Источники логов для SIEM: что подключать в первую очередь
Какие источники логов для SIEM подключать первыми: приоритизация по ценности для расследований, быстрые победы и базовая нормализация событий.
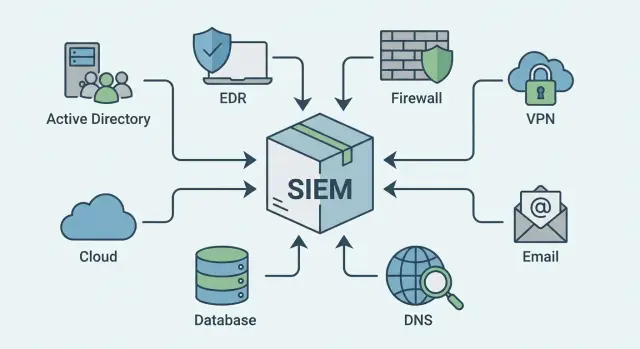
Задача SIEM: не собрать все логи, а дать пользу быстро
SIEM часто пытаются превратить в «пылесос»: собрать все логи, а потом разобраться. На практике это заканчивается шумом, ростом затрат и разочарованием. Рабочий подход другой: идти от ценности. Какие источники быстрее всего помогут заметить атаку и дадут ответы в расследовании, пока ситуация не переросла в инцидент.
Приоритизация нужна всегда, потому что ограничены время, люди и лицензии. Если начать с «удобных» логов (например, второстепенных приложений), SIEM быстро заполнится событиями, но не будет помогать в ключевых вопросах: кто вошел, откуда пришла атака, что изменили, что могли утащить.
Перед стартом стоит договориться о базовых вещах, чтобы подключение источников не превратилось в бесконечный проект:
- Какие 3-5 сценариев хотите ловить первыми: фишинг, перебор паролей, несанкционированные админ-действия.
- Какие системы критичнее всего: учетные записи, почта, периметр, серверы, рабочие места.
- Какие требования по регуляторике и срокам хранения.
- Кто разбирает алерты и по каким правилам идет эскалация.
- Какие ресурсы есть на нормализацию и поддержку источников.
Хороший результат через 2-4 недели выглядит не как «подключили 50 систем», а как работающие первые детекции и понятные отчеты: входы с подозрительных географий, серия неудачных логинов, запуск админ-инструментов, изменения групп и прав. Например, в организации с парком рабочих станций и серверов (в том числе на оборудовании уровня GSE) вы уже сможете связать цепочку «учетка - устройство - сервер - сетевое событие» и быстро ответить, что именно произошло и где искать следы дальше.
Как оценивать источники: простые критерии ценности
Выбирать источники логов для SIEM лучше не по принципу «что проще подключить», а по тому, какие события быстрее всего дадут ответы на два вопроса: «что происходит» и «что делать дальше». Иначе SIEM превращается в дорогой архив, а не в инструмент обнаружения и расследований.
Быстрая оценка за 10 минут
Пройдитесь по каждому кандидату и поставьте простые оценки (например, по шкале 1-5). Важно, чтобы это мог сделать не только инженер, но и человек, который потом будет разбирать инциденты.
Обычно достаточно пяти критериев:
- Связь с критичными активами и учетными записями: домен, почта, VPN, админ-доступы, ключевые серверы.
- Доверие к данным: нет ли пропусков, совпадают ли временные метки, не «падает» ли доставка.
- Польза для расследования: видно ли кто действовал, откуда пришел доступ, что сделал и чем закончилось (успех, отказ, ошибка).
- Стоимость владения: лицензии, хранение, нагрузка на SIEM, время на разбор полей и поддержку парсинга.
- Усилия на внедрение: доступы, агенты, согласования, изменения на проде.
Дальше помогает простая матрица «ценность vs сложность».
- Высокая ценность + низкая сложность: подключайте первыми. Это быстрые детекции и понятные расследования.
- Высокая ценность + высокая сложность: план на следующий шаг, но фиксируйте заранее.
- Низкая ценность + высокая сложность: чаще всего лучше отложить, чтобы не покупать шум.
Пример: выбор между логами с рабочих станций (сложно, много данных) и логами аутентификации из AD/VPN (обычно проще и сразу видно, кто и откуда входил). Для первых расследований чаще выигрывают аутентификации: они быстро показывают компрометацию учеток и движение злоумышленника по сети.
Первые источники, которые почти всегда дают максимум пользы
Если вы выбираете источники по принципу «что даст быстрые ответы», начните с систем, которые видят вход пользователя, запуск кода и сетевой выход. Это базовый треугольник для обнаружения атак и расследований.
В большинстве организаций максимум эффекта в первые недели дают:
- Каталог учетных записей (Active Directory или Entra ID): успешные и неуспешные входы, блокировки, сбросы паролей, изменения групп и прав.
- EDR или антивирус: срабатывания, процессы, командные строки, создание файлов, попытки отключения защиты.
- Пограничный firewall или UTM: разрешенные и заблокированные сессии, NAT, попадание в запрещенные категории, срабатывания сигнатур.
- VPN и другие средства удаленного доступа: кто подключился, откуда, насколько успешно, длительность сессии, смена устройства.
- Почта и защита почты: фишинговые письма, подозрительные вложения, переходы по ссылкам, блокировки на уровне шлюза.
Почему именно так: AD или Entra ID быстро отвечают на вопрос «кто это был» и показывают, как менялись права. EDR помогает понять «что запускалось на хосте» и отличить реальную активность от ложного входа. Firewall, VPN и почта дают контекст: откуда пришла атака, куда пользователь выходил, с какого канала все началось.
Простой пример: сотрудник ввел пароль на фишинговой странице. В логах почты видно письмо и ссылку, в VPN или Entra ID - вход с необычного региона, в AD - добавление учетной записи в привилегированную группу, а в EDR - запуск PowerShell и создание архивов. Даже без сложных правил это уже цепочка, по которой можно действовать быстро.
Второй эшелон: что добавлять после базового набора
Когда базовые источники уже дают первые детекции (учетные записи, конечные точки и периметр), пора расширять картину. Эти журналы часто не самые «шумные», но именно они помогают ответить «куда ходил пользователь или хост» и «что было дальше».
DNS: самый быстрый след по доменам
DNS часто становится короткой дорогой к признакам компрометации: связь с командными серверами (C2), странные домены, редкие TLD, попытки туннелирования через длинные запросы. Даже без анализа контента сам факт запроса и частота обращений сильно сужают поиск.
Proxy или Secure Web Gateway: контекст про веб
Если в компании есть прокси или шлюз веб-доступа, он добавляет детали: какие URL открывали, что скачивали, к какой категории относился сайт, были ли блокировки по политике. В расследовании это часто превращает «подозрительную активность» в понятную цепочку: фишинг -> переход -> загрузка файла.
После DNS и прокси обычно логично подключать то, что помогает связать адреса и действия:
- DHCP, чтобы сопоставлять IP с конкретным устройством во времени.
- Веб-серверы и серверы приложений, чтобы видеть ошибки, попытки входа и подозрительные запросы.
- Облачные журналы (например, Microsoft 365 и IaaS), чтобы отслеживать действия админов, доступ к данным и входы из необычных мест.
Короткий пример: SOC видит срабатывание на подозрительный процесс на ноутбуке. По DHCP находится, какой IP был у устройства утром и вечером. DNS показывает редкий домен, а прокси подтверждает загрузку архива за минуту до запуска процесса. Дальше в M365 видно, что сразу после этого был вход в почту с нового региона и правило пересылки. Такая связка часто экономит часы.
Источники под расследования: где чаще всего находятся ответы
Когда инцидент уже произошел, важнее всего быстро ответить на три вопроса: кто сделал, что именно сделал и какой был реальный ущерб. Поэтому в расследованиях ценятся не самые «громкие» источники, а те, где видно действия пользователей и администраторов в системах, где крутятся деньги, данные и права доступа.
Бизнес-системы и базы данных
В ERP/CRM обычно видно, что происходило с клиентами, договорами, счетами и выгрузками. Подозрительные признаки: массовые операции «одним пользователем», нетипичные возвраты, удаление карточек, крупные экспорты в нерабочее время.
Базы данных добавляют точность: успешные и неуспешные логины, выдача привилегий, выполнение тяжелых запросов, запуск команд экспорта. В расследовании утечки это часто ключ: кто получил доступ, к каким таблицам обращался и как данные уносили.
Минимальный набор событий, который стоит искать в первую очередь:
- вход/выход и причина отказа
- изменение ролей и прав
- операции экспорта/выгрузки
- массовые изменения или удаления
- административные действия (создание пользователей, смена настроек)
Инфраструктура, бэкапы и физический доступ
На сетевом оборудовании (коммутаторы, маршрутизаторы) важны изменения конфигурации и админ-доступ. Атака часто оставляет «следы ремонта»: новые правила, обходные маршруты, включенный удаленный доступ.
Системы резервного копирования помогают понять, пытались ли скрыть следы: удаления точек восстановления, сбои заданий, изменение политик хранения. События СКУД полезны для проверки гипотезы «человек был в здании» и для корреляции: например, вход в серверную ночью и почти одновременно - админские действия в критичной системе.
Минимальный набор нормализации событий, без которого SIEM слепнет
Даже лучшие источники быстро превращаются в шум, если события приходят в разных форматах и с разными именами одних и тех же сущностей. Нормализация - это не «красота данных», а способ сделать так, чтобы правила одинаково работали для Windows, VPN, почты и серверов, а расследование не упиралось в ручное сопоставление.
Минимум, который стоит привести к единому виду сразу (хотя бы для базовых источников):
- время события (в UTC или с явной таймзоной)
- хост или устройство, где произошло событие
- пользователь (кто действовал)
- действие и результат (успех/ошибка)
- объект доступа (файл, процесс, учетная запись, политика, правило)
Чаще всего «ломается» идентификация пользователя. В одном логе это UPN, в другом - sAMAccountName, в третьем - просто имя без домена. Заранее договоритесь, как хранить: отдельные поля для домена и логина плюс каноническое значение. Отдельно пометьте сервисные аккаунты и учетные записи приложений, чтобы не тратить время на ложные подозрения.
С хостами похожая история: FQDN, короткое имя, серийник, инвентарный asset ID. Полезно иметь одно основное поле (например, asset_id или fqdn) и атрибут критичности (сервер с персональными данными, рабочая станция бухгалтера и т.д.).
Еще один частый провал - «кто был за IP». Без связки IP-устройство-пользователь детекции по VPN, DHCP и NAT теряют смысл. Сохраняйте аренды DHCP, сессии VPN и данные NAT, чтобы по времени восстанавливать, кто именно использовал адрес.
И отдельная тема - время. Проверьте NTP на ключевых системах, учитывайте часовые пояса, фиксируйте задержки доставки логов. Иначе получится «атака, которая началась после того, как закончилась», и корреляции будут пропускать реальные инциденты.
Пошаговый план подключения логов: от инвентаря до первых правил
Быстрый старт с SIEM упирается не в «подключить все», а в дисциплину: выбрать первые источники, настроить доставку без потерь и договориться о ключевых полях. Тогда первые детекции появляются за недели, а не за кварталы.
План, который подходит большинству организаций:
-
Сделайте инвентарь и выберите приоритеты. Соберите список систем, где есть аутентификация, периметр, конечные точки и критичные приложения. Выберите 5-7 источников по критериям: влияют на риски, покрывают много пользователей/хостов, дают детали «кто, откуда, что сделал», доступны уже сейчас.
-
Определите способ доставки и владельца. Для каждого источника заранее решите, как он отправляет события (агент, syslog, API), какой будет буфер при обрывах, и кто отвечает за обновления и изменения. На этом шаге часто выясняется: логи есть, но сеть или права доступа не готовы.
-
Включите нужный аудит и проверьте полноту. Убедитесь, что собираете именно то, что нужно для расследований: входы и выходы, ошибки аутентификации, изменения прав, админские действия, блокировки на периметре. Сразу оцените ожидаемый поток событий, чтобы SIEM не «захлебнулся».
-
Настройте парсинг и минимальную нормализацию. Договоритесь о едином нейминге и заполнении полей: время (с часовым поясом), пользователь, хост, IP источника и назначения, действие (успех/отказ), объект (что меняли). Простая нормализация резко ускоряет поиск и корреляции.
-
Проведите валидацию и запустите первые правила. Проверьте качество до того, как писать десятки детекций:
- отправляются ли тестовые события и видны ли они в SIEM
- совпадает ли время с первоисточником
- нет ли потерь при пике нагрузки
- правильно ли распарсены ключевые поля
- можно ли по событию быстро найти первичный лог
Пример: вы подключили AD/LDAP, VPN, межсетевой экран и EDR. Первое правило делайте не «сложное», а полезное: много неудачных входов на VPN, затем успешный вход с нового IP, затем запуск PowerShell на рабочей станции. Дальше помогает простой ритм: раз в неделю добавлять 1-2 правила, чинить парсинг и уточнять исключения, чтобы оповещения были редкими, но точными.
Какие детекции и расследования реально заработают первыми
Первые рабочие детекции появляются там, где события складываются в цепочку: кто вошел, откуда, что запустил, куда пошел трафик. Ценность дают источники, которые легко связываются между собой и отвечают на базовые вопросы расследования за минуты.
Быстрые сценарии, которые начинают ловиться сразу
Когда в SIEM есть AD (аутентификация), VPN/шлюз удаленного доступа (точка входа) и EDR (действия на хосте), быстро начинают работать такие кейсы:
- Цепочки входов: успешный вход в AD после подключения по VPN, затем запуск PowerShell, cmd или неизвестного процесса.
- Подбор паролей: серия неуспешных входов в AD и/или VPN, подтвержденная событиями firewall (частые попытки с одного IP, необычная страна, резкий рост ошибок).
- Фишинг: письмо с вложением или ссылкой (почта), затем переход через proxy/web-шлюз, затем запуск файла и сетевые соединения по данным EDR.
- Подозрительные админ-изменения: добавление пользователя в привилегированную группу в AD, включение удаленного доступа на сервере, изменения конфигурации сетевого оборудования.
- Связка DNS + firewall: новый домен в DNS, после чего с хоста идет исходящее соединение на редкий адрес или нестандартный порт.
Что реально ускоряет расследование
Даже без «идеальных» правил вы сможете быстро отвечать на вопросы: это один инцидент или несколько, где точка входа, какие хосты затронуты. Например, сотрудник подключился по VPN ночью, через минуту вошел в AD, а затем EDR показал запуск архива из временной папки и исходящее соединение. Этого часто достаточно, чтобы изолировать хост и проверить учетную запись.
Чтобы эти кейсы работали, приведите к единому виду хотя бы: пользователя, хост, IP, результат события (успех/ошибка) и тип действия (вход, запуск процесса, сетевое соединение). Без этого корреляция «сыпется» на мелочах.
Частые ошибки при подключении источников в SIEM
Самая обидная ситуация: источники подключили, «лампочки горят», а пользы нет. Обычно проблема не в SIEM как таковой, а в качестве исходных данных и базовых настройках.
Ошибки, из-за которых события становятся бесполезными
Первая ошибка - включить сбор, но не включить нужные категории аудита на самом источнике. Например, с серверов приходят только «успешные входы», но нет неудачных попыток, повышений привилегий, запусков служб и задач. В итоге расследование упирается в пустоту: событие есть, деталей нет.
Вторая частая проблема - время. Если NTP не настроен, события «прыгают» на минуты и часы, корреляция разваливается. Вы видите цепочку атаки в неправильном порядке и тратите время на поиск несуществующих связей.
Третья ошибка - слишком рано строить сложные корреляции. Когда поля не нормализованы, названия пользователей записаны по-разному, а IP и хосты то есть, то нет, любая сложная логика превращается в генератор шума. Сначала добейтесь стабильных полей и минимальной полноты.
Еще несколько промахов, которые быстро бьют по качеству детекций:
- Не учли NAT и VPN: внешний IP виден, а кто именно был пользователем - непонятно.
- Не выделили сервисные аккаунты и «нормальную» активность админов: правила срабатывают постоянно.
- Не договорились о едином формате имен (user, host): одно и то же выглядит как разные сущности.
- Подключили источник без оценки объема: важные события тонут в «болтовне».
- Не настроили контроль доставки: пропуски замечают только во время инцидента.
Отдельно стоит тюнинг. Без регулярной настройки правила быстро превращаются в шум: аналитики начинают игнорировать алерты, и SIEM фактически слепнет.
Простой пример: вы видите подозрительный вход по VPN, затем запуск PowerShell на сервере и доступ к файловой шаре. Если время у VPN и сервера расходится, а NAT не позволяет связать IP с пользователем, цепочка не собирается и расследование останавливается на первом шаге.
Короткий чеклист: готовность к запуску и стабильной работе
Перед тем как подключать источники «пачками», проверьте базовые условия. Они скучные, но именно они чаще всего ломают детекции и расследования: время, ответственность, контроль потерь и единые справочники.
Организация и владение источниками
У каждого критичного сервиса должен быть понятный владелец и контакт на согласование. Иначе вы быстро упретесь в вопросы доступа, изменения формата и «это не наша система».
- Составлен список ключевых систем (AD, VPN, почта, EDR, межсетевые экраны, прокси) и назначены владельцы.
- По каждому источнику зафиксированы: способ доставки (агент/syslog/API), ожидаемый формат, кто отвечает за доступ и кто чинит при сбоях.
- Есть правило изменений: любые апдейты, которые могут поменять логирование, заранее согласуются с командой SIEM.
Техника, без которой SIEM ошибается
Ошибки времени и пропуски логов дают «дырки» в цепочке событий и ложные корреляции. Это особенно критично, когда вы ищете первые минуты атаки.
- На ключевых системах проверены NTP и часовой пояс, время совпадает с SIEM.
- Определен минимальный набор полей нормализации (кто, откуда, куда, что сделал, результат) и заведены справочники пользователей и хостов.
- Настроен контроль потерь: алерт на падение потока, резкие провалы/скачки объемов, очередь доставки.
- Согласован процесс работы с алертами: кто делает триаж, какие сроки реакции, как фиксируется обратная связь для тюнинга правил.
Если этот минимум закрыт, подключение новых источников будет предсказуемым, а первые расследования - воспроизводимыми.
Простой сценарий: как по логам собрать картину атаки
Подозрение простое: сотрудник говорит, что не подключался к VPN вечером, но коллеги видели странные действия в его почте. Такой кейс быстро показывает, какие источники реально помогают, а какие нужны уже позже.
Ситуация: возможная компрометация учетной записи
Сначала ищем точку входа. В логах VPN видим сессию на имя пользователя: время, внешний IP, результат аутентификации, выданный внутренний адрес и, если есть, ID устройства или сертификата.
Дальше собираем цепочку по времени, без попытки охватить все сразу:
- Подтверждаем факт и тип входа: VPN (успех/ошибка, MFA, страна/ASN при наличии).
- Проверяем события AD: интерактивный вход, Kerberos/NTLM, блокировки, смена пароля, добавление в группы.
- Смотрим почту: вход в почтовый ящик, правило пересылки, письмо с вложением или ссылкой, скачивание файла.
- Сопоставляем на устройстве: EDR показывает, был ли запуск процесса после открытия вложения (например, офисное приложение -> скрипт -> командная строка).
- Восстанавливаем маршрут IP -> пользователь -> устройство: VPN выдал внутренний адрес, DHCP привязал его к MAC и хосту, а NAT/прокси помог понять, какие внешние обращения делал этот хост.
Что нужно, чтобы подтвердить или опровергнуть
Сильные доказательства строятся из простых полей: результат входа (success/fail), способ (MFA/без MFA), привилегии пользователя и реальные действия. Если в AD есть событие добавления в привилегированную группу, а в EDR видно создание нового сервиса или запуск PowerShell, это уже не просто «странный вход».
Этот сценарий обычно учит двум вещам. Первое: критичны VPN, AD, почта и EDR, потому что дают вход, личность, действие и последствия. Второе: без DHCP/NAT быстро теряется связка «кто именно был за этим IP», и расследование превращается в догадки.
Следующие шаги: как закрепить результат и масштабировать SIEM
Когда базовые источники уже подключены и первые правила дают находки, важно закрепить процесс: что подключаем дальше, как храним данные, кто реагирует и как часто пересматриваем правила. Без этого SIEM быстро теряет ценность.
Хороший ориентир - дорожная карта на 90 дней. Она удерживает фокус на пользе для расследований, а не на бесконечном сборе «всех логов».
Дорожная карта на 90 дней
Зафиксируйте план простыми блоками:
- Источники и приоритеты: что добавляете следующим и какие вопросы расследований это закрывает.
- Нормализация: какие поля обязательны (кто, где, что сделал, результат), какие события приводите к единому виду, где остаются пробелы.
- Правила и отчеты: какие детекции включаете, какие отчеты нужны руководству и аудиторам, что проверяете раз в неделю.
- Эксплуатация: кто дежурит, как заводятся инциденты, какой SLA на разбор и эскалацию.
- Тюнинг: как снижаете шум (исключения, пороги, списки доверенных объектов) и как подтверждаете качество правил.
Хранение и масштабирование
Дальше обычно упираются в объем и скорость. Посчитайте текущий поток событий в сутки, пиковые нагрузки (например, массовые обновления, сканирования) и срок хранения: что нужно для оперативного поиска, а что - для расследований «задним числом». Отдельно решите, как будете расширяться: облачные сервисы, базы данных, резервное копирование, сетевые устройства после изменений в сети.
Наконец, закрепите эксплуатацию: пересмотр правил и источников раз в месяц, контроль качества нормализации, проверка, что критичные логи действительно приходят.
Если нужна инфраструктура и внедрение под ключ, GSE.kz может помочь как системный интегратор: подобрать платформу и серверы под нагрузку SIEM, развернуть решение и организовать сопровождение с 24/7 поддержкой.
FAQ
Какие логи подключать в SIEM в первую очередь, если времени мало?
Начните с источников, которые отвечают на «кто вошел», «что запустил» и «куда пошел трафик»: - **AD/Entra ID**: успешные/неуспешные входы, блокировки, смены паролей, изменения групп и прав. - **VPN/удаленный доступ**: кто подключился, откуда, результат, выданный внутренний IP, длительность. - **EDR/антивирус**: процессы, командные строки, создание файлов, попытки отключения защиты. - **Firewall/UTM**: разрешенные/заблокированные соединения, NAT, сигнатуры/категории. - **Почта и защита почты**: фишинг, вложения, переходы по ссылкам, блокировки. Этого набора обычно хватает, чтобы быстро собрать цепочку событий и начать реагировать.
Как быстро и понятно приоритизировать источники логов?
Сделайте короткую оценку каждого источника по 5 пунктам (например, 1–5): - связь с критичными активами и учетками - доверие к данным (нет пропусков, корректное время) - польза для расследования (видно «кто/откуда/что сделал/чем закончилось») - стоимость владения (лицензии, хранение, нагрузка) - усилия внедрения (доступы, агенты, согласования) Дальше используйте матрицу **«ценность vs сложность»**: сначала берите то, что дает высокий эффект при низких усилиях (обычно AD/VPN/firewall/почта).
Какие поля нужно нормализовать в первую очередь, чтобы SIEM не был «слепым»?
Базовый минимум полей, без которого правила и поиск часто «сыпятся»: - **время** (UTC или явная таймзона) - **хост/устройство** (понятный идентификатор) - **пользователь** (и отдельные поля для домена/логина) - **действие + результат** (success/fail/error) - **объект** (что меняли/к чему обращались) - **IP источника/назначения** (где уместно) Практичный подход: сначала нормализуйте эти поля для 3–5 ключевых источников, а уже потом наращивайте количество систем.
Что сделать перед подключением источников, чтобы не получить бесполезные события?
Сначала стабилизируйте базу, иначе вы купите «шум»: - включите корректный аудит на источнике (особенно **неудачные входы**, изменения прав, админ-действия) - проверьте **NTP** и таймзоны на ключевых системах - убедитесь, что парсинг достает пользователя/хост/IP/результат - настройте контроль потерь: алерт на падение потока, очередь/буфер при обрывах И только после этого добавляйте новые источники и усложняйте корреляции.
Что важнее для старта: логи рабочих станций или AD/VPN?
Для первых кейсов чаще выигрывают логи аутентификации (AD/VPN/Entra ID), потому что они сразу показывают компрометацию учеток и перемещения. Логи рабочих станций (через EDR или Windows audit) полезны, но обычно: - их больше по объему - сложнее тюнить шум - нужно больше времени на нормализацию Хороший компромисс: подключить **EDR** на критичных группах (админы, бухгалтерия, серверы), а полный охват рабочих мест делать поэтапно.
Зачем в SIEM нужны DHCP/NAT, если уже есть firewall и VPN?
Потому что без этого вы не сможете ответить «кто был за этим внешним/внутренним IP в конкретное время». Практический минимум: - **VPN-сессии** (кто, когда, какой внутренний IP выдан) - **DHCP-аренды** (какой хост/MAC держал IP в момент события) - **NAT на firewall/UTM** (как внутренние адреса выходили наружу) Если этого нет, детекции по периметру будут, а расследование будет упираться в догадки.
Через сколько времени реально получить пользу от SIEM после старта?
Ориентируйтесь не на количество подключенных систем, а на результат: - есть 3–5 работающих детекций (например, brute force, вход из необычного места, подозрительный PowerShell) - по алерту можно за минуты собрать цепочку «учетка → устройство → сервер/сеть» - отчеты понятны и повторяемы Часто это достижимо за **2–4 недели**, если ограничить список источников и привести к единому виду ключевые поля.
Какие детекции проще всего запустить первыми, чтобы было меньше ложных срабатываний?
Начните с быстрых «цепочек», где мало условий и много смысла: - много неудачных входов → затем успешный вход (AD/VPN) - успешный вход → запуск PowerShell/cmd/скрипта (AD/VPN + EDR) - письмо с ссылкой/вложением → переход/скачивание → запуск процесса (почта + proxy + EDR) - добавление в привилегированную группу (AD) + админ-действия на сервере (EDR/аудит) Важно сначала сделать правила редкими, но точными: пороги, исключения для сервисных аккаунтов, учет «нормальных» админ-работ.
Какие источники логов логично добавлять после базового набора?
Обычно следующий шаг — источники, которые добавляют контекст и связывают события: - **DNS**: редкие домены, возможные C2, аномальная частота - **Proxy/SWG**: какие URL открывали, что скачивали, что блокировалось - **облачные логи** (например, почта и админ-действия): входы, правила пересылки, изменения настроек - **веб-серверы/приложения**: попытки входа, ошибки, подозрительные запросы Подключайте их, когда базовые источники уже стабильны по времени, парсингу и полноте.
Как организовать работу с алертами, чтобы SIEM не превратился в шумный архив?
Нужны два простых элемента: **ответственность** и **правила работы**. - назначьте, кто делает триаж алертов и кто владеет каждым источником логов - определите уровни критичности и сроки реакции (хотя бы «сразу/в течение дня») - заведите цикл тюнинга: раз в неделю смотреть топ-алерты, добавлять исключения, чинить парсинг Если SIEM развернут на вашей инфраструктуре (в том числе на серверах и рабочих станциях корпоративного уровня), заранее заложите ресурсы под хранение и обработку, чтобы поток событий не «забивал» полезные сигналы.