F5 BIG-IP iSeries для балансировки и WAF: HA и сертификаты
Разбираем типовые HA-схемы, требования к TLS-сертификатам и журналированию, и тесты отказоустойчивости для F5 BIG-IP iSeries для балансировки и WAF.
Задача: доступность сервиса и контроль безопасности без сюрпризов
F5 BIG-IP iSeries обычно ставят в самое чувствительное место: на вход веб-сервисов, порталов и API. Поэтому цель тут не просто «раскидать трафик по серверам», а добиться предсказуемой доступности и понятной безопасности даже тогда, когда что-то ломается.
На практике систему чаще проверяют не нагрузочные тесты, а обычные отказы. Заранее решите, какие инциденты сервис обязан пережить без простоя или с минимальной паузой: отказ одного узла BIG-IP, потеря питания в стойке, падение интерфейса до коммутатора, обрыв канала до провайдера или пограничного маршрутизатора, недоступность части бэкендов (приложение, база, подсеть).
HA в этом контексте означает не «две коробки в стойке», а управляемое переключение ролей с понятными правилами: кто активен, как выбирается лидер, что происходит с сессиями и как быстро пользователи возвращаются к работе. Если переключение каждый раз проходит по-разному, это почти гарантированные ночные аварии.
Отдельная боль - сертификаты и журналы. Одна ошибка в TLS (не тот CN/SAN, забытая цепочка, истекший срок, неверный SNI, слабые наборы шифров) дает «частично работающий» сервис, где поломка выглядит как проблема приложения.
С логами похожая история. Если WAF блокирует запросы, но события не пишутся в нужном формате (время, IP, host, URI и причина срабатывания), расследование превращается в гадание. Типовой кейс: после обновления приложения пошли жалобы на вход в личный кабинет. Без корректного журналирования неясно, это новая уязвимость, ложные срабатывания WAF или сбой на бэкенде.
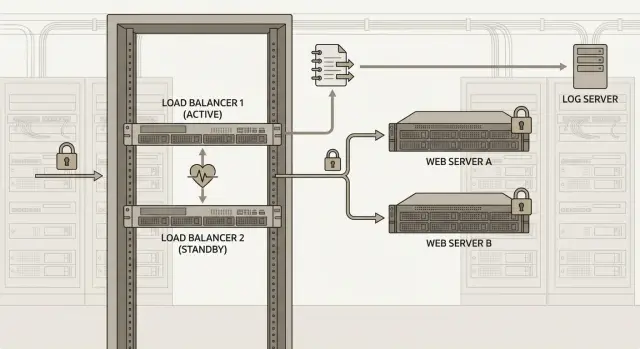
BIG-IP одновременно работает как L4/L7 балансировщик и точка применения политик WAF. Это напрямую влияет на дизайн: где завершается TLS, какие заголовки нужны приложению, какие события вы обязаны фиксировать и как HA должно вести себя при отказе узла, чтобы защита не «пропадала» вместе с ним.
Типовые схемы HA для iSeries: active-standby и active-active
Для F5 BIG-IP iSeries для балансировки и WAF чаще всего выбирают одну из двух схем высокой доступности: active-standby или active-active. Обе рабочие, но дают разный компромисс между простотой, использованием ресурсов и предсказуемостью отказа.
Active-standby обычно проще и надежнее в эксплуатации. Один узел обслуживает трафик, второй ждет и готов принять роль активного. Плюс в том, что поведение при аварии почти всегда одинаковое и легче проверяется. Минус тоже понятен: часть мощности простаивает.
Active-active уместен, когда нужно задействовать оба узла под нагрузкой или когда есть несколько независимых сервисов, которые можно аккуратно разнести по узлам. Чаще всего сложности возникают из-за состояния сессий, асимметрии маршрутизации и различий в модулях или политиках на устройствах. Любая мелкая разница в конфигурации быстро превращается в «плавающие» инциденты.
Floating IP и traffic group простыми словами
Клиенты подключаются не к физическому адресу устройства, а к виртуальному адресу сервиса (floating IP). Этот адрес принадлежит traffic group. При отказе активного узла traffic group переезжает на второй узел вместе с тем, что нужно для продолжения работы: виртуальные адреса, VIP и связанные self IP (а иногда и маршруты - в зависимости от дизайна).
Sync-failover: что должно совпадать на обоих узлах
Чтобы failover был предсказуемым, на обоих узлах должны совпадать ключевые объекты: виртуальные серверы, пулы и мониторы; WAF-политики и связанные профили; SSL-профили и цепочки сертификатов; iRules и data groups; а также SNAT/NAT и маршрутизация, если вы их используете.
Отдельно заранее решите вопрос с приватными ключами. В некоторых организациях их нельзя копировать между узлами. Тогда это не «мелкое ограничение», а часть архитектуры и процесса эксплуатации.
Иногда лучше не строить одну «сложную» пару на две площадки, а сделать две независимые пары по зонам/ЦОДам и переключать трафик внешним механизмом (DNS/GSLB/маршрутизация). Так меньше риск, что задержки между площадками или проблемы с межсайтовым L2/L3 превратят аварию в серию нестабильных переключений.
Сетевые требования и базовые настройки для стабильного failover
Чтобы переключение BIG-IP проходило без сюрпризов, сначала разложите сеть по ролям. Минимум нужны management (админка), external (клиенты) и internal (к бэкендам). Часто отдельно выделяют HA-сеть для обмена состоянием между узлами (heartbeat и синхронизация). Разделение снижает риск: проблема на клиентском сегменте не должна «убить» управление или связь пары.
Для портов и коммутаторов важно убрать единую точку отказа. Типовой вариант - по два физических интерфейса в каждый сегмент, подключенные к двум разным коммутаторам. На BIG-IP это часто делают через агрегацию (LACP), но только если коммутаторы поддерживают корректную схему (например, MLAG/vPC). Частая ошибка: LACP включили, а коммутаторы не согласованы. В итоге при аварии один линк «горит», но трафик не ходит.
Что стоит проверить по сети:
- Management отдельно и доступен даже при проблемах на external/internal.
- Для external/internal есть резервирование на уровне линков и коммутаторов.
- VLAN и теги одинаковы на обоих узлах и на обоих коммутаторах.
- HA-сеть не перегружена и не фильтруется ACL «по привычке».
Маршрутизация напрямую влияет на корректность failover. Default route обычно нужен на трафиковом контексте (ответы клиентам и исходящие проверки), а для management лучше держать отдельный маршрут к сети админов. Если к части бэкендов ходите через другой шлюз, добавьте статические маршруты одинаково на обоих узлах. Иначе после переключения часть пулов станет «невидимой».
Пользовательские сессии зависят от persistence. В active-standby без синхронизации состояния соединений часть активных TCP-сессий оборвется, а HTTP-сессии часто восстановятся при повторном запросе (если persistence на cookie или SSL session id настроен правильно). Если сервис «не терпит» разрывов, это нужно зафиксировать как требование, а не надеяться, что «само пройдет».
И последнее - здоровье пулов. Для базовой надежности используйте не только TCP, но и HTTP/HTTPS мониторы (например, запрос к /health с ожидаемым кодом 200). Рабочий сервис - это не «порт открыт», а приложение отвечает быстро и корректно.
TLS-сертификаты на BIG-IP: что предусмотреть заранее
Перед внедрением F5 BIG-IP iSeries для балансировки и WAF определите, где будет завершаться TLS: на BIG-IP или на бэкендах. Завершение на BIG-IP дает единое место для управления сертификатами, правилами шифрования и логами. Но тогда важно решить, нужно ли повторно шифровать трафик до приложений, чтобы не передавать его внутри сети в открытом виде.
Чтобы клиенты не ругались на «недоверенный сертификат», держите в порядке не только серверный сертификат, но и всю цепочку. Частая ошибка - установлен только leaf-сертификат, а промежуточные не добавлены. В результате часть браузеров и мобильных клиентов начинает падать, а диагностика занимает часы.
Если на одном VIP несколько доменов, почти всегда нужен SNI. Иначе один clientssl-профиль может случайно «перекрыть» другой сайт, и вы получите неверный сертификат на части запросов. Проверьте, что для каждого домена задан правильный набор сертификат + ключ, и что имя (CN/SAN) совпадает с тем, как к вам реально приходят пользователи.
Ротацию и доступ к ключам лучше описать заранее:
- кто отслеживает сроки и за сколько дней стартует замена;
- как делаете замену без простоя (загрузка нового сертификата, переключение профиля, быстрый откат);
- кто имеет доступ к приватным ключам и как это контролируется;
- как работает синхронизация в HA (сертификаты и ключи должны оказаться на обоих устройствах);
- какая политика TLS принята (минимальная версия, базовые шифры), чтобы не «отрубить» старых клиентов внезапно.
Простой пример: если у вас портал для госорганизации и отдельный домен для API, разделите профили по доменам и заранее прогоните тесты со старыми клиентами. Так вы поймаете несовместимость по TLS еще до ввода в эксплуатацию.
TLS к приложениям: шифрование до бэкенда и частые риски
Когда на F5 BIG-IP iSeries терминируют HTTPS на входе, дальше встает вопрос: шифровать ли трафик до приложений. Частый вариант: клиентский TLS заканчивается на BIG-IP, затем BIG-IP устанавливает отдельную TLS-сессию к каждому бэкенду. Политики и инспекция становятся управляемыми, но появляются новые точки, где легко ошибиться.
Сертификаты к бэкендам и mutual TLS
Если бэкенды в отдельном сегменте, есть требования комплаенса или нет доверия к внутренней сети, включайте TLS до бэкенда. Mutual TLS (mTLS) нужен, когда приложение должно проверять не только пользователя, но и сам прокси (BIG-IP) как клиента. Тогда на BIG-IP хранится клиентский сертификат и приватный ключ, а на бэкенде - доверенные CA/цепочки.
Чтобы mTLS не превратился в хаос, заранее договоритесь о правилах: какие CA используются для внутренних сервисов, где хранится доверенная цепочка для проверки бэкендов и как проходит ротация ключей.
Проверка подлинности бэкенда и частые сбои
Критично включать проверку сертификата сервера бэкенда (валидацию цепочки и имени). Без этого легко не заметить подмену или ошибочную конфигурацию. С включенной проверкой типовая проблема другая: BIG-IP начинает отклонять соединения при любой мелочи - неправильное имя в сертификате, отсутствует промежуточный сертификат, устаревший CA.
Отдельная ловушка - разные среды dev/test/prod. Часто случайно переиспользуют сертификат или доверенный CA из теста в проде. Снаружи все выглядит похоже, но при первой же ротации начинаются отказы.
Еще один сценарий, который бьет по доступности: у одного бэкенда истек сертификат. Если проверки включены, BIG-IP начнет считать узел недоступным. Если пул небольшой, пользователи увидят ошибки, хотя «в целом сервис жив». Срок действия внутренних сертификатов стоит мониторить так же строго, как и публичных.
Журналирование: что фиксировать для балансировки и WAF
Если F5 BIG-IP iSeries для балансировки и WAF стоит на границе, логи становятся главным источником правды: что было в запросе, почему он прошел или был заблокирован, и что случилось во время переключения HA.
Минимальный набор лучше определить заранее. Обычно нужны:
- L7 access-логи по виртуальным серверам (кто, куда, какой статус, сколько заняло);
- ошибки обработки (5xx, таймауты, resets);
- события WAF (правило/нарушение, уровень угрозы, действие block/alarm);
- аудит изменений конфигурации;
- события HA (failover, потеря heartbeat, смена роли устройства).
Чтобы логи реально помогали, договоритесь о едином наборе полей. Как правило, достаточно: точное время (с учетом часового пояса и синхронизации), VIP и порт, клиентский IP (с учетом X-Forwarded-For, если используете), backend pool member, HTTP метод и URI, код ответа, идентификатор события WAF (policy, rule/violation), действие (blocked/allowed) и request ID (корреляционный ID). Request ID полезно прокидывать дальше в приложение, чтобы связывать события BIG-IP и логи backend.
Хранение лучше делать в два слоя: небольшой локальный буфер для быстрой диагностики и отправка в централизованное хранилище (лог-сервер или SIEM) на длительный срок. Это важно и из-за рисков компрометации, и из-за банальной нехватки диска при всплеске событий.
Разделите роли: просмотр логов должен быть доступен ИБ и эксплуатации, а изменение политики WAF и объектов LTM - ограниченному кругу с фиксацией в audit trail.
Перед вводом в эксплуатацию проверьте непрерывность доставки:
- логи приходят с обоих узлов (active и standby), источник различим по hostname;
- при ручном failover события переключения пишутся и не ломают корреляцию;
- при недоступности лог-сервера есть буферизация и последующая догрузка;
- время на обоих узлах и на лог-сервере синхронизировано;
- права на просмотр и изменения соответствуют регламенту.
Как настроить схему HA шаг за шагом (без лишних деталей)
Чтобы HA работала предсказуемо, начните с согласования требований: какие VIP критичны, сколько минут простоя допустимо (RTO) и что считается потерей данных или сессии (RPO). Это влияет на persistence, требования к синхронизации и план тестов.
Дальше удобна короткая последовательность:
- Определите, какие адреса должны «переезжать» при аварии: VIP и, как правило, floating Self IP на клиентской и серверной VLAN. Отдельно проверьте default route, DNS и источник исходящих соединений к бэкендам.
- Подготовьте сети для failover и синхронизации: стабильные L2/L3 пути между узлами, корректный MTU и понятные роли интерфейсов (client, server, HA). Выделенная failover-сеть помогает избежать ложных переключений.
- Соберите пару устройств: device trust, config sync и Sync-Failover group. Сделайте initial sync и убедитесь, что синхронизируются нужные объекты (Virtual Server, Pool, Monitor, WAF policy, сертификаты), а статус везде «зеленый».
- Начните с тестового сервиса, затем переносите «боевые» VIP. Минимум: VIP, pool с реальными member, health monitor и при необходимости persistence (например, cookie для веб-кабинета). Монитор должен проверять реальную работоспособность (HTTP 200 и, при необходимости, проверка строки).
- Подключайте WAF поэтапно: сначала режим логирования на выбранных URL, затем блокировка. Сразу определите, где заканчивается TLS, потому что это влияет на видимость параметров запроса для WAF.
После настройки включите централизованную отправку логов (балансировка, WAF, системные события) и отдельно проверьте, что события failover фиксируются и на BIG-IP, и в системе сбора. Контрольный кейс простой: открыта сессия в веб-сервисе, запрос идет раз в 2-3 секунды, вы принудительно переводите активность на второй узел и смотрите, что VIP доступен, мониторинг не «краснеет», а в логах есть понятная цепочка (причина переключения, кто стал active, что произошло с сессией).
Проверка работоспособности при отказе одного узла: тест-план
Хороший HA проверяется не по схемам на бумаге, а по измеримым тестам. Для F5 BIG-IP iSeries для балансировки и WAF заранее договоритесь, что считается успехом: сервис доступен, активные сессии не обрываются (или обрываются в пределах нормы), события WAF и LTM попадают в централизованные журналы.
Перед началом зафиксируйте базовую линию: среднее время ответа, число активных соединений, состояние пулов, статус синхронизации и текущий активный узел. Выберите простой контрольный запрос (например, открытие страницы логина и отправка тестовой формы), который можно повторять каждые 2-5 секунд.
Набор практических тестов
Пять проверок обычно дают полную картину:
- Manual failover: принудительно переключите активный узел и измерьте фактическое время восстановления для пользователя.
- Отказ линка/порта: отключите внешний линк или один порт в агрегации на активном узле и проверьте, что VIP продолжает отвечать.
- Перезагрузка узла: следите за успехом контрольного запроса и всплеском 5xx/таймаутов, а не за пингами.
- Падение бэкенда: остановите сервис на одном сервере и убедитесь, что трафик уходит на здоровые узлы без «залипания».
- Поведение WAF при failover: вызовите тестовое запрещенное событие до и после переключения и проверьте блокировку и доставку логов.
Что фиксировать в протоколе
После каждого теста запишите время начала и окончания, какой узел был активным, симптомы со стороны пользователя, ключевые фрагменты логов LTM/ASM и системных сообщений, а также итог (прошло или нет) и что нужно поправить.
Простой и честный замер RTO: во время принудительного failover оператор обновляет страницу каждые 2 секунды и отмечает один «провал» или их серию.
Частые ошибки и ловушки в HA, сертификатах и логах
Даже когда роли active-standby видны в интерфейсе, отказоустойчивость часто ломается на «мелочах». Типичный случай: Virtual Server и политики одинаковые, а VLAN, self IP или маршруты отличаются. Переключение происходит, но трафик не идет, потому что новый active «не видит» нужную подсеть или отвечает не тем gateway.
Вторая частая проблема - persistence. Если не продумать закрепление сессии (cookie, source IP, token), пользователи разлогиниваются, а платежи и длинные операции «рвутся» при переключении или перераспределении по пулу. Это особенно заметно в личных кабинетах и B2B системах.
С сертификатами ошибка чаще не в том, что «забыли поставить», а в том, что обновили только на одном узле или не проверили цепочку. После failover клиент получает другой сертификат или неполный chain, и часть пользователей видит ошибки TLS. Всегда сверяйте срок, SAN, промежуточные сертификаты и то, что ключ и сертификат совпадают.
С WAF похожая история: включили блокировку без этапа наблюдения, и легитимные запросы начинают резаться. Например, поиск или загрузка документов ловит ложные срабатывания, а команда узнает об этом из жалоб.
С логами многие теряют картину: журналирование уходит только с active узла, а при аварии именно его логи недоступны. В итоге непонятно, это атака, ошибка приложения или сетевой сбой.
Практичный минимум проверок перед изменениями и после них:
- Сверить VLAN, self IP, маршруты и доступность next hop на обоих узлах.
- Проверить persistence на реальном пользовательском сценарии.
- Убедиться, что сертификаты и цепочки одинаковы и применены к нужным профилям.
- Прогнать WAF сначала в режиме наблюдения и собрать исключения под ваш трафик.
- Настроить централизованную отправку логов с обоих узлов, включая события failover.
Еще одна ловушка - отсутствие плана возврата (failback). Если не определены окно работ, кто принимает решение о возврате и как проверяется состояние после возврата, любое переключение превращается в ручной стресс и риск повторного простоя.
Быстрый чек-лист перед вводом в эксплуатацию и после изменений
Перед запуском F5 BIG-IP iSeries для балансировки и WAF полезно пройти короткую проверку.
Перед вводом в эксплуатацию
- HA: оба узла видят друг друга, синхронизация без ошибок, VIP действительно переезжает при смене роли.
- Сеть: есть резервирование линков/путей, маршруты и ARP ведут себя предсказуемо, health check проверяет то, что важно (HTTP-ответ приложения).
- TLS: сроки и алгоритмы актуальны, цепочка собирается полностью, SNI соответствует именам, слабые протоколы и шифры отключены.
- WAF: политика включена на нужных виртуальных серверах, режим выбран осознанно, исключения минимальные и документированы.
- Логи: события LTM/ASM и системные сообщения приходят в центральное хранилище с обоих узлов, время синхронизировано.
После изменений (сертификаты, правила, пулы)
- Прогоните короткий тест: открыть сайт, авторизация, ключевые формы, загрузки.
- Посмотрите логи WAF на ложные срабатывания и на блокировку тестовых атаковых шаблонов.
- Сымитируйте отказ одного узла и проверьте поведение VIP и сессий.
Назначьте владельца процесса: кто обновляет сертификаты, кто подтверждает изменения и кто хранит результаты проверок.
Пример схемы для типового веб-сервиса: что и как проверять
Представьте публичный портал с личным кабинетом: авторизация, платежи, загрузка документов. Есть две площадки (основная и резервная) и требования ИБ: аудит действий, хранение логов и отчет после испытаний.
Чаще всего для такого сервиса выбирают active-standby на F5 BIG-IP iSeries. Оба узла подключают к двум коммутаторам (разные стойки и питающие линии) и выводят наружу через двух провайдеров. Снаружи пользователи видят один VIP, внутри трафик идет на пул приложений. Логи балансировки и WAF отправляются на централизованный лог-сервер, чтобы при аварии одного узла записи не пропали.
По TLS часто делают так: один набор сертификатов и цепочек на VIP (который видит клиент), а для внутренних сервисов - отдельные сертификаты, нередко от внутреннего УЦ. Заранее согласуйте план ротации: кто обновляет, как проверяется цепочка, где лежат ключи и как фиксируется смена.
WAF лучше включать поэтапно: сначала логирование и обучение, затем точечные блокировки для явно вредоносных запросов. После каждого изменения правил смотрите на ложные срабатывания именно по критичным URL личного кабинета.
Что проверить, чтобы схему приняли ИБ и эксплуатация:
- Плановый failover узла: VIP доступен, новые сессии создаются, старые не обрываются дольше допустимого.
- Отказ линка или коммутатора: трафик уходит на резервный путь, нет петли и не растет задержка до бэкендов.
- Отказ провайдера: маршрутизация и доступность VIP сохраняются, сертификат на VIP не меняется.
- Логи: события WAF, доступ к VIP, изменения конфигурации и причины блокировок попадают в хранилище с правильным временем.
- Отчет: список тестов, фактическое время переключения, подтверждение, что политика WAF и TLS не ослабла после аварии.
Следующие шаги: пилот, регламенты и поддержка эксплуатации
Чтобы HA, TLS и WAF не стали сюрпризом в продакшене, начните со сбора требований: какие сервисы критичны, сколько минут простоя допустимо, кто владеет сертификатами и как служба ИБ хочет хранить и выдавать логи.
Хорошая практика - короткий пилот на одном VIP, где вы проверяете весь цикл: failover, TLS (клиентский и до бэкенда), базовые политики WAF и журналирование. Пилот быстро показывает реальные ограничения: например, что не хватает прав на выгрузку логов в SIEM или что процесс обновления сертификатов завязан на одного человека.
Критерии готовности пилота лучше зафиксировать заранее: целевой RTO/RPO, требования к TLS (сроки, алгоритмы, хранение ключей), требования к логам (поля, сроки хранения, доступы), правила изменений (кто утверждает WAF-политики и исключения) и способ подтверждения успешного failover (глазами пользователя и по мониторингу).
Дальше важнее всего регламенты. Обновление сертификатов должно быть процедурой, а не разовой операцией. Для WAF полезен простой цикл: внесли изменение, проверили на тестовом трафике, включили, затем несколько дней отслеживают ложные срабатывания и корректируют. И отдельно - плановые тесты failover (например, раз в квартал) с фиксацией результатов.
Если не хватает времени или опыта на проектирование, внедрение и поддержку, логично подключать системного интегратора. GSE.kz (gse.kz) как производитель и системный интегратор может взять на себя интеграцию ИТ-инфраструктуры и эксплуатационную поддержку 24/7, чтобы переключения, обновления и разбор инцидентов не зависели от одного специалиста.