM в закрытом контуре работала предсказуемо, контур лучше собирать как конвейер. У каждой части есть роль, а у каждой версии - владелец и журнал изменений. Тогда вы точно знаете, что запущено, откуда это взялось и кто это одобрил.
Базовые блоки контура
Обычно хватает пяти опорных компонентов. Они могут быть отдельными системами или функциями одной платформы, но логика должна сохраняться:
- вычислительный слой: GPU/CPU узлы для инференса и (если нужно) дообучения
- хранилище артефактов: модели, токенизаторы, датасеты, контейнеры, веса, промпт-шаблоны
- контроль зависимостей: фиксированные версии библиотек, сборок и окружений, плюс SBOM для каждой поставки
- сканирование: проверка пакетов и образов на уязвимости и запрещенные компоненты до запуска
- оркестрация и доступ: запуск сервисов, квоты, аудит, секреты, роли и права
Потоки и точки контроля
Ключевой принцип - единая точка правды для версий. Один реестр (или согласованный набор реестров) хранит утвержденные артефакты, и только из него разрешен запуск.
Поток поставки обычно такой: внешняя команда формирует пакет (модель + зависимости + SBOM), затем он попадает в карантинную зону, проходит сканирование и проверку политик, после чего ответственный утверждает выпуск. Только затем артефакты продвигаются в офлайн-репозиторий и становятся доступными для теста и продакшена.
Разделение сред важно даже без интернета: песочница для экспериментов, тест для воспроизводимых прогонов и нагрузочных проверок, продуктив для стабильной работы. Между средами - только продвижение утвержденных версий, без ручных копирований.
Отдельно закрепите запрет неявных загрузок. При запуске нельзя подтягивать модели, плагины и пакеты "по умолчанию". Любой внешний вызов должен быть явным, отключаемым и отраженным в аудит-логах.
Репозиторий моделей: хранение, версии и права доступа
В закрытом контуре репозиторий моделей - это единый источник правды. Он должен хранить не только "веса", но и все, без чего модель нельзя безопасно воспроизвести и проверить. В офлайн-среде нельзя "быстро скачать недостающее", поэтому полнота релиза критична.
Практичное правило: одна модель = один набор артефактов, который можно развернуть заново и получить тот же результат.
Обычно в единый релиз кладут: веса модели (в том числе шардированные, если нужно), токенизатор и его словарь, конфиги запуска и инференса (параметры, лимиты, контекст), лицензию и карточку модели (источник и ограничения использования), а также эталонные промпты и небольшой тестовый набор для регрессии.
С версионированием проще всего жить, когда оно строгое и читаемое: теги по схеме вроде model-name:vX.Y.Z, плюс неизменяемый идентификатор сборки (хэш) и подпись. Тогда любой запуск в продакшене можно привязать к конкретному артефакту и доказать, что он не менялся.
Права доступа лучше разделять по ролям. Читать могут многие (например, команды интеграции), публиковать - только сборочная линия, а утверждать - владелец продукта и служба ИБ. Если у вас строгие закупки и отчетность (часто так в госсекторе, банках, медицине), такой поток согласований быстро окупается.
Отдельно продумайте квантованные и оптимизированные варианты. Храните их как производные от базовой версии, с явной пометкой (int8, int4, gguf и т.д.) и с теми же тестами на качество. Это защищает от ситуации, когда модель "ускорили" и незаметно сломали ответы на критичных запросах.
Контроль зависимостей: чтобы сборка повторялась один в один
В офлайн-контуре главная угроза не только в утечках, но и в том, что сборка сегодня и завтра внезапно окажется разной. Это ломает тесты, усложняет расследования и превращает обновления в лотерею.
Первый шаг - организовать зеркала пакетов и запретить любые прямые скачивания извне. Зеркалировать стоит только то, что реально используется: Python-пакеты, системные пакеты (rpm/deb), контейнерные образы, большие артефакты (модели, токенизаторы). Запрещайте все "динамические" источники: установку по git-веткам, теги "latest", скачивание скриптами во время сборки. Если компонент нельзя получить из вашего зеркала, он не должен попадать в прод.
Фиксация версий - это не формальность. Держите lock-файлы (для Python и контейнеров) и правило воспроизводимой сборки: одна и та же спецификация должна давать одинаковый набор файлов. На практике это удобно проверять в CI: собрать дважды и сравнить хэши ключевых артефактов.
SBOM (перечень компонентов) храните рядом с релизом, как часть поставки. Включайте в него зависимости приложения (пакеты и версии), базовые образы и системные библиотеки, ML-артефакты (модель, токенизатор, их хэши), а также инструменты сборки, которые влияют на результат.
Иногда оправдан вендоринг: заранее собрать локальные wheels или заморозить зависимости в отдельный "bundle", если пакеты часто исчезают или требуют сложной сборки без интернета. Это повышает вашу ответственность за обновления, поэтому такой подход лучше применять точечно.
И еще одно практичное правило: разделяйте dev и prod зависимости (отдельные репозитории или хотя бы отдельные lock-файлы). Тогда тестовые утилиты и "удобные" библиотеки не окажутся внутри боевого контура.
Сканирование пакетов и артефактов: контроль до запуска
В закрытом контуре главный риск не "внешний взлом", а то, что внутрь однажды попадет сомнительный компонент, и вы узнаете об этом слишком поздно. Поэтому сканирование стоит сделать обязательным этапом поставки, а не разовой проверкой.
Проверяйте не только Python-пакеты. В реальном стеке уязвимость может сидеть в базовом образе, системной библиотеке или "невинном" утилитарном бинарнике рядом с моделью. Минимум того, что имеет смысл сканировать:
- пакеты и зависимости (pip/conda/apt), включая транзитивные
- контейнерные образы и базовые слои
- образы ОС и системные библиотеки (OpenSSL, glibc и т.д.)
- артефакты модели: веса, токенизатор, конфиги, скрипты инференса
- файлы сборки и метаданные: lock-файлы, манифесты, SBOM
Важно, когда именно запускается контроль. Хорошая практика - несколько "ворот" качества: при импорте в изолированный репозиторий (первичная фильтрация), перед публикацией артефакта как "доверенного", и перед выкладкой в prod (финальная проверка того, что ничего не изменилось).
Политики блокировки должны быть простыми и исполнимыми: запрещать критические уязвимости без исключений, не пропускать неподписанные артефакты, отклонять компоненты с неизвестным источником или без хэшей. Результаты сканирования храните как часть "паспорта версии": отчет, дата, инструмент и правила, плюс хэш/подпись и привязка к конкретному тегу модели или образа.
Исключения неизбежны, но их важно "обезвредить" процессом: кто согласует (например, ИБ и владелец сервиса), на какой срок (короткий), и что является компенсацией (изоляция, отключенные функции, мониторинг). В практике системной интеграции, включая проекты GSE.kz, это часто оформляют как контролируемое окно до ближайшего офлайн-обновления, чтобы риск не становился постоянной нормой.
Офлайн-обновления: как безопасно доставлять новое внутрь
В закрытом контуре обновления - это не "скачал и поставил", а контролируемая поставка. Самая частая ошибка - переносить файлы "как получилось": кто-то принес модель на флешке, кто-то - архив с пакетами, и через месяц уже никто не помнит, что именно было установлено.
Начните с одного официального канала переноса: либо физический носитель с учетом и пломбированием, либо выделенная точка обмена (например, отдельный шлюз в демилитаризованной зоне). В любом варианте важно, чтобы у обновления был владелец и журнал: что внесли, когда, откуда и кто одобрил.
На входе в контур проверяйте не только "вирусы", а весь набор свойств, которые делают систему предсказуемой:
- подпись поставщика и подпись вашей внутренней сборки
- контрольные суммы (хэш) каждого артефакта: модель, токенизатор, конфиги
- соответствие версии и политике (что разрешено для этой среды)
- SBOM и список зависимостей для окружения инференса
- результаты сканирования пакетов и контейнеров на уязвимости
Дальше задайте ритм. Регулярные окна обновлений (например, раз в месяц) помогают не накапливать долг. Для экстренных патчей нужен отдельный быстрый маршрут с заранее согласованными критериями.
Перед выкладкой в прод проверьте обновление на стейджинге в той же конфигурации железа и драйверов, что и в бою. Прогоните короткую регрессию качества на ваших типовых запросах и тест на совместимость (драйверы, библиотеки, формат модели).
План отката держите простым: храните прошлую версию модели и окружения, переключение делайте через версионирование и атомарную смену тега, а время возврата измеряйте минутами, а не днями.
Минимизация внешних вызовов: чтобы контур оставался закрытым
Закрытый контур чаще ломается не "большими" интеграциями, а мелочами: библиотека отправила телеметрию, контейнер потянул обновление, рантайм проверил лицензию. Поэтому правило простое: по умолчанию никакого исходящего трафика, а каждое исключение должно быть объяснимым, проверяемым и легко отключаемым.
Уберите неявные сетевые обращения
Начните с инвентаризации всего, что любит "позвонить домой": автоапдейтеры, сбор метрик, краш-репорты, проверка подписок, загрузка шрифтов и токенизаторов "по умолчанию". Часто такие вызовы прячутся в настройках SDK и включены автоматически.
Практичный набор мер:
- запрет исходящих соединений на уровне сети (egress deny) для подов/ВМ с LLM
- принудительные офлайн-флаги и переменные окружения для библиотек (телеметрия, обновления, кеш)
- локальные зеркала для всего, что нужно на старте: модели, пакеты, контейнеры, документация
- центральный прокси как единственная точка выхода, если без него никак
- обязательная заявка на каждое внешнее обращение: цель, домен, сроки, владелец
Проверяйте поведение и быстро находите аномалии
Однажды команда добавит новую зависимость, и она попробует выйти в сеть. Это должно ловиться до продакшена. Добавьте "тест на тишину сети": поднимаете сервис в тестовом сегменте и проверяете, что нет DNS-запросов и исходящих соединений, кроме разрешенных.
Пример: внедряют чат-бота для внутренней базы знаний. На стенде он внезапно делает запросы к внешнему хосту из-за библиотеки аналитики. Тест фиксирует попытки, сборка блокируется, а библиотеку заменяют на внутренний трекинг.
Для расследований важны журналы доступа. Логируйте минимум: время, источник (сервис/узел), назначение (домен/IP/порт), решение (разрешено/запрещено), объем. Держите быстрый поиск по "новым доменам" и всплескам DNS, чтобы за 10 минут понять, что изменилось и кто владелец компонента.
Пошаговый план внедрения: от пилота до продакшена
Начните с одного-двух сценариев, где пользу можно измерить: поиск по внутренним документам, ответы службе поддержки, черновики писем. Сразу опишите, какие данные доступны модели, а какие запрещены, и разделите пользователей по уровням доступа (например, сотрудники, руководители, админы).
Дальше выберите базовую платформу запуска и способ упаковки. Контейнеры упрощают перенос и контроль версий, но иногда в закрытом контуре удобнее минимальная установка без контейнеров. Ключевое - разворачивать одинаково на тесте и в продакшене.
Затем соберите внутренние источники артефактов: репозиторий моделей и репозиторий пакетов. Это снимает зависимость от внешних скачиваний и помогает фиксировать точные версии. В изолированном ЦОД модель и все Python-пакеты должны браться только из внутренних хранилищ, а серверы получать одинаковый набор артефактов.
Перед масштабированием зафиксируйте правила сборки: повторяемость, SBOM, подпись артефактов. Это позволяет доказуемо понять, из чего состоит образ, и не спорить "что именно было установлено".
Переход к продакшену обычно выглядит так:
- Пилот на обезличенных или непубличных данных и базовые метрики качества.
- Внутренние репозитории моделей и пакетов, строгие права доступа.
- Сборка по шаблону, SBOM и подпись перед публикацией артефактов.
- Сканирование пакетов и образов, политика блокировок на входе.
- Процедура офлайн-обновлений: доставка, проверка подписей, регрессионные тесты, затем релиз.
Финальный штрих - регрессионный набор тестов, который ловит "тихие" поломки (качество ответов, утечки чувствительных данных, скорость) после каждого обновления модели или зависимостей.
Пример сценария: LLM для внутренней базы знаний в организации
Представим отдел методологии и комплаенса в крупной организации. Каждый день люди ищут ответы в регламентах, шаблонах писем, приказах, инструкциях, а еще делают черновики: пояснительные записки, ответы на запросы, внутренние уведомления. Интернет запрещен, потому что в документах есть персональные данные и служебная информация. Цель простая: быстрее находить нужный пункт и получать аккуратный черновик, не выводя данные наружу.
Поток работы обычно такой:
- модель и все зависимости привозят внутрь как один пакет, с версиями и контрольными суммами
- пакет проверяют: сканирование уязвимостей, сверка SBOM, проверка лицензий
- модель прогоняют через короткий набор тестов: качество ответов на эталонных вопросах, запреты на выдачу персональных данных, скорость
- после одобрения выпуск фиксируют как релиз, выкатывают в прод и включают мониторинг
- в эксплуатации ведут журнал запросов и инцидентов, чтобы разбирать спорные ответы и улучшать промпты и базу знаний
Обновления лучше делать по расписанию, например раз в месяц: так проще планировать окна, тесты и откат. Внеплановые обновления допускайте только при критических уязвимостях, и тоже через тот же конвейер проверок и тестов.
Результат стоит мерить не только "нравится или нет". Полезные метрики: стабильность ответов на одном и том же наборе вопросов, средняя задержка ответа, число ИБ-инцидентов и ложных срабатываний фильтров, а также время отката до предыдущего релиза, если что-то пошло не так.
Частые ошибки и ловушки, которые дорого обходятся
Самая частая причина инцидентов в таких проектах - не модель, а дисциплина вокруг нее. Контур выглядит изолированным, но оговорки в сборке и обновлениях быстро превращаются в риск.
Первая ловушка - выпуск в прод без зафиксированных версий библиотек и без SBOM. Через месяц вы уже не можете повторить сборку один в один, а значит не можете доказать, что в проде стоит ровно то, что было протестировано.
Вторая - смешивание dev и prod в одном окружении. Сегодня разработчик поставил удобный пакет для отладки, завтра он тянет новые зависимости, и "чистый" контур начинает жить своей жизнью. Обычно это видно по разным хэшам артефактов и расхождениям в скорости и качестве ответов.
Третья - обновление модели без регрессионных тестов и без плана отката. Даже "минорная" версия может поменять стиль ответов, ухудшить работу на ваших документах или начать галлюцинировать в критичных темах. В закрытой сети это особенно болезненно: откат нужно продумать заранее, а не искать прошлую копию в последний момент.
Четвертая - доверие артефактам без подписи и проверки источника. Если вы принимаете контейнер, Python-пакет или саму модель "как есть", вы фактически переносите доверие наружу. Нужны проверка подписи, контроль хэшей и понятная цепочка поставки.
Пятая - неучтенная телеметрия и скрытые сетевые обращения. Многие библиотеки пытаются отправлять метрики, проверять лицензии или тянуть обновления. В изолированном сегменте это превращается в зависания, таймауты и "невидимые" попытки выхода наружу.
Шестая - нет владельца процесса обновлений. Когда непонятно, кто решает "можно обновлять или нет", обновления либо не происходят годами, либо происходят хаотично.
Полезная проверка перед продом:
- есть фиксированные версии, SBOM и повторяемая сборка
- dev и prod разделены, доступы минимальны
- на обновление есть тесты, окно внедрения и план отката
- артефакты подписаны и проверены, источники задокументированы
- все внешние вызовы запрещены и мониторятся
Быстрый чеклист и следующие шаги
Если архитектура уже набросана, проверьте ее по простому набору признаков. Такой контроль быстро показывает, где "закрытый контур" может начать жить своей жизнью.
Короткий чеклист готовности:
- есть единый офлайн-репозиторий моделей: версии, хэши (контроль целостности), понятные права доступа и аудит
- для кода и библиотек есть зеркало пакетов, lock-файлы и SBOM на каждый релиз (чтобы сборка повторялась один в один)
- все артефакты (модели, контейнеры, пакеты) проходят сканирование до публикации в продуктив и получают статус "разрешено"
- обновления идут по регламенту: тест на стенде, окно внедрения, понятный откат на прошлую версию
- нет неявных внешних вызовов ни при сборке, ни при запуске (телеметрия, автообновления, скачивание токенизаторов, шрифтов, моделей)
Дальше важны не технологии, а порядок действий. Начните с одного пилотного кейса (например, поиск по внутренней базе знаний) и зафиксируйте, что считаете "релизом": модель + конфиг + промпты/шаблоны + зависимости + данные для теста. После этого закрепите роли и журнал изменений: кто добавляет модели в репозиторий, кто утверждает результаты сканирования, кто дает добро на выкладку.
Следующие шаги на 2-4 недели:
- собрать минимальный контур поставки: репозитории, сканирование, подписи/хэши, регламент обновлений
- сделать эталонный релиз и один безопасный откат, чтобы проверить, что процесс работает
- провести "сухой прогон" инцидента: что делаем, если найдена уязвимость или модель ведет себя иначе
Если вы строите такой контур для госорганизаций или крупных предприятий, полезно заранее синхронизировать ИБ, инфраструктуру и владельца продукта по правилам поставки. В системной интеграции это часто решает половину проблем еще до продакшена. А если параллельно требуется надежная инфраструктура и поддержка под офлайн-сценарии (серверы, рабочие станции, интеграция в ЦОД), такие задачи обычно закрывают локальные производители и интеграторы уровня GSE.kz (gse.kz), которые берут на себя полный цикл поставки и сопровождения внутри страны.