API management для госинтеграций: Kong, Apigee, Azure, Tyk
API management для госинтеграций: как сравнить Kong, Apigee, Azure API Management и Tyk по лимитам, ключам, аудиту, версиям, порталу и отказам.
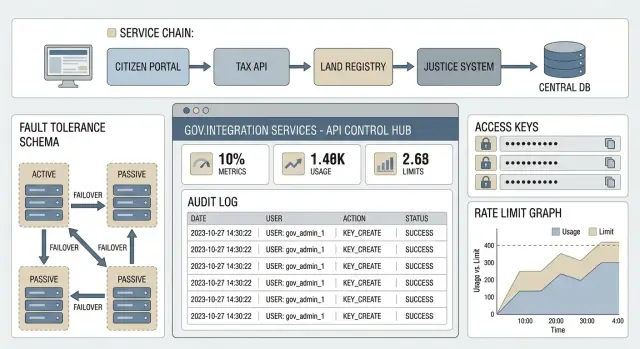
Зачем госинтеграциям отдельный слой API-управления
В межведомственных интеграциях ломается не сама идея API, а «мелочи» вокруг нее. Один потребитель начинает вызывать метод в 10 раз чаще из-за ошибки в расписании, другой присылает нестандартные заголовки, третий забывает обновить сертификат. В итоге страдают все: очередь растет, сервис отвечает медленно, а виноватым выглядит владелец API.
Отдельный слой API management нужен, чтобы ловить такие проблемы заранее и гасить их до уровня инцидента. Он становится единым входом: контролирует доступ, ограничивает нагрузку, фиксирует, кто и что вызывал, и помогает выпускать изменения без хаоса.
WAF или обычный прокси ключевые задачи не закрывают. WAF хорошо отсекает типовые атаки, но обычно не решает вопросы контрактов API: квоты по ключам, разные правила для разных потребителей, публикация документации, управление версиями, единая политика ошибок. Прокси может «пробросить» запросы, но без централизованных правил быстро превращается в набор ручных исключений.
Почти всегда есть три стороны: владелец API (ведомство или оператор реестра), потребители (другие ведомства, ЦОН, подрядчики, интеграторы) и оператор инфраструктуры (ЦОД, облако, интеграционный контур). Каждой стороне нужно свое: владельцу - контроль и прозрачность, потребителям - понятный доступ и стабильные правила, оператору - управляемость и прогнозируемая нагрузка.
Обычно регламенты и аудит требуют простых, но жестких вещей: идентификации каждого потребителя (ключи, сертификаты, роли) без «общих» учеток; лимитов и квот, чтобы один клиент не уронил сервис для остальных; журналирования вызовов и действий администраторов с хранением и поиском по инцидентам; управления версиями и плановой замены старых методов без остановки услуг; понятной процедуры выдачи доступа и единого источника документации.
Пример: ведомство открывает API к реестру для пяти систем. Без слоя управления вы договариваетесь о лимитах в письмах и разбираете инциденты «по логам приложения». С API management правила становятся явными и проверяемыми: кто вызывал, сколько, по какой версии, и что произошло при ошибке внешней зависимости.
Коротко о Kong, Apigee, Azure API Management и Tyk
API management для госинтеграций - это набор функций вокруг API, который помогает безопасно публиковать сервисы, выдавать доступ внешним потребителям, контролировать нагрузку и собирать следы для проверок. На практике это не только «шлюз», но и правила доступа, журналирование, аналитика, портал для разработчиков и управление версиями.
Kong и Tyk часто выбирают как более легкие и гибкие платформы: их можно развернуть в своем контуре, быстрее подстроить под типовую архитектуру и интегрировать с существующими системами авторизации. Apigee и Azure API Management чаще воспринимаются как «полный стек», где сильнее выражены готовые политики, управление жизненным циклом API, аналитика и инструменты для команд, которые обслуживают много потребителей.
Облако или свой контур
В госсреде вопрос размещения часто решает все. Облако бывает удобнее по эксплуатации, но согласования, требования по локализации данных и правила доступа к контуру могут сделать on-premise вариантом по умолчанию.
On-premise обычно проще объяснить проверяющим: где стоят компоненты, кто администратор, как устроены резервирование и журналы. Облако выигрывает, когда важно быстро запускать новые API и масштабировать нагрузку. Тогда заранее фиксируют, какие данные можно выносить, как хранить логи и кто имеет доступ к настройкам.
Из чего состоит «слой управления»
Минимально полезный набор обычно включает API gateway (единая точка входа, маршрутизация, лимиты, базовые политики безопасности), портал разработчика (документация, заявки на доступ, ключи, тестовые среды), аналитику и журналы (кто вызывал, когда, с каким результатом, где были ошибки), а также набор политик (валидация, преобразования, защита от типовых атак, контроль версий).
«Легкого решения» обычно достаточно, когда у вас 1-2 интеграции, предсказуемая нагрузка и простая схема доступа (например, ключ + IP). В этом случае важнее быстро поставить шлюз и лимиты.
Полный стек нужен, когда десятки потребителей (ведомства, подрядчики, регионы), строгий аудит, много версий API, отдельные песочницы и понятный процесс выдачи доступа. В таких проектах системный интегратор обычно помогает собрать целевую схему под требования заказчика и развернуть ее в доверенном контуре, включая локальную инфраструктуру и эксплуатацию с поддержкой 24/7.
Лимиты и квоты: как защитить контур и не сорвать услуги
В госинтеграциях слой API management важен не только как «шлюз», но и как предохранитель. Без лимитов один сбойный потребитель или неудачный релиз может забить канал, перегрузить бэкенд и заодно «положить» остальных.
Ограничения стоит задавать сразу на нескольких уровнях: по ключу (token или API key), по IP или подсети, по приложению (client_id), по методу или маршруту (например, отдельно на /search и /download), а также по времени (окно в минуту, час, сутки).
Важно различать burst и sustained. Burst защищает от кратких всплесков (например, ретраи после таймаута), а sustained держит среднюю нагрузку в норме (например, 200 запросов в минуту постоянно). Если включить только burst, бэкенд «закипит» от длительной очереди. Если включить только sustained, вы можете «наказать» легитимные короткие пики в начале рабочего дня.
Квоты почти всегда должны различаться по контурам: прод, тест, пилот. Часто их дополнительно делят по ведомствам и ролям. Пример: для пилота одному потребителю дают 50 запросов в минуту и 10 000 в сутки, а для критичного сервиса на проде - выше, но с более строгими правилами по дорогим операциям.
Когда лимит сработал, отказ должен быть понятным и проверяемым. Полезно логировать и, где это уместно, отражать в ответе: кто превысил (ключ, приложение, IP), какой маршрут и метод, какой лимит сработал (burst или sustained и окно времени), значение счетчика и порог, а также корреляционный идентификатор запроса для разбора инцидента. Тогда потребителю проще принять причину («превышена квота по /search в тестовом контуре»), а вашей поддержке проще доказать, что контур защищался, а не «ломался».
Ключи и доступ: практичная схема аутентификации
В госинтеграциях доступ к API почти всегда проверяют не только «по логину», но и по тому, кто именно вызывает метод, откуда, и какие операции ему разрешены. Поэтому лучше сразу выбрать схему, которая проста в сопровождении и достаточно строгая для проверок.
Что выбрать: API key, OAuth2, mTLS, JWT
API key подходит для базовых сценариев, когда есть фиксированный набор систем-потребителей и нужно быстро включить контроль доступа и лимиты. Минус в том, что ключ часто живет долго и его проще случайно «утечь», если нет дисциплины хранения.
OAuth2 удобен, когда потребителей много, есть роли и нужен управляемый жизненный цикл токенов. На практике OAuth2 часто используют вместе с JWT, чтобы шлюз мог быстро проверять права и сроки действия без постоянных запросов внутрь.
mTLS (взаимная TLS-аутентификация по сертификатам) хорошо работает для межсистемного взаимодействия в закрытом контуре. Это сильный сигнал доверия: подключиться без клиентского сертификата нельзя. Частая схема: mTLS отвечает на вопрос «кто ты и откуда», а OAuth2/JWT - «что тебе можно».
Если выбирать без лишней сложности, обычно ориентируются так: для server-to-server в закрытой сети - mTLS + короткоживущий JWT; при большом числе потребителей и ролей - OAuth2/JWT; для временной интеграции или простого чтения - API key, но с жесткими лимитами и регулярной ротацией.
Ротация и сроки действия: чтобы не остановить интеграции
Частая причина «внезапных» падений - истекший ключ или сертификат. Делайте ротацию без простоя: заранее выпускайте новый ключ, держите короткий период, когда работают оба, затем отключайте старый. Для OAuth2 ставят короткие токены доступа и более длинные токены обновления, а для mTLS ведут календарь продления сертификатов.
Разделяйте права по операциям, а не «один ключ на все». Минимальный набор ролей обычно такой: чтение (GET/справки), запись (создание/изменение), админские операции (управление справочниками, массовые действия), техдоступ (диагностика, ограниченная по времени).
Хранение секретов должно быть регламентировано: ключи и приватные сертификаты не держат в почте, чатах и документах. Доступ дают только тем, кто обслуживает интеграцию, по заявке и с журналированием. Практика, которая хорошо переживает аудит: отдельное хранилище секретов, выдача по ролям и регулярная проверка «кто имеет доступ и зачем».
Аудит и журналирование: что проверяют и как подготовиться
Для госинтеграций журналирование - это не «посмотреть ошибки», а доказуемость: кто обращался к API, что запрашивал, почему получил отказ, и кто менял настройки шлюза. В проектах API management это часто проверяют так же строго, как доступ к базам данных.
Минимальный набор событий лучше определить сразу. Обычно ожидают, что в логах есть факт обращения (успех и отказ), технические ошибки (4xx/5xx), превышение лимитов, а также любые изменения конфигурации: политики, маршруты, ключи, сертификаты, роли, правила IP-доступа.
Чтобы расследования не превращались в ручной квест, включайте корреляцию запросов по цепочке. Подход простой: один request-id проходит через API-шлюз, сервисы и очереди и попадает в логи всех компонентов. Тогда можно быстро собрать историю «пользователь -> шлюз -> сервис -> внешняя система» и понять, где случился сбой. Важно заранее договориться, кто генерирует идентификатор (часто шлюз) и как он передается дальше (например, в заголовке).
По хранению логов обычно два требования: срок и защита от подмены. Срок задают регуляторика и внутренние политики, но почти всегда это месяцы, а не дни. Защиту делают через разделение прав (кто пишет, кто читает, кто удаляет), неизменяемое хранилище (WORM или аналог) и отправку копии в централизованный мониторинг/SIEM. Если логи могут содержать персональные данные или служебную информацию, полезно также фиксировать «кто смотрел логи».
Заранее подготовьте шаблоны отчетов, которые чаще всего просят на проверках: реестр потребителей и прав (какие ключи/клиенты имеют доступ к каким методам), статистику обращений и отказов, журнал изменений конфигурации с инициатором и подтверждением (тикет/заявка), а также выборки инцидентов с полным следом по request-id и временем восстановления.
Пример: внешний потребитель жалуется на «пропавшие ответы» при обращении к реестру. Если есть request-id, за несколько минут видно, что на шлюзе запрос прошел, дальше сработал таймаут на стороне интеграционного сервиса, а в тот же день кто-то изменил политику ретраев. Без корреляции и журнала изменений это часто превращается в недельный спор «у кого проблема».
Версионирование API без конфликтов и простоев
Версионирование в госинтеграциях нужно, чтобы новые функции не ломали действующие услуги. В один и тот же API приходят разные потребители: старые ведомственные системы, новые мобильные приложения, подрядчики. Если обновление внезапно меняет формат полей или правила валидации, падают интеграции и бизнес-процессы.
Версии в URL или в заголовках
Версия в URL (например, /v1/) проще для поддержки и диагностики. Ее видно в логах, ее легко маршрутизировать на разные бэкенды, и многим командам так проще договариваться. Минус в том, что URL быстро «расползается» по документации и коду потребителей, а значит, миграция требует релиза у каждого.
Версия в заголовках (Accept или отдельный X-API-Version) меньше трогает маршруты и иногда удобнее для эволюции. Но в расследованиях инцидентов заголовки чаще теряются: не все прокси их сохраняют и не все логи пишут полностью. Это стоит учитывать.
Главное правило: где бы ни была версия, она должна быть однозначной, проверяемой на шлюзе и отражаться в журналах.
Обратная совместимость - лучший способ избежать массовых падений. Если меняете поле, чаще безопаснее добавить новое и поддержать оба, чем переименовывать «в лоб». Для старых версий задайте срок поддержки (например, 6-12 месяцев) и не нарушайте его без критической причины.
Политика депрекейта должна быть формальной: помечайте устаревшие методы в документации и в ответах (например, заголовком Deprecation), заранее уведомляйте потребителей и фиксируйте окно миграции, следите за метриками использования старой версии по ключам и клиентам, ограничивайте новые подключения только на актуальную версию и отключайте старую по плану.
Чтобы тестировать новую версию без риска для продакшена, используйте параллельный выпуск: отдельный маршрут для v2, изолированные квоты и ключи, и «теневое» сравнение ответов на части трафика (без влияния на пользователя). В Kong, Apigee, Azure API Management и Tyk это обычно решается правилами маршрутизации, лимитами и логированием на уровне шлюза.
Портал разработчика: меньше переписки, больше прозрачности
Портал разработчика - место, где потребители API находят ответы и получают доступ без длинной цепочки писем. Для госинтеграций это особенно важно: участников много, контроль строгий, изменения идут постоянно. Хорошо настроенный портал снижает риск ошибок и ускоряет согласования, не теряя управляемость.
Минимальный набор, который действительно работает: понятная документация (методы, параметры, коды ошибок, примеры), спецификация (например, OpenAPI) и версия документации рядом с версией API, sandbox с безопасными данными и четкими ограничениями, самообслуживание по ключам (выпуск, ротация, отзыв, просмотр лимитов), а также страница статуса и инцидентов.
Онбординг лучше строить как короткий и измеримый процесс. Сначала потребитель выбирает API и сценарий доступа, затем подтверждает организацию и контакт ответственного, после чего получает минимальные права для тестов. Полный доступ выдают после проверки: кто владелец интеграции, где хранится ключ, какие IP/сети используются, какие лимиты нужны и кто отвечает за журналирование у потребителя.
Чтобы изменения не становились сюрпризами, нужна дисциплина выпусков. На портале должны быть правила совместимости (что считается breaking change), календарь поддерживаемых версий и release notes простым языком: что изменилось, кого затронет, что нужно сделать и до какого срока. Удобный прием - шаблон заметки о релизе: один абзац для руководителя и отдельный блок с деталями для разработчика.
Пример: при интеграции с госреестром один потребитель использует только поиск, другой - массовую выгрузку. На портале это можно оформить как два профиля доступа с разными квотами и наборами методов, а ключи выдавать отдельно. Поддержка при этом получает меньше типовых вопросов, потому что ответы находятся в документации, примерах и статусе.
Если вы внедряете API management, начните с портала: это самый заметный для потребителей слой. В проектах системной интеграции, где участвуют компании уровня GSE.kz (gse.kz), портал часто становится и точкой контроля качества: по нему быстро видно, где документация устарела, где лимиты настроены неудачно и где процесс доступа слишком сложный.
Сценарии отказа и деградации: как не упасть вместе с зависимостями
В госинтеграциях внешний реестр, шина или ведомственная система могут стать узким местом. Проблема редко выглядит как «все упало» - чаще это рост задержек, частичные ответы, всплеск 500-х и очередь запросов, которая тянет вниз ваш сервис. Сценарии отказа стоит продумать заранее: что делать при медленном ответе, при временной недоступности и при деградации качества данных.
Таймауты, ретраи и circuit breaker
Первое правило: время ожидания должно быть ограничено и одинаково понятно всем участникам. Если таймаут на шлюзе 30 секунд, а у клиента 5 секунд, вы получите лишние повторы и «зомби»-запросы.
Обычно помогает базовая настройка:
- Таймауты: короткие для чтения справочников, чуть длиннее для операций, где допустима обработка.
- Ретраи: только для безопасных операций (GET), с паузой и джиттером, и с лимитом попыток.
- Circuit breaker: при серии ошибок или росте задержек шлюз (и клиент) временно «отсекают» зависимость, чтобы не утопить весь контур.
- Ограничение параллелизма: чтобы «плохая» зависимость не забрала все рабочие потоки.
Роли важно разделять: шлюз защищает периметр и стабилизирует трафик, а клиент обязан корректно обрабатывать ошибки и не «долбить» зависимость бесконечно.
Кэширование и план деградации
Кэш особенно полезен для справочников (коды регионов, статусы, неизменяемые перечни). Но он допустим только если вы фиксируете срок актуальности и понимаете риск. Хорошая практика - хранить метку «данные из кэша» и дату последнего обновления.
План деградации лучше описать простыми правилами:
- Если реестр недоступен, возвращаем последний валидный ответ для справочника (до N часов).
- Для критичных проверок вместо «пусто» возвращаем понятную ошибку и сценарий повторного обращения.
- Для некритичных полей (адрес, дополнительные атрибуты) возвращаем частичный ответ и явно отмечаем неполноту.
Отдельно продумайте георезервирование и разделение контуров: тестовый трафик, отчетность и массовые проверки не должны жить в одном «коридоре» с боевыми госуслугами. В системной интеграции это часто оформляют как независимые контуры с разными лимитами, ключами и правилами отказа, чтобы локальная авария не стала массовой.
Пример сценария: подключение к реестру с разными потребителями
Представим единый реестр (например, реестр лицензий), к которому подключаются три ведомства. Ведомство А делает массовые проверки пакетами. Ведомство Б работает из фронт-офиса, и важно время ответа. Ведомство В подключает аналитическую витрину и делает редкие, но тяжелые запросы. У всех разные SLA, и при этом нельзя допустить, чтобы один потребитель «задушил» реестр пиками нагрузки.
Здесь слой API management работает как «диспетчер»: принимает запросы, применяет правила доступа и лимитов, пишет аудит и дает понятные отчеты каждой стороне.
Как развести доступы, ключи и квоты
Практичный подход - завести три отдельных продукта (или плана доступа) и три набора учетных данных. Тогда ключи и лимиты не смешиваются, а настройки остаются прозрачными.
Например:
- Ведомство А: 200 запросов/сек, но с жестким ограничением на размер ответа и обязательной фильтрацией полей.
- Ведомство Б: 50 запросов/сек, приоритет по задержке, короткий таймаут и понятные коды ошибок для операторов.
- Ведомство В: 10 запросов/сек, разрешены только «тяжелые» методы, но строго по расписанию или с отдельной квотой по времени.
Ключи выдают отдельно (API key или OAuth2 client credentials), а для чувствительных методов добавляют mTLS или подпись запроса. Важно, чтобы каждый ключ был привязан к конкретному потребителю, среде (тест/прод) и набору методов.
Аудит и отчеты, которые устраивают всех
Аудит удобно строить вокруг «кто, что, когда, откуда и с каким результатом». В логах фиксируются идентификатор потребителя, метод, путь, код ответа, время, размер, а также корреляционный ID, чтобы собрать одну цепочку по всему контуру. Для персональных данных заранее решают, что маскируется, а что хранится только в защищенном хранилище.
В отчетах полезно разделять разрезы: отдельные дашборды по каждому ведомству (успехи/ошибки/пики) и общий отчет для владельца реестра (нагрузка, доступность, нарушения лимитов).
Переход на новую версию API без остановки
Если нужно добавить поля или поменять формат, безопаснее держать v1 и v2 параллельно. Сначала публикуется v2 на портале разработчика с примерами, сроками и тестовыми ключами. Затем включают маршрутизацию на v2 для пилотной группы (например, только Ведомство В), добавляют предупреждения в заголовках ответов v1 о сроках вывода, ставят разные лимиты для v1 и v2, а после стабилизации переводят v1 в режим «только чтение» и выводят по плану.
Так даже при разной зрелости потребителей вы не останавливаете прием обращений и сохраняете управляемость изменений.
Пошаговый план внедрения и следующие действия
Если вам нужен API management для госинтеграций, лучше начать не с выбора продукта, а с плана. Тогда Kong, Apigee, Azure API Management или Tyk решают конкретные задачи, а не стоят «для галочки».
5 шагов, которые обычно дают предсказуемый результат
-
Соберите требования: какие контуры участвуют (внутренний, межведомственный, интернет), какие SLA по доступности и времени ответа, какие проверки по безопасности и аудиту ожидаются. Сразу договоритесь, сколько и где хранятся логи, кто имеет доступ, и как быстро можно поднять цепочку событий по инциденту.
-
Выберите модель размещения и разберите точки отказа. Для госинтеграций это часто гибрид: часть компонентов внутри периметра, часть в выделенной зоне. Отдельно проверьте, что будет при недоступности внешней зависимости, базы, DNS, канала связи и центра сертификатов.
-
Опишите политики как «правила сервиса», а не как настройки конкретного вендора. Минимальный набор: лимиты и квоты по потребителям, выдача и ротация ключей, требования к версиям API, обязательные поля в логах, маскирование персональных данных, правила для ошибок и таймаутов.
-
Проведите пилот на одном реальном сценарии. Например, один реестр и два типа потребителей: внутренний сервис с высоким лимитом и внешний подрядчик с жесткой квотой. На пилоте проще проверить, что разработчикам понятно, как получить доступ, а службе безопасности понятно, как расследовать инцидент.
-
После пилота закрепите эксплуатацию: регламенты, матрицу ответственности, расписание обновлений, процедуры отката, шаблоны для публикации новых версий и согласований. Добавьте нагрузочные проверки и контроль того, что новые политики не ломают старых потребителей.
Следующие действия обычно простые: выбрать 1-2 критичных интеграции для пилота, согласовать формат логирования и аудит, определить владельца API (кто принимает решения), и только потом сравнивать платформы по стоимости и удобству.
Если нужен партнер, который может закрыть инфраструктуру и интеграцию в одном проекте, имеет смысл смотреть на системных интеграторов, которые умеют строить доверенные контуры и сопровождать их круглосуточно. Например, GSE.kz занимается системной интеграцией, решениями для дата-центров и поддержкой 24/7 через сервисную сеть по Казахстану.
FAQ
Зачем вообще нужен отдельный слой API management в госинтеграциях?
Потому что основные сбои часто происходят не в самом API, а вокруг него: лишние вызовы из-за ошибки у потребителя, нестандартные заголовки, просроченные сертификаты, бесконечные ретраи. Слой API management перехватывает такие проблемы на входе, ограничивает ущерб и дает прозрачность, кто именно вызвал инцидент.
Чем API management отличается от WAF или обычного прокси?
WAF в первую очередь отсекает типовые атаки, но обычно не решает задачи контрактов API: квоты по ключам, разные политики для разных потребителей, версионирование, единые правила ошибок и портал документации. Обычный прокси просто «пробрасывает» трафик и без централизованных политик быстро превращается в набор ручных исключений.
Что входит в «слой управления API» на практике?
Минимально полезный набор включает единую точку входа (gateway) для маршрутизации, лимитов и базовой безопасности, плюс журналы и аналитические следы, чтобы разбирать инциденты. Дальше обычно добавляют портал разработчика для документации и выдачи доступа, а также политики валидации, преобразований и управления версиями.
Что лучше для госсреды: облако или свой контур?
On‑premise чаще выбирают из-за требований к локализации данных, контролю администрирования и простоты объяснения аудиторам, где стоят компоненты и как устроены журналы. Облако удобно, когда важно быстро запускать API и масштабировать нагрузку, но тогда заранее фиксируют, какие данные и логи можно выносить и кто имеет доступ к настройкам.
Как правильно настроить лимиты и квоты, чтобы один потребитель не «положил» всех?
Задайте ограничения сразу по нескольким измерениям: по ключу или client_id, по IP/подсети, по методу или маршруту и по времени (минута, час, сутки). Разделяйте burst и sustained: первое гасит краткие всплески, второе держит среднюю нагрузку, и вместе они лучше защищают бэкенд и очередь.
Что должно происходить, когда срабатывает лимит?
Отказ должен быть понятным и проверяемым: фиксируйте в логах, какой именно потребитель превысил лимит, какой метод и маршрут, какое окно времени и какой счетчик сработал. Если это уместно, отражайте в ответе код и краткую причину, а также корреляционный идентификатор запроса, чтобы поддержка быстро нашла цепочку событий.
Что выбрать для доступа: API key, OAuth2/JWT или mTLS?
Для закрытого межсистемного взаимодействия часто подходит mTLS как сильная проверка «кто подключился», а права и сроки удобнее давать через OAuth2/JWT. API key используют для простых или временных сценариев, но тогда нужны жесткие лимиты и регулярная ротация, чтобы ключ не стал вечной «общей учеткой».
Как избежать падений из-за просроченных ключей и сертификатов?
Делайте ротацию без простоя: заранее выпустите новый ключ или сертификат, держите период, когда работают оба, и только потом отключайте старый. Введите календарь продления сертификатов и разделяйте права по операциям, чтобы компрометация одной учетной записи не давала полный доступ ко всем методам.
Что чаще всего хотят видеть аудит и проверяющие в логах?
Обычно проверяют доказуемость: кто обращался, что запрашивал, почему получил отказ, и кто менял настройки шлюза и политик. Практичный минимум — логировать обращения (успехи и отказы), 4xx/5xx, превышения лимитов и все изменения конфигурации, а также вести request-id через шлюз и сервисы для быстрой корреляции инцидентов.
Как лучше версионировать API: в URL или в заголовках?
Версия в URL проще для поддержки и расследований, потому что ее видно сразу и легко маршрутизировать, но миграция требует обновления у каждого потребителя. Версия в заголовках меньше трогает маршруты, но заголовки чаще теряются в промежуточных прокси, поэтому важно, чтобы шлюз проверял версию и писал ее в журналы, а старые версии выводились по формальному плану.