Data lineage: трассировка показателей от документа до дашборда
Data lineage помогает показать путь показателя от первичного документа до дашборда: разберем уровни lineage и функции, которые стоит искать в платформах данных.
Зачем разбирать путь цифры
Цифры в отчетах часто не совпадают, потому что по дороге они меняются. В одной системе документ уже исправили, в другой еще нет. Где-то суммы округляют, где-то пересчитывают курс, а где-то берут другой срез данных. Итог простой: на совещании спорят не о решениях, а о том, какая цифра правильная.
В бизнесе «показатель» - это не просто число. У него есть формула (что именно считаем), период (за какой интервал), правила отбора (какие филиалы, продукты, статусы) и исключения (например, возвраты или внутренние продажи). Если хотя бы один элемент различается, две «выручки» будут разными, даже если обе посчитаны честно.
Умение ответить на вопрос «откуда взялась цифра» превращает отчет из мнения в доказательство. В этом и смысл data lineage: показать цепочку от первичного документа и источника до итогового графика, включая преобразования и проверки. Тогда можно быстро найти шаг, на котором возникло расхождение, и исправить причину, а не симптомы.
Это важно не только аналитикам и IT. Обычно первыми задают вопросы финансы (закрытие периода, сверки, аудит), комплаенс и риск (контролируемость расчетов, прозрачность), руководители (доверие к KPI и скорость решений), владельцы процессов (понимание, что влияет на показатель).
Когда путь цифры понятен, обсуждение смещается с «почему не сходится» на «что делаем дальше».
Data lineage и трассировка показателей простыми словами
Data lineage - это понятная карта того, откуда взялась цифра и что с ней происходило по пути. Не просто «данные пришли из 1С», а какой именно объект был источником, какие поля взяли, как их очистили, объединили, пересчитали и в каком виде они попали в витрину и на дашборд.
Lineage показывает не только перемещение данных, но и смысловые преобразования. Например, «сумма по документам» становится «выручкой» только после фильтров (исключили возвраты), правил (учли НДС или нет) и пересчета по курсу.
Чем это отличается от ETL-документации? Документация чаще описывает процесс в целом: какие задачи запускаются и куда пишут результат. Data lineage отвечает на вопрос пользователя: «почему в этом KPI такое число» и позволяет пройти по цепочке назад до конкретного источника. Это также надежнее, чем «знания в голове» одного аналитика: когда человек уходит, вместе с ним не должно уходить понимание показателей.
Трассировка показателей идет глубже, чем «таблица A загрузилась в таблицу B». Нужна связь формулы KPI с данными: из каких полей берутся компоненты, какие фильтры применены, как считаются доли, план-факт, скользящие средние. Без этого вы сможете отследить строку в таблице, но не сможете объяснить итоговую цифру на графике.
Цепочка часто ломается там, где появляется ручной шаг. Типичный сценарий: бухгалтер выгрузил отчет, поправил его в Excel, отправил файл по почте, а аналитик подгрузил в BI. В итоге источник и правила правок не зафиксированы, а «путь цифры» превращается в догадки и перепроверки.
Какие уровни lineage бывают и чем они отличаются
Data lineage часто рисуют как одну схему, но на практике это несколько слоев. Чем четче разделены уровни, тем быстрее находится причина, почему цифра на дашборде изменилась.
Технический lineage
Это слой, привычный инженерам: какие файлы, таблицы и колонки участвовали, какие трансформации прошли данные, какие пайплайны и задачи их перемещали. Он отвечает на вопрос: «из каких источников собрана витрина и какие шаги были между ними».
Пример: заказ из учетной системы попал в таблицу raw, затем очистился, объединился со справочником клиентов и оказался в витрине продаж, из которой уже считает BI.
Бизнес-lineage
Этот слой объясняет смысл: как показатель определяется в словаре данных, какие фильтры и правила в него входят, какие метрики и отчеты построены поверх данных. Он отвечает на вопросы: «что означает эта цифра» и «какие бизнес-правила в ней спрятаны».
Без бизнес-слоя «путь цифры» остается туманным: вы видите, что revenue считается из amount, но не понимаете, включает ли он НДС, возвраты, скидки, пересчет валюты и на каком шаге это произошло.
Операционный lineage
Это про факт выполнения: кто и когда запускал расчет, с какими параметрами, какие версии кода и справочников использовались, что было в логах, были ли ошибки и повторные прогоны. Он отвечает на вопрос: «почему именно сегодня цифра стала другой», даже если логика не менялась.
Когда все три уровня собраны вместе, получается трассировка, понятная и технарю, и владельцу показателя: смысл, путь и история выполнения в одном месте.
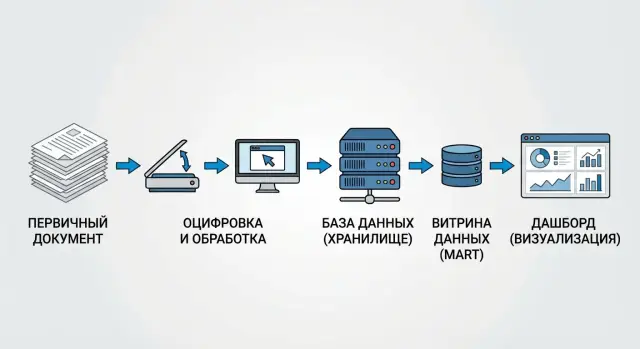
Карта пути: от первичного документа до дашборда
Чтобы показать путь цифры, удобнее всего представить ее как посылку: у нее есть отправитель (первичный документ), сортировочные центры (системы и слои данных) и точка выдачи (дашборд). Хорошая карта пути отвечает на два вопроса: откуда взялась цифра и что с ней сделали по дороге.
Маршрут обычно начинается с первичного документа: договор, накладная, платежное поручение, акт приемки услуги. Важно фиксировать не только номер и дату, но и ключевые поля, из которых потом сложится показатель (сумма, валюта, контрагент, дата признания).
Дальше данные попадают в системы-источники: ERP, бухгалтерия, CRM, кадровые системы. Уже на этом этапе появляются расхождения: разные статусы (проведен или нет), разные справочники, ручные корректировки.
Практичная карта data lineage чаще всего укладывается в четыре шага: источник (где первичка и какой объект системы является «истиной»), хранилище (как данные загружаются в raw и приводятся к cleaned), витрины (в каком mart собирается показатель и по каким правилам), BI-слой (какая семантическая модель, какие вычисляемые поля и фильтры в дашборде).
Простой пример: в отчете «Выручка за месяц» цифра берется из платежей, но в cleaned-слое исключили возвраты, а в mart добавили правило «признавать по дате акта». В BI сверху стоит фильтр «только оплаченные». Если показать эти преобразования рядом с привязкой к первичным документам, пользователи быстро понимают, почему их «выручка» отличается от бухгалтерской и где именно это произошло.
Как описать показатель так, чтобы его можно было трассировать
Трассировка начинается не с инструмента, а с нормального описания показателя. Если «выручка» или «количество обращений» живут только в голове аналитика, даже самая красивая схема lineage на дашборде не ответит на вопросы.
Для каждого критичного показателя полезна короткая карточка. В ней важна конкретика:
- Владелец: кто отвечает за смысл и изменения (роль или конкретный человек).
- Формула: как считаем (с НДС или без, по оплате или по отгрузке) и за какой период.
- Частота обновления: раз в час, ежедневно, по закрытию дня.
- Допустимые исключения: что считается ошибкой, а что нормальной вариацией.
Дальше показатель нужно привязать к источникам и полям. Не «берем из ERP», а «таблица X, поле Y». Для каждого атрибута отметьте «источник истины»: дата оплаты - из платежного модуля, контрагент - из справочника, статус заказа - из CRM.
Самое частое слабое место - преобразования. Зафиксируйте правила очистки (как убираете дубли и выбираете «последнюю версию» записи), маппинги кодов, джойны (по каким ключам склеиваете) и фильтры.
Добавьте точки контроля: где и как сверяете результат. Например, «сумма по оплатам за день должна сходиться с бухгалтерским отчетом с допуском до 0,5%», а при отклонении уходит алерт владельцу показателя.
Пошагово: как показать путь цифры на практике
Начните с небольшого пилота. Выберите один показатель и один отчет, где он используется, и договоритесь, что именно вы хотите доказать: откуда берется цифра, какие преобразования она проходит и кто отвечает за изменения.
Для пилота хорошо подходит «выручка за месяц» в одном финансовом дашборде: у показателя много пользователей, и расхождения обычно быстро проявляются.
Дальше двигайтесь по шагам:
- Выберите один показатель и один конкретный отчет (дашборд или таблицу), где он виден пользователю.
- Соберите полный список источников и промежуточных объектов: первичные документы, выгрузки, таблицы, витрины, модели BI.
- Постройте зависимости в обе стороны: сверху вниз (от дашборда к источникам) и снизу вверх (от документа к дашборду).
- Проверьте цепочку на реальных данных: возьмите 2-3 строки из первички и вручную проследите, как они превращаются в метрику.
- Зафиксируйте результат в каталоге данных и в регламенте изменений, чтобы цепочка не «сломалась» после правок.
Чтобы шаг с проверкой проходил быстро, заранее подготовьте «пакет доказательств»: идентификатор документа, ключи (номер, дата, контрагент), поле суммы, правило фильтрации (например, только проведенные документы) и формулу агрегации.
Если в проверке не сходится даже пара строк, причина обычно в одном из трех мест: фильтры (что-то исключили), справочники (переопределили атрибуты) или дедупликация (склеили записи). Это лучше поймать на пилоте, чем после публикации дашборда.
Типовые ошибки и ловушки при внедрении lineage
Самая частая проблема начинается не с инструментов, а с смысла. Если у показателя нет одного утвержденного определения, команды считают его по-разному: финансы берут сумму по оплатам, продажи - по отгрузкам, аналитики - по счетам. В итоге трассировка превращается в спор.
Вторая ловушка: lineage есть только на уровне таблиц. На схеме видно, что витрина собрана из нескольких источников, но не видно, какая колонка откуда пришла и где именно применили формулу, фильтр или курс валют. Для KPI это критично: 2-3 строки логики могут сдвинуть итог на проценты.
Еще один разрушитель доверия - ручные правки в выгрузках. Когда кто-то «чуть поправил Excel перед загрузкой» или заменил значения в CSV, аудит ломается: в lineage этого шага нет, а цифра на дашборде уже другая.
Полезно заранее проверить, не попадаете ли вы в эти сценарии:
- у показателя нет владельца, который подтверждает определение и изменения;
- логика хранится в голове или в переписке, а не рядом с данными;
- lineage показывает путь набора данных, но не путь конкретных полей и расчетов;
- источники меняются (поля, типы, справочники), а уведомлений и тестов нет;
- «временные» ручные правки становятся постоянными.
Пример: отдел закупок переименовал статус документа в учетной системе, и фильтр «только оплачено» перестал работать. Отчет не упал, просто «тихо» сместилась выручка. Без владельца показателя и отслеживания изменений в источниках такую причину ищут неделями.
Хорошая практика - закрепить владельцев данных, хранить формулы и правила рядом с метаданными и требовать lineage на уровне колонок и расчетов, а не только таблиц.
Какие функции lineage искать в платформах данных
При выборе платформы смотрите не на красивую схему, а на то, сколько ручной работы она снимает с команды. Хороший lineage строится из реальных процессов и обновляется сам, а не живет в презентации.
Автоматический сбор и глубина трассировки
Платформа должна уметь подтягивать связи из ваших ETL/ELT, оркестраторов и SQL, чтобы не рисовать все вручную. Иначе lineage быстро устареет, особенно когда меняются источники, расписания и логика трансформаций.
Проверьте глубину: часто нужен путь не только «таблица в таблицу», но и до уровня колонок (какое поле из первичного документа превратилось в конкретный столбец витрины). Бизнесу, в свою очередь, важно видеть обратную зависимость: какие отчеты, дашборды и метрики зависят от этой колонки.
На демо достаточно попросить показать три вещи: автопостроение lineage из пайплайнов и SQL с регулярным обновлением; связь «колонка -> трансформация -> метрика/отчет» в обе стороны; визуализацию, где видны шаги и фильтры, а не только конечные узлы.
Словарь, версии и доступы
Lineage бесполезен без человеческих названий. Нужны поиск по терминам и синонимам и единый словарь, где «выручка», «доход» и sales сводятся к одному определению. В больших организациях это снимает много споров.
Критичная функция - версионирование. Должно быть видно, что изменилось, когда и кто согласовал. Пример: поменяли правило учета возвратов, и KPI в дашборде «поехал». Без истории изменений вы будете долго разбираться, где произошел сдвиг.
И наконец, права доступа. Lineage должен учитывать ограничения: кто видит полный путь, а кто - только обезличенную часть. Полезно, когда платформа поддерживает маскирование чувствительных полей и при этом не «ломает» трассировку для аудиторов и владельцев данных.
Как оценить качество lineage: простые критерии
Хороший data lineage помогает быстро ответить на вопросы: откуда взялась цифра в отчете, кто и когда ее изменил и можно ли этому доверять.
Оценивать удобно по пяти критериям.
Точность: видно ли реальные преобразования или только стрелки между системами. Если lineage показывает конкретные шаги (SQL, правила в ETL, формулы в модели), вы сможете объяснить расхождение и найти место, где оно появилось.
Полнота: покрывает ли трассировка весь путь - источники, слои хранения и витрины, BI, включая расчетные поля и меры. Частая проблема - все понятно до витрины, а дальше в дашборде появляются «серые зоны», где KPI пересчитывается без контроля.
Актуальность: как быстро карта отражает изменения (новый столбец, переименование, новый фильтр). Простой тест - поменять формулу или пайплайн в тестовой среде и проверить, когда это появится в зависимостях.
Удобство: бизнесу нужны понятные названия и расшифровка шагов («из счета-фактуры берем сумму без НДС»), инженерам - детали (поля, джобы, версии, владельцы). Если все видно только одной группе, ценность для компании падает.
Аудит: можно ли выгрузить историю изменений и доказательства для проверок. Важно уметь показать не «картинку», а цепочку версий и подтверждение, от каких документов шли данные в конкретный период.
Пример сценария: почему KPI «выручка» вдруг стал другим
Финдиректор смотрит дашборд и видит выручку за месяц 1,2 млрд. Руководитель продаж показывает свой отчет и называет 1,35 млрд. Оба уверены, что правы, потому что цифры «из системы». Это классическая задача для data lineage: найти, где разошлись определения и данные.
Часто первое расхождение начинается с источника и набора документов. Финансы считают по закрывающим документам и проводкам (с учетом дат признания, возвратов, корректировок). Продажи - по отгрузкам или по счетам, иногда по заказам; где-то включают НДС, где-то не исключают отмененные сделки. Здесь важно явно перечислить, какие операции входят в расчет: продажи, возвраты, бонусы, скидки, корректировки, курсовые разницы.
Дальше включается трассировка по шагам обработки. Расхождение обычно находится в одном из мест:
- на загрузке потерялись строки (например, фильтр по статусу «проведен» отсекает часть документов);
- на преобразовании поменялась логика (например, дата берется «дата счета», а не «дата отгрузки»);
- на уровне витрины или дашборда стоит фильтр (например, исключены филиалы);
- в справочниках разные маппинги (например, часть продаж уходит на другое юрлицо).
Когда точка расхождения найдена, правило нужно зафиксировать как единое определение KPI: формула, список источников, условия включения, дата, валюта, НДС, обработка возвратов. Параллельно стоит поставить контроль качества: сверки между слоями (источник -> витрина -> дашборд), алерты при резких отклонениях и проверки полноты (сколько строк было и сколько стало на каждом шаге).
Короткий чек-лист перед запуском дашборда
Перед публикацией дашборда полезно сделать быстрый прогон: сможете ли вы объяснить любую цифру так, чтобы у бизнеса не осталось вопросов. Такой чек занимает 10-15 минут, но экономит дни разборов после релиза.
Проверьте пять вещей:
- у показателя есть владелец (имя или роль) и зафиксированное определение: что считаем, в какой валюте и периоде, с какими исключениями;
- понятно, какие источники первичные, а какие производные (например, первичен счет/акт/операция, а выгрузка в Excel - нет);
- видно, где происходят ключевые преобразования: фильтры, правила дедупликации, пересчет курсов, маппинг справочников;
- есть объяснение на одном примере: 1 документ и 1 строка, как она проходит через загрузку, расчет и попадает в нужную ячейку;
- перед публикацией есть контроль: проверки качества, сверки с эталоном и журнал изменений, чтобы можно было ответить «когда и почему цифра изменилась».
Мини-сценарий для проверки: выберите одну строку счета на 100 000, найдите ее в витрине по ключу, убедитесь, что она не отфильтрована, и посмотрите, какой шаг добавил НДС или пересчитал валюту. Если на любом шаге вы не можете быстро показать «где это произошло», дашборд лучше не выпускать.
И отдельно договоритесь, кто утверждает изменения в логике расчетов. Даже маленькая правка фильтра без записи в журнале превращает вопросы к цифрам в бесконечный спор.
Следующие шаги: как начать с малого и масштабировать
Не пытайтесь сразу покрыть весь контур данных. Выберите 3-5 показателей, которые чаще всего обсуждают на планерках и по которым чаще всего «не сходятся цифры». На них проще всего показать ценность: когда путь цифры прозрачен, спор заканчивается заметно быстрее.
Стартовый набор шагов обычно выглядит так: зафиксировать список показателей и их официальные определения (формулы, периоды, исключения), построить сквозную цепочку «первичный документ -> загрузка -> хранилище -> витрина -> BI-дашборд», настроить простые проверки качества на ключевых точках (полнота, дубликаты, аномалии), сделать «паспорт показателя» (владелец, источник, обновление, где используется), договориться, как обновлять описание при изменениях (релизы, заявки, согласование).
Дальше важно закрепить роли. Без ответственности все быстро превращается в набор разрозненных заметок. Обычно достаточно трех: владелец данных (источники и загрузки), владелец показателя (смысл и формула) и владелец отчета (как цифра показана в BI). Тогда на вопрос «почему изменилось значение» сразу понятно, кто отвечает за какой участок.
Как масштабировать без перегруза
Масштабирование лучше делать волнами: сначала финансы и продажи, потом операционные метрики, затем регуляторная отчетность. Например, если вы уже протрассировали «выручку» и «маржу», следующий логичный шаг - «дебиторка» и «доля просрочки», потому что они часто завязаны на те же документы и справочники.
Параллельно стоит продумать базу: каталог данных и метаданные, DWH, BI, контроль качества и единые правила именования. Если нужен партнер, который соберет такой контур под требования организации и возьмет на себя интеграцию, этим занимается GSE.kz (gse.kz) как системный интегратор, с поддержкой и инфраструктурными решениями для корпоративных сред.
FAQ
Что такое data lineage простыми словами?
Data lineage — это описание и визуальная «цепочка» того, откуда взялись данные для показателя и какие преобразования они прошли до отчета. По нему можно пройти назад от KPI на дашборде до конкретных документов, таблиц, полей и правил расчета, чтобы быстро найти причину расхождений.
С чего начать, если у нас постоянно «не сходятся цифры» в отчетах?
Сначала зафиксируйте официальное определение показателя: формулу, период, фильтры и исключения. Затем привяжите каждый элемент формулы к конкретным источникам и полям, и проверьте цепочку на 2–3 реальных документах, чтобы убедиться, что правила действительно работают так, как описаны.
Чем data lineage отличается от обычной ETL-документации?
ETL-документация обычно описывает процесс загрузки и преобразований в целом, а lineage отвечает на пользовательский вопрос «почему здесь такое число». Хороший lineage позволяет раскрыть путь конкретной цифры в KPI, включая фильтры, джойны, дедупликацию, курсы валют и вычисления в BI.
Какие уровни lineage бывают и зачем разделять их?
Технический слой показывает, какие объекты данных и пайплайны участвовали и как данные перемещались и трансформировались. Бизнес-слой объясняет смысл показателя и правила расчета. Операционный слой фиксирует, когда и кем выполнялся расчет, с какими версиями кода и справочников, и почему значение могло измениться сегодня при той же логике.
Что должно быть в «паспорте показателя», чтобы KPI можно было трассировать?
Паспорт помогает сделать показатель проверяемым и поддерживаемым: у него появляется владелец, единое определение и понятные источники. В паспорте важны формула, период, обновление, исключения, источники «истины» для ключевых полей и точки контроля, где вы сверяете результат.
Почему ручные правки в Excel так часто ломают трассировку?
Потому что часть логики оказывается «вне системы»: кто-то поправил выгрузку, заменил значения, переименовал столбцы, а следов не осталось. Минимальная защита — убрать ручные правки из критичных цепочек, а если без них нельзя, фиксировать автора, дату, причину и точные правила изменений рядом с данными.
Как быстро понять, почему KPI «выручка» в двух отчетах разный?
Самые частые причины — разные фильтры и статусы документов, разные правила признания даты, отличия в учете НДС/скидок/возвратов, и разные маппинги справочников. Lineage помогает локализовать расхождение: где именно применили правило, какой источник считается «истиной», и на каком шаге изменился смысл цифры.
Какие вопросы задать на демо платформы, чтобы проверить качество lineage?
Попросите показать путь «колонка → трансформация → метрика/отчет» в обе стороны и убедитесь, что он строится автоматически из ваших пайплайнов и SQL. Также проверьте, видно ли вычисления и фильтры в BI, а не только стрелки между таблицами, и есть ли история изменений с датами и ответственными.
Как оценить, что lineage у нас действительно работает, а не «для галочки»?
Проверяйте, можно ли объяснить любую цифру на примере одного документа: где он попал в хранилище, как очистился, где применились фильтры и как дошел до графика. Дополнительно важно, чтобы карта зависимостей быстро обновлялась после изменений, и чтобы была история версий для аудита и разборов инцидентов.
Кто должен отвечать за показатель и за изменения в его расчете?
Обычно это владелец показателя (смысл и изменения формулы), владелец данных/источников (качество и загрузки) и владелец отчета (как KPI считается и отображается в BI). Когда роли закреплены, вопрос «почему изменилось значение» сразу попадает к правильному человеку, а изменения перестают быть «тихими».