Хранилище для RAG: уровни хранения для датасетов и логов
Хранилище для RAG: как разнести индекс на NVMe, исходники в отдельный слой и настроить жизненный цикл логов без перерасхода.
Зачем разделять хранилище для RAG, датасетов и логов
RAG простыми словами - это когда система сначала находит подходящие фрагменты в базе знаний, а потом модель формулирует ответ на их основе. Чтобы ответы были быстрыми и предсказуемыми, данные для поиска, исходники и служебные записи лучше держать раздельно.
Если все складывать в один слой, хранилище быстро превращается в компромисс: одновременно хочется низкую задержку для поиска, дешевое место для больших файлов и удобные бэкапы. В итоге страдает и скорость, и стоимость, и восстановление.
В RAG обычно есть четыре класса данных:
- векторный индекс (то, по чему идет быстрый поиск)
- исходные документы и их версии (PDF, DOCX, письма, страницы)
- датасеты для обучения и оценки (вопрос-ответ, разметка, эталоны)
- логи и трассировки (запросы, ошибки, метрики, события)
Когда они живут в одном месте, проблемы появляются быстро. Поиск начинает тормозить, потому что быстрые диски заняты не тем. Дорогой слой хранения забивается логами, которым не нужен NVMe. А бэкапы становятся тяжелыми: вы копируете индекс, сырье и шум логов как единый монолит, и время восстановления растет.
Разделение по слоям решает это прямолинейно: индекс получает максимально быстрый доступ и стабильную задержку, исходники и датасеты хранятся надежно и недорого, а логи живут по понятной политике сроков и объемов. Это упрощает контроль стоимости, ускоряет поиск и делает восстановление после сбоев реальной процедурой.
Какие типы данных у вас есть и чем они отличаются
Правильная схема начинается не с выбора дисков, а с понимания требований разных данных. Если сложить все в одну папку и один пул, почти неизбежно получится либо медленный поиск, либо дорогой объем, либо хаос с доступами.
Векторный индекс обычно заметно меньше по объему, чем исходники, но он очень чувствителен к задержкам. Лишние миллисекунды на чтение легко превращаются в секунды на выдачу ответа, особенно под нагрузкой.
Исходники (PDF, DOCX, презентации, сканы, изображения) тяжелые по объему и редко читаются целиком. Зато они нужны для переиндексации, проверки цитат и юридической точности. Их нельзя терять, и ими нельзя управлять как временными файлами.
Датасеты для обучения и оценки - это версии, эксперименты и архивы, иногда с чувствительными данными. Здесь важны понятное версионирование, контроль доступа и возможность откатиться к прошлому набору.
Логи - много мелких записей, ежедневный рост, ценность падает со временем. Без правил ретеншна они быстро съедят место и усложнят расследования: важное будет тонуть в шуме.
Чтобы быстро развести классы данных, ответьте на пять вопросов:
- Что критичнее: задержка, пропускная способность или объем?
- Как часто данные читаются и перезаписываются?
- Можно ли восстановить данные из другого источника?
- Нужны ли строгие права доступа и аудит?
- Какой срок хранения реально полезен?
Отдельно держите в голове бэкапы и снапшоты. Это не "еще одна копия на всякий случай", а часть стратегии восстановления. Индекс часто можно пересобрать, а исходники и датасеты без бэкапа могут быть потеряны навсегда.
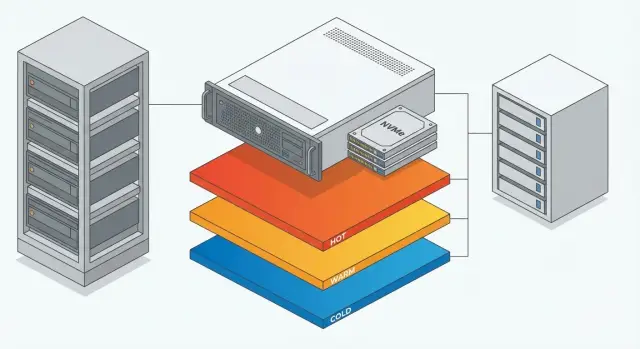
Практичная схема уровней хранения: 3 слоя
Идея простая: быстрое и дорогое хранение используйте только там, где оно напрямую влияет на скорость ответа RAG. Остальное переносите на более емкие и дешевые уровни.
Слой 1: быстрый (NVMe) - индекс и поиск
Сюда попадает то, что участвует почти в каждом запросе:
- векторный индекс (файлы/сегменты)
- небольшие таблицы соответствий (например, id документа и фрагмента)
- кеши горячих запросов и эмбеддингов, если они у вас есть
- служебные файлы поискового движка, которые часто читаются
Этот слой важно держать чистым. Не складывайте сюда архивы, сырые файлы, большие датасеты целиком и старые логи. Они почти не улучшают отклик, но быстро съедают место и усложняют обслуживание.
По объему ориентируйтесь на размер индекса, но планируйте запас под рост и пересборку. Практичное правило: держать место для текущего индекса, его прироста и временных файлов ребилда. Например, если индекс занимает 400 ГБ, план в районе 1-1.5 ТБ часто оказывается реалистичным: вы спокойно переживете обновления и не упретесь в диск в момент пересборки.
Надежность тоже важна, даже если индекс можно пересоздать. Потеря NVMe - это простои и часы на восстановление. Минимум, который обычно имеет смысл, - зеркало (RAID1) на двух NVMe.
Сразу определите правила обновлений: как часто пересобираете индекс (ежедневно, раз в неделю, по изменениям) и где живут временные файлы ребилда. Удобный подход - держать временную папку на том же NVMe, но с четко выделенным лимитом, а исходники для пересборки хранить во втором слое.
Слой 2: емкий - исходники и датасеты
Здесь живут исходные документы (PDF, DOCX, письма, сканы после OCR), распакованные тексты и изображения, а также датасеты для обучения и тестов. Доступ к ним нужен не на каждом запросе, а при переиндексации, проверках качества и разборе спорных случаев. Поэтому важнее надежность и структура, чем рекордная скорость.
Чтобы не путать "как получили" и "что пошло в прод", удобно завести три зоны:
- raw: как получили (оригиналы, без правок)
- processed: после извлечения текста, нормализации и разбиения
- published: то, что разрешено использовать в продакшене
Версионирование нужно даже в небольших проектах. Храните наборы как отдельные версии (v1, v2) и фиксируйте, что изменилось: источник, правила чистки, разметка. Тогда вы честно сравниваете качество и быстро откатываетесь, если новая версия дает хуже ответы.
Права доступа лучше задать заранее, иначе порядок ломается неизбежно. Частая схема: raw доступен только владельцам источников и службе безопасности, processed - команде данных, published - сервисам RAG и тем, кто готовит тесты.
Связь с индексом держите через стабильные идентификаторы. Каждый документ и фрагмент получают ID, а в индексе хранится ссылка на ID версии и контроль целостности (хэш). Если published-файл изменился, вы это увидите сразу и не будете искать ответы по индексу, который ссылается на другие данные.
Слой 3: логирование - жизненный цикл и ретеншн
Логи в RAG нужны для двух вещей: быстро найти причину сбоя и доказать, что система работала по правилам (аудит). Если хранить все подряд и бесконечно, стоимость растет, а польза падает.
Собирайте то, что помогает отвечать на вопросы "что произошло, когда, где и почему": запросы (без лишних персональных данных), статус ответа, версии промпта и модели, технические ошибки, задержки по этапам (поиск, ранжирование, генерация), а также аудиторские события (кто менял датасеты, кто пересобирал индекс, кто менял политики).
Дальше задайте жизненный цикл по ценности. Примерная схема:
- горячий слой 7-30 дней: события для быстрых разборов
- теплый слой 3-6 месяцев: только важные поля, сжатие, реже запросы
- архив 12-36 месяцев (если требует регулятор): аудит и минимальный набор техсобытий
Перед записью делайте маскирование. Не логируйте пароли, токены, ключи API, номера документов, ИИН и медицинские данные. Если нужно расследование, чаще достаточно хэшей, категорий и идентификаторов объектов.
Доступ к логам лучше выделять в отдельную роль с минимумом прав: чтение только нужных индексов, ограничение по проектам и обязательное журналирование доступа.
Как внедрить схему по шагам за 1-2 недели
Если относиться к этому как к небольшому проекту, уровни хранения можно внедрить за 1-2 недели без остановки разработки. Важно договориться, кто отвечает за каждый поток: поиск (индекс), владельцы контента (исходники), MLOps (датасеты и пайплайны), безопасность (логи и аудит).
Начните с карты данных: откуда они приходят, где лежат, кто владелец, какой рост по дням и какие сроки хранения действительно нужны.
Дальше соберите короткий план:
- зафиксировать потоки и владельцев
- оценить прирост и ретеншн для каждого типа данных
- развести уровни (NVMe для индекса, отдельная емкость для исходников и датасетов, отдельная политика для логов)
- настроить бэкап и один раз пройти тест восстановления в тестовой среде
- оформить правила в одном документе: что где лежит, кто имеет доступ, какие сроки и почему
Чтобы не утонуть в деталях, сделайте небольшой пилот: один тип документов, отдельный слой исходников, индекс на NVMe и миграция старых логов в холодный слой. Если поиск работает стабильно, а восстановление из бэкапа понятно по шагам, масштабирование пойдет быстрее.
Частые ошибки и ловушки
Чаще всего все складывают в один быстрый слой. NVMe кажется большим и быстрым, но он быстро забивается исходниками, логами и временными файлами. Итог предсказуемый: поиск замедляется, а при переполнении начинаются сбои.
Вторая типовая проблема - смешать тестовые данные и прод. Сегодня вы залили черновики и экспериментальные чанки, а через месяц уже непонятно, что можно удалить без риска. Это становится особенно болезненно, когда нужно доказать, откуда взялся ответ модели и какие документы участвовали.
Логи часто оставляют без лимитов. Пока система маленькая, все терпимо. Потом включили подробные трассировки, добавили интеграции, и через пару недель диск заполнен.
С бэкапами тоже ошибаются регулярно: копируют только индекс и забывают про исходники и метаданные, или наоборот. В первом случае индекс не получится восстановить корректно. Во втором восстановление занимает слишком долго, потому что индекс придется строить с нуля.
И еще одна вещь, о которую часто спотыкаются: не закладывают место на переиндексацию. При обновлении эмбеддингов или смене схемы чанкинга нужно хранить старый и новый индекс параллельно, плюс временные файлы.
Простой индикатор, что вы в зоне риска: место на NVMe прыгает непредсказуемо, а команда боится удалять данные, потому что непонятно, что реально участвует в ответах.
Короткий чеклист перед запуском
Перед включением RAG в прод пройдитесь по базовым пунктам:
- индекс и поисковые структуры живут на быстром хранилище, и там есть запас места минимум на одно полное пересоздание индекса
- исходники и датасеты отделены от индекса, и понятно, где raw, processed и published
- для логов задан ретеншн и правила перемещения между горячим, теплым и архивным слоями
- бэкап проверен восстановлением в тестовой среде, и вы знаете время восстановления
- назначен владелец политики хранения и расписание пересмотра правил (например, раз в квартал)
Маленький тест, который часто дает больше всего пользы: удалите тестовый индекс, восстановите его из исходников и проверьте, что ответы остаются ожидаемыми. Если это занимает часы вместо минут, обычно проблема в том, что данные смешаны или нет места под ребилд.
Пример: RAG для организации с требованиями к хранению
Банк или крупная больница запускает RAG-поиск по внутренним регламентам, договорам, инструкциям и базе знаний поддержки. Требования простые и жесткие: быстрые ответы для сотрудников, понятная история изменений и логи для расследований - без раздувания прод-хранилища.
Практичная схема выглядит так: векторный индекс и все, что нужно для поиска "здесь и сейчас", лежит на NVMe. Это дает стабильный отклик, когда одновременно ищут десятки пользователей. Исходники (версии документов, выгрузки из систем, сканы) лежат на отдельном емком слое, где важнее объем и надежность.
Логи живут по ретеншну: свежие 7-14 дней в горячем слое для быстрых разборов, дальше в более дешевом слое для аудита и расследований, затем в архив или удаление по требованиям. По мере роста объемов сценарий остается управляемым: добавили документы, пересобрали индекс, старые версии и логи уехали в свои уровни автоматически.
Если служба безопасности просит поднять цепочку запросов за последние 90 дней по конкретному подразделению, вы не трогаете прод-индекс и не копируете терабайты данных. Выбираете нужный период из слоя логов, делаете отчет, а поиск продолжает работать с тем же временем отклика.
Следующие шаги: закрепить политику и подобрать инфраструктуру
Если уже понятно, что индекс, исходники и логи живут по разным правилам, следующий шаг - превратить это в короткую проверяемую политику. Достаточно простой таблицы, где по каждому типу данных принято решение: объем и рост, SLA по отклику и восстановлению, срок хранения, уровень (NVMe, емкостный слой, архив) и доступы.
После пилота удобно планировать масштабирование как две разные задачи: производительность (узлы под NVMe и CPU/RAM для поиска) и емкость (узлы под исходники, датасеты и бэкапы). Так вы не покупаете дорогие NVMe там, где нужны просто терабайты.
Если вы строите такую схему на собственной инфраструктуре, полезно сразу проверить, что серверная платформа нормально поддерживает отдельный NVMe-пул под индекс и раздельные политики хранения. В подобных проектах иногда опираются на опыт GSE.kz (gse.kz) как производителя и системного интегратора, особенно когда нужны серверы под вычисления и дальнейшая эксплуатация с круглосуточной поддержкой.
FAQ
Почему нельзя хранить индекс, исходники, датасеты и логи в одном хранилище?
Обычно да: индекс для поиска, исходные документы, датасеты и логи лучше хранить раздельно, потому что у них разные требования к скорости, объему и срокам хранения. Так проще контролировать задержку в поиске, стоимость хранения и восстановление после сбоев.
Зачем класть векторный индекс на NVMe, если он не самый большой по объему?
Векторный индекс участвует почти в каждом запросе, поэтому лишние миллисекунды на диске быстро превращаются в заметную задержку ответа. NVMe помогает держать отклик стабильным под нагрузкой и уменьшает риск, что поиск начнет «плыть» из‑за фоновых операций.
Нужен ли RAID для NVMe со векторным индексом, если индекс можно пересоздать?
Индекс часто можно пересобрать, но это время простоя и дополнительная нагрузка на систему, особенно если индекс большой. Зеркало на двух NVMe обычно дает понятный минимум защиты от отказа диска и снижает вероятность аварийного восстановления в неудобный момент.
Почему важно отдельно хранить исходные документы, если в индексе уже есть фрагменты?
Исходники нужны для переиндексации, проверки цитат и юридической точности, а также чтобы объяснить, откуда взялся ответ. Если хранить только чанки или только индекс, вы рискуете потерять контекст, версию документа и возможность быстро восстановить систему после изменений.
Что дает разделение на raw/processed/published для документов?
Разделение на raw, processed и published помогает не смешивать «как получили» и «что разрешено использовать в продакшене». Это снижает риск, что черновики или непроверенные данные попадут в ответы, и упрощает откат, когда качество после обновления стало хуже.
Зачем версионировать датасеты для обучения и оценки в RAG-проекте?
Датасеты почти всегда живут версиями: меняются правила чистки, разметка, тестовые вопросы и эталоны. Если версии не фиксировать, вы не сможете честно сравнивать результаты экспериментов и быстро понять, из‑за чего качество улучшилось или ухудшилось.
Как понять, какой срок хранения логов выбрать?
Логи растут быстро и со временем теряют ценность, поэтому им нужен ретеншн и жизненный цикл, иначе они займут дорогой объем и усложнят расследования. Практичный подход — хранить подробности короткое время, а дальше оставлять только то, что реально нужно для аудита и поиска причин сбоев.
Что нельзя писать в логи RAG-системы и чем это заменить?
Не записывайте секреты и чувствительные данные: пароли, токены, ключи, лишние персональные идентификаторы и медицинские детали. Обычно достаточно хранить технические идентификаторы, хэши, статусы, версии модели и промпта, а также метрики задержек, чтобы разбирать инциденты без утечек.
Как связать индекс с документами так, чтобы потом можно было объяснить ответ модели?
Нужны стабильные идентификаторы документа и фрагмента, привязка к версии и контроль целостности, например хэш. Тогда вы можете доказуемо восстановить, какие данные участвовали в ответе, и быстро заметить, что опубликованный документ изменился, а индекс еще старый.
Как быстро проверить, что схема хранения реально готова к продакшену?
Проведите тест восстановления: удалите тестовый индекс, соберите его заново из исходников и сравните ответы с ожидаемыми. Если это занимает слишком много времени или требует ручных «танцев», значит данные смешаны, нет запаса места на ребилд или не оформлены правила, кто и где хранит версии.