Аудит действий пользователей: как устроить надежный лог событий
Аудит действий пользователей помогает расследовать инциденты: как описать события, защитить логи от правок, настроить ретеншн и быстрый поиск.
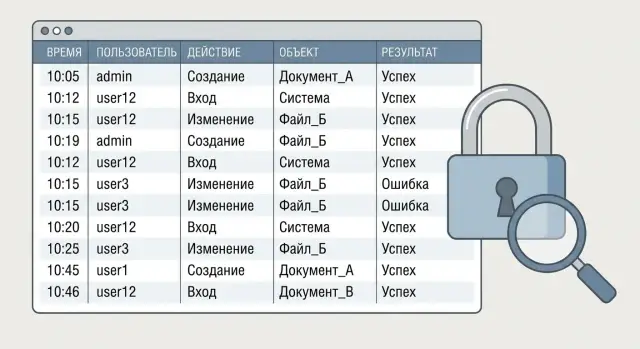
Зачем нужен аудит действий и какие задачи он решает
Аудит действий пользователей нужен не ради галочки. Он помогает быстро отвечать на вопросы, которые возникают при проверках, спорных ситуациях и инцидентах: кто сделал действие, что изменилось, когда это произошло, откуда был доступ и чем все закончилось.
Важно не путать аудит с техническими логами и мониторингом. Технические логи показывают, что происходило с компонентами системы (ошибки сервисов, падение базы, задержки запросов). Мониторинг показывает состояние прямо сейчас (нагрузка, доступность). А журнал аудита фиксирует значимые для бизнеса действия людей и сервисных учетных записей: вход, изменение прав, создание или удаление записи, выгрузку данных, запуск отчета, подтверждение операции.
Хороший аудит закрывает практические задачи: расследования (восстановить цепочку и первопричину), контроль доступа (кто выдавал права и когда их повышали), комплаенс (подтвердить соблюдение процедур), разбор ошибок (баг, процесс или человеческий фактор), снижение рисков (заметить нетипичные действия и подозрительные шаблоны).
Пример из жизни: сотрудник утверждает, что не менял реквизиты контрагента, но платеж ушел не туда. Технические логи покажут, что запрос к базе прошел успешно. А аудит должен показать конкретное действие: какой пользователь открыл карточку, какие поля изменил, с какого устройства или IP, в какое время, и была ли операция сохранена или отменена.
На практике аудит чаще всего используют команды ИБ, комплаенс, внутренний контроль и владельцы бизнес-систем. Им нужна не лента «шума», а понятная история действий, которую можно быстро найти, объяснить и приложить к отчету.
Структура событий: из чего состоит хороший словарь аудита
Чтобы аудит помогал в расследованиях, сначала договоритесь, что именно вы называете событием. В бизнес-системе событие - это действие, которое влияет на данные, права или риск: вход, просмотр карточки, изменение реквизитов, экспорт, удаление, выдача или отзыв прав. Если действие не отвечает ни на один из этих вопросов, часто его можно не логировать.
Дальше нужен словарь событий (каталог) - небольшой документ или таблица, где каждое событие описано одинаково. Он помогает разработчикам писать записи единообразно, а службе безопасности и внутреннему контролю - быстро понимать, что произошло.
Обычно для каждого события фиксируют: название и короткое описание, категорию (доступ, данные, права, отчеты), критичность и смысл (зачем событие нужно), ожидаемые поля (что обязательно, что опционально), примечания по приватности (есть ли персональные данные и как их маскировать).
Отделяйте бизнес-события от системных. Бизнес-события отвечают на вопрос «что сделал пользователь»: открыл договор, изменил сумму, выгрузил отчет. Системные - «что сделала платформа»: фоновая синхронизация, плановая очистка кеша, перезапуск сервиса. Если смешать их в одном потоке без фильтров, журнал станет нечитаемым, и нужные действия утонут в шуме.
Для именования удобно использовать единый шаблон, чтобы события сортировались и искались предсказуемо: entity.action или domain.entity.action (user.login, contract.update, report.export). Добавьте версию события, потому что формат и смысл со временем меняются: contract.update.v1. Это сильно помогает, когда через год вы сравниваете записи из разных релизов.
Простой тест качества: откройте журнал и попробуйте без контекста восстановить, что произошло. Если это легко, аудит будет полезен в реальных проверках, а не только «для отчета».
Поля в записи аудита: минимум, который спасает расследование
Хорошая запись аудита должна отвечать на три вопроса: кто сделал, что сделал и с каким результатом. Если хотя бы одного элемента нет, расследование превращается в догадки, а проверка идет дольше. При этом лог не должен превращаться в свалку: лучше стабильный минимум, чем десятки полей без смысла.
Для большинства бизнес-систем базовый набор такой:
- время события (с часовым поясом) и источник времени (сервер/клиент);
- субъект: пользователь (user_id), роль на момент действия, способ входа (например, SSO);
- действие: понятный код операции (create/update/delete/export/login и т.п.);
- объект: тип сущности, object_id и человекочитаемое имя на момент события;
- результат: успех/отказ, код статуса и краткая причина.
Контекст часто решает спорные ситуации. Добавляйте подразделение или филиал, рабочее место (например, kiosk-01), приложение или модуль, IP и тип устройства, а также признак «интерактивно» или «через API». Так проще отличать действия оператора от фоновой интеграции и быстрее находить источник ошибки.
Чтобы склеивать цепочки действий, нужны идентификаторы. В идеале у каждого события есть request_id, а для длинных сценариев еще session_id и correlation_id. Тогда восстанавливается история целиком: вход пользователя, открытие карточки, изменение, попытка экспорта, отказ, повторная попытка. Это особенно полезно в сложных средах, когда к одной системе ходят разные приложения.
Про объект храните не только ID. Название, номер договора или ФИО на момент события экономят часы: записи живут дольше данных, а «текущие» поля могли поменяться.
Причину отказа логируйте аккуратно: пишите код (POLICY_DENY, INVALID_ROLE, MFA_REQUIRED) и короткую фразу без секретов. Не сохраняйте пароли, токены, полные номера документов, содержимое полей и «сырые» SQL-ошибки. В аудите важнее понять логику запрета, чем увидеть чувствительные детали.
События про данные и права: что важно для проверок
Проверки почти всегда упираются в два вопроса: кто трогал данные и кто мог это сделать. Поэтому в словаре аудита отдельно продумайте события про данные (чтение, изменение, выгрузка) и события про права (роли, привилегии, админ-обходы). Такой журнал быстро отвечает на вопрос: ошибка, злоупотребление или нормальная операция.
Для изменений данных важно фиксировать не только факт, но и смысл. Идеально, когда запись хранит «было» и «стало» для небольших полей. Для крупных объектов (договор, анкета, документ) лучше писать ссылку на дифф или идентификатор версии. Так журнал остается «легким», а цепочку можно восстановить точно.
Иногда значения писать нельзя: персональные данные, номера карт, медданные, секреты. Тогда используйте маскирование (например, последние 4 символа), хеширование для сравнения «одинаково или нет», или токены (идентификатор значения в защищенном хранилище). Цель простая: должно быть понятно, что изменилось, без раскрытия лишнего.
Отдельно логируйте доступ к данным. Просмотр карточки не менее важен, чем изменение, если речь о чувствительной информации. Также фиксируйте печать, экспорт и массовые операции: один клик может унести тысячи записей.
Минимальный набор событий, который чаще всего нужен аудиторам:
- просмотр записи и вложений (с указанием объекта);
- выгрузка/экспорт/печать (с количеством строк и фильтрами);
- массовые изменения (с параметрами операции);
- выдача/снятие роли, смена прав, добавление в группу;
- включение админ-режимов и обходов (если они есть).
Частый провал - время. Выберите единый часовой пояс (обычно UTC), синхронизируйте серверы, пишите точность хотя бы до миллисекунд и добавьте монотонный номер события. Тогда при споре «кто раньше» порядок восстановится даже при параллельных запросах.
Неизменяемость аудита: как защитить журнал от правок
Если журнал можно тихо подправить, он перестает быть доказательством. Для расследований и проверок важно, чтобы записи появлялись только в одном направлении: добавились и остались.
Append-only и разделение ролей
Принцип простой: события нельзя редактировать и удалять, можно только дописывать новые. На практике это достигается не только настройкой хранилища, но и разделением прав. Тот, кто генерирует события (приложение), не должен администрировать хранение. А администратор хранения не должен иметь возможности «подчищать» следы незаметно.
Полезно заранее закрепить роли:
- приложение пишет события, но не читает и не управляет политиками хранения;
- служба безопасности и аудиторы читают и ищут, но не могут менять данные;
- администраторы управляют ресурсами и доступом, но их действия тоже логируются;
- для критичных операций действует двухконтроль: две независимые роли подтверждают действие.
Технические и организационные меры
Технические меры должны усложнять любую незаметную правку. Обычно используют контроль целостности: цепочки хешей (каждая запись содержит хеш предыдущей), цифровую подпись пакетов событий, неизменяемые сегменты хранения (например, «закрытые» файлы или объекты с запретом перезаписи) и строгий контроль доступа. Обязательно логируйте админ-действия: изменение политик, ротации, ключей подписи, прав доступа.
Организационная часть не менее важна. Нужен регламент: кто и как запрашивает выгрузки, кто согласует доступ, как оформляется исключение, как долго хранится ключ подписи, как проверяется целостность. Хорошая практика - периодические проверки: берутся выборки событий, сверяются подписи и цепочки хешей, результаты фиксируются.
Что делать, если запись лога ломается
Ошибка записи не должна останавливать бизнес-процесс, но и терять события нельзя. Обычно помогают асинхронная запись и буфер: приложение кладет событие в очередь, а отдельный компонент доставляет его в хранилище. Если хранилище недоступно, события временно копятся локально с лимитом и тревогой для админов.
Например, при оформлении закупки в госоргане система продолжает работать, но поднимает оповещение и помечает операции как требующие проверки, пока журнал не догонит реальность.
Ретеншн и хранение: сколько держать логи и где это дешевле
Ретеншн лучше начинать не с цифры в годах, а с целей. Для расследований и проверок важны критичные события (входы, смена прав, операции с деньгами, изменение ключевых данных), а для отладки - вспомогательные (технические метрики, подробные трассировки). Держать все одинаково долго дорого и обычно не нужно.
Практичный подход - задать сроки по классам событий. Например: критичные - 1-3 года, важные - 3-12 месяцев, вспомогательные - 7-30 дней. Дальше свериться с требованиями отрасли и внутренними регламентами. Особенно аккуратно с персональными данными: храните только то, что нужно для контроля и безопасности, и не дублируйте чувствительные поля без причины.
По стоимости почти всегда выигрывает многоуровневое хранение. Оно обычно делится на горячий слой (быстрый поиск по свежим инцидентам), теплый (регулярные проверки, но дешевле), холодный (архив на годы) и резервные копии, которые хранятся отдельно от основного хранилища.
План очистки должен быть таким же формальным, как и план хранения. Нужны сроки, ответственные, подтверждение удаления и отчетность. И обязательно исключение: если начато расследование, связанные записи ставятся на hold и не удаляются до закрытия кейса.
Чтобы не ошибиться с объемами, считайте заранее и закладывайте пики: событий в день по типам (включая массовые операции), средний размер записи (с учетом контекста), рост пользователей и интеграций на 6-12 месяцев вперед, пиковые дни (закрытие месяца, миграции, кампании), доля данных в горячем слое.
Пример: в организации с жесткими требованиями комплаенса (банк, госструктура, клиника на собственной инфраструктуре, например на серверах в стойке) логи доступа и прав держат дольше, а подробные технические события - коротко, чтобы не раздувать архив и не переплачивать за быстрый поиск.
Удобный поиск: как сделать аудит пригодным для расследований
Если по аудит-логам нельзя быстро ответить на вопрос «кто, что и когда сделал», то даже аккуратный формат событий не спасет. Для расследований важнее всего скорость и точность: находить нужные события за минуты, а не перелистывать миллионы строк.
Начните с индексов. Индексируйте не все подряд, а поля, по которым чаще всего фильтруют и сортируют. Обычно в первую очередь нужны пользователь (ID и отображаемое имя), объект (тип и ID), действие и результат (успех/ошибка, код причины), время события (с точностью до миллисекунд), корреляция (request_id или session_id).
Дальше продумайте сценарии поиска. Проверяющим редко нужен один лог, им нужна история: что было за 15 минут до инцидента и что произошло после. Поэтому полезны временные окна (например, -30/+60 минут), группировки по пользователю и объекту, а также «цепочки действий» по request_id: вход -> просмотр -> экспорт -> изменение прав.
Хороший интерфейс поиска поддерживает быстрые преднастройки и сохраненные запросы для типовых проверок: доступ к чувствительным данным, массовые выгрузки, изменения ролей, попытки входа с ошибками. Это снижает нагрузку на ИБ и внутренний контроль и делает проверки повторяемыми.
Экспорт результатов тоже должен быть управляемым. Разрешайте его только тем, кому это нужно по роли, и фиксируйте сам факт экспорта отдельным событием: кто экспортировал, какой запрос, какой диапазон времени, сколько строк, в каком формате. Для расследований удобно иметь один «пакет» (например, CSV/JSON) плюс метаданные запроса, чтобы потом воспроизвести выборку.
И последнее: разграничение доступа. Следователи должны видеть достаточно, чтобы разобраться, но не больше. На практике помогают раздельные права на просмотр событий, на просмотр значений чувствительных полей (с маскированием) и на экспорт. Так аудит усиливает безопасность, а не создает новые риски.
Как внедрить аудит шаг за шагом без перегруза системы
Чтобы аудит действий пользователей реально помогал в проверках, его лучше строить от практики, а не от принципа «логируем все подряд». Начните с 5-10 сценариев: расследование утечки, спор по доступу, проверка изменений в справочниках, инцидент с удалением данных. Из них выводится список событий и становится понятно, что вообще нужно видеть в журнале.
Дальше зафиксируйте единый формат записи: какие поля обязательны, как писать результат (успех, отказ, ошибка), где хранить идентификаторы объектов, как маскировать чувствительные данные. Например, в событиях про авторизацию или работу с персональными данными оставляйте идентификаторы и тип операции, но не сохраняйте «сырые» значения, если это не требуется для расследований.
Чтобы не перегрузить систему, внедряйте логирование точечно, в ключевых точках бизнес-процесса, и сразу добавляйте корреляцию запросов. Тогда цепочку действий можно собрать по одному request_id или trace_id, а не искать «похожие» записи по времени.
План, который обычно работает:
- выбрать минимальный набор событий для первого релиза под выбранные угрозы и проверки;
- утвердить словарь событий и правила маскирования, чтобы команды писали логи одинаково;
- включить аудит в критичных местах (вход, выдача прав, изменение данных) и добавить корреляционные идентификаторы;
- настроить хранение: ретеншн, резервные копии, раздельные права доступа, учет того, кто читает аудит;
- подготовить шаблоны запросов и простые дашборды для типовых проверок, затем коротко обучить поддержку и безопасность.
Не забывайте про регулярную проверку качества. Раз в спринт прогоняйте тестовые кейсы: «пользователь получил роль», «удалил запись», «попытался открыть запрещенный документ». По результатам видно, где журнал неполный, где не хватает контекста, и какие события дублируются.
Хороший признак зрелости: аудит можно использовать без разработчика на созвоне. Служба ИБ за 10 минут отвечает на вопрос: кто изменил права, что именно изменилось, и какие действия были до и после.
Пример расследования: как по аудиту восстановить цепочку действий
Ситуация: служба безопасности получает сигнал, что кто-то мог выгрузить клиентскую базу из CRM и передать файл наружу. Доказательств мало: один сотрудник говорит, что «ничего не делал», а в отчете нашли необычно свежую копию данных.
Начните не с человека, а с события. В нормальном журнале легко отфильтровать массовые выгрузки: экспорт в CSV/XLSX, запуск отчета с большим объемом строк, API-запросы на выдачу больших выборок, скачивание архива.
Как восстановить цепочку
Дальше задача - связать одно подозрительное действие с конкретной сессией и всем, что было до и после. Обычно цепочка выглядит так:
- вход в систему: кто вошел, с какого IP, устройства, по какому способу (пароль, SSO, токен);
- изменение прав: выдача роли, добавление в группу, снятие ограничений, временный доступ;
- доступ к разделу с клиентами: открытие списка, поиск, просмотр карточек, построение отчета;
- экспорт или выгрузка: формат, объем (число записей), фильтр, откуда выгружали;
- действия с файлом: скачивание, отправка в почту внутри системы, загрузка в хранилище, попытка поделиться.
Чтобы не гадать, важно, чтобы события имели одинаковые ключи связи: session_id, user_id, request_id (или correlation_id). Тогда вы собираете ленту в нужном окне времени и видите последовательность.
Признаки, которые чаще всего «выдают» инцидент: вход в необычное время, новый IP или город, новое устройство, внезапная роль «администратор», серия ошибок доступа прямо перед успехом (кто-то подбирал путь), экспорт с нетипичным фильтром (например, «все клиенты» вместо конкретного региона).
Оформляйте выводы так, чтобы их можно было перепроверить: список подтвержденных событий с точным временем, кто выполнил, какие данные затронуты (объем и тип), и какие факты подтверждают неизменяемость журналов. Отдельно фиксируйте, что не удалось доказать по логам, чтобы закрыть пробелы в аудите.
Частые ошибки, из-за которых аудит не помогает
Самая обидная ситуация случается не из-за отсутствия логов, а из-за того, что они не подходят для проверки. В момент инцидента выясняется: события есть, но связать их нельзя, доверять им нельзя, а искать нужное долго.
Частая ошибка - логировать только успешные операции. Тогда пропадают попытки входа, отказы по правам, ошибки валидации и отмененные действия. А именно они показывают намерение и путь: кто пробовал открыть запись, кто подбирал пароль, кто пытался выдать себе доступ.
Вторая проблема - нет стабильных идентификаторов объектов. Если в событиях то «договор №12», то «Contract-12», то просто название файла, цепочка распадается. Нужны постоянные ID (пользователя, роли, документа, записи) и единый формат.
Третья - смешивать аудит и отладочные логи. Когда в одном потоке лежат «User updated role» и «DEBUG: cache miss», поиск превращается в хаос.
Опасная ошибка - писать чувствительные данные целиком: пароли, токены, полные номера документов, медицинские данные. Аудит не должен становиться новой точкой утечки. Лучше хранить маску, хеш или ссылку на объект через ID.
Если у администратора есть право править записи, доверие к журналу пропадает. Для проверок важна неизменяемость: дописывать можно, переписывать нельзя, и должно быть видно, кто и как получил доступ к самим логам.
Наконец, ретеншн часто ставят наугад. В итоге или хранилище переполняется, или не хватает данных для внутренней проверки и требований регулятора.
Короткая самопроверка:
- есть ли в журнале и успешные действия, и попытки с отказами;
- есть ли стабильные ID объектов и корреляционный ID сессии/запроса;
- отделен ли аудит от технических и отладочных логов;
- не попадают ли в события секреты и лишние персональные данные;
- можно ли изменить или удалить записи без следа.
Пример: сотрудник пытался выгрузить список клиентов, получил отказ, затем запросил роль у коллеги и повторил попытку. Если вы не логируете отказы, смену прав и стабильные ID, цепочка распадется, и журнал не даст ответа, что именно произошло.
Чеклист перед запуском и следующие шаги
Перед запуском аудита полезно сделать несколько быстрых проверок. Это дешевле, чем потом выяснять на расследовании, что половина событий не пишется, а нужное поле оказалось пустым.
Проверьте по минимуму:
- события: входы, изменения прав, операции с данными (создание, изменение, удаление, экспорт), критичные настройки;
- обязательные поля: кто сделал, когда, где (система/модуль), что именно изменил, результат;
- маскирование: пароли, токены, полные номера документов и персональные данные не должны попадать в лог целиком;
- неизменяемость: доступ на запись отделен от доступа на чтение, есть контроль целостности (хеши/подписи), админ-действия тоже логируются;
- поиск: индексы по ключевым полям, готовые шаблоны запросов для типовых проверок, разграничение ролей на просмотр и экспорт.
Отдельно прогоните ретеншн на практике, а не на бумаге. Важно не только «сколько дней храним», но и как вы поднимете архив за нужный период, сколько это займет времени и кто имеет право сделать исключение для расследования.
Если аудит уже пишется, следующий шаг - сделать его удобным в работе: чтобы безопасность, ИТ и внутренний контроль могли быстро находить цепочки событий и подтверждать целостность данных.
План на ближайшие 2-4 недели:
- оценить нагрузку: сколько событий в сутки, пики, сколько места нужно с учетом ретеншна и индексов;
- выбрать схему хранения: горячее (для поиска) и холодное (архив), плюс регулярные проверки восстановления;
- описать роли и доступы: кто может смотреть, кто может выгружать, кто утверждает запросы на расследование;
- сделать 5-10 «боевых» сценариев поиска и оформить их как стандартные запросы для проверок;
- если не хватает ресурсов, подключить интегратора.
Если под аудит нужен надежный контур хранения и вычислений (например, для быстрого поиска по индексам, долгого ретеншна и выделенных ролей доступа), часто упираются в инфраструктуру. В таких проектах может быть полезен опыт GSE.kz (gse.kz) как производителя серверов и системного интегратора: от подбора серверов и хранилищ до внедрения и дальнейшей поддержки 24/7.
FAQ
Чем аудит действий отличается от технических логов и мониторинга?
Аудит фиксирует значимые для бизнеса действия людей и сервисных учетных записей: вход, изменение прав, операции с данными, экспорт, подтверждение операций. Технические логи описывают работу компонентов (ошибки сервисов, задержки, падения), а мониторинг показывает состояние системы «сейчас» (нагрузка, доступность).
Какие поля в записи аудита обязательны, чтобы потом можно было расследовать инцидент?
Ставьте цель: чтобы по одной записи было понятно, **кто** сделал, **что** сделал и **чем закончилось**. Минимум обычно включает время с часовым поясом, идентификатор пользователя и его роль на момент действия, код операции, тип и `object_id` объекта, а также результат (успех/отказ) с краткой причиной без секретов.
Как правильно именовать события и зачем нужна версия события?
Удобнее всего использовать единый шаблон, например `entity.action` или `domain.entity.action`, чтобы события легко сортировались и искались: `user.login`, `contract.update`. Добавляйте версию, например `contract.update.v1`, чтобы изменения формата со временем не ломали анализ и сравнение записей из разных релизов.
Какой контекст стоит добавлять в аудит, кроме пользователя и объекта?
Логируйте контекст, который помогает отличать человека от интеграции и быстро локализовать источник: приложение/модуль, IP, тип устройства, признак «интерактивно» или «через API», филиал/подразделение, рабочее место. Это часто решает спорные ситуации, когда нужно понять, откуда именно было действие и почему оно выглядит нетипично.
Нужно ли логировать отказы и неуспешные попытки действий?
Пишите не только успешные действия, но и попытки с отказами: неверные права, требования MFA, запреты политиками, ошибки валидации, отмененные операции. Именно отказы показывают намерение и путь к результату, а без них цепочка событий выглядит «чистой» и не объясняет, как пользователь дошел до критичного действия.
Как логировать изменения данных, если значения содержат персональные или секретные сведения?
По умолчанию не сохраняйте в аудит пароли, токены, полные номера документов, медицинские данные и другие чувствительные значения. Если нужно понимать факт изменения, используйте маскирование (например, последние символы), хеш для сравнения «изменилось/не изменилось» или храните только идентификатор значения, чтобы не превращать аудит в новую точку утечки.
Как обеспечить неизменяемость аудита, чтобы ему доверяли на проверках?
Делайте журнал «append-only»: записи можно только добавлять, но нельзя тихо править или удалять. Усильте это разделением прав (приложение пишет, аудиторы читают, администраторы управляют инфраструктурой, но их действия тоже логируются) и контролем целостности, например цепочками хешей и/или подписью пакетов событий.
Как выбрать ретеншн: сколько хранить аудит и что делать при расследовании?
Не начинайте с одной цифры «на все»: задайте сроки по классам событий и целям. Критичные события (входы, права, деньги, ключевые данные) обычно хранят дольше, вспомогательные — меньше, чтобы не переплачивать за объем и быстрый поиск. Важно также иметь правило hold: если начато расследование, связанные записи не удаляются до закрытия кейса.
Как настроить поиск по аудит-логам, чтобы находить цепочки событий за минуты?
Сделайте поиск ориентированным на типовые вопросы: «кто трогал объект», «кто выдавал права», «кто экспортировал данные», «что было за 30 минут до инцидента». Для этого индексируйте поля, по которым реально фильтруют: `user_id`, объект и `object_id`, действие, результат, время, а также `session_id`/`request_id`/`correlation_id`, чтобы собирать цепочки действий в одну историю.
Как внедрить аудит по шагам и не перегрузить систему?
Начните с 5–10 самых важных сценариев проверок и инцидентов и под них утвердите словарь событий и единый формат записи. Логируйте в ключевых точках бизнес-процесса и сразу добавляйте корреляционные идентификаторы, а запись делайте асинхронной через очередь/буфер, чтобы не тормозить основную транзакцию. Если проект упирается в инфраструктуру хранения и быстрый поиск, такие контуры часто делают вместе с системным интегратором, например на базе серверов и хранилищ уровня предприятия от GSE.kz.