Кэширование запросов к LLM: маршрутизация моделей и экономия GPU
Кэширование запросов к LLM и маршрутизация между моделями помогают снизить нагрузку на GPU, ускорить ответы и удержать расходы под контролем.
Откуда берется перегрузка GPU при работе с LLM
Перегрузка GPU часто появляется неожиданно: пользователей немного, а задержки уже растут. Причина в том, что LLM нагружает видеокарту не «на человека», а на каждый запрос. Один активный пользователь легко генерирует десятки обращений подряд (уточнения, правки, повторные формулировки), и нагрузка быстро складывается.
Больше всего времени обычно уходит не на «умность», а на механику вычислений. Самые дорогие факторы - генерация длинного ответа, большой входной контекст (история чата, документы, инструкции) и повторяющиеся вопросы, которые каждый раз считаются заново. Поэтому кэширование запросов к LLM дает эффект даже в небольших проектах, если люди часто спрашивают одно и то же.
Первые симптомы обычно одинаковые: появляется очередь запросов и «залипание» ответов в пиковые минуты, задержка скачет (то 2 секунды, то 20), пропускная способность падает на длинных промптах, а стоимость растет (больше GPU-часов на тот же объем полезных ответов).
Есть и менее очевидная причина: многие запросы простые (перефразировать, извлечь дату, коротко резюмировать), но их по привычке отправляют в самую большую модель. Это как ездить за хлебом на грузовике.
Оптимизация становится важнее покупки еще одного GPU, когда уже видны очереди и нестабильная задержка, а нагрузка повторяется изо дня в день. В таких случаях добавление железа часто лишь откладывает проблему. Без кэша, ограничений на контекст и правил маршрутизации между моделями рост запросов снова «съест» запас мощности.
Что именно кэшировать и где это дает максимум эффекта
Кэширование запросов к LLM дает лучший эффект там, где пользователи задают похожие вопросы и ждут одинаковый результат. Если часть ответов можно вернуть без повторного прогона модели, нагрузка на GPU падает сразу: меньше токенов, меньше очередей, быстрее отклик.
В первую очередь имеет смысл кэшировать готовые ответы на типовые запросы: FAQ (как оформить доступ, как восстановить пароль), шаблонные письма (подтверждение, отказ, запрос уточнений), справки и выдержки из регламентов. Такие формулировки часто повторяются почти дословно, а пользователю важнее скорость и стабильность.
Кроме финальных ответов, иногда выгоднее кэшировать промежуточные результаты. Если система сначала ищет подходящий документ, а уже потом просит модель оформить ответ, можно кэшировать найденный фрагмент и метаданные (какой раздел, какая версия). Отдельная зона экономии - шаблонные куски: приветствие, структура письма, стандартные дисклеймеры. Их проще собирать без вызова модели или хранить как заготовки.
Максимум эффекта обычно дают запросы с высокой повторяемостью: внутренние инструкции и регламенты, типовые обращения в поддержку, короткие справочные вопросы с одним правильным ответом, уведомления и письма с одинаковой структурой.
Есть и то, что кэшировать опасно. Не стоит хранить ответы с персональными данными, секретами, токенами, финансовыми деталями, а также одноразовые ответы, зависящие от текущего состояния (статус заявки, баланс, наличие на складе). Даже если это ускоряет работу, риск утечек и ошибок слишком велик.
По качеству кэш почти всегда выигрывает в скорости, но может проиграть в актуальности. Поэтому задавайте срок жизни и правила обновления: регламенты меняются, цены обновляются, формулировки политики уточняются. Хорошая практика - помечать ответы источником и версией документа, чтобы было понятно, когда их нужно сбросить и пересчитать.
Ключи, TTL и инвалидация: чтобы кэш не вредил
Кэш дает экономию только тогда, когда вы точно понимаете, что считается «тем же самым запросом», и когда старые ответы вовремя уходят. Для кэширования запросов к LLM это обычно важнее, чем выбор хранилища.
Ключ кэша собирайте не только из текста. Включайте параметры, которые меняют смысл ответа: системный промпт, выбранную модель, температуру, инструменты (например, вызов поиска), язык и формат (кратко или подробно). Практичный прием - хранить версию промпта (например, prompt_v3) и добавлять ее в ключ. Тогда при обновлении инструкций вы не будете случайно раздавать ответы «по старым правилам».
Нормализация повышает долю совпадений и снижает стоимость. Идея простая: одинаковые по смыслу запросы должны выглядеть одинаково технически. Уберите лишние пробелы, приведите регистр, унифицируйте кавычки. Для некоторых задач полезно стабилизировать даты и числа. Например, «отчет за 01.01.2026» и «отчёт за 1 января 2026» можно привести к одному виду, если в ответе важен сам период, а не точная форма записи.
TTL выбирайте по скорости устаревания:
- минуты или часы - для новостей, статусов, цен и остатков
- дни - для процедур и внутренних регламентов
- недели - для справочных ответов, которые меняются редко
Инвалидация нужна, когда меняется источник знаний или правила. Если обновили базу знаний, добавили документы или поменяли маршрутизацию, сбрасывайте кэш по тегам: «коллекция документов», «версия индекса», «версия политики». Это проще, чем пытаться угадать, какие ключи затронуты.
Без метрик кэш легко начинает вредить. Логируйте hit rate, среднюю задержку, долю повторов и количество «устаревших попаданий» (когда пользователи жалуются на неактуальность). Эти цифры быстро покажут, где TTL слишком длинный, а где ключ собран слишком узко или слишком широко.
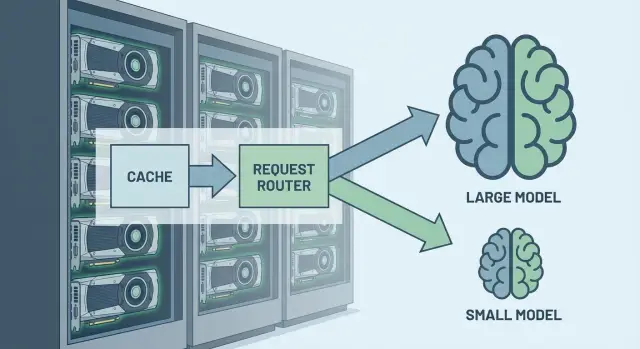
Почему маршрутизация между моделями снижает расход GPU
Не каждый запрос заслуживает самой большой и дорогой модели. Большая LLM обычно медленнее и потребляет больше GPU-памяти и времени на вычисления. Если гонять через нее все подряд, вы платите за «ум» там, где нужен обычный быстрый ответ.
Маршрутизация запросов между моделями работает как фильтр: простые задачи уходят в меньшую модель (или вообще в правила и классический код), а сложные получают «тяжелую артиллерию». В результате снижается средняя стоимость одного запроса и уменьшаются очереди на GPU.
На «легком маршруте» чаще всего оказываются классификация (тема письма, тональность, приоритет), извлечение полей (ИНН, номер договора, даты, суммы), короткие ответы по шаблону (режим работы, статус заявки, список документов), а также перефразирование и правка грамматики в 1-2 предложениях.
Большая модель нужна там, где высок риск ошибок и требуется «мышление в несколько шагов»: сложные инструкции, длинные документы, смешанные языки, неоднозначные вопросы, или когда ответ должен связать несколько фактов. Еще один сигнал - длинный контекст (например, переписка на 30 сообщений) или просьба составить план, сравнение, аргументацию.
Практичная схема - каскад. Сначала дешевая попытка, потом эскалация, если есть сомнение. Например: «Нужна справка для бухгалтерии, что принести?» - малая модель отвечает коротким списком. А запрос уровня «Сверь условия договора с приложением и объясни расхождения» лучше сразу отправлять в большую.
Чтобы каскад не ломал качество, добавьте простое правило эскалации: повышайте модель, если ответ слишком короткий для запроса, если модель сама отмечает низкую уверенность, или если в тексте есть слова вроде «договор», «приложение», «расчеты», «выписка». В связке с кэшированием запросов к LLM это обычно дает заметную экономию GPU без ощущения «хуже отвечаем».
Правила роутинга по типу и сложности запроса
Маршрутизация работает лучше всего, когда правила понятны и проверяемы. Не пытайтесь угадать «умность» запроса целиком. Разбейте его на признаки: что нужно сделать, насколько это сложно, и какой риск ошибки. Тогда экономия GPU и качество становятся управляемыми, а кэширование запросов к LLM дает предсказуемый эффект.
1) Роутинг по типу задачи
Сначала определите класс запроса. Один и тот же текст может быть и «вопросом», и «сделай письмо», и «сожми документ». Для каждого класса заранее выберите подходящую модель и настройки.
Примеры правил:
- Вопрос-ответ по фактам (короткие запросы) - меньшая модель, строгий формат ответа.
- Суммаризация длинного текста - модель среднего уровня, ограничение на длину вывода.
- Перевод - отдельная модель или режим с приоритетом точности терминов.
- Поиск по базе знаний (RAG) - сначала поиск, затем генерация на меньшей модели.
- Генерация письма или ответа клиенту - модель сильнее, потому что важен тон и структура.
2) Роутинг по сложности, языку и риску
Дальше добавьте триггеры, которые повышают класс модели.
Сложность: длинный ввод, таблицы, много требований (например, «сделай 3 версии, учти стиль, добавь цифры, не используй жаргон») - повод поднимать модель на уровень выше.
Язык: если есть отдельные настройки под русский и казахский, переключайте их явно. Простой вариант - определить язык по первому сообщению и зафиксировать его на всю сессию.
Риск: юридические, финансовые, медицинские темы и госуслуги лучше сразу отправлять в более сильную модель и включать более осторожные настройки (меньше «догадок», больше уточняющих вопросов).
Правило эскалации: если меньшая модель не справилась (попросила уточнение два раза подряд, дала противоречия, не соблюла формат), запрос автоматически уходит в более сильную модель с короткой «историей» того, что уже было сделано.
Как контролировать качество при кэше и роутинге
Кэш и маршрутизация экономят ресурсы, но могут незаметно «съесть» качество. Результат должен быть проверяемым: почему выбрана эта модель, был ли ответ из кэша, и насколько система уверена.
Полезно добавлять в метаданные ответа короткое объяснение и уровень уверенности. Это не обязательно показывать пользователю, но важно писать в логи. Например: «источник: кэш», «модель: малая, потому что запрос справочный», «уверенность: средняя, нужны уточнения».
Для быстрых проверок не нужны огромные бенчмарки. Достаточно короткого набора типовых запросов из реальных логов, который вы прогоняете регулярно, особенно после изменения правил и TTL. Удобный минимум:
- 20-30 частых запросов, где кэш должен срабатывать
- 10-15 «похожих, но разных» формулировок, чтобы поймать ложные попадания
- 10 запросов, где точно нужна большая модель
- 5-10 запросов с персональными данными (проверка маскирования и запрета кэша)
- 5 «провокаций» (двусмысленность, сложные инструкции)
Обратная связь от пользователя должна быть простой: «полезно / не полезно» и поле «что не так». По этому фидбеку удобно править правила роутинга и черные списки кэша. Если вы делаете кэширование запросов к LLM, отмечайте в отчете, сколько негативных оценок пришло именно на ответы из кэша.
Границы ответственности лучше задать заранее. Все, что связано с деньгами, юридическими формулировками, медданными или доступами, часто требует «человека в контуре»: модель готовит черновик, а финальное решение подтверждает сотрудник.
Чтобы избежать резких изменений, включайте роутинг постепенно: сначала логируйте решение без влияния на ответ, затем отдайте 5-10% трафика на новые правила, добавьте A/B там, где это возможно, держите стоп-кран по метрике ошибок и жалоб, и пересматривайте правила раз в 1-2 недели.
Пошаговый план внедрения: от логов до продакшена
Начните не с кода, а с данных. Снимите логи запросов за 1-2 недели: текст запроса, тип пользователя, время ответа, стоимость по токенам, модель, а также итог (успех, повтор, эскалация к оператору).
Дальше сгруппируйте запросы по смыслу и найдите повторяющиеся сценарии. Обычно быстро всплывают шаблоны: «объясни термин», «сделай краткое резюме», «найди ошибку в письме», «сформируй ответ клиенту», «сложный кейс с контекстом». Это база и для кэширования запросов к LLM, и для выбора моделей.
Опишите 3-6 типов запросов и закрепите за каждым набор моделей: маленькая для простых задач, средняя для «обычных», большая для редких сложных. На этом же шаге решите, что можно кэшировать безопасно: справочные ответы без персональных данных, шаблонные формулировки, результаты нормализации текста.
Когда категории готовы, внедрите кэш ответов только для тех, где цена ошибки низкая. Задайте TTL так, чтобы изменения знаний не портили ответ: для инструкций и справки часто хватает часов или дней, для динамики (цены, статусы) кэш лучше не включать.
Следом добавьте маршрутизатор с понятными правилами эскалации на большую модель. Например: если запрос длиннее N символов, содержит вложения, требует точного цитирования политики или уверенность классификатора ниже порога, отправляйте на более сильную модель.
Параллельно настройте мониторинг и пороги деградации:
- доля попаданий в кэш и экономия токенов
- средняя задержка и p95
- процент эскалаций на большую модель
- жалобы пользователей или ручные оценки качества
- доля отказов по таймаутам
Запускайте пилот на 5-10% трафика и расширяйте покрытие только когда метрики стабильны. Простой пример: для внутреннего помощника службы поддержки сначала кэшируйте ответы на частые «как оформить заявку», а сложные обращения с деталями договора сразу эскалируйте на большую модель и отключайте кэш.
Пример из практики: помощник службы поддержки с экономией GPU
Представьте внутреннего помощника для сотрудников банка или госоргана: он отвечает на вопросы по регламентам, подсказывает статусы заявок, выдает шаблоны писем и помогает быстро найти нужную справку. Нагрузка обычно растет резко: в часы пик десятки людей задают почти одинаковые вопросы, и GPU тратится на повтор.
Здесь хорошо работает кэширование запросов к LLM. Для «FAQ-подобных» тем (график работы, список документов, типовые формулировки) ответы сохраняются и переиспользуются. Важно кэшировать не все подряд, а только то, где ожидается повторяемость и нет персональных данных.
Дальше подключается маршрутизация. Сначала малая модель делает простую классификацию: вопрос про регламент, статус, шаблон или нестандартный кейс. Если запрос короткий и типовой, можно отвечать из кэша или генерировать на меньшей модели. Большая модель включается только когда нужно: много контекста, неоднозначность, несколько документов, требуется аккуратное объяснение.
Эффект удобно отслеживать по нескольким метрикам: доля ответов из кэша, среднее время ответа, доля эскалаций на «большую» модель, доля обращений, ушедших к человеку.
Обновление обычно тоже простое: при изменении регламентов сбрасывают связанные записи кэша, а при правках промпта меняют версию ключа, чтобы старые ответы не всплывали.
Частые ошибки, которые ломают качество и экономию
Оптимизация часто ломается не из-за сложной математики, а из-за пары «мелочей» в реализации. Эти ошибки обычно съедают и качество ответов, и экономию GPU.
Ошибки в кэше: экономия сегодня, проблемы завтра
Кэш бесполезен, если он «не понимает», какой именно запрос был обработан. Частая ситуация: ключ строят только по тексту вопроса, но забывают про версию промпта, системные инструкции, язык, параметры генерации и важный контекст. В результате возвращается старый ответ для уже другой логики, и пользователи видят уверенную, но неверную подсказку.
Вторая проблема - безопасность. Если кэшировать ответы вместе с персональными данными, токенами, внутренними номерами заявок или фрагментами конфиденциальных документов, это быстро превращается в риск утечки. Кэш должен либо исключать такие данные, либо хранить их отдельно и очень недолго.
Ошибки в роутинге: слишком смелая экономия
Маршрутизация запросов между моделями ломается, когда маленькую модель ставят «по умолчанию» и не дают пути эскалации. Тогда она начинает отвечать на сложные вопросы как на простые: кратко, но неправильно. Нужны явные правила, когда переключаться на более сильную модель (например, при низкой уверенности, при запросе расчета, при юридических формулировках, при длинном контексте).
Пять частых сигналов, что настройка сделана неправильно:
- ключ кэша не учитывает версию промпта и контекст, ответы устаревают
- в кэш попадают секреты или персональные данные
- малая модель используется без четких условий эскалации
- нет метрик (hit rate кэша, доля эскалаций, качество), поэтому эффект «на глаз»
- разные типы задач смешаны без правил и тестов, и поведение становится непредсказуемым
Практичный тест: возьмите 50-100 типовых запросов и прогоните их после изменений. Если экономия выросла, а доля исправлений оператором тоже выросла, значит вы оптимизировали стоимость, но проиграли в качестве.
Короткий чеклист перед запуском в работу
Перед тем как включать кэширование запросов к LLM и роутинг моделей в продакшене, полезно пройти короткую проверку.
Сначала решите, что вообще можно кэшировать. Простое правило: кэшируйте то, что одинаково для многих пользователей и не содержит персональных данных. Для чувствительных данных заранее зафиксируйте запрет (например, обращения с ФИО, номером договора, медицинскими деталями), даже если кажется, что ответ «безопасный».
Дальше проверьте правила маршрутизации: какие типы запросов идут в меньшую модель, а какие сразу в старшую. Важно, чтобы эти правила можно было объяснить одной фразой и быстро изменить без переписывания всего сервиса.
Финальная проверка:
- Категории кэша и запреты описаны: что кэшируем, что никогда не кэшируем, как маскируем данные в логах.
- Типы запросов размечены и есть правила выбора модели (по теме, длине, требуемой точности, наличию инструментов).
- Настроены TTL и инвалидация: что происходит при обновлении базы знаний, промпта, версии модели или политики безопасности.
- Метрики заведены и смотрятся вместе: hit rate, задержка, доля эскалаций на более сильную модель, ошибки качества по проверкам.
- Подготовлены тестовые наборы и план отката: типовые вопросы, «сложные» кейсы и четкий переключатель, который отключает кэш или роутинг.
Последний шаг - убедиться, что инфраструктура выдержит пики. Даже при хорошем кэше бывают всплески: массовые одинаковые запросы, ночные пакетные процессы, сезонные кампании. Заранее решите, что важнее в пике: скорость ответа или стоимость (например, временно чаще отправлять на меньшую модель и эскалировать только при низкой уверенности).
Следующие шаги: как спланировать внедрение и инфраструктуру
Начните с того, что можно сделать за 1-2 дня: соберите логи запросов и разложите их по типам (FAQ, поиск по базе, генерация текста, код, суммаризация). Обычно быстро окупается пилот кэша на частых вопросах: приветствия, статусы заказов, базовые инструкции, типовые ошибки. Это даст первые цифры экономии GPU без сложной маршрутизации.
Дальше планируйте пилот так, чтобы он измерял не только скорость, но и качество: долю попаданий в кэш, среднюю задержку, число эскалаций на «большую» модель и процент жалоб пользователей. Если метрики улучшаются, расширяйте правила роутинга и подключайте более тонкие проверки.
Об on-prem решении стоит думать, если есть жесткие требования по данным (персональные данные, коммерческая тайна), важна предсказуемая задержка, нужен полный контроль над версиями моделей и обновлениями, или бюджет удобнее планировать через закупки оборудования. В таких случаях заранее заложите время на безопасность, резервирование и эксплуатацию.
При подборе узлов под LLM смотрите на баланс, а не только на GPU. Часто упираются в память и сеть: большой контекст, кэш и векторное хранилище требуют RAM и быстрых дисков, а параллельные запросы нагружают сетевой интерфейс.
План работ по неделям:
- Неделя 1: аудит запросов, список «топ-50» FAQ, базовый кэш и метрики.
- Неделя 2: простые правила роутинга по типу задач и ограничение контекста.
- Неделя 3: тестирование качества, A/B, пороги эскалации на большую модель.
- Неделя 4: расчет мощности, отказоустойчивость, план эксплуатации 24/7.
Если нужна поддержка с инфраструктурой и внедрением, полезно привлекать системного интегратора, который закрывает и железо, и эксплуатацию. Например, GSE.kz работает как производитель серверов и интегратор с решениями для дата-центров и круглосуточной технической поддержкой, что бывает удобно для on-prem сценариев с ИИ-нагрузками.
FAQ
Почему GPU перегружается, даже если пользователей немного?
Перегрузка появляется не «на пользователя», а на каждый запрос: один человек может отправить десятки уточнений подряд, и все они считаются заново. Больше всего GPU тратит длинный контекст и длинная генерация, поэтому очередь и скачки задержки часто начинаются даже при небольшой аудитории.
Как понять, что пора оптимизировать, а не покупать еще один GPU?
Смотрите на очередь запросов, рост p95 задержки и резкие «провалы» скорости на длинных промптах. Если при тех же сценариях изо дня в день задержка становится нестабильной и стоимость растет, сначала оптимизируйте кэш, контекст и роутинг, а не добавляйте еще один GPU.
Что кэшировать в первую очередь, чтобы быстро разгрузить GPU?
В первую очередь кэшируйте типовые ответы, где ожидается одинаковый результат для многих людей: справочные вопросы, шаблонные письма, выдержки из регламентов. Максимальный эффект дают запросы с высокой повторяемостью и низкой ценой ошибки, потому что вы сразу снижаете число повторных прогонов модели.
Какие ответы лучше никогда не кэшировать?
Опасно кэшировать ответы с персональными данными, секретами, токенами, финансовыми деталями и всем, что зависит от текущего состояния системы (статус заявки, баланс, наличие). Если есть риск утечки или устаревания, лучше отключить кэш для этого класса запросов или кэшировать только обезличенную часть результата.
Как правильно собирать ключ кэша для запросов к LLM?
Ключ должен учитывать не только текст запроса, но и все, что меняет смысл результата: системный промпт и его версию, выбранную модель, параметры генерации, язык, формат ответа и подключенные инструменты. Это защищает от ситуации, когда вы обновили правила, а пользователи получают старый ответ «по другой логике».
Как выбрать TTL и не попасть на устаревшие ответы?
TTL выбирайте по скорости устаревания: для динамических данных он должен быть коротким или кэша не должно быть вообще, а для стабильной справки — дольше. Плюс нужен понятный способ сбрасывать кэш при изменении источников знаний или промптов, иначе вы неизбежно начнете раздавать неактуальные ответы.
Нужна ли нормализация текста перед кэшированием и что она дает?
Нормализация повышает шанс попадания в кэш: одинаковые по смыслу запросы должны выглядеть одинаково «технически». Обычно достаточно убрать лишние пробелы, привести регистр, унифицировать кавычки и стабилизировать даты или числа, если для ответа важен период или сущность, а не способ написания.
Как маршрутизация между моделями реально снижает расходы GPU?
Маршрутизация отправляет простые задачи в меньшую модель или в код, а сложные — в большую, поэтому средняя стоимость запроса падает и очередь на GPU становится короче. Практичный вариант — каскад: сначала дешевая попытка, затем эскалация, если модель не соблюдает формат, просит уточнение повторно или видна высокая рискованность темы.
Как контролировать качество, если часть ответов идет из кэша и часть — из разных моделей?
Проверяйте качество на небольшом, но регулярном наборе реальных запросов из логов и отдельно отслеживайте ответы из кэша. В логах фиксируйте, была ли выдача из кэша, какая модель выбрана и почему, а также жалобы пользователей — так вы быстро увидите, где ключ слишком широкий, TTL слишком длинный или правила роутинга слишком агрессивны.
С чего начать внедрение кэша и роутинга в продакшене?
Начните с выгрузки логов за 1–2 недели и выделите 3–6 типов запросов, затем включите кэш только для «безопасных» категорий и добавьте простые правила роутинга с эскалацией. На инфраструктурном уровне заранее планируйте не только GPU, но и RAM, диски и сеть: большой контекст, кэш и хранилища знаний часто упираются именно в них, особенно в on-prem сценариях.