Ingress и API-шлюзы в Kubernetes: тест-план для продакшена
Ingress и API-шлюзы в Kubernetes: практичный тест-план по производительности, TLS, маршрутизации и управлению сертификатами для продакшена.
Зачем нужен тест-план для Ingress и API-шлюза
Ingress и API-шлюзы в Kubernetes часто настраивают один раз и надолго. А проблемы всплывают уже после релиза, когда исправлять дороже: задержки на пике, всплески 502/504, странные редиректы, а иногда и истекшие TLS-сертификаты в самый неподходящий день.
Если сказать просто, Ingress решает задачу "как принять HTTP(S) трафик в кластер и разрулить его по сервисам". API-шлюз идет дальше и добавляет контроль на уровне API: аутентификацию, лимиты, преобразования, ключи, аналитику. На практике граница размыта, поэтому важнее не термин, а то, как компонент ведет себя под вашей нагрузкой и вашими правилами.
Сравнивать NGINX Ingress, Traefik и Kong по таблицам характеристик полезно, но этого мало. У каждого свои настройки по умолчанию, свои ограничения и свои "острые углы". То, что выглядит идеально в демо, может дать неожиданные таймауты в продакшене из-за размеров заголовков, поведения keep-alive, повторных попыток или нюансов TLS.
Хороший тест-план заранее проверяет то, что напрямую влияет на пользователей и безопасность: задержки и пропускную способность, корректность TLS (включая ротацию и сценарии ошибок), маршрутизацию (пути, хосты, заголовки, редиректы, WebSocket), а также устойчивость при рестартах, обновлениях и проблемах на бэкендах. Такой план превращает выбор контроллера или шлюза из "веры в документацию" в проверяемое решение, которое можно уверенно запускать.
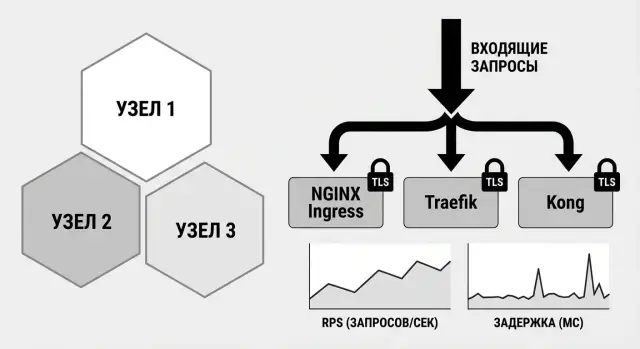
Что сравниваем: NGINX Ingress, Traefik и Kong
NGINX Ingress, Traefik и Kong решают похожую задачу: принять внешний трафик и довести его до сервисов внутри кластера. Но подходы разные.
NGINX Ingress обычно выбирают за предсказуемость и большое число примеров в продакшене. Traefik ценят за простую динамическую конфигурацию и удобное автообнаружение маршрутов. Kong ближе к миру API gateway: помимо маршрутизации он сильнее в политиках, плагинах и управлении API, но часто требует больше внимания к настройке и эксплуатации.
Чтобы сравнение было честным, фиксируйте одинаковые вводные: версии Kubernetes, тип балансировщика, одинаковые лимиты CPU и памяти, одно и то же тестовое приложение и одинаковый профиль нагрузки.
Базовый минимум для продакшена можно сформулировать так: корректная маршрутизация по host и path, стабильная работа TLS, понятное применение изменений без длинных пауз, и наблюдаемость (метрики и логи, по которым быстро ясно, откуда берутся 4xx/5xx).
На первом раунде лучше не усложнять: временно не включайте WAF, многоступенчатую аутентификацию, тяжелые наборы плагинов и кастомные скрипты. Иначе вы будете тестировать не контроллер, а конкретную комбинацию расширений.
Перед стартом зафиксируйте допущения и ограничения: какой трафик меряете (HTTP/1.1, HTTP/2, gRPC) и какие размеры запросов, что считается "успехом" по задержкам и ошибкам, как устроен TLS (свой CA или публичные сертификаты) и как часто планируется ротация, допустимы ли краткие разрывы при обновлении правил, и что важнее именно вам - простота эксплуатации или максимум функций.
Требования продакшена и критерии успеха
Тест-план работает только тогда, когда вы заранее договорились, что для вашей системы считается нормой. Для Ingress и API-шлюзов в Kubernetes это критично: один и тот же контроллер может показать красивые цифры в лаборатории, а затем "поплыть" на реальном трафике из-за мелочей в маршрутизации или TLS.
Опишите входной трафик так, чтобы это можно было проверить: средний RPS, ожидаемые пики (например, в 3-10 раз выше нормы), размер запросов и ответов, долю длинных ответов (файлы, отчеты), типы клиентов (браузер, мобильное приложение, сервис-сервис). Это задает профиль нагрузки и помогает не сравнивать несравнимое.
Дальше задайте измеримые цели по качеству. Обычно достаточно нескольких показателей: p95 и p99 задержки для ключевых ручек (отдельно для коротких и "тяжелых" запросов), верхняя граница для 5xx и осмысленная доля 4xx (с пониманием, какие 4xx нормальны), целевой RPS на один экземпляр контроллера и понятная модель масштабирования, а также ожидаемое поведение на пике (что ломается первым и как быстро).
Маршрутизацию лучше описывать как набор правил: домены, пути, версии API, приоритеты совпадений, обработка хвостовых слешей, редиректы, логика на заголовках (например, канареечный трафик по header). Отдельно решите, что считается корректным поведением при конфликтующих правилах.
По безопасности зафиксируйте минимальные версии TLS, наборы шифров, где нужен mTLS, и ограничения по частоте запросов. Для интеграционных сервисов в госсекторе или финтехе mTLS встречается часто, а для публичных методов обычно важны rate limit и защита от всплесков.
И наконец, критерии, которые важны бизнесу и эксплуатации: обновления без простоя, понятный откат за минуты, воспроизводимые конфигурации, наблюдаемость изменений в метриках и логах, и готовые сценарии для типовых инцидентов. В проектах системной интеграции это обычно отдельный приоритет: предсказуемая поставка, прозрачная поддержка и стандартные подходы к эксплуатации.
Подготовка тестового стенда в Kubernetes
Тесты Ingress и API-шлюза имеют смысл только тогда, когда стенд похож на продакшен по настройкам и ограничениям. Самая частая ошибка - сравнивать контроллеры на разных версиях Kubernetes или с разными лимитами ресурсов, а потом удивляться разнице в цифрах.
Сделайте отдельный namespace для экспериментов и заведите тестовый сервис, который похож на реальное приложение: отвечает быстро и медленно, возвращает разные коды, читает заголовки, принимает небольшие и крупные payload. Удобно держать два бэкенда: один "легкий" для проверки маршрутизации, второй "тяжелее" для проверки таймаутов и буферов.
Для честного сравнения NGINX Ingress, Traefik и Kong заранее зафиксируйте версию Kubernetes и CNI, параметры узлов (одинаковые типы нод и сеть), версии контроллеров и режим запуска (DaemonSet или Deployment) вместе с числом реплик, requests/limits CPU и RAM для контроллеров и тестовых сервисов, одинаковые правила HPA (или полное отключение автоскейла на время теста), а также единые настройки таймаутов на балансировщике/Service, если он участвует.
Нагрузку готовьте отдельным инструментом и набором сценариев. Минимум: несколько маршрутов (разные path/host), разные размеры ответа (например 1 KB, 50 KB, 1 MB) и разные методы (GET/POST). Генератор нагрузки лучше запускать вне кластера или на выделенной ноде, чтобы он не съедал ресурсы у контроллера.
Для TLS и SNI тестов домены должны нормально резолвиться. В тесте это можно решить через CoreDNS или через зону в корпоративном DNS, даже если домены не выходят в интернет.
С самого начала включите сбор метрик и логов. Иначе вы увидите только симптом (рост задержки), но не причину (перезапуски подов, ошибки TLS, переполнение очередей). Базового набора обычно достаточно: метрики контроллера, метрики HTTP (RPS, p95/p99), логи доступа и логи ошибок.
Тесты маршрутизации: правила, заголовки, редиректы
Маршрутизация ломается незаметно: сайт открывается, но часть путей уходит не туда, редиректы зацикливаются, а реальный IP клиента теряется. Поэтому важно проверять правила как "на бумаге", так и реальными запросами.
Сначала пройдитесь по базовым правилам host и path. Проверьте точные совпадения и префиксы: например, что /api не перехватывает /api-v2, а /app/ не "съедает" запросы к /apple. Если доменов несколько, убедитесь, что каждый host отдает свой бэкенд и не отвечает чужим контентом.
Дальше проверьте rewrite и редиректы. Ожидаемые коды 301/302 должны совпадать с задумкой, и не должно быть циклов. Типичная ошибка: / редиректит на /app, а /app обратно на / из-за разницы в слешах или правилах префикса.
Набор проверок, который обычно ловит большую часть проблем: приоритеты host/path и совпадений, корректность rewrite (нет неожиданных 404), редиректы без бесконечных переходов, нужные заголовки X-Forwarded-For, X-Forwarded-Proto, X-Request-ID, и корректная работа canary или blue-green (трафик реально делится, а не "прилипает" к одному поду из-за сессий или кеша).
Практичный пример: есть api.example.kz и app.example.kz. Для API нужен префикс /v1, а фронту нужен редирект с / на /login. Проверьте это простыми запросами (смотрите и заголовки, и финальный URL):
curl -si -H 'Host: api.example.kz' http://<lb-ip>/v1/health
curl -si -H 'Host: app.example.kz' http://<lb-ip>/
curl -si -H 'Host: app.example.kz' http://<lb-ip>/login
Если используются WebSocket или gRPC, сделайте хотя бы одну длинную проверку: соединение должно держаться стабильно, без обрывов через 30-60 секунд.
Производительность: пошаговая методика нагрузочных тестов
Цель нагрузочных тестов простая: понять, сколько трафика выдержит Ingress или API-шлюз, как растут задержки и как система ведет себя после перегрузки. Для сравнения NGINX Ingress, Traefik и Kong держите одинаковые условия: один и тот же кластер, одинаковые лимиты CPU и памяти, один и тот же сервис за Ingress.
Начните с базовой линии: один маршрут, короткий ответ (например, 200-500 байт), без TLS. Так вы увидите потолок контроллера без шифрования и сложной логики. Зафиксируйте среднюю задержку, p95/p99 и долю 4xx/5xx.
Дальше добавьте ramp-up: поднимайте RPS ступенями каждые 1-3 минуты, пока не появятся ошибки или p99 не станет неприемлемым. Важно не просто "уронить", а найти точку, где качество ответа начинает заметно ухудшаться.
После этого сделайте длительный прогон (soak) на уровне, близком к рабочему (например, 60-80% от найденного предела) на 30-120 минут. Здесь проявляются утечки памяти, рост очередей, деградация из-за логирования или метрик.
Затем проведите всплеск (spike): резко подайте нагрузку выше нормы и верните обратно. Проверьте восстановление: как быстро падает p99, исчезают ли ошибки, не "залипают" ли соединения.
Отдельно сравните режимы: 1 против 2-3 реплик контроллера, разные лимиты ресурсов, включенный и выключенный keep-alive. Это помогает понять, что дает масштабирование, а где упираетесь в сеть или приложение.
В отчет по тесту удобно включать условия (версии, конфигурация, лимиты, число реплик), профиль нагрузки (ramp-up, soak, spike, длительность и целевой RPS), метрики (p50/p95/p99, ошибки, CPU/память, перезапуски), наблюдения (где началась деградация и на что это похоже), и вывод (безопасный рабочий предел и запас под рост).
TLS и управление сертификатами: что тестировать
TLS ломается не в "криптографии", а в деталях: неверный домен, неполная цепочка, неожиданная версия протокола у клиента. Поэтому в тест-плане важно проверять не только "открывается ли сайт", но и как именно проходит рукопожатие.
Сначала убедитесь, что сертификат корректен для всех доменов. Проверьте цепочку до доверенного корневого центра и работу SNI, если на одном IP обслуживаются разные FQDN. Практичный сценарий: один кластер и два домена для разных систем - оба должны получать свой сертификат и правильный backend по имени хоста.
Дальше проверьте, какие версии TLS и шифры реально разрешены. Часто нужно запретить слабые наборы и старые версии, но при этом не отрезать легаси-клиентов, если они еще есть.
Набор проверок, который стоит автоматизировать в CI или хотя бы запускать перед релизом: сертификат подходит домену (CN/SAN) и SNI выбирает правильный сертификат, цепочка полная без пропущенных intermediate, разрешены только ожидаемые версии TLS (например, 1.2 и 1.3) и нужные шифры, автовыпуск и продление работают (cert-manager или другой процесс), секрет обновляется и конфигурация перечитывается, ротация проходит без простоя и не требует ночных ручных действий.
Обязательно тестируйте ошибки, потому что именно они всплывают при аудитах и инцидентах: просроченный сертификат, сертификат на другой домен (hostname mismatch), неполная цепочка (часть клиентов начнет падать, даже если браузер "терпит"), неверно настроенный редирект HTTP->HTTPS (петля редиректов или утечка на HTTP).
Если вы сравниваете Ingress и API-шлюзы в Kubernetes, фиксируйте результаты одинаковыми командами и одинаковыми клиентами. Иначе отличия будут не в контроллере, а в методике измерений.
Пример сценария: один сервис, разные маршруты и домены
Представьте один бэкенд-сервис, который обслуживает сразу три домена: api.example для внешнего API, admin.example для админки и public.example для публичной части. Сервис один и тот же, но требования разные: админке важны более длинные сессии и большие ответы, публичной части нужна простая отдача, а API должен быть предсказуемым по таймаутам и лимитам.
Для API добавьте два маршрута: /v1 и /v2. Например, /v1 оставьте мягче для старых клиентов (длиннее таймаут, меньше ограничений по частоте), а /v2 сделайте строже. Так вы проверите, как контроллер обрабатывает разные политики на уровне маршрута, а не только домена.
Выберите два эндпоинта с разным профилем нагрузки: один быстрый (например, /health) и один тяжелый (например, /reports/export или загрузка файла). На тяжелом эндпоинте обычно проявляются проблемы с буферами, ограничениями на размер тела запроса, таймаутами чтения и разрывами соединений.
Обязательное условие: включить TLS на всех трех доменах, настроить редирект HTTP->HTTPS и убедиться, что клиенты не ломаются. Проверьте, что редирект не превращает POST в GET, не добавляет неожиданные слеши и не меняет хост.
Чтобы сравнение NGINX Ingress, Traefik и Kong не превратилось в спор, заранее зафиксируйте правила: один и тот же кластер и лимиты ресурсов, один и тот же набор маршрутов, таймаутов, лимитов и заголовков (насколько это возможно в каждой реализации), один и тот же генератор нагрузки и длительность прогонов. Снимайте одни и те же метрики (p50/p95/p99, доля 4xx/5xx, количество редиректов, ошибки TLS), а итог фиксируйте таблицей: что получилось повторить 1:1, и где поведение отличается по дизайну.
Надежность и поведение при сбоях
Надежность Ingress или API-шлюза проверяют не на "идеальном стенде", а в момент, когда что-то ломается: поды перезапускаются, конфигурация обновляется, апстрим временно недоступен. В продакшене это происходит регулярно, поэтому такие тесты лучше сразу делать частью тест-плана.
Дайте стабильную нагрузку (постоянный поток запросов) и проверьте, что будет при сбоях контроллера и апстрима. Важно смотреть не только на долю ошибок, но и на время восстановления.
Что обязательно ломаем в тестах
Перезапуск pod контроллера под нагрузкой: обрываются ли активные соединения, растет ли доля 499/502/504, как быстро восстанавливается прием новых запросов.
Rolling update конфигурации: измените правила маршрутизации или TLS-настройки и посмотрите, появляются ли длинные серии 502/503 во время применения.
Граничные лимиты: отправьте большой запрос (body size), медленный запрос (timeouts), а также много коротких соединений (keep-alive) и оцените, не начинается ли "пилообразный" рост ошибок.
Недоступность апстрима: отключите сервис или сделайте так, чтобы он отвечал с задержкой. Сравните поведение retries, очередей и, если в решении есть, circuit breaking.
Откат: заранее подготовьте быстрый возврат предыдущей конфигурации и измерьте время до полного восстановления.
Критерий успеха: краткие всплески ошибок допустимы, но они должны быть предсказуемыми, короткими и воспроизводимыми. Если после обновления конфигурации "сыпется" несколько минут или откат занимает много шагов, это сигнал упрощать процесс изменений и усиливать проверки перед релизом.
Наблюдаемость: метрики, логи и простые алерты
Сравнение Ingress и API-шлюзов имеет смысл только тогда, когда вы одинаково хорошо видите поведение каждого варианта. Иначе тесты превращаются в набор цифр без причин.
Минимальный набор метрик: RPS и доля ошибок (4xx и 5xx) по хостам и маршрутам, p95 и p99 задержки (отдельно для upstream и на уровне контроллера), количество рестартов подов и статус readiness/liveness, CPU и RAM контроллера (включая пики во время нагрузки), активные соединения и очередь запросов (если метрика доступна).
Логи должны помогать быстро ответить на вопрос: это сеть, конфиг или бэкенд. Для 502 и 504 заранее проверьте, что в логах есть код ответа, upstream-адрес, время до ответа upstream, признак таймаута, SNI/host, путь и минимум один идентификатор запроса. Во время теста p99 вырос и пошли 504 - по логам вы должны за пару минут понять, где тратится время: в TLS, на прокси или на стороне сервиса.
Если используете трассировку, проверьте корреляцию по request-id: один и тот же request-id должен появляться в клиентском запросе, в логах ingress и в логах сервиса.
Простые алерты перед продакшеном: срок действия TLS-сертификатов (например, меньше 14 дней), рост 5xx выше порога и всплески 502/504, рост p95/p99 относительно базовой линии, частые рестарты или флаппинг readiness.
К тестовому отчету полезно прикладывать конфиг Ingress/API-шлюза и версии, графики RPS и p95/p99, распределение 4xx/5xx, выдержку логов по проблемным окнам и список сработавших алертов с временем.
Частые ошибки при выводе Ingress и шлюзов в продакшен
Частая причина проблем в продакшене - не баги в NGINX Ingress, Traefik или Kong, а тесты, которые не похожи на реальную жизнь. Когда проверяют на одном стенде, а запускают на другом, отличия в лимитах CPU, памяти и сети превращаются в "необъяснимые" 502, рост задержек и разрывы соединений.
Еще один перекос - нечестные условия сравнения: одному варианту дали больше ресурсов, у другого включены дополнительные плагины, а в третьем не настроены лимиты. В итоге выбирают не лучший вариант, а тот, которому просто повезло с окружением.
Отдельная ловушка - слишком оптимистичные таймауты. На тестах ответы маленькие и быстрые, а в продакшене появляются большие JSON, выгрузки, отчеты, медленные запросы в БД. Если не прогнать сценарии с крупными ответами и долгими соединениями, будут обрывы, повторные запросы клиентов и лавина нагрузки.
Ошибки, которые стоит поймать заранее: не проверили реальные клиентские протоколы (WebSocket, gRPC, большие заголовки, CORS), не протестировали большие тела запросов и ответов (лимиты, буферы, сжатие), не заложили сценарии обновления конфигурации и выкатывания новой версии без простоя, забыли про TLS целиком (легаси-клиенты, набор шифров, SNI, поведение при истечении сертификата), нет единого шаблона конфигурации и правила правят вручную в последний момент.
С сертификатами ошибка обычно звучит так: "сегодня работает". В тест-план добавьте проверку продления (автоматического или ручного) и имитацию истечения: что увидит клиент, какие алерты сработают и как быстро можно откатиться.
Быстрый чек-лист и следующие шаги
Перед релизом полезно прогнать короткий чек, прежде чем переключать трафик в продакшене. Он помогает поймать типичные вещи: случайные 404 из-за правил, проблемы с сертификатами и деградацию под нагрузкой.
Маршрутизация: все хосты и пути совпадают с ожиданиями, нет конфликтов, редиректы работают только там, где нужны.
TLS: корректная цепочка сертификатов, проверено автообновление, SNI и набор доменов соответствуют реальным запросам.
Лимиты и защита: таймауты, max body size, rate limit (если используете) и заголовки безопасности настроены и протестированы.
Отказоустойчивость: поведение при падении подов, при недоступности upstream, при перезапуске контроллера и при обновлении конфигурации проверено.
Наблюдаемость: метрики, логи и трассировка (если есть) дают ответ на вопрос "что сломалось и где", а алерты не шумят.
Выбор NGINX Ingress, Traefik или Kong лучше делать не по популярности, а по приоритетам. Если важны скорость и простота, чаще выигрывает более минималистичный вариант. Если нужен жесткий контроль политик, расширенные плагины и централизованное управление API, может подойти шлюзовый подход. Важно зафиксировать решение: конфиги, версии, параметры тестов и результаты. Это легко превращается во внутренний стандарт и экономит время при новых кластерах.
План на первые 2 недели после релиза: ежедневно смотрите одни и те же показатели, чтобы рано заметить тренд. Обычно достаточно доли 4xx/5xx и p95/p99 по ключевым маршрутам, ошибок TLS (handshake, просроченные или неверные сертификаты), рестартов и потребления CPU/RAM у контроллера или шлюза, времени применения новых правил и числа откатов, а также нагрузки на upstream (не добили ли сервис ретраями и таймаутами).
Если нужна помощь с подбором архитектуры, инфраструктуры под кластер и внедрением под требования госсектора, финансового сектора, медицины или образования, это часто упирается не только в Kubernetes, но и в стандартизацию поддержки и поставок. В таких задачах может быть полезен опыт системной интеграции GSE.kz, а также их инфраструктурные решения и поддержка 24/7 для организаций по Казахстану.
FAQ
Зачем вообще нужен тест-план для Ingress или API-шлюза?
Тест-план нужен, чтобы заранее поймать проблемы, которые в продакшене стоят дороже: всплески 502/504, неожиданные редиректы, деградацию p99 на пике и сбои с TLS. Он превращает выбор Ingress или шлюза из доверия к документации в проверяемое решение с измеримыми критериями успеха.
В чем практическая разница между Ingress и API-шлюзом?
Ingress в первую очередь занимается приемом HTTP(S) трафика и маршрутизацией по сервисам (host/path, TLS, базовые настройки прокси). API-шлюз обычно добавляет управление API: аутентификацию, rate limit, трансформации, ключи и аналитику. На практике функции часто пересекаются, поэтому важнее тестировать реальное поведение под вашей нагрузкой и правилами.
Как сделать сравнение NGINX Ingress, Traefik и Kong честным?
Фиксируйте одинаковые вводные: версию Kubernetes, сеть, тип балансировщика, лимиты CPU/RAM, число реплик, одно тестовое приложение и один профиль нагрузки. Иначе вы сравните не NGINX Ingress, Traefik и Kong, а разные условия стенда.
Какие критерии успеха стоит задать перед тестами?
Начните с описания трафика: средний RPS, пики, размеры запросов и ответов, долю длинных ответов и типы клиентов. Затем задайте измеримые цели: p95/p99 по ключевым ручкам, допустимую долю 5xx, и ожидаемое поведение на перегрузке. Без этих чисел тесты дадут графики, но не дадут решения.
Что обязательно проверять в маршрутизации и редиректах?
Проверьте приоритеты host/path, точные совпадения и префиксы, чтобы правила не перехватывали лишнее. Обязательно тестируйте rewrite и редиректы, а также сохранность нужных заголовков вроде `X-Forwarded-For` и `X-Forwarded-Proto`. Если есть WebSocket или gRPC, делайте длинную проверку соединения, чтобы не поймать обрывы через 30–60 секунд.
Как правильно проводить нагрузочные тесты Ingress или шлюза?
Двигайтесь шагами: сначала базовая линия без TLS на одном маршруте, затем ramp-up до точки деградации, потом длительный прогон на 60–80% от предела и отдельный spike-тест. В конце сравните 1 реплику и 2–3 реплики, чтобы понять, помогает ли масштабирование или упираетесь в сеть/бэкенд.
Что тестировать в TLS и сертификатах, кроме обычного HTTPS?
Проверяйте не только факт “открывается”, а детали: правильный сертификат на каждый домен, корректную цепочку, работу SNI и реальные версии TLS/шифры. Отдельно прогоняйте ротацию: секрет обновился, конфигурация перечиталась, и сервис не получил заметного простоя. В тестах ошибок тоже есть смысл: просрочка, mismatch домена, неполная цепочка часто всплывают у клиентов и на аудитах.
Какие сбойные сценарии важнее всего проверить перед продакшеном?
Дайте стабильную нагрузку и ломайте предсказуемо: перезапуск pod контроллера, rolling update правил, недоступность upstream и откат конфигурации. Смотрите не только на процент ошибок, но и на время восстановления и на то, появляются ли длинные серии 502/503/504 при применении изменений.
Какие метрики и логи собирать, чтобы тесты были полезными?
Минимум нужен такой, чтобы быстро отличить проблему сети/конфига от проблемы бэкенда: RPS, 4xx/5xx, p95/p99, CPU/RAM, рестарты и readiness, плюс логи доступа и ошибок с upstream-таймингами. Когда растет p99 и появляются 504, по логам должно быть видно, где ушло время: в прокси или на стороне сервиса.
Какие самые частые ошибки при выводе Ingress или API-шлюза в продакшен?
Чаще всего ошибаются в том, что стенд не похож на продакшен, условия сравнения разные, а таймауты и лимиты проверяют только на “быстрых” ответах. Еще забывают про реальные протоколы (WebSocket/gRPC), большие заголовки и тела запросов, а также про обновление правил без простоя. Самая неприятная категория — сертификаты: если не проверить продление и сценарии ошибки заранее, инцидент случается в самый неподходящий момент.