Быстрый старт Oracle Enterprise Manager: архитектура и алерты
Быстрый старт Oracle Enterprise Manager: минимальная архитектура, подключение БД и middleware, сбор метрик, типовые дашборды и алерты для эксплуатации.
Задача: быстро начать мониторинг БД и middleware без лишнего
Когда у БД и middleware нет единого мониторинга, эксплуатация живет "по симптомам". Пользователи пишут "тормозит", интеграции падают без понятной причины, а дежурные узнают о проблеме из чатов, а не по алерту. При этом нет общей картины: где именно узкое место - хост, база, пул соединений, диски, бэкапы или место в FRA.
Oracle Enterprise Manager (OEM) нужен не для графиков, а чтобы каждый день отвечать на базовые вопросы продакшена:
- Доступность: живы ли хосты, БД и компоненты middleware, не "отвалился" ли listener или managed server.
- Производительность: растут ли задержки, блокировки, очереди, CPU, I/O, число соединений.
- Емкость: хватает ли места на файловых системах, в tablespace и FRA, не упираемся ли в память и диски.
- Бэкапы: выполняется ли RMAN, есть ли свежий успешный бэкап, не копятся ли ошибки.
Реалистичная цель быстрого старта - за 1-2 дня поднять минимальную архитектуру OEM, подключить несколько ключевых целей (хосты, 1-3 БД, один контур middleware) и включить типовые алерты, которые ловят 80% инцидентов. Тогда дежурство становится предсказуемым: сначала сигнал, затем диагностика, потом действия.
Дальше нет тонкой настройки порогов под каждую систему и глубокого тюнинга. Фокус другой: поставить, подключить, начать собирать базовые метрики и собрать понятные дашборды, чтобы мониторинг начал приносить пользу уже на этой неделе.
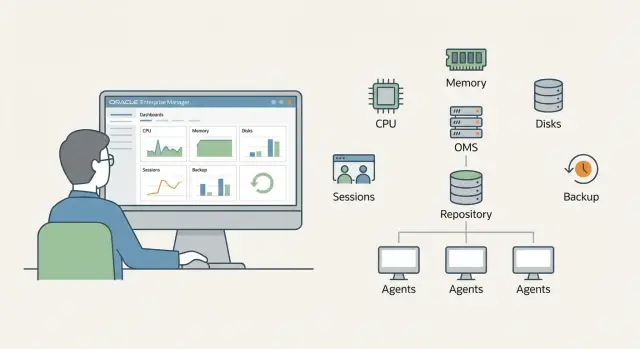
Минимальная архитектура OEM: что нужно в первом приближении
Для старта достаточно понимать три роли, которые есть даже в самой небольшой установке.
OMS (Oracle Management Service) - центральный сервер, куда приходит телеметрия и где открывается консоль. Management Repository - база данных, в которой хранятся метрики, события, настройки, история алертов и отчеты. Агент (OEM Agent) - сервис на каждом хосте с БД или middleware: он собирает показатели и отправляет их в OMS.
Минимальный набор обычно такой:
- 1 OMS
- 1 БД под Repository
- агенты на хостах с Oracle Database и middleware
Все остальное имеет смысл переносить на вторую волну, когда система уже работает и есть понимание нагрузки: второй OMS для отказоустойчивости, балансировщик перед OMS, standby-база для Repository, отдельный сервер отчетности или интеграций.
Где размещать компоненты
Самый частый вариант для старта - отдельная ВМ под OMS и отдельная ВМ под Repository. Так проще обслуживать, обновлять и находить узкие места. Если инфраструктура небольшая, OMS и Repository иногда ставят вместе, но при росте нагрузки вы быстрее упретесь в диски и память.
Если у вас критичные контуры (гос, банк, медицина), практичнее заранее планировать разнесение по узлам и понятное резервирование. В интеграционных проектах, похожих на те, что делает GSE.kz, это обычно сокращает простой и упрощает поддержку 24/7.
Что важнее всего для стабильности
Чаще всего OEM "ложится" не из-за CPU, а из-за хранения и задержек сети. Заранее проверьте:
- быстрые диски под Repository (IOPS важнее объема)
- стабильную сеть между агентами, OMS и Repository
- регулярные бэкапы Repository и место под рост истории
- резервирование: хотя бы бэкап, позже - standby и второй OMS
Такой минимум дает опору: вы подключаете цели, включаете типовые алерты и в первую неделю видите реальные проблемы, а не "шум".
Быстрая прикидка ресурсов и размещения
Размер OEM почти всегда упирается в один вопрос: сколько целей вы будете мониторить в первые 2-4 недели. Под "целями" обычно понимают хосты, экземпляры Oracle Database, слушатели, ASM, WebLogic домены и ключевые компоненты middleware. Для старта считайте именно первые цели, а не "потом весь ЦОД".
Что считать и где размещать
Для черновой оценки выпишите: число хостов, БД (prod и test отдельно) и middleware. Если есть изолированные сегменты сети, заранее проверьте, как пойдут соединения от агентов к серверу управления.
Если целей немного, на старте иногда хватает одной площадки (одна ВМ или один сервер) для сервера управления и репозитория. Если планируется рост или есть жесткие требования по отказоустойчивости, разделяйте роли: OMS отдельно, репозиторий отдельно.
Минимально приемлемо и комфортно для старта
| Компонент | Минимально (до ~30-50 целей) | Комфортно (до ~100-150 целей) |
|---|---|---|
| CPU | 4 vCPU | 8-12 vCPU |
| RAM | 16 ГБ | 32-64 ГБ |
| Диск под репозиторий | 200-300 ГБ | 500 ГБ - 1 ТБ |
| Диск под логи/диагностику | 50-100 ГБ | 150-300 ГБ |
Диск важнее "красивых" CPU: рост репозитория, история метрик и алертов, диагностические данные съедают место незаметно. Хорошее правило: выделить отдельные тома хотя бы под данные репозитория и под логи, чтобы всплеск логов не "положил" базу репозитория.
Пример: если вы начинаете с 10 хостов, 12 БД (prod+test) и 2 WebLogic доменов, комфортная конфигурация из таблицы обычно позволяет включить типовые метрики и хранить историю без постоянной чистки уже в первый месяц.
Установка и первичная настройка: план на один рабочий день
Чтобы запуск не растянулся на неделю, заранее соберите вводные. Больше всего времени обычно уходит не на инсталлятор, а на доступы, имена и доверие между хостами.
До начала: что подготовить
Нужны DNS-имя для сервера OMS (прямое и обратное разрешение), учетные записи (root или sudo для установки агента, отдельный пользователь для ПО), параметры прокси (если есть) и решение по сертификатам. Если в компании строго с TLS, сразу уточните: подойдет ли внутренний CA или нужен заранее выпущенный сертификат.
Также заранее определите БД под репозиторий (обычно отдельная Oracle Database). Для пилота можно начать с одной БД, но лучше сразу заложить место под рост и бэкап.
План на день (реалистичный)
- Подготовить ОС: пакеты, лимиты, время (NTP), firewall-порты, диски под софт и репозиторий.
- Развернуть или подготовить БД под репозиторий: параметры, табличные пространства, доступы.
- Установить OMS и создать репозиторий, проверить запуск сервисов.
- Зайти в консоль, добавить первый хост и поставить агент, убедиться, что метрики приходят.
- Включить базовые настройки эксплуатации: уведомления и хранение.
После установки сделайте короткие проверки: открывается ли консоль с рабочего места, как быстро грузятся главные страницы (если заметно медленно - чаще всего это DNS, сертификаты или ресурсы), корректны ли часовой пояс и время (иначе графики и алерты будут сбивать с толку).
Сразу имеет смысл включить почтовый канал уведомлений, рабочие часы и окна обслуживания, политику хранения (чтобы не переполнился диск) и базовую аутентификацию операторов. Если OEM внедряется под требования госсектора или финансовых организаций, заранее согласуйте это с ИБ - на практике это часто экономит день на согласованиях (в проектах GSE.kz такое бывает регулярно).
Подключаем цели: хосты, БД и middleware
На практике больше всего времени уходит на первые подключения целей. Логика простая: сначала хост, затем база, затем middleware. Так вы сразу понимаете, что агент живой, и не ищете ошибку одновременно в трех местах.
Начните с агента на нужном хосте. После установки укажите адрес OMS и зарегистрируйте агент. В OEM хост должен появиться как Target, а у агента должен быть статус Up. Если хост не виден, чаще всего проблема в DNS/hostname, портах или синхронизации времени.
Дальше добавьте Oracle Database. Понадобятся учетные данные (обычно SYSDBA или отдельный мониторинговый пользователь) и доступность listener. После добавления проверьте базовое: OEM видит инстанс, статус Open, режим ARCHIVELOG (если ожидается) и собираются метрики по сессиям и табличным пространствам.
Для middleware (например, WebLogic) заранее подготовьте доступы. Минимум обычно такой:
- учетная запись WebLogic Admin (или пользователь с правами чтения конфигурации)
- адрес и порт Admin Server
- JVM параметры, если доступ ограничен прокси или фаерволом
- права ОС на хосте (если агент будет читать логи и процессы)
После добавления целей сделайте короткие sanity-checks:
- хост виден и обновляется без ошибок
- у базы и WebLogic есть свежие метрики
- Last Upload агента не старше 5-10 минут
- нет критических ошибок в Agent Status и OMS Alerts
Если эти пункты проходят, можно переходить к дашбордам и типовым алертам.
Сбор метрик: минимум, который реально помогает
На старте важнее не собрать все подряд, а выбрать метрики, которые быстро отвечают на три вопроса: система жива, где узкое место, что меняется со временем.
В первую неделю держите фокус на доступности, нагрузке и задержках I/O. Это покрывает большинство инцидентов, которые реально мешают пользователям.
База данных: что смотреть сразу
Начните с метрик, которые почти всегда дают понятную картину:
- доступность инстанса и время отклика (включая задержки по ожиданиям)
- активные сессии и всплески ожиданий (блокировки, I/O, CPU)
- табличные пространства (процент заполнения и скорость роста)
- архивлоги и FRA (заполнение, скорость генерации, риск остановки из-за места)
- ошибки и критические события в alert log (как индикатор, что что-то пошло не так)
Если пользователи жалуются на "тормоза", обычно хватает связки Active Sessions + Top Waits + I/O latency. Она быстро показывает, это CPU, диски, блокировки или "шторм" запросов.
Хост и middleware: без этого картина неполная
По хосту минимум такой: CPU (включая load average), память, swap, заполнение файловых систем, сеть (ошибки и перегруз). Нередко проблема выглядит "как база", а на деле это закончилась память, начался swap или заполнился раздел под архивлоги.
Для middleware полезны метрики, напрямую связанные с деградацией сервиса: JVM heap и частота GC, пул потоков, пул соединений datasource, число ошибок приложения. Типовой пример: растет heap, учащается GC, очередь потоков увеличивается, а база при этом "чистая".
Частота сбора: чтобы не перегрузить и не пропустить
Для ключевых метрик производительности ставьте сбор раз в 1-5 минут, для емкости (диски, табличные пространства) - раз в 5-15 минут. Для событий и ошибок лучше опираться на пороги и событийные проверки, а не пытаться "чаще опрашивать" все подряд. Начните с умеренных интервалов и ускоряйте сбор только там, где вы реально ловите короткие пики.
Типовые дашборды для эксплуатации: 4 экрана без перегруза
Дашборд в эксплуатации нужен не для красоты, а чтобы за 30 секунд понять: все ли в порядке и где копать. Удобно сделать 4 простых экрана и держать их одинаковыми на всех средах.
Принцип простой: меньше виджетов, больше сигналов. На каждом экране оставляйте 6-10 показателей, задайте понятные пороги (желтый - скоро плохо, красный - уже плохо) и показывайте данные за последний час и за сутки.
Набор, который обычно закрывает 80% дежурных вопросов:
- Экран дежурного: красные цели, последние критичные события, доступность хостов и БД, очередь заданий, статус загрузок агентов.
- Экран производительности БД: топ ожиданий, загрузка CPU, Active Sessions, медленные SQL, блокировки и длительные транзакции.
- Экран емкости: рост табличных пространств, заполнение FRA, свободное место на файловых системах, тренд на 7-30 дней.
- Экран middleware: здоровье JVM (heap, GC), состояние managed servers, пулы подключений и источники данных, частые ошибки приложения.
Чтобы дашборды работали в смене, добавьте простой прием: рядом с метрикой показывайте "что проверить дальше". Например, при росте Active Sessions сразу должно быть видно, есть ли блокировки и какие SQL в топе.
В проектах системной интеграции (например, в госсекторе или банке) это особенно помогает: дежурный видит симптом, а инженер сразу получает направление, не тратя время на ручной сбор показаний из разных утилит.
Типовые алерты для старта: что включить сразу
На старте важнее всего включить алерты, которые ловят простои и "тихие" проблемы, пока они не стали инцидентом. Остальное добавите позже, когда появится статистика.
Базовый набор, который почти всегда полезен:
- Доступность: Target Down, Agent Down, потеря связи (нет данных от цели).
- Емкость Oracle Database: tablespace почти заполнен, быстрое заполнение FRA, аномальный рост архивлогов.
- Производительность: насыщение CPU, резкий рост DB Time, скачок активных сессий.
- Бэкапы и задания: нет успешного RMAN backup за заданный период, ошибки у критичных job-ов.
- Middleware: JVM heap близко к лимиту, ошибки datasource, stuck threads.
Пороговые значения лучше ставить мягко, чтобы не получить лавину уведомлений в первый же день. Например, для tablespace можно начать с предупреждения на 85% и критики на 95%. Для FRA полезно смотреть не только на процент, но и на скорость роста: если место уходит за часы, алерт нужен даже при 70-80%.
Чтобы алерты были полезными, придерживайтесь простых правил:
- Сначала включайте критичное, предупреждения добавляйте постепенно.
- Используйте задержку (например, 5-10 минут), чтобы отсечь короткие всплески.
- Делайте разные пороги для prod и test.
- Группируйте одинаковые цели шаблонами, чтобы не настраивать вручную каждую.
- Проверьте алерт "вживую" (искусственно создайте ситуацию) и поправьте пороги.
Практичный сценарий: ночью выросли архивлоги, FRA заполнилась, и БД остановилась бы при следующей записи. С правильными алертами вы увидите раннее предупреждение по росту архивлогов и заполнению FRA и успеете расширить место или ускорить очистку, не доводя до простоя.
Для крупных сред (гос, финансы, здравоохранение) такой набор обычно дает максимум эффекта при минимальной настройке и становится основой для дальнейшего развития мониторинга.
Уведомления и эскалации: чтобы алерты доходили до нужных людей
Мониторинг не дает пользы, если алерты остаются в консоли. На старте лучше выбрать один надежный канал и простую схему эскалации, чем пытаться настроить все сразу.
Самый понятный минимум - email. Настройте отправителя, проверьте, что письма доходят во внешние домены, и добавьте запасной адрес (общий ящик дежурных). Эскалацию по времени делайте прямолинейно: если алерт не подтвержден за 10-15 минут, он уходит следующей группе.
Получателей лучше разделить по ролям:
- дежурные 24/7 (первый уровень)
- DBA (Oracle Database)
- middleware (WebLogic и сопутствующее)
- инфраструктура (ОС, сеть, хранилище)
Дальше включите защиту от спама: окна обслуживания и подавление повторов. Для повторов удобно правило "один алерт - одно письмо", а обновления отправлять только при смене статуса или резком ухудшении.
Текст письма должен помогать действовать. Минимум, который ускоряет реакцию:
- что сломалось: цель и тип (хост, БД, middleware)
- насколько критично: severity и влияние
- когда началось: время и длительность
- ключевая метрика и превышенный порог
- что проверить первым: короткая подсказка (listener, место в tablespace, health check managed server)
Если ночью заканчивается место в FRA, дежурный получит понятное письмо, подтвердит инцидент, а через 15 минут при отсутствии прогресса OEM автоматически подключит DBA. Это быстрее и надежнее, чем ручные пересылки и звонки "по памяти".
Пример из жизни: один инцидент и как OEM помогает разобрать его быстро
Ночь, 02:40. Дежурному приходит предупреждение: на сервере базы быстро растет занятое место в FRA (Fast Recovery Area). Через несколько минут подтягивается второе: архивлоги генерируются быстрее обычного. Третий сигнал показывает, что ночной бэкап не завершился. Без мониторинга это часто выглядит как "закончился диск", но в OEM цепочка собирается в одно понятное событие.
Сначала срабатывает алерт по использованию FRA (например, 85% - warning, 95% - critical). Затем видно ускорение генерации archived redo log (лог-свитчи участились). Параллельно в статусе RMAN Job видно, что бэкап упал или завис, а значит архивлоги не удаляются по политике retention. Через 10-15 минут база уже близко к остановке из-за нехватки места.
Дежурный открывает два экрана: сводный дашборд по базе (состояние, нагрузка, ошибки) и Storage/FRA. По графику FRA видно резкое "пилообразное" заполнение, а в разделе Job Activity - последний сбойный бэкап и код ошибки. Это быстро подтверждает первопричину: не "вдруг стало больше данных", а "архивлоги копятся, потому что бэкап не забирает их".
Дальше обычно есть два типа действий. Временное решение - освободить место (расширить FRA или файловую систему, перенести часть архивлогов на временное хранилище, перезапустить упавший RMAN job). Постоянное исправление - устранить причину сбоя бэкапа (доступ к бэкап-репозиторию, лимиты, ошибка канала), добавить алерт на "RMAN job failed" и порог по "FRA projected full in N hours", чтобы предупреждение приходило раньше, чем при 95%.
Этот сценарий хорошо показывает ценность запуска OEM с минимальным набором метрик и типовыми алертами: дежурный видит не только симптом, но и понятную последовательность причин.
Типовые ошибки при внедрении OEM и как их избежать
Чаще всего разочарование связано не с OEM, а с настройками "на всякий случай". Сначала добейтесь понятных сигналов, а уже потом расширяйте охват.
Первая ошибка - слишком низкие пороги. Когда алерт срабатывает от каждого короткого всплеска CPU или пары медленных запросов, команда быстро перестает реагировать. Начните с порогов, которые ловят риск простоя: заполнение файловых систем, FRA и табличных пространств, недоступность listener, рост очередей, ошибки бэкапа. Более чувствительные правила добавляйте после недели наблюдений.
Вторая ошибка - включить все метрики и коллекции сразу. Это перегружает OMS и репозиторий, а в интерфейсе появляется "шум". Лучше включить минимум и сделать один понятный дашборд, чем собрать все подряд и не смотреть ничего.
Третья ошибка - одни учетные данные "на всех" и отсутствие ролей. В итоге сложно безопасно делегировать работу: DBA, админы middleware и поддержка начинают мешать друг другу. Разделите доступ по целям и заведите отдельные named credentials для разных сред (prod, test) и задач.
Четвертая ошибка - недооценить рост репозитория. Данные накапливаются быстро, и место заканчивается внезапно. Заранее задайте политику хранения, контролируйте рост и оставьте запас по диску.
Пятая ошибка - разное время на хостах. Итог: "прыгающие" графики и алерты без логики. Быстрая проверка перед запуском:
- синхронизация времени на OMS, репозитории и целях
- корректный часовой пояс
- единые настройки NTP
- проверка задержек сети до агентов
- тест уведомлений на пилотной группе
Короткий чеклист: готовность мониторинга к эксплуатации
Перед тем как сказать "мониторинг запущен", полезно сделать короткую проверку, чтобы OEM не превратился в красивую витрину.
Сначала проверьте качество данных. Если агент периодически отваливается, все остальное теряет смысл. Ориентир для старта: свежесть данных по ключевым целям (хост, БД, middleware) не старше 10-15 минут и нет "серых" целей в статусе Unknown.
Что должно быть готово к первой эксплуатации:
- все агенты и цели в статусе Up, задержка сбора метрик укладывается в выбранный порог (например, до 15 минут)
- есть один "экран дежурного" и набор примерно из 10-15 алертов, которые вы реально готовы обрабатывать
- видны бэкап-джобы, настроено уведомление о любой ошибке бэкапа (или пропуске по расписанию)
- цели собраны в понятные группы (по сервисам или окружениям), включены базовые роли доступа
- есть простой план роста: когда добавится еще N БД или серверов, что увеличиваем в OMS и репозитории (CPU, память, место, обслуживание)
Если по каждому пункту можно ответить "да" без оговорок, OEM уже помогает, а не просто установлен. Следующий шаг обычно один: по итогам 1-2 недель убрать шумные алерты и уточнить пороги под вашу нагрузку.
Следующие шаги после быстрого старта
После первых метрик и алертов не стоит надолго оставаться на настройках "по умолчанию". В первые недели OEM показывает реальную картину, и пороги лучше подогнать под окна бэкапов, ночные батчи и особенности middleware.
План на ближайшие 30 дней
Короткий план, который помогает превратить мониторинг из "экрана" в рабочий инструмент:
- уточнить пороги: отделить ожидаемые пики от настоящих проблем
- добавить емкостное планирование: тренды по CPU, памяти, дискам, росту данных и архивлогов
- настроить регулярные отчеты: недельный для эксплуатации и месячный для руководителя
- разобрать топ-10 событий за неделю и убрать лишнее, оставив важное
- проверить, что по каждому алерту понятен владелец и первое действие
Если мониторинг запущен на минимальной архитектуре (все на одном сервере), обычно пора думать о разнесении ролей, когда целей становится много, растет частота сборов, появляются тяжелые отчеты или важна доступность 24/7. Практичный признак: вам неудобно обслуживать сам OEM без потери наблюдаемости.
Как "подружить" OEM с эксплуатацией
Договоритесь о простых правилах: какие алерты требуют реакции в смене, какие можно закрывать по регламенту, и в каком виде фиксировать постмортем (что случилось, как нашли, как предотвратить). Тогда OEM становится частью процесса, а не отдельной системой.
Если удобнее начать с пилота и параллельно подобрать железо, размещение и план внедрения, это можно сделать вместе с GSE.kz как системным интегратором - особенно когда нужно сразу учесть требования по поддержке и дальнейшему росту.
FAQ
Какая минимальная цель мониторинга на первые 1–2 дня внедрения OEM?
Для быстрого старта достаточно, чтобы мониторинг стабильно отвечал на четыре вопроса: доступность хостов/БД/middleware, базовая производительность, емкость (диски, tablespace, FRA) и бэкапы RMAN. Если эти вещи под контролем, вы закрываете большую часть типовых инцидентов без долгой настройки.
Из каких компонентов состоит минимальная архитектура OEM?
В минимальной схеме нужны три роли: OMS как центральный сервер и консоль, база данных под Management Repository для хранения метрик и событий, и OEM Agent на каждом хосте, где есть Oracle Database или middleware. С этого набора можно сразу подключать цели и включать типовые алерты.
Где лучше размещать OMS и Repository: вместе или раздельно?
Самый практичный вариант на старте — разнести OMS и Repository на разные виртуальные машины или серверы, чтобы проще было обслуживать и чтобы нагрузка дисков репозитория не «топила» консоль. Ставить всё на один узел имеет смысл только при совсем небольшом числе целей и понимании, что придется быстрее масштабироваться.
Что чаще всего делает OEM нестабильным и что проверить заранее?
Чаще всего проблемы начинаются из-за медленного хранилища репозитория и нестабильной сети между агентами, OMS и Repository. Сразу проверьте IOPS для дисков Repository, DNS и обратное разрешение имен, синхронизацию времени (NTP) и запас места под рост истории и логов.
Как прикинуть ресурсы OEM на старте и от чего зависит размер?
Оценка упирается в количество целей в ближайшие 2–4 недели: хосты, экземпляры БД, listeners/ASM, домены WebLogic и ключевые компоненты middleware. Для старта уровня до десятков целей обычно хватает 4 vCPU и 16 ГБ RAM для OMS/узла управления, но «комфорт» чаще дает запас по памяти и особенно по дискам под Repository.
В каком порядке подключать цели: хост, база и middleware?
Сначала установите агент и добейтесь, чтобы хост появился как Target со статусом Up и свежей загрузкой данных. Затем добавляйте Oracle Database (проверив доступность listener и учетные данные), и только после этого подключайте middleware, чтобы не искать проблему одновременно в сети, агенте и доступах приложения.
Какие метрики Oracle Database стоит включить в первую неделю?
Начните с доступности и нескольких «сигнальных» метрик: Active Sessions и ожидания, I/O latency, рост табличных пространств, заполнение и скорость роста FRA, а также ошибки в alert log. Этого обычно хватает, чтобы быстро понять, это CPU, диски, блокировки или аномальная нагрузка запросами.
Какие базовые метрики нужны для хоста и WebLogic, чтобы видеть картину целиком?
По хосту минимум — CPU и load average, память и swap, заполнение файловых систем и базовые сетевые ошибки. Для middleware чаще всего полезнее всего JVM heap и частота GC, состояние managed servers, пулы соединений datasource и признаки stuck threads, потому что деградация сервиса нередко начинается на уровне JVM, а не базы.
Какие типовые алерты стоит включить сразу и как не утонуть в шуме?
На старте включайте алерты, которые предупреждают простой и «тихие» накопительные проблемы: Target/Agent Down, заполнение файловых систем, tablespace и FRA, отсутствие успешного RMAN-бэкапа, резкий рост DB Time или активных сессий, а для middleware — проблемы heap и datasource. Пороги лучше ставить мягко и с задержкой 5–10 минут, чтобы не получить лавину уведомлений.
Как настроить уведомления и эскалации, чтобы алерты реально доходили?
Сделайте один надежный канал (обычно email), настройте рабочие часы и окна обслуживания и простую эскалацию по времени, если алерт не подтвержден. В тексте уведомления держите только то, что помогает действовать: что сломалось, когда началось, какая метрика вышла за порог и что проверить первым, иначе письмо не ускоряет реакцию.