ESB и iPaaS on-prem: как выбрать WSO2, MuleSoft, Camel
ESB и iPaaS on-prem: как сравнить WSO2, MuleSoft, Camel и Kafka Connect, выбрать архитектуру и избежать неподдерживаемого комбайна.
Какая проблема на самом деле у интеграций
Интеграции редко ломаются из-за выбора «не того» продукта. Чаще ломается процесс: систем становится больше, требования меняются быстрее, а ответственность размазана между командами.
Обычно болит одно и то же: у каждой системы свои протоколы и привычки, данные называются по-разному, а изменения согласуют «по договоренности» в чатах. В итоге интеграция превращается в набор исключений, который понимают только авторы.
Классический сценарий: сначала нужно быстро связать ERP с CRM и парой внутренних сервисов. Потом появляется шина событий, витрина данных, интеграция с госпорталом, новые филиалы, новые подрядчики. Каждый раз «чуть-чуть допиливают», и через год вы получаете неподдерживаемый комбайн: правила спрятаны в десятках маршрутов и скриптов, тестов нет, а обновление любой системы запускает цепочку непредсказуемых правок.
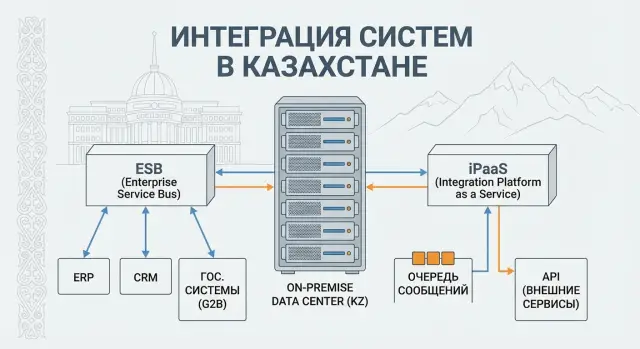
Платформы класса ESB и iPaaS в on-prem установке обычно закрывают четыре вещи: подключение разных протоколов (HTTP, SOAP, MQ, файлы, JDBC и т.д.), преобразование данных и маршрутизацию, управление надежностью (повторы, очереди, дедупликация), а также наблюдаемость (логи, метрики, трассировка, алерты).
Но инструмент не спасет, если нет понятных границ и правил эксплуатации. Успех интеграций выглядит не как «все связано», а как «изменения проходят предсказуемо». Например, когда банк меняет формат заявки в CRM, команда точно знает: какие потоки затронуты, где обновить контракт, как прогнать тесты, кто дежурит и как откатиться.
Если оставить один критерий выбора, пусть он будет таким: через год новая команда должна уметь безопасно вносить изменения и поддерживать интеграции без героизма и ночных правок.
ESB, iPaaS и on-prem: простыми словами про отличия
В разговорах об интеграциях часто путают три вещи: подход (как строим), размещение (где работает) и уровень ответственности (инструмент или платформа). Из-за этого легко купить «не то»: взять мощный компонент и превратить его в самодельную платформу без поддержки и правил.
ESB (Enterprise Service Bus) обычно понимают как «центральный узел», через который проходят интеграции. Он принимает запросы, направляет их дальше, меняет формат данных, добавляет проверки, а иногда управляет цепочкой шагов (например, сначала создать клиента, потом договор, потом отправить уведомление). Это удобно, когда интеграций много, форматы разные, а порядок действий важен.
iPaaS (Integration Platform as a Service) ближе к управляемой платформе внутри организации: важна не только сборка потоков, но и контроль жизненного цикла. Обычно это означает каталог интеграций, шаблоны, роли и доступы, централизованный мониторинг, единые правила версионирования и выпусков. Акцент смещается с «сделали интеграцию» на «управляем интеграциями как сервисом для команд».
On-prem означает, что все это работает внутри вашей инфраструктуры. Причины обычно прагматичные: требования по данным и регуляторике, изоляция от внешнего интернета, доступ к внутренним системам, которые физически не открывают наружу. В банке или госорганизации часто нельзя, чтобы данные уходили в облако, а интеграции должны жить рядом с внутренними контурами.
Граница между «инструментом» и «платформой» появляется, когда кроме разработки потоков вам нужны единые стандарты и шаблоны, мониторинг и алерты с понятными ожиданиями для бизнеса, управление доступами и аудит действий, процесс выпусков и откатов как у обычного ПО, а также команда эксплуатации с закрепленной ответственностью.
Если это звучит как обязательный минимум, выбирайте именно платформенный подход, а не набор разрозненных скриптов. И смотрите не только на «как подключиться», но и на «как жить с этим через год».
Типовые архитектуры: от точек к потокам событий
Главный спор в интеграциях обычно не про бренды, а про режим работы.
Синхронные вызовы (API) удобны, когда пользователю нужен ответ прямо сейчас: проверить статус заявки, создать запись, показать остаток. Асинхронные очереди и события лучше, когда важнее надежно доставить факт, чем мгновенно ответить: «счет оплачен», «партия отгружена», «пациент зарегистрирован». Если перепутать, вы получите либо медленные цепочки API, либо задержки там, где люди ждут ответ на экране.
Есть несколько типовых схем, и у каждой свой потолок. Точечные интеграции (point-to-point) позволяют быстро стартовать, но при росте числа систем превращаются в клубок зависимостей. Hub-and-spoke (хаб и спицы) проще держать в голове, но центральный узел легко становится бутылочным горлышком. ESB как шина переносит маршрутизацию, трансформации и контроль в единое место, что помогает управлять, но есть риск снова собрать «комбайн». Событийная модель (event-driven) уменьшает связность и проще масштабируется, но требует дисциплины в качестве событий и в наблюдаемости цепочек.
Вопрос «где нужен единый мозг» решается просто. Если у вас много правил (валидация, оркестрация, маршрутизация, ретраи, дедупликация, аудит), нужна платформа, где это прозрачно и поддерживаемо. Если задача - забрать данные из системы A и положить в систему B по расписанию или триггеру, часто достаточно коннектора и минимальной логики.
Чтобы не получить единую точку отказа, избегайте длинных синхронных цепочек через центральный узел. Делите поток на шаги, ставьте очереди между критичными участками и заранее продумывайте отказоустойчивость: несколько инстансов интеграционного компонента, независимое хранение очередей или журналов и понятный план действий при деградации (например, временный переход на асинхронную обработку).
Кратко про WSO2, MuleSoft, Apache Camel и Kafka Connect
При выборе ESB или iPaaS в on-prem формате полезнее понять не «кто популярнее», а какой тип работы вам нужен: управление API, оркестрация процессов, перенос данных или событийные потоки.
WSO2 чаще используют как набор продуктов, а не один компонент. Типичный сценарий: API Management для публикации и контроля API, интеграционный слой (ESB или Micro Integrator) для маршрутизации и преобразований, плюс IAM для SSO и ролей. Сильная сторона WSO2 - единая экосистема, но она требует аккуратной эксплуатации: версии, безопасность и наблюдаемость должны быть настроены «по-взрослому», иначе начинают копиться исключения и ручные обходы.
MuleSoft хорошо проявляет себя как iPaaS: много коннекторов, шаблонов и удобных практик для команд, которым важно быстро собирать интеграции. Обратная сторона удобства часто в лицензировании и в необходимости заранее договориться о правилах: как разворачиваются среды, как выдаются доступы, как ведется каталог API и кто отвечает за жизненный цикл потоков. Без governance платформа превращается в дорогой набор разрозненных «флоу».
Apache Camel - библиотечный подход. Он подходит, когда у вас сильная инженерная культура и вы готовы жить в коде: тесты, CI/CD, ревью, стандарты логирования. Camel дает свободу, но почти не дает «ограждений», поэтому без дисциплины команды легко расползается в набор уникальных интеграций, которые понимает только автор.
Kafka Connect уместен, когда фокус на данных и потоках событий: забирать изменения из систем, публиковать их в топики и доставлять дальше. Это не замена оркестрации бизнес-процессов: Connect решает транспорт и коннекторы, а сложную логику обычно выносят в отдельные сервисы.
Удобная рамка выбора:
- Управляемые API, политики, лимиты и портал разработчиков - чаще WSO2 или MuleSoft.
- Сложная оркестрация и много готовых коннекторов - чаще MuleSoft.
- Максимальная гибкость и «все в коде» - Camel.
- Надежная доставка событий и перенос данных между системами - Kafka Connect.
Важный вопрос на старте: кто будет сопровождать это через 12-18 месяцев. В организациях с жестким on-prem (например, госсектор и финансы) обычно заранее фиксируют владельца платформы, бюджет на обновления, правила разработки и график замены ключевых людей.
Соберите требования так, чтобы выбор был честным
Большинство ошибок выбора начинается не с WSO2 или MuleSoft, а с требований «по ощущениям». В итоге берут «универсальную платформу на все случаи», а через год получают набор исключений, который никто не хочет поддерживать.
Начните с инвентаризации интеграций: список систем, владельцы, критичность, частота изменений. Важно закрепить владельца с каждой стороны. Если у сервиса нет владельца, изменения прилетают внезапно, и интеграция быстро становится хрупкой.
Дальше разложите потоки по классам. Обмен справочниками обычно терпит задержки и пакетность. Транзакции требуют предсказуемого времени ответа и понятной обработки ошибок. Файлы упираются в формат, расписание и контроль дублей. События требуют порядка, идемпотентности и четких правил повторной доставки.
Не пропускайте нефункциональные требования. SLA, RPO/RTO, шифрование, аудит, журналирование, хранение логов и регуляторика (госсектор, медицина, финансы) часто влияют на выбор больше, чем список коннекторов.
Для on-prem заранее выпишите ограничения: сегментация сети, где можно ставить агенты и коннекторы, какие порты разрешены, какие есть окна обновлений и какое «железо» реально доступно. Нередко оказывается, что проще поменять один сетевой маршрут, чем строить вокруг него сложный обход.
Мини-проверка, которая хорошо сокращает «особые случаи»: можно ли стандартизировать форматы и справочники до начала работ; где нужен синхронный вызов, а где лучше очередь или события; какие ошибки критичны и кто их разбирает ночью; что должно переживать перезапуск (сообщения, статусы, корреляция); какие системы будут меняться чаще всего в ближайший год.
Когда требования оформлены так, выбор превращается из спора мнений в сравнение конкретных сценариев и рисков.
Критерии выбора, которые обычно забывают
При сравнении ESB и iPaaS on-prem часто смотрят на коннекторы и удобство разработки. А через год выясняется, что «платформа» - это набор настроек и скриптов, которые никто не может безопасно менять.
Эксплуатация и поддержка 24/7
Первый вопрос не про разработку, а про жизнь после запуска. Нужны мониторинг, трассировка запросов через несколько систем, понятные алерты и удобная повторная обработка сообщений. Если для анализа инцидента надо вручную собирать логи по серверам, команда выгорит быстро. Проверьте, как платформа показывает зависшие интеграции, где видна причина ошибки и можно ли переиграть обработку без «ручных костылей».
Изменения без ломки и паники
Интеграции чаще ломаются от изменений: новая версия API, правка формата поля, миграция системы. Нужны правила версионирования контрактов, контрактные тесты и понятный путь миграции. Хороший признак - когда можно держать две версии интерфейса параллельно и постепенно переводить потребителей.
То, что стоит проверить до выбора (и что часто пропускают в демо): как хранятся и ротируются секреты и сертификаты и есть ли аудит доступа; как устроена сеть (сегменты, прокси, mTLS, работа в закрытых контурах); как настраиваются ретраи, идемпотентность и dead letter очереди без «магии»; как платформа переживает пики нагрузки и падение узла; сколько стоит владение - лицензии, обучение, разработка, сопровождение и найм.
Пример: в госорганизации меняют формат идентификатора пациента в медсистеме. Если нет версий API и контрактных тестов, правка может остановить обмен с регистратурой, лабораторией и биллингом одновременно. Если есть версионирование, dead letter очередь и повторная обработка, вы сначала собираете «непонятные» сообщения отдельно, обновляете потребителей и только потом догоняете накопившиеся данные.
Финальный тест простой: «Сможем ли мы безопасно поддерживать это небольшой командой в дежурстве, по понятным регламентам?» Если ответ неясный, через год получится неподдерживаемый комбайн.
Пошаговый план: как выбрать подход и не ошибиться
Не начинайте со сравнения маркетинговых таблиц. Возьмите несколько реальных интеграций, которые точно будут в первый год, и посмотрите, как выбранный подход ведет себя в ваших условиях.
Выберите 2-3 потока разной природы. Например: API между фронтом и CRM, события для статусов заказов и ночной обмен файлами с бухгалтерией. Это быстро покажет, где нужен оркестратор, где достаточно коннекторов, а где важнее надежная доставка.
Дальше зафиксируйте правила данных. Назначьте владельцев доменов и ответьте на простой вопрос: кто главный источник для клиента, договора, сотрудника и справочников. Без этого вы получите бесконечные «сверки» и ручные правки даже при хорошей платформе.
Проверяйте подход по шагам. Опишите контракты (формат, частота, допустимая задержка, размер сообщений). Сделайте PoC в условиях реальной сети и безопасности: сегменты, прокси, закрытые порты, требования ИБ, сертификаты. Затем сразу продумайте эксплуатацию: какие дашборды нужны, какие алерты обязательны, кто дежурит и по каким регламентам.
Не откладывайте стандарты «на потом». Шаблоны маршрутов, единый формат ошибок, корреляционные ID, уровни логирования и правила ретраев решают больше, чем выбор конкретного продукта.
Внедряйте по волнам, а не «сразу все». Например, сначала 5-7 интеграций одного домена (скажем, закупки), затем следующий. Так команда успевает закрепить практики, и платформа не превращается в комбайн.
Частые ошибки, из-за которых получается неподдерживаемый комбайн
Самая частая причина провала - попытка построить «универсальную шину для всего» без границ. В один слой сваливают обмен с 1С, API для мобильных приложений, загрузки в хранилище, очереди, файлы и расписания. Через год никто не понимает, что здесь платформа, а что бизнес-логика, и любое изменение становится рискованным.
Вторая ошибка - смешивать оркестрацию бизнес-процессов и транспорт данных. Когда интеграционный слой начинает решать «кто кому должен позвонить и в какой последовательности», он быстро обрастает условиями, ручными исключениями и таймерами. В on-prem средах это особенно заметно, когда один продукт пытаются заставить заменить и BPM, и API management, и брокер сообщений.
Третья проблема проявляется позже всего: нет единых правил ошибок. Без стандартов для таймаутов, ретраев, дедупликации и идемпотентности появляются дубли заказов, «зависшие» статусы и ночные инциденты, которые сложно воспроизвести.
Еще один путь к комбайну - переусложнение трансформаций. Как только расчеты, валидации и ветвления живут в маппингах и скриптах интеграционной платформы, команда перестает понимать, где находится настоящая логика продукта.
Красные флаги, которые стоит заметить заранее:
- нет владельца каждого интеграционного потока и его SLA
- ошибки обрабатываются «как получится» в каждом проекте
- интеграции держатся на 1-2 людях без runbook
- нет каталога интерфейсов и схем сообщений
- изменения выкатываются вручную и без тестов
Пример из жизни: в организации с закупками, складом и бухгалтерией один специалист собрал десятки потоков и трансформаций «внутри шины». Когда он ушел, новые сотрудники увидели набор загадочных маршрутов и не смогли безопасно добавить даже одно поле.
Быстрая проверка перед покупкой и запуском
Перед покупкой лицензий или стартом разработки сделайте короткую проверку: она показывает, получится ли управляемая система, а не набор скриптов.
Возьмите 2-3 реальных потока (например, портал заявок -> CRM -> бухгалтерия или МИС -> лаборатория -> архив) и прогоните их через пять вопросов. Лучше делать это вместе: бизнес-владелец процесса, интеграционная команда и эксплуатация.
Проверьте:
- Управляемость: есть ли каталог интеграций, назначен ли владелец на каждый поток, понятны ли ответственность за данные, SLA и изменения.
- Наблюдаемость: можно ли за 5 минут понять, где «застрял» запрос, без ручного поиска логов по серверам.
- Версионирование: есть ли правила версий API и сроки поддержки старых контрактов.
- Сбои и повтор: где хранится очередь, как устроены ретраи, есть ли понятный путь обработки «ядовитых» сообщений.
- Обновления: можно ли обновлять ключевые компоненты без остановки критичных сервисов, и кто реально будет это делать в нерабочее время.
Небольшой тест: попросите инженера, который не участвовал в проекте, найти конкретную транзакцию по ID и объяснить ее путь. Если это занимает больше 10-15 минут, платформа не помогает, а усложняет.
Пример: как выбрать стек для реальной организации
Представим областную больницу в Казахстане. Есть МИС, бухгалтерия, склад, лаборатория, портал для пациентов и отдельная система для госотчетности. По требованиям безопасности все работает строго on-prem, а изменения проходят через согласования.
Потоки обычно разношерстные. Заявки на анализы и запись к врачу идут через API почти в реальном времени. Справочники (врачи, кабинеты, услуги, цены) синхронизируют раз в сутки. Финансовые операции и списание препаратов удобнее вести через события: кто и когда сделал действие, чтобы быстро находить ошибки и не терять данные.
Вариант A: ESB + отдельная очередь сообщений
Если много оркестрации (одна заявка запускает цепочку из 5-7 шагов), ESB удобен: маршрутизация, преобразования, правила. Очередь добавляют, чтобы не терять данные при сбоях и разгрузить системы. Минус простой: придется отдельно выстраивать мониторинг, деплой, версионирование и дисциплину разработки, иначе интеграции превратятся в набор ручных настроек.
Вариант B: iPaaS on-prem для управления жизненным циклом
Этот путь выбирают, когда важны единые процессы: кто изменил интеграцию, как она тестируется, как выкатывается и как откатывается. В больнице или банке, где много согласований и важен аудит, такой контроль снижает цену ошибки.
Вариант C: Kafka Connect для данных + Camel для нестандартных маршрутов
Если основной объем - перенос данных между системами и события по транзакциям, Kafka Connect закрывает типовые коннекторы и доставку. Apache Camel можно оставить для редких специфичных маршрутов.
Чтобы понять, что «потянет» эксплуатация, ответьте на несколько практичных вопросов: сколько людей реально будет сопровождать интеграции 24/7; смогут ли они разбирать инциденты без разработчиков; нужны ли строгие релизы и аудит изменений; сколько интеграций станет через год (10 или 100); есть ли время поддерживать самописные коннекторы и обновления.
Если команда маленькая, а требований к контролю много, чаще выигрывает управляемый платформенный подход. Если команда сильная и важна гибкость, связка Connect + Camel может дать меньше «комбайна» и более понятную ответственность.
Следующие шаги: как запустить и не бросить на полпути
Начните с понятной цели: какой интеграционный слой вам нужен и где его границы. Зафиксируйте, какие системы общаются только через этот слой (например, ERP и CRM), а где допустимы прямые вызовы (например, внутри одного приложения). Это снижает риск превратить платформу в «всё для всего».
Дальше нужен короткий пилот на 6-8 недель, который проверяет не красивые диаграммы, а жизнеспособность команды и подхода. Выберите 2-3 интеграции разного типа (запрос-ответ, пакетная загрузка, событие), задайте критерии успеха (скорость разработки, стабильность, наблюдаемость, сколько ручной поддержки нужно), договоритесь о правилах (версии API, ретраи, таймауты, обработка ошибок) и проведите «операционную репетицию»: развернуть, обновить, откатить.
Параллельно подготовьте базовые требования к инфраструктуре, иначе пилот будет «работать на ноутбуке», а в проде развалится. Нужны роли сред (dev, test, prod), сеть и доступы (сегментация, прокси, секреты), резервирование и восстановление (бэкапы, план RTO/RPO), мониторинг и логи (метрики, алерты, трассировка), регламент обновлений (окна, ответственность, проверка совместимости).
Чтобы система не держалась на «героях», заложите обучение и передачу в поддержку: короткие гайды, шаблоны интеграций, чеклисты инцидентов, роли дежурных. Если проект требует on-prem внедрения и дальнейшей эксплуатации 24/7, логично заранее привлекать интегратора, который берет на себя и инфраструктуру, и поддержку. Например, GSE.kz занимается системной интеграцией, поставкой серверной инфраструктуры и круглосуточной технической поддержкой с сервисной сетью по Казахстану.
FAQ
Почему интеграции чаще ломаются, даже если выбран «правильный» продукт?
Чаще всего ломается не продукт, а процесс: нет владельцев потоков, данные называются по‑разному, изменения согласуют в чатах, а тестов и регламентов нет. В итоге интеграция превращается в набор исключений, который понимают только авторы, и любое обновление одной системы запускает цепочку непредсказуемых правок.
В чем простое отличие ESB и iPaaS?
ESB обычно работает как центральный узел, который принимает запросы, маршрутизирует их, преобразует данные и может управлять последовательностью шагов. iPaaS больше про управление жизненным циклом интеграций: стандарты, каталог, роли и доступы, централизованный мониторинг, версионирование и выпуск изменений как у обычного ПО.
Зачем вообще делать ESB/iPaaS on-prem, а не в облаке?
On-prem выбирают, когда данные нельзя выносить наружу, нужен контроль сетевых контуров и доступ к внутренним системам, которые физически не открывают в интернет. Это типично для госсектора, финансов, медицины и для инфраструктур, где важны аудит, регуляторные требования и предсказуемые окна обновлений.
Когда лучше API, а когда очереди и события?
Синхронные API подходят, когда пользователю нужен ответ прямо сейчас, например при создании заявки или проверке статуса на экране. Очереди и события лучше, когда важнее надежно доставить факт и пережить сбой: «оплата прошла», «заказ отгружен», «пациент зарегистрирован». Ошибка начинается, когда строят длинные синхронные цепочки там, где нужна устойчивость, или наоборот добавляют задержки в пользовательские сценарии.
Как не превратить интеграционную платформу в неподдерживаемый «комбайн»?
Оставьте интеграционному слою транспорт, маршрутизацию, преобразования и контроль надежности, а бизнес‑логику держите в сервисах, где она тестируется и версионируется. Помогают границы: какие системы обязаны ходить через платформу, единый формат ошибок, правила таймаутов и ретраев, и запрет на «уникальные» скрипты без ревью и тестов.
Какие критерии выбора обычно забывают при сравнении ESB и iPaaS?
Проверьте не только коннекторы, а то, как платформа живет после запуска: мониторинг, трассировка, понятные алерты, повторная обработка, хранение и ротация логов. Отдельно важно, как устроены секреты и сертификаты, есть ли аудит действий, как платформа переживает падение узла и пики нагрузки, и насколько реально обновлять ее без остановки критичных потоков.
Как на практике выбрать между WSO2, MuleSoft, Apache Camel и Kafka Connect?
WSO2 часто берут как экосистему: управление API, интеграционный слой и управление доступом, но это требует аккуратной эксплуатации и дисциплины по версиям и наблюдаемости. MuleSoft удобен как iPaaS с большим числом коннекторов и быстрым сбором потоков, но важно заранее договориться о правилах governance и владения. Apache Camel дает свободу «все в коде» и хорошо ложится на сильную инженерную культуру, но без стандартов легко разъезжается по разным стилям. Kafka Connect уместен, когда главный фокус — перенос данных и событийные потоки, а сложную оркестрацию лучше вынести отдельно.
Как правильно провести пилот (PoC), чтобы выбор был честным?
Сделайте короткий PoC на 2–3 реальных потоках разной природы и прогоните его в вашей сети и с вашей безопасностью, а не «на демо-стенде». Успех PoC — это не только «заработало», а то, что команда может быстро найти транзакцию по ID, понять причину ошибки, повторно обработать сообщение и безопасно выкатить изменение с откатом.
Как организовать версионирование API и изменения форматов, чтобы ничего не ломать?
Начните с простых правил: кто владелец контракта, как выпускаются версии, сколько живет старая версия и как тестируется совместимость. Хорошая практика — поддерживать две версии параллельно на время миграции и иметь контрактные тесты, чтобы изменения форматов не ломали потребителей внезапно.
Кто должен сопровождать интеграционную платформу через год и что делать, если своей команды не хватает?
Если вам нужен on-prem с эксплуатацией 24/7, заранее решите, кто отвечает за платформу, обновления и дежурство, и где будет сервисная поддержка. В таких проектах часто привлекают системного интегратора, который берет на себя инфраструктуру, разворачивание, мониторинг и поддержку; например, GSE.kz может закрыть системную интеграцию, поставку серверов и круглосуточную техническую поддержку с сервисной сетью по Казахстану.